**
Zero-shot learning(一):ZSL的基本概念
——-
好久没中一区论文了,在此立个旗
。今天把所有的思路整理出来,看过的论文之类的罗列出来。有错误的地方大家批评指正,内容多数是各界大牛的论文,大家一起研究。本文内容大家也可以随便转发或copy。
——-这一章都是基本概念,初学者、或者是对概念不清楚的等同行可以进来看看。基础比较深厚的可以去看后面的内容,或者不看,轻喷,以讨论为主。
——–关于小明如何认识斑马的悲惨介绍我就不说了,刚进来的同学直接参考下面这个链接吧。
https://blog.csdn.net/tianguiyuyu/article/details/81948700
https://zhuanlan.zhihu.com/p/34656727
——–这个连接就先初步的不带任何学术的让你知道什么是Zero-shot learning,同时里面还介绍了几个小小的数据集。
一、Zero-shot learning的基本概念
——-zero/one/few shot learning 是迁移学习的一种,是需要考虑源域和迁移域等问题的。
——-需要写在前面的一些小概念,方面阅读后面的文章:
类原型Class Prototypes
: 详细阅读本文
属性空间
介绍部分即可知道原型的含义。
——–Zero-shot learning依赖于存在的一组有标记的训练类,以及关于一个不可见类如何与所见类在语义上相关的知识。可见和不可见的类通常在高维向量空间中相关,称为
语义空间
,其中来自可见类的知识可以转移到不可见的类。大多数早期文章使用的
语义空间
基于语义属性。给定定义的属性本体,每个类名可以由属性向量表示,并称为
类原型
。
1.1 可见类(seen classes)和不可见类(unseen classes)
——在Zero-shot learning中,特征空间(feature space)中存在一些标记的训练实例。这些训练实例所涵盖的类称为可见类–seen classes。在特征空间中,还有一些未标记的测试实例,它们属于另一组类。这些类被称为不可见类–unseen classes。
——特征空间通常是实数空间,每个实例都表示为其中的一个向量。通常假定每个实例都属于一个类。

1.2 嵌入空间(Semantic spaces)
——语义空间包含有关类的语义信息,是zero-shot learning的重要组成部分。各种语义空间被现有的文章所使用。根据语义空间的构造方法,将其分为(1)
工程语义空间
(Engineered Semantic Spaces)和(2)
学习语义空间
(learned semantic spaces)。
Engineered Semantic Spaces
—–在工程语义空间中,语义空间的每个维度都是由人来设计的。有不同种类的工程语义空间,每一种都有一个独特的数据源和构建空间的独特方式。接下来,我们介绍了用于zero-shot learning的典型工程语义空间。
属性空间-Attribute spaces
属性空间是由一组属性构成的语义空间。它们是zero-shot learning中应用最广泛的语义空间之一。在开创性的工作中[1,2],属性空间已经被采用。在属性空间中,描述类的各种属性的术语列表被定义为属性。每个属性通常是一个单词或短语,对应于这些类的一个属性。例如,在图像中的动物识别问题中,属性可以是身体颜色(如“灰色”、“棕色”和“黄色”)或栖息地(如“海岸”、“沙漠”和“森林”)[1]。然后,这些属性用于形成
语义空间
,每个维度都是一个属性。对于每个类,对应
原型
(prototype)的每个维度的值由该类是否具有对应的属性决定。
——假设在动物识别问题中,有三个属性:“有条纹”,“生活在陆地上”和“吃植物的”。对于“虎”类,这三个属性的相应值构成
原型
[1,1,0]。 对于“马”类,相应的值形成原型[0,1,1] [1]。 在上面的例子中,属性值是
二值
的(即,0/1)。 因此,结果属性空间被称为
二值属性空间
。通常,属性值也可以是实数,表示具有属性的一个类的程度/置信度。 属性空间称为连续属性空间。 二值和连续属性空间是最常见的属性空间。 此外,还存在相对属性空间[3],其测量在不同类之间具有属性的相对程度。
词汇空间–Lexical spaces
词汇空间是由一组词汇项构造的各种语义空间。 词汇空间基于可以提供语义信息的类和数据集的标签。 数据集可以是一些结构化的词汇数据库,例如WordNet。 采用WordNet作为信息源,有不同的方法来构建语义空间。 一种方法是利用WordNet中的层次关系,例如使用所有看到和未看到的类,以及它们在WordNet中的前期版本来形成语义空间,每个维度对应于一个类[4,5]。然后,对于类
c
i
c_i
c
i
,其原型ti的第j维的值由类
c
i
c_i
c
i
和类
c
j
c_j
c
j
(第j维的对应类)之间的关系确定。 在某些方法中,如果
c
j
c_j
c
j
是
c
i
c_i
c
i
的祖先或
c
i
c_i
c
i
本身,则值为1; 否则,该值为0 [4]。 在其他方法中,该值由WordNet中
c
i
c_i
c
i
和
c
j
c_j
c
j
之间的距离确定; 距离测量可以是Jiang-Conrath距离[5],Lin距离[5],或路径长度相似度[5]。 除了层次关系之外,其他关系(如WordNet中的部分关系)也可用于形成语义空间[6]。 WordNet是一般词汇数据库的代表。在一些问题中,存在特定于问题的词汇数据库。例如,在细粒度命名实体类型[7]中,有不同实体类型的预定义树层次结构,它们用于形成语义空间。除了结构化词汇数据库,数据集还可以是一些语料库。例如,在[2]中,每个类都表示为类标签的共现向量,其中包含来自谷歌万亿单词库中最频繁的5000个单词。
文本关键字空间Text-keyword spaces
文本关键字空间是一种语义空间,由从每个类的文本描述中提取的一组关键字构成。 在文本关键字空间中,文本描述的最常见来源是网站,包括维基百科[5,8]等一般网站和特定于域的网站。 例如,在[9,10]中,由于任务是图像中的zero-shot flower识别,因此使用植物数据库和植物百科全书(其特定于植物)来获得每个花类的文本描述。 除了预定义的网站之外,还可以从搜索引擎获得这样的文本描述。 例如,在[11]中,每个类名用作Google的查询,以查找描述该类的网页。 在一些特定问题中,存在获得文本描述的特定方法。在
zero-shot video事件检测
[12]中,事件的文本描述可以从数据集中提供的事件工具包中获得。
在获得每个类的文本描述之后,下一步是构造语义空间并从这些描述中生成类原型
。 语义空间通常由从这些文本描述中提取的关键字构成,每个维度对应于关键字。 为了构建类的原型,提出了不同的方法。 对于每个文本描述,一些文章使用二进制出现指示符(binary occurrence indicator)[8]或Bag of Words(BOW)表示[5]。另一方面,一文章利用了信息检索技术(information retrieval techniques)。例如,[9,13,11]使用term frequency-inverse document frequency (TF-IDF)来表示每个类,而[10]对TF-IDF向量采用聚类潜在语义索引算法来获得降维表示向量。
一些基于特定为题的空间–Some problem-specific spaces
一些工程语义空间专门针对某些问题而设计。 例如,在zero-shot character recognition[14]中,类被限制为字母数字字符。 [14]中的语义空间由字符的“规范”表示组成,即每个字符的7×5像素图像。 在与图像分类相关的问题中,使用人眼凝视数据时[15]。 从凝视数据中提取的特征用于形成语义空间。 在计算生物学中的一些零射击学习问题中,例如在新的生物因子存在下识别分子成分是否有活性[14],生物学代理的描述用于形成语义空间。
工程嵌入空间小结
——工程语义空间的优点是通过语义空间和类原型的构建,灵活地编码人类领域知识。缺点是严重依赖人来执行语义空间和类原型工程。例如,在属性空间中,属性设计需要手工完成,这需要领域专家付出大量的努力。
学习嵌入空间—Learned Semantic Spaces
——-在学习语义空间中,空间的维度不是由人设计的。每个类的
原型Prototypes
都是从一些机器学习模型的输出中获得的。在这些原型中,每个维度都没有明确的语义。相反,语义信息包含在整个原型中。用于提取原型的模型可以在其他问题中预先训练,也可以专门针对Zero-shot learning问题进行训练。接下来,介绍zero-shot learning中典型的学习语义空间。
标签嵌入空间—Label-embedding spaces
标签嵌入空间是一类通过嵌入类标签来获得类原型的语义空间。鉴于单词嵌入技术在自然语言处理中的发展和广泛应用,本小节介绍了这种空间。在单词嵌入中,单词或短语作为向量嵌入到实数空间中。这个嵌入空间包含语义信息。在该空间中,语义相似的词或短语被嵌入到相邻的向量中,而语义不同的词或短语被嵌入到距离较远的向量中。在zero-shot learning,对于每一个class,它的class标签都是一个单词或短语。因此,它可以嵌入到一个词的嵌入空间中,以得到的对应向量为原型。在现有的文章中,采用了不同的嵌入技术,如Word2Vec[5,16, 17]和GloVe[5,17]。此外,不同的语料库,从一般的维基百科[135,144]到特定的语料库,如来自Flickr [19]的文本,已被用于学习嵌入模型。 除了为每个类生成一个原型之外,还有一些工作[20,21]为标签嵌入空间中的每个类生成多个原型。 在这些工作中,类的原型通常是遵循高斯分布的多个向量。
文本嵌入空间–Text-embedding spaces.
文本嵌入空间是一种语义空间,其中通过嵌入每个类的文本描述来获得类原型。 与文本关键字空间类似,文本嵌入空间中的语义信息也来自文本描述。 但是,这两种空间之间存在着重大差异。 具体地,通过提取关键字并将它们中的每一个用作构造空间中的维度来构造文本关键字空间。 通过一些学习模型构建文本嵌入空间。 每个类的文本描述用作学习模型的输入,输出向量被视为该类的原型。 例如,在图像对象识别任务[22]中,为每个类收集若干文本描述。 这些文本描述用作文本编码器模型的输入,输出向量被视为类原型。
图像表示空间–Image-representation spaces
图像表示空间是各种语义空间,其中类原型是从属于每个类的图像中获得的。 例如,在视频动作识别任务[23]中,通过搜索引擎获得不同动作类的图像。 然后,对于每个动作类,属于该类的图像被用作某些预训练模型的输入(例如,在ImageNet数据集上预训练的GoogLeNet)。 来自模型的输出向量被组合以形成表示向量,并且其被用作该动作类的原型。
学习嵌入空间的小节
——-学习语义空间的优势在于生成过程相对较少的人工介入,生成的语义空间包含的信息容易被人类忽略。缺点是类的原型是从一些机器学习模型中获得的,每个维度的语义都是隐式的。这样,对于人类来说,将类的领域知识合并到原型中是不方便的。
本节参考文献(参考文献后面还有内容)
[1] Christoph H. Lampert, Hannes Nickisch, and Stefan Harmeling. 2009. Learning to detect unseen object classes by between-class attribute transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’09). 951–958
[2] Mark Palatucci, Dean Pomerleau, Geoffrey Hinton, and Tom M. Mitchell. 2009. Zero-shot learning with semantic output codes. In Advances in Neural Information Processing Systems 22: 23rd Annual Conference on Neural Information Processing Systems 2009 (NIPS’09). 1410–1418.
[3] Devi Parikh and Kristen Grauman. 2011. Relative attributes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV’11). 503–510.
[4] Zeynep Akata, Florent Perronnin, Zaid Harchaoui, and Cordelia Schmid. 2016. Label-embedding for image classification.IEEE Transactions on Pattern Analysis and Machine Intelligence 38, 7 (2016), 1425–1438.
[5] Zeynep Akata, Scott Reed, DanielWalter,Honglak Lee, and Bernt Schiele. 2015. Evaluation of output embeddings for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR’15). 2927–2936.
[6] Marcus Rohrbach, Michael Stark, Gyorgy Szarvas, Iryna Gurevych, and Bernt Schiele. 2010. What helps where – and why? Semantic relatedness for knowledge transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’10). 910–917.
[7] Yukun Ma, Erik Cambria, and Sa Gao. 2016. Label embedding for zero-shot fine-grained named entity typing. In 26th International Conference on Computational Linguistics (COLING’16). 171–180.
[8] Ruizhi Qiao, Lingqiao Liu, Chunhua Shen, and Anton van den Hengel. 2016. Less is more: Zero-shot learning from online textual documents with noise suppression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’16). 2249–2257.
[9] Jimmy Lei Ba, Kevin Swersky, Sanja Fidler, and Ruslan Salakhutdinov. 2015. Predicting deep zero-shot convolutional neural networks using textual descriptions. In Proceedings of the IEEE International Conference on Computer Vision(ICCV’15). 4247–4255.
[10] Mohamed Elhoseiny, Babak Saleh, and Ahmed Elgammal. 2013. Write a classifier: Zero-shot learning using purely textual descriptions. In Proceedings of the IEEE International Conference on Computer Vision (ICCV’13). 2584–2591.
[11] Vincent W. Zheng, Derek Hao Hu, and Qiang Yang. 2009. Cross-domain activity recognition. In Proceedings of the 11th International Conference on Ubiquitous Computing (UbiComp’09). 61–70.
[12] Jeffrey Dalton, James Allan, and Pranav Mirajkar. 2013. Zero-shot video retrieval using content and concepts. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management (CIKM’13). 1857–1860.
[13] Mohamed Elhoseiny, Yizhe Zhu, Han Zhang, and Ahmed Elgammal. 2017. Link the head to the “Beak”: Zero shot learning from noisy text description at part precision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’17). 6288–6297.
[14] Hugo Larochelle, Dumitru Erhan, and Yoshua Bengio. 2008. Zero-data learning of new tasks. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (AAAI’08). 646–651.
[15] Nour Karessli, Zeynep Akata, Bernt Schiele, and Andreas Bulling. 2017. Gaze embeddings for zero-shot image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’17). 6412–6421.
[16] Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. 2011. The Caltech-UCSD Birds-200-2011 Dataset. Technical Report CNS-TR-2011-001. California Institute of Technology.
[17] Yongqin Xian, Zeynep Akata, Gaurav Sharma, Quynh Nguyen, Matthias Hein, and Bernt Schiele. 2016. Latent embeddings for zero-shot classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’16). 69–77.
[18] Richard Socher, Milind Ganjoo, Christopher D. Manning, and Andrew Y. Ng. 2013. Zero-shot learning through cross-modal transfer. In Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems (NIPS’13). 935–943.
[19] Spencer Cappallo, Thomas Mensink, and Cees G. M. Snoek. 2015. Image2Emoji: Zero-shot emoji prediction for visual media. In Proceedings of the 23rd ACM International Conference on Multimedia (MM’15). 1311–1314.
[20] Tanmoy Mukherjee and Timothy Hospedales. 2016. Gaussian visual-linguistic embedding for zero-shot recognition. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP’16). 912–918.
[21] Zhou Ren, Hailin Jin, Zhe Lin, Chen Fang, and Alan Yuille. 2016. Joint image-text representation by Gaussian visual semantic embedding. In Proceedings of the 2016 ACM Conference on Multimedia Conference (MM’16). 207–211.
[22] Scott Reed, Zeynep Akata, Honglak Lee, and Bernt Schiele. 2016. Learning deep representations of fine-grained visual descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’16). 49–58.
[23] Qian Wang and Ke Chen. 2017. Alternative semantic representations for zero-shot human action recognition. In European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECMLPKDD’17). 87–102.
二、Zero-shot learning的的方法概述
——–我们将现有的Zero-shot learning方法分为两类:
基于分类器
的方法和
基于实例
的方法。 对于基于分类器的方法,重点是如何直接学习看不见的类的分类器。 对于基于实例的方法,重点是如何获得属于看不见的类的标记实例,并将它们用于分类器学习。 接下来,我们介绍此方法层次结构中的每个类别。 在介绍这些方法时,我们主要关注Zero-shot learning的最标准数据设置。 也就是说,对于Zero-shot learning任务,考虑一个语义空间并用该空间中的一个原型表示每个类。
2.1 基于分类器的方法—Classifier-Based Methods
——–根据构造分类器的方法,将基于分类器的方法进一步划分为三类:(1)对应方法–correspondence methods、(2)关系方法–relationship methods和(3)组合方法–combination methods。现有的基于分类器的方法通常采用one-versus-rest的解决方案来学习多类zero-shot classifier
f
u
(
⋅
)
f^u(\cdot)
f
u
(
⋅
)
。也就是说,对于每个不可见的类
c
i
u
c_i^u
c
i
u
,它们学习一个二进制的one-versus- rest(一对多)分类器。我们将
f
u
(
⋅
)
:
R
D
→
f^u(\cdot):R^D\rightarrow
f
u
(
⋅
)
:
R
D
→
{0,1}表示为类
c
i
u
∈
u
c_i^u\in u
c
i
u
∈
u
的二元一对二分类器。因此,看不见的类的最终zero shot分类器
f
u
(
⋅
)
f^u(\cdot)
f
u
(
⋅
)
由
N
u
N_u
N
u
二进制组成 一对二分类{
f
u
(
⋅
)
∣
i
=
1
,
.
.
.
,
N
u
f^u(\cdot)\mid i=1,…,N_u
f
u
(
⋅
)
∣
i
=
1
,
.
.
.
,
N
u
}。
涉及该方法的部分论文(这些论文不需要全看,看看摘要,找符合自己研究方向的)
A simple exponential family framework for zero-shot learning
DeViSE: A deep visual-semantic embedding model
Label-embedding for attribute-based classification
Evaluation of output embeddings for fine-grained image classification
An embarrassingly simple approach to zero-shot learning
Deep semantic structural constraints for zero-shot learning
Latent embeddings for zero-shot classification
Zero-shot human activity recognition via nonlinear compatibility based method
Less is more: Zero-shot learning from online textual documents with noise suppression
Less is more: Zero-shot learning from online textual documents with noise suppression
2.2 基于实例的方法—Instance-Based Methods
——–基于实例的方法旨在首先获得看不见的类的标记实例,然后使用这些实例来学习zero shot分类器
f
u
(
⋅
)
f^u(\cdot)
f
u
(
⋅
)
。 根据这些实例的来源,现有的基于实例的方法可以分为三个子类别:(1)
投影方法—projection methods
,(2)
实例借用方法instance-borrowing methods
,以及(3)
合成方法–synthesizing methods
。
——–这里需要介绍一下基于投影方法的算法。它的观点是通过将
特征空间实例
和
语义空间原型
投射到公共空间中,为不可见的类获取标记的实例。
——–在特征空间中,有标记的训练实例属于所看到的类。同时,在语义空间中,既有可见类的原型,也有不可见类的原型。特征空间和语义空间都是实数空间,其中实例和原型都是向量。在这个框架中,原型也可以看作是带标签的实例。因此,我们在两个空间(特征空间X和语义空间T)中标记了实例。
在投影方法中,这两个空间中的实例被投影到一个公共空间中
。通过这种方式,我们可以获得属于不可见类的标记实例。
在本文中,我们将这个公共空间称为投影空间,记作P
。
——–投影方法的一般过程如下。 首先,特征空间X中的实例
x
i
x_i
x
i
和语义空间T中的原型
t
j
t_j
t
j
分别以投影函数
θ
(
⋅
)
θ(·)
θ
(
⋅
)
和
ξ
(
⋅
)
ξ(·)
ξ
(
⋅
)
投影到投影空间P中:
X
→
P
:
z
i
=
θ
(
x
i
)
X \to P : z_i = θ(x_i)
X
→
P
:
z
i
=
θ
(
x
i
)
T
→
P
:
b
i
=
ξ
(
t
j
)
T \to P : b_i = ξ(t_j)
T
→
P
:
b
i
=
ξ
(
t
j
)
——–然后对投影空间进行分类。
——–在投影方法中,对于每个不可见的类
c
i
u
c_i^u
c
i
u
,在特征空间中没有标记实例;因此,它在语义空间中的原型
t
i
u
t_i^u
t
i
u
是属于该类的惟一标记实例。
——–也就是说,对于每个看不见的类,只有一个标记的实例可用。 很难学习像SVM这样的分类器或逻辑回归分类器,因为看不见的类的标记实例很少。 结果,在现有的投影方法中,分类通常通过最近邻分类(1NN)或其一些变体来执行。 1NN方法可以在只有一个标记实例可用于分类所需的类的情况下工作,这适用于这种情况。 1NN方法是一种懒惰的学习方法,不需要明确的学习过程。 因此,当使用它进行分类时,不需要为看不见的类学习分类器的明确过程。 现有论文中的投影方法可以在不同的学习环境下进行。
基于实例借用的方法—Instance-Borrowing Methods
——–它的观点是通过借鉴训练实例来为不可见的类获取标记的实例。
——–实例借用方法基于类之间的相似性。 例如,在图像中的对象识别中,假设我们想要学习“卡车”类的分类器,但是没有相应的标记实例。 但是,我们有一些属于类“car”和“bus”的标记实例。因为它们是类似于“truck”的对象,当学习类“truck”的分类器时,我们可以使用属于这两个类的实例作为正实例。 这种方法遵循人类认识世界的方式[58]。 我们可能从未见过属于某些类的实例,但已经看到属于某些类似类的实例。 通过了解这些类似的类,我们能够识别属于看不见的类的实例。
——实例借用方法的一般过程如下。 首先,对于每个看不见的类
c
i
u
c_i^u
c
i
u
,来自训练实例的一些实例被借用并分配该类的标签。 然后,利用所有看不见的类的借用实例,学习看不见的类的分类器
f
u
(
⋅
)
f^u(·)
f
u
(
⋅
)
,并实现测试实例
X
t
e
X^te
X
t
e
的分类。
——–在实例借用方法中,在借用实例之前,应该确定看不见的类
U
U
U
. 只有这样,我们才能知道借用实例的类。 因此,模型的优化是针对预定的看不见的类,并且自然看不见的类原型
T
u
T^u
T
u
参与优化过程。
涉及该方法的部分论文
Zero-shot learning via semantic similarity embedding
三、总结(从网上打磨过来)的一些关于ZSL的问题
重要参考:
https://zhuanlan.zhihu.com/p/34656727
3.1 领域漂移问题(domain shift problem)
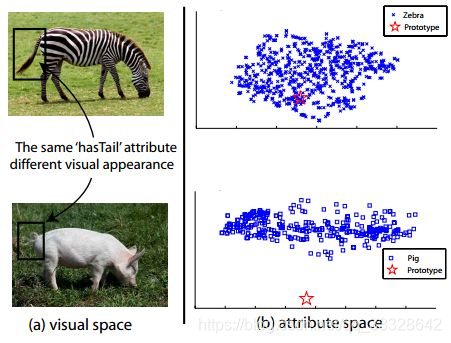
——–该问题的正式定义首先由[2]提出。简单来说,就是同一种属性,在不同的类别中,视觉特征的表现可能很大。如图所示,斑马和猪都有尾巴,因此在它的类别语义表示中,“有尾巴”这一项都是非0值,但是两者尾巴的视觉特征却相差很远。如果斑马是训练集,而猪是测试集,那么利用斑马训练出来的模型,则很难正确地对猪进行分类。
——由于样本的特征维度往往比语义的维度大,所以建立从 X 到 S 的映射往往会丢失信息,为了保留更多的信息,保持更多的丰富性,最流行的做法是将映射到语义空间中的样本,再重建回去,这样学习到的映射就能够得到保留更多的信息。因此,在原来简单岭回归[1]的基础上,可以将目标函数改为:[7]
m
i
n
∥
X
t
r
−
W
T
A
t
r
∥
2
+
λ
∥
W
X
t
r
−
A
t
r
∥
2
min\left \| X_{tr}-W^{T}A_{tr} \right \|^{2}+\lambda \left \| WX_{tr}-A_{tr} \right \|^{2}
m
i
n
∥
∥
X
t
r
−
W
T
A
t
r
∥
∥
2
+
λ
∥
W
X
t
r
−
A
t
r
∥
2
从目标函数可以看出,这其实完成的是一个简易的自编码器过程,我们简称这个算法为SAE
3.2 枢纽点问题(Hubness problem)
——–这其实是高维空间中固有的问题:在高维空间中,某些点会成为大多数点的最近邻点。这听上去有些反直观,细节方面可以参考[3]。由于ZSL在计算最终的正确率时,使用的是K-NN,所以会受到hubness problem的影响,并且[4]中,证明了基于岭回归的方法会加重hubness problem问题。
目前对于枢纽点问题的解决主要有两种方法:
a. 如果模型建立的方式为岭回归,那么可以建立从
语义空间到特征空间的映射
,从而不加深hubness problem对结果的影响[4],也就是说将目标函数(1)改为:
m
i
n
∥
X
t
r
−
A
t
r
W
∥
2
+
Ω
(
W
)
min\left \| X_{tr}-A_{tr}W \right \|^{2}+\Omega\left ( W \right )
m
i
n
∥
X
t
r
−
A
t
r
W
∥
2
+
Ω
(
W
)
b.可以使用生成模型,比如自编码器、GAN等,生成测试集的样本,这样就变成了一个传统的监督分类问题,不存在K-NN的操作,所以不存在hubness problem的影响。
3.2 语义间隔(semantic gap)
——–样本的特征往往是视觉特征,比如用深度网络提取到的特征,而语义表示却是非视觉的,这直接反应到数据上其实就是:样本在特征空间中所构成的流型与语义空间中类别构成的流型是不一致的。(如图4所示)
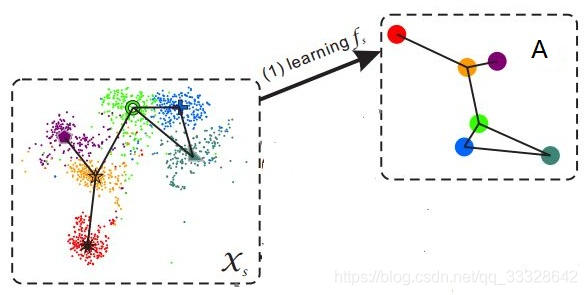
——
语义间隔问题的本质是二者的流形结构不一致,因此,解决此问题的着手点就在于将两者的流形调整到一致
,再学习两者之间的映射[8]。最简单的方法自然是将类别的语义表示调整到样本的流型上,即用类别语义表示的K近邻样本点,重新表示类别语义即可。
相关论文
[2]Transductive Multi-View Zero-Shot Learning.
[3]Hubness and Pollution: Delving into Class-Space Mapping for Zero-Shot Learning.
[4]Ridge Regression, Hubness, and Zero-Shot Learning.
[5]Zero-Shot Visual Recognition using Semantics-Preserving Adversarial Embedding Network.
[6]Zero-Shot Learning via Class-Conditioned Deep Generative Models.
[7]Semantic Autoencoder for Zero-Shot Learning.
[8]Zero-Shot Recognition using Dual Visual-Semantic Mapping Paths.
3.3 关于ZSL的研究问题
—————–我感觉上面说的这些general的问题大家都不需要深入研究了,没什么特别大意义,特别是对于小的深度学习团队,既没有算力支持,也没有算法推导支持(需要很强的数学功底),又没有工程支持(好多人代码能力不行,配环境好多人都头疼,更别说写代码了)。
—————————-个人认为,应该从实际的问题出发,分析数据,在一个小点开枝散叶,基本就够博士四五年的研究了。比如现在:…下一篇文章见刊的时候我会分享给大家的。