神经网络学习小记录63——Keras 图像处理中注意力机制的解析与代码详解
学习前言
注意力机制是一个非常有效的trick,注意力机制的实现方式有许多,我们一起来学习一下。

什么是注意力机制
注意力机制是
深度学习常用的一个小技巧
,它有多种多样的实现形式,尽管实现方式多样,但是
每一种注意力机制的实现的核心
都是类似的,就是
注意力
。
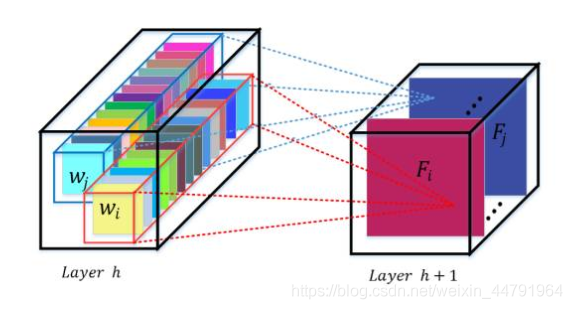
注意力机制的核心重点就是让网络关注到它更需要关注的地方
。
当我们使用卷积神经网络去处理图片的时候,
我们会更希望卷积神经网络去注意应该注意的地方,而不是什么都关注
,我们不可能手动去调节需要注意的地方,这个时候,如何让
卷积神经网络去自适应的注意重要的物体
变得极为重要。
注意力机制
就是实现
网络自适应注意
的一个方式。
一般而言,注意力机制可以分为通道注意力机制,空间注意力机制,以及二者的结合。
代码下载
Github源码下载地址为:
https://github.com/bubbliiiing/yolov4-tiny-keras
复制该路径到地址栏跳转。
注意力机制的实现方式
在深度学习中,常见的注意力机制的实现方式有SENet,CBAM,ECA等等。
1、SENet的实现
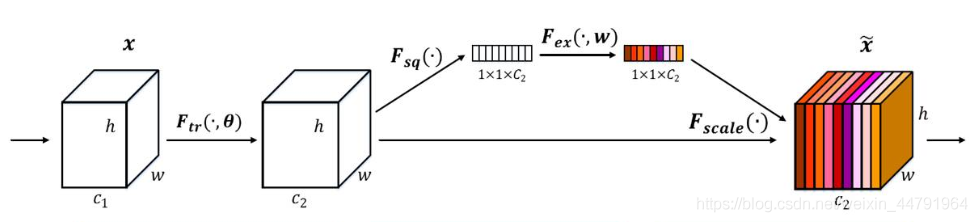
SENet是通道注意力机制的典型实现。
2017年提出的SENet是最后一届ImageNet竞赛的冠军,其实现示意图如下所示,对于输入进来的特征层,我们关注其每一个通道的权重,对于SENet而言,
其重点是获得输入进来的特征层,每一个通道的权值
。利用SENet,我们可以让网络关注它最需要关注的通道。
其具体实现方式就是:
1、对输入进来的
特征层进行全局平均池化
。
2、然后进行两次全连接,第一次
全连接神经元个数较少
,第二次
全连接神经元个数和输入特征层相同
。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了
输入特征层每一个通道的权值
(0-1之间)。
4、在获得这个权值后,我们将
这个权值乘上原输入特征层即可。
实现代码如下:
def se_block(input_feature, ratio=16, name=""):
channel = input_feature._keras_shape[-1]
se_feature = GlobalAveragePooling2D()(input_feature)
se_feature = Reshape((1, 1, channel))(se_feature)
se_feature = Dense(channel // ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=False,
bias_initializer='zeros',
name = "se_block_one_"+str(name))(se_feature)
se_feature = Dense(channel,
kernel_initializer='he_normal',
use_bias=False,
bias_initializer='zeros',
name = "se_block_two_"+str(name))(se_feature)
se_feature = Activation('sigmoid')(se_feature)
se_feature = multiply([input_feature, se_feature])
return se_feature
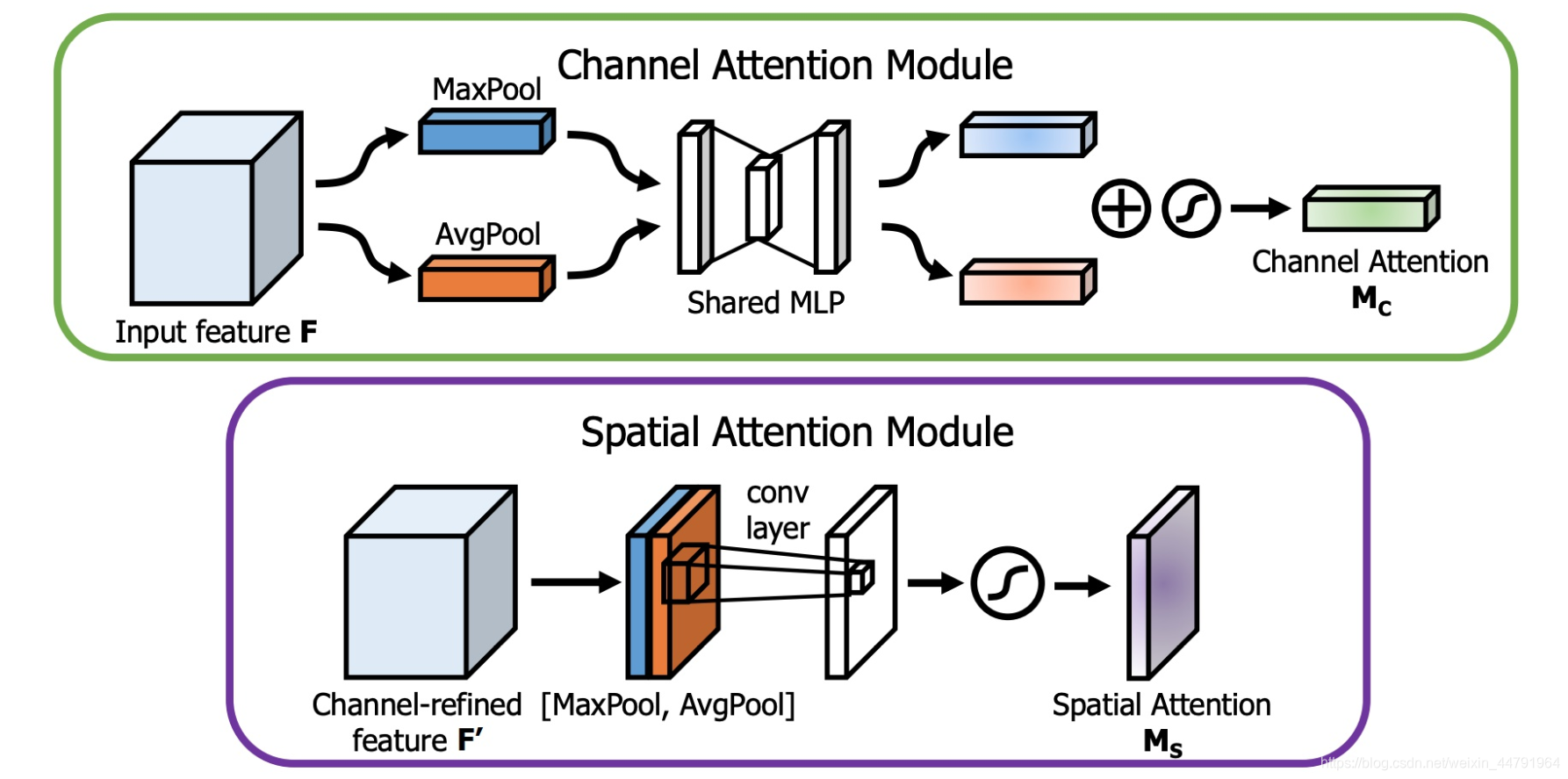
2、CBAM的实现
CBAM将
通道注意力机制和空间注意力机制
进行一个结合,相比于
SENet只关注通道的注意力机制
可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行
通道注意力机制的处理和空间注意力机制的处理
。

下图是
通道注意力机制和空间注意力机制
的具体实现方式:
图像的上半部分为
通道注意力机制
,
通道注意力机制的实现
可以分为
两个部分
,我们会对输入进来的
单个特征层
,分别进行
全局平均池化
和
全局最大池化
。之后对
平均池化
和
最大池化
的结果,利用
共享的全连接层
进行处理,我们会对
处理后的两个结果
进行相加,然后取一个sigmoid,此时我们获得了
输入特征层每一个通道的权值
(0-1之间)。在获得这个权值后,我们将
这个权值乘上原输入特征层即可。
图像的下半部分为
空间注意力机制
,我们会对输入进来的特征层,在
每一个特征点的通道上取最大值和平均值
。之后将这两个结果进行一个堆叠,利用一次
通道数为1的卷积调整通道数
,然后取一个
sigmoid
,此时我们获得了
输入特征层每一个特征点的权值
(0-1之间)。在获得这个权值后,我们将
这个权值乘上原输入特征层即可。
实现代码如下:
def channel_attention(input_feature, ratio=8, name=""):
channel = input_feature._keras_shape[-1]
shared_layer_one = Dense(channel//ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=False,
bias_initializer='zeros',
name = "channel_attention_shared_one_"+str(name))
shared_layer_two = Dense(channel,
kernel_initializer='he_normal',
use_bias=False,
bias_initializer='zeros',
name = "channel_attention_shared_two_"+str(name))
avg_pool = GlobalAveragePooling2D()(input_feature)
max_pool = GlobalMaxPooling2D()(input_feature)
avg_pool = Reshape((1,1,channel))(avg_pool)
max_pool = Reshape((1,1,channel))(max_pool)
avg_pool = shared_layer_one(avg_pool)
max_pool = shared_layer_one(max_pool)
avg_pool = shared_layer_two(avg_pool)
max_pool = shared_layer_two(max_pool)
cbam_feature = Add()([avg_pool,max_pool])
cbam_feature = Activation('sigmoid')(cbam_feature)
return multiply([input_feature, cbam_feature])
def spatial_attention(input_feature, name=""):
kernel_size = 7
cbam_feature = input_feature
avg_pool = Lambda(lambda x: K.mean(x, axis=3, keepdims=True))(cbam_feature)
max_pool = Lambda(lambda x: K.max(x, axis=3, keepdims=True))(cbam_feature)
concat = Concatenate(axis=3)([avg_pool, max_pool])
cbam_feature = Conv2D(filters = 1,
kernel_size=kernel_size,
strides=1,
padding='same',
kernel_initializer='he_normal',
use_bias=False,
name = "spatial_attention_"+str(name))(concat)
cbam_feature = Activation('sigmoid')(cbam_feature)
return multiply([input_feature, cbam_feature])
def cbam_block(cbam_feature, ratio=8, name=""):
cbam_feature = channel_attention(cbam_feature, ratio, name=name)
cbam_feature = spatial_attention(cbam_feature, name=name)
return cbam_feature
3、ECA的实现
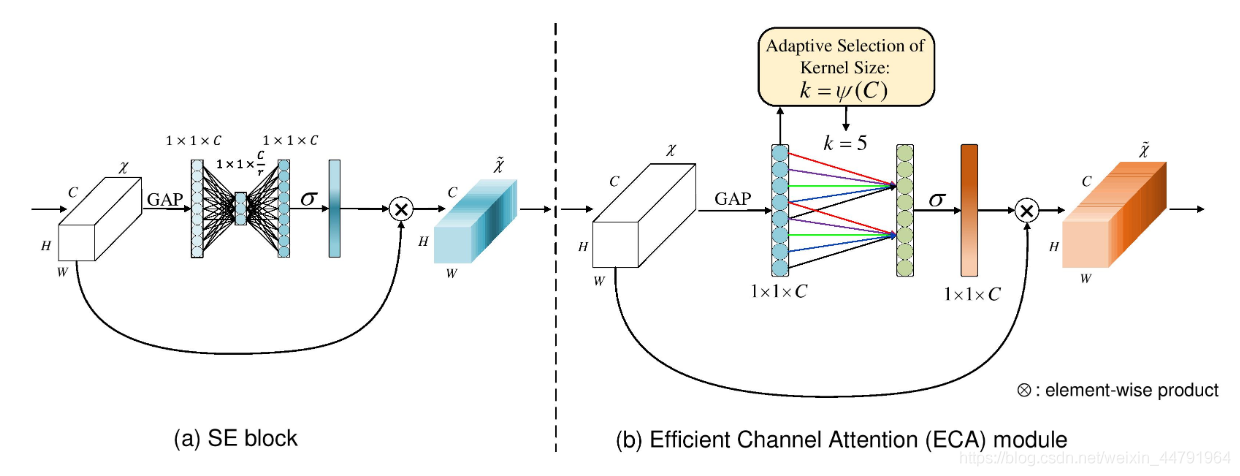
ECANet是也是通道注意力机制的一种实现形式。ECANet可以看作是SENet的改进版。
ECANet的作者认为
SENet对通道注意力机制的预测带来了副作用
,
捕获所有通道的依赖关系是低效并且是不必要的
。
在ECANet的论文中,作者认为
卷积具有良好的跨通道信息获取能力
。
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。
既然使用到了1D卷积,那么
1D卷积的卷积核大小的选择就变得非常重要了
,了解过卷积原理的同学很快就可以明白,1D卷积的卷积核大小
会影响注意力机制每个权重的计算要考虑的通道数量
。用更专业的名词就是
跨通道交互的覆盖率
。
如下图所示,左图是常规的SE模块,右图是ECA模块。ECA模块用1D卷积替换两次全连接。
实现代码如下:
def eca_block(input_feature, b=1, gamma=2, name=""):
channel = input_feature._keras_shape[-1]
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
avg_pool = GlobalAveragePooling2D()(input_feature)
x = Reshape((-1,1))(avg_pool)
x = Conv1D(1, kernel_size=kernel_size, padding="same", name = "eca_layer_"+str(name), use_bias=False,)(x)
x = Activation('sigmoid')(x)
x = Reshape((1, 1, -1))(x)
output = multiply([input_feature,x])
return output
注意力机制的应用
注意力机制是一个即插即用的模块,理论上可以放在任何一个特征层后面
,可以放在主干网络,也可以放在加强特征提取网络。
由于放置在主干会导致网络的预训练权重无法使用,本文以YoloV4-tiny为例,将注意力机制应用加强特征提取网络上。
如下图所示,我们在主干网络提取出来的
两个有效特征层上增加了注意力机制
,同时
对上采样后的结果增加了注意力机制
。

实现代码如下:
attention = [se_block, cbam_block, eca_block]
#---------------------------------------------------#
# 特征层->最后的输出
#---------------------------------------------------#
def yolo_body(input_shape, anchors_mask, num_classes, phi = 0):
inputs = Input(input_shape)
#---------------------------------------------------#
# 生成CSPdarknet53_tiny的主干模型
# feat1的shape为26,26,256
# feat2的shape为13,13,512
#---------------------------------------------------#
feat1, feat2 = darknet_body(inputs)
if phi >= 1 and phi <= 3:
feat1 = attention[phi - 1](feat1, name='feat1')
feat2 = attention[phi - 1](feat2, name='feat2')
# 13,13,512 -> 13,13,256
P5 = DarknetConv2D_BN_Leaky(256, (1,1))(feat2)
# 13,13,256 -> 13,13,512 -> 13,13,255
P5_output = DarknetConv2D_BN_Leaky(512, (3,3))(P5)
P5_output = DarknetConv2D(len(anchors_mask[0]) * (num_classes+5), (1,1))(P5_output)
# 13,13,256 -> 13,13,128 -> 26,26,128
P5_upsample = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(P5)
if phi >= 1 and phi <= 3:
P5_upsample = attention[phi - 1](P5_upsample, name='P5_upsample')
# 26,26,256 + 26,26,128 -> 26,26,384
P4 = Concatenate()([P5_upsample, feat1])
# 26,26,384 -> 26,26,256 -> 26,26,255
P4_output = DarknetConv2D_BN_Leaky(256, (3,3))(P4)
P4_output = DarknetConv2D(len(anchors_mask[1]) * (num_classes+5), (1,1))(P4_output)
return Model(inputs, [P5_output, P4_output])