论文查重怎么办?就那么办!OK!
数据查重怎么办?就这么办!KO!
数据清洗过程中的典型问题:数据分析|R-缺失值处理、数据分析|R-异常值处理和重复值处理,本次简单介绍一些R处理重复值的用法:
-
将符合目标的重复行全部删掉;
-
存在重复的行,根据需求保留一行
数据准备
使用GEO数据库的表达数据,抽取一些并稍加处理(为方便展示)

data read.csv("A.csv",header=TRUE)
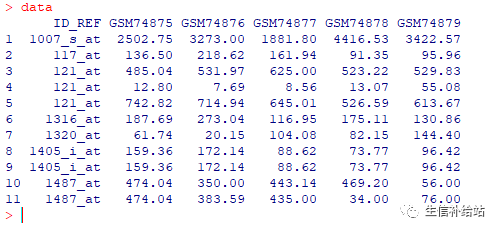
可以明显看到ID_REF存在重复,那要怎么处理呢?
一个不留
对于重复的行,一个不留!
1. unique 直接去重
data1 unique(data)data1
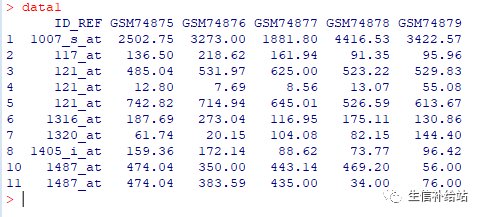
简单,直接,可以看到第9行完全重复的已经被删除。
如果我还想去掉ID_REF重复的行,怎么办?
2. duplicated 可选去重
1)删除数据集中完全重复的行,同unique
data2 data[!duplicated(data),]
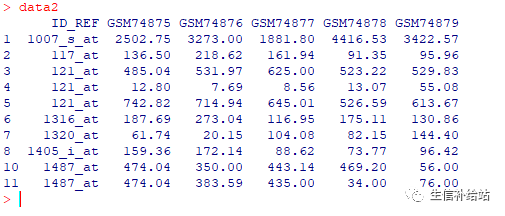
2)选择性删除
A:删除某一列存在重复的行
data2 data[!duplicated(data$ID_REF),]
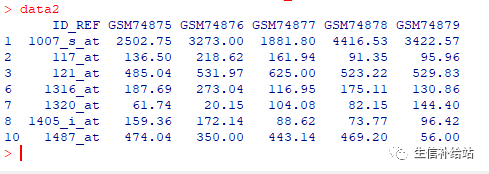
删除了ID_REF列存在重复的行,搞定!
B:删除某几列重复的行
#等价data2 data[!duplicated(data[,c("ID_REF","GSM74876")]),]data2 data[!duplicated(data[,c(1,3)]),]

删除了ID_REF列和GSM74876列均重复的行,Done!
择“优”录取
存在重复,但是不想完全删除,根据数据处理的目的保留一行。
1. aggregate函数
A : ID_REF重复行,保留其均值
data3 aggregate( . ~ ID_REF,data=data, mean)
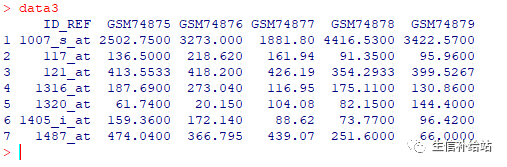
保留其最大值如下即可:
data3 aggregate( . ~ ID_REF,data=data, max)
2 dplyr函数
A : ID_REF重复行,保留其均值,同aggregate函数结果一致。
library(dplyr)data4 data %>% group_by(ID_REF) %>% summarise_all(mean)
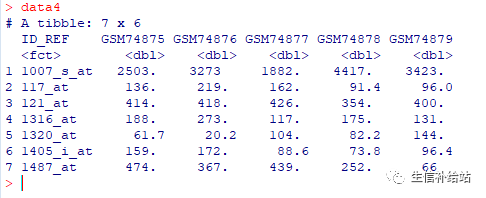
表达量去重
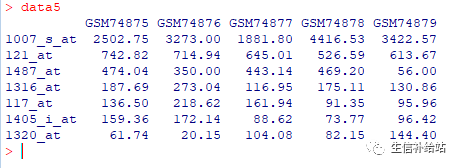
芯片表达数据中,会存在一个基因多个探针的情况,此处选择在所有样本中表达量之和最大的探针。
library(tibble)data5 data %>% #计算每个探针(行)的表达量均值 mutate(rowMean =rowMeans(.[grep("GSM", names(.))])) %>% #表达量均值从大到小排序 arrange(desc(rowMean)) %>% # 选择第一个,即为表达量最大值 distinct(ID_REF,.keep_all = T) %>% #去除rowMean这一列 select(-rowMean) %>% # 将ID_REF列变成行名 column_to_rownames(var = "ID_REF")
好了,常用的数据去重方法先介绍这些,绝对比论文查重简单多了!
◆ ◆ ◆ ◆ ◆
数据分析相关:
R|批量循环处理同一格式文件-csv,txt,excel
R In Action |基本数据管理
数据分析|R-缺失值处理
数据分析|R-异常值处理
数据分析|R-描述性统计
小数据| 描述性统计(Python/R 实现)
数据挖掘|R-相关性分析及检验
数据处理 | R-tidyr包
数据处理|R-dplyr
R|apply,tapply
数据处理|数据框重铸
R|ML_code-入门(1)
R|ML_code-线性回归(2)
R|机器学习入门-多元线性回归(3)
【觉得不错,右下角点个“在看”,期待您的转发,谢谢!】