Redis中五种类型的对象
为什么是五种类型的对象呢?
对象的类型与编码
Redis使用对象来表示数据库中的键和值,每当创建一个键值对的时候,其实我们至少创建了两个对象:键对象和值对象。
键对象其实就是字符串对象。而值对象是字符串、列表、哈希、集合、有序集合对象中的一个。
为什么创建的是对象呢?
不管是值对象和键对象,其都是用redisObject结构表示。结构中有三个属性:type、encoding、ptr。

由此我们实例化了以后就是一个对象了。
三个属性代表什么意思呢?
类型:type
type也是一个命令,其返回的结果为
键对应的值对象的类型
这个属性的值只能是以下五种类型中的一个。

所谓“列表键”:指的是键对应的值是列表对象。而键永远是一个字符串对象。
编码:encoding 底层实现指针 ptr
encoding记录了值对象所使用的编码,也就是用了什么数据结构作为底层的实现。ptr指针指向对象的底层实现的数据结构。
encoding属性的值,也是下面8个中的一个。
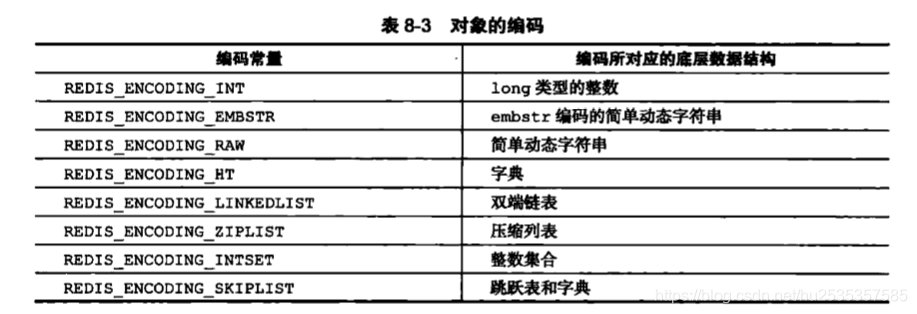
由此:对象由三种属性构成,type、encoding 、ptr 这三个属性决定了,对象是什么对象,底层是由什么数据结构实现的。
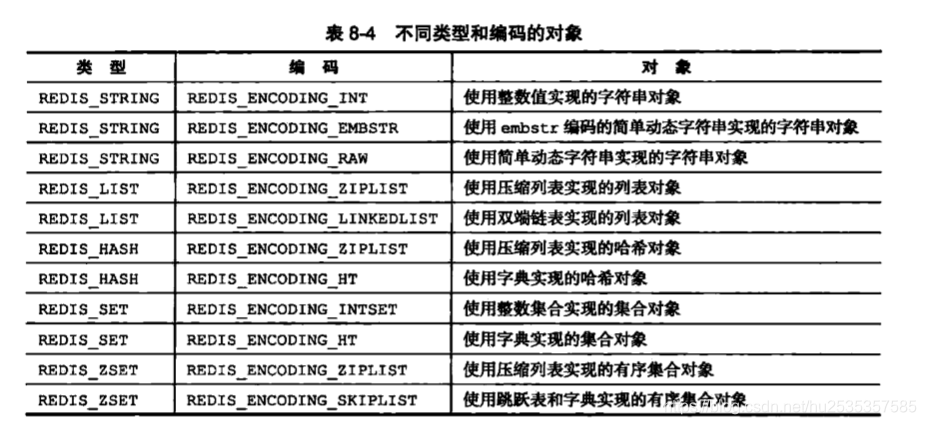
下图标明了:五种对象的编码以及对应的数据结构实现。
使用OBJECT ENCODING 命令来查看一个数据库键的值的对象的编码。
总结:分清楚键对象和值对象,以及对象(redisobject)结构中的三个属性。
通过type命令来查看值对象的类型,通过objectencoding来查看值对象的编码(底层数据结构)。
每种类型有2-3个编码,这样极大的提升了redis灵活性。可以根据不同的场景选择不同的编码,比如使用压缩列表作为列表对象的底层实现:因为压缩列表比双端链表更加节约内存。并且在元素数量较少时,在内存中以连续块方式保存的压缩列表比双端链表更加容易载入缓存,但是随着列表中的对象越来越多,使用压缩列表保存元素的优势逐渐消失,那么对象就会将底层实现的压缩列表转换成双端链表上。对象从一种编码转换成另外一种编码是需要条件的。
字符串对象
字符串的数据结构
字符串的对象的编码有三种:int、raw、embstr。
编码是raw的字符串对象表示
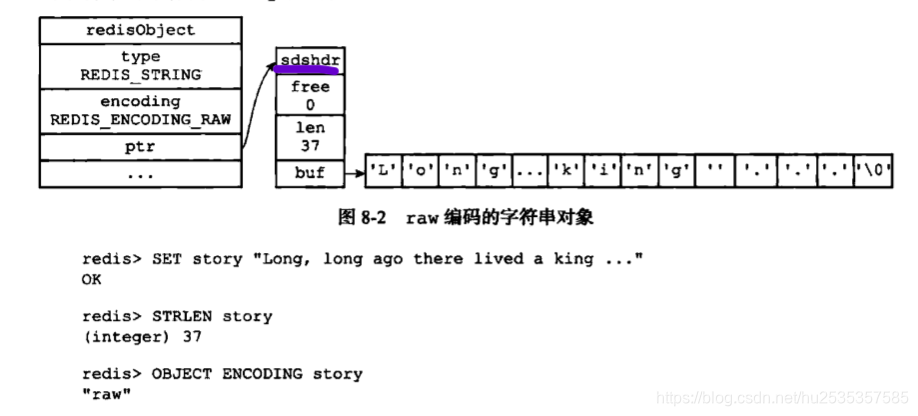
由此结构可以看出, raw编码会调用两次内存分配函数来创建redisobject和sdhdr结构。因此raw保存的字符串长度比较长。(大于等于32个字节)
int编码的字符串对象是由ptr直接指向整数值。embtr相对于raw是用来存储短字符串的优化方式(小于32字节)。
编码的转换
int转换为raw编码
本来是存储的是整数值,但是我们append一个字符串,这样就会从int编码转换成raw编码。
embtr转换成raw编码
embtr是一个只读的编码,意思是在我们首次存入一格小于32字节的时候,其编码为embtr,之后做出任何修改就会变成raw编码。
字符串的命令处理
字符串可以存储三种类型:字节串、整数、浮点数。同时也可以对数值进行自增和自减操作以及二进制和子串的处理命令。


上述命令中常用的是自增、自减以及处理子串。
列表
列表的编码可以是ziplist和linkedlist。

从上面可以看出,我们一般使用的列表对象一般都是ziplist底层结构实现。
编码转换:
使用ziplist必须同时满足两个条件:1.列表对象保存的字符串长度小于64字节。2.数量小于512个。不能
同时
满足以上两个条件的都用linkedlist。
列表的处理命令
其实就是一个双端链表,允许用户从序列的两端推入或者弹出元素。
处理命令

LTRIM命令和LRANGE命令可以构建一个在功能上类似LPOP和RPOP,但是一次却可以返回多个元素的操作。

“阻塞执行”的优点是:如果元素在会直接弹出,如果不在可以设置超时时间等待元素的出现。
散列
散列对象的编码可以是ziplist或者hashtable。

那么profile键的值对象是ziplist底层实现的。
底层实现存储如下表示:

那么
如果
说profile键对应的哈希对象是hashtable底层实现
那么存储方式应该是下面的样子:
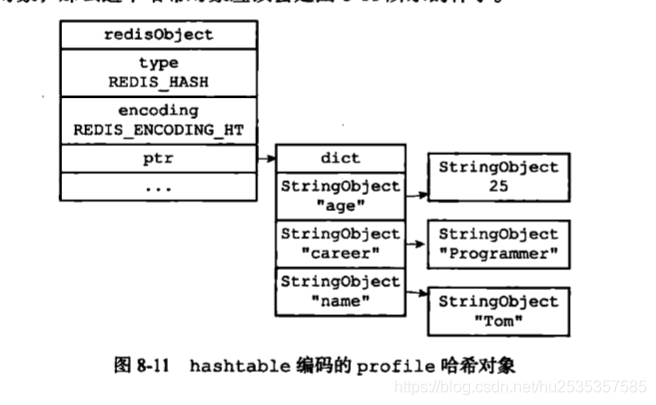
hashtable编码的profile对象:键是字符串对象,值是哈希对象。但是哈希对象的底层表示中,键是字符串对象,值也是字符串对象。
编码转换:使用ziplist必须同时满足两个条件:1.保存的所有键和值的字符串小于64字节。2.数量小于512。不能同时满足则用hashtable
常用命令介绍:
添加、删除键值对、获取所有键值对,以及键值对的自增、自减操作。


集合
编码可以是intset和hashtable

以intset编码的存储结构
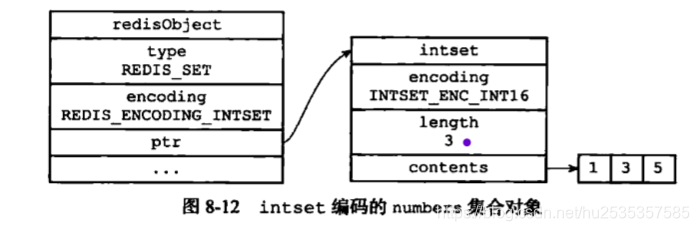
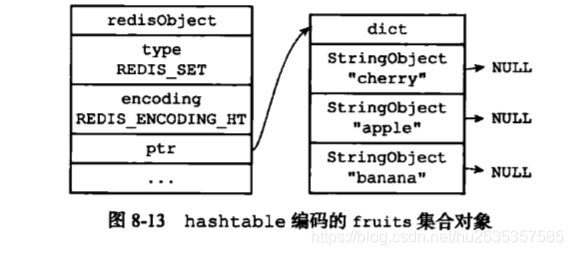
那么以hashtable编码作为集合对象的底层实现,字典的键是一个字符串对象,这个字符串对象包含了一个集合元素,其字典的值为null。

hashtable 编码的底层存储方式
编码转换:
使用intset编码同时满足两个条件:
1.都是整数
2.数量不超过512.不能同时满足用hashtable。
集合的命令处理
集合以无序的方式存储多个各不相同的元素,用户可以快速的对集合执行添加元素的操作,移除元素操作以及检查一个元素是否存在于集合里。常用的命令是:插入、移除、将元素从一个集合移动到另外一个集合,以及进行交集、并集。差集运算。



有序集合
有序集合的编码可以是ziplist和skiplist

ziplist编码的底层存储

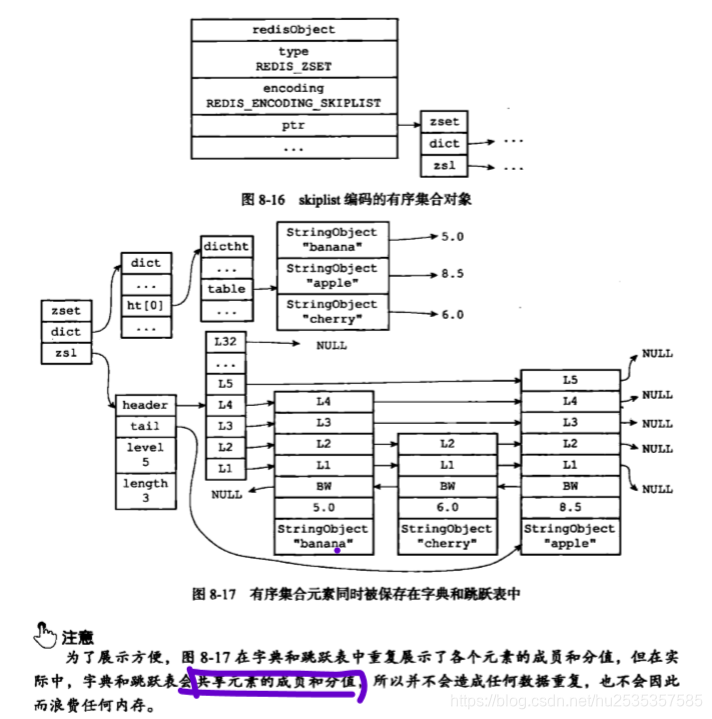
skipist编码的有序集合使用zset结构(两个属性:zsl(跳跃表)、dict(字典))
跳跃表按照分值大小保存了所有集合元素,而字典可以以O(1)的复杂度查找键值对。这也就是为什么使用字典+跳跃表实现来实现有序集合。
下面是zset结构和skiplist编码的底层存储
编码的转换
使用ziplist同时满足2个条件:
数量小于128、元素成员小于64字节。
不能满足以上两个用skiplist。
有序集合的命令处理
有序集合存储着成员与分值之间的映射,并且提供了分值的处理命令,以及根据分值的大小有序地获取或者扫描成员和分值的命令。
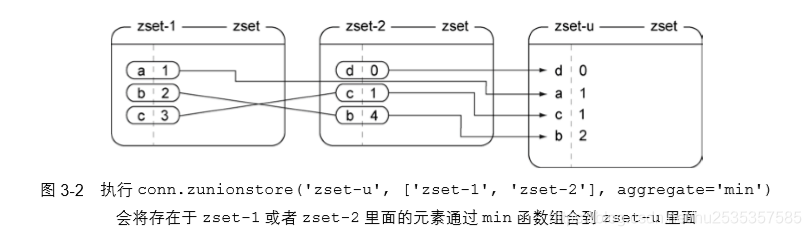
命令介绍:添加、更新、交集和并集

交集处理(默认的是sum(加和))
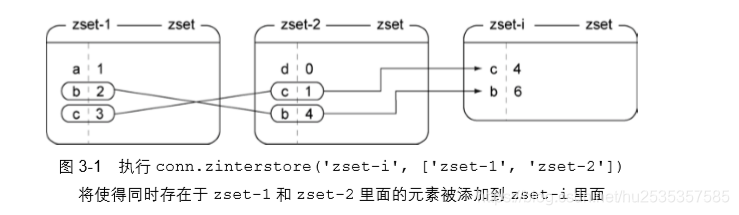
并集处理