疫情在家,整理下以前的学习笔记, 作为linux 三个最重要的部分之一(进程,io,内存),内存管理是非常重要的,是深入理解linux各个部分的基础,linux的内存管理与其他rtos的内存管理不一样,他是一个“富” os,也就是支持很多的应用同时跑,还需要支持应用之间的内存隔离。Linux 内存不仅仅用于内存,比如作为硬盘的补充,硬盘本身也可以作为内存来使用。
- 硬件原理和分页管理
只要我们打开了MMU之后,CPU只能看到虚拟地址,最终这个虚拟地址通过MMU根据页表查询到对应的硬件地址。比如要访问虚拟地址0x1234560,其中0x560 是页内偏移, 0x1234 是页号, 比如查到0x1234 对应的物理地址是1G,CPU访问0x1234560 的时候,实际访问的是1G+0x560 的地址。

物理地址是页表下面的一个数值,所以物理地址本质上是一个整数,而不是指针。地址是以*p访问到的,其实从linux中物理地址的数据类型也可以看出来

页表除了可以查虚拟地址对应的物理地址以外,还承担了一项非常重要的权限管理(RWX),RWX指读写执行权限,对linux安全非常重要,比如代码段映射为只读读加可执行,那么无论是应用还是内核里面的任何错误行为都不会改写代码段,只要一改写硬件就会发生page fault,软件的错误行为就会被硬件拦截,硬件里面还可以管理另外一个重要的权限,当在用户态运行的时候是不能访问内核态的东西的。 在用户态的时候处于CPU的非特权模式,在32位的系统里面,3G到4G 在页表里面填的是只有在特权模式才能访问,一旦被用户模式访问,硬件就会报错,产生page fault。比如应用写一个const 变量,这个const 变量地址会映射为read-only –>wiret –> page fault–>检查illegal(writing const var)–>signal segmentatino fault –> 进程退出。
通常用户态是无法访问内核态的内容的,但是之前产生了一个熔断漏洞(meltaldown),这个漏洞为什么引起很大恐慌,因为利用这个漏洞,用户态突破了内核的界限,使得应用可以访问到内核态的内容,但是其实他并没有突破MMU的权限保护,他利用的是旁敲侧击的旁路攻击。
Meltdown 攻击的原理:
比如我们在应用程序中定义一个256个字节的数组,每个数组成员为4096 ,是为了使得每个成员隔得很远,防止CPU cache命中其他成员。k是一个内核地址,我们访问k的时候,会产生page fault,但是cpu是不会停止的,a[c]其实已经访问了,cache中命中了。此时我们还是不知道c是多少,接下来我们利用for循环把a中所有成员读一遍,看看哪个成员访问最快,结果发现就a[c] 比较快,其他都很慢,说明k里面的内容就c。这就是基于时间的旁路攻击。Meltdown 硬件从头到尾都没有让你真正读到,我们基于时间探测,推测出去。

这种旁路攻击很常见,比如以前我们破解用户名和密码,我们用破解软件尝试各种用户名,一般用户名不匹配就直接返回错误,不会check 密码,当用户名对的时候,就会去check 密码,这样我们查询突然有一个用户名返回时间比较久,说明这个用户是正确的用户名,再去尝试不同的密码,从而通过旁路攻击找到正确的用户名和密码。
内存zone
从上面我们知道内存是按照一页页进行管理,之所以按照页进行管理是因为MMU在管理内存按照页管理,linux还有一个概念叫做分zone。对于一个典型的32位系统按照下面分zone:
X86 平台入下图:arm 会不一样,因为arm里面32M的调用是短跳转,超过32M就是长跳转,开销大,3G-16M就是内核空间, 3G-16M 3G-2M之间就是内核用来放内核模块的,内核的代码又再3G – 3G+6M 之间。
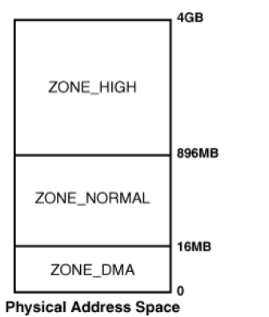
DMA 是可以不需要CPU干预直接访问内存。为什么有个DMA zone,这个其实是历史遗漏原因,有一些比较老的外设(DMA有缺陷的)的地址总线只能范围32M的内存,所以DMA ZONE 存在的目的是保证内存一定是在32M或者更小的内存区域,从而保证DMA总线能够正常访问内存。这种硬件申请DMA zone的内存需要带一个GFP_DMA 标记,没有缺陷的硬件就不需要这个标记。现在的很多arm芯片,里面的外设控制器都没有这样的缺陷,所以很多情况下都不需要定义DMA zone。

还有一个high memory zone,为什么又这个HIGH ZONE ,在一个典型的32位系统 3G-4G 是内核空间, 0-3G是用户空间,内核空间总共只有1G,linux开机的时候会把做一个一一映射到内核空间,比如内存条有4G,怎么访问到所有的内存呢? linux 就创造了一个high memory。DMA zone NORMAL ZONE 都是低端内存,剩余的HIGH ZONE 就是高端内存。低端内存都是开机线性映射的,可以通过phys_to_virt 或者virt_to_phys 就可以访问。高端内存是运行时决定映射到哪个位置的,他不是线性映射,所以不能使用上的两个apis。 内核一般不从high memory 申请,因为内核使用的内存有限,一般normal内存就够了,但是应用程序一般是先从high memory 里面找,没有再从normal memory ,还没有再从dma zone ,按照这个顺序。对于arm 内核如果非要使用high memory ,一般映射到3G-2M 到3G的虚拟机中访问。
Buddy算法:
上面讲的每个zone使用管理算法都是Buddy算法,Buddy是按照2的n次方去管理内存的。这种算法牛在任何正整数都可以差分为2的n次方的和,所有linux最底层的算法一定都来自buddy(alloc_pages get_free_pages


buddy包含所有内存的使用情况,所有我们再proc/budyinfo 里面就可以查看这些信息

对于64位的处理器里面是没有low memory和high memory 的概念,因为64 位的处理,寻址空间2的64次方,可以映射到所有的内存,所以所有的内存都可以在内核里面线性映射。
Buddy 算法是用于自洽的,但是他有一个问题,他跑着跑着就跑散了,也就是内核碎片,就可能存在一个问题,比如电脑有100M的空闲内存,比如你需要16M的连续内存可能申请不到了,谁会需要连续的内存,应用程序只需要虚拟连续就可以了,只有DMA引擎 需要连续的内存,可是内存都散了,申请16M的连续内存可能就失败了。所以在工程上,一般的做法是直接预留内存(存在一定的乱费)。而更高级的做法是CMA的方式。

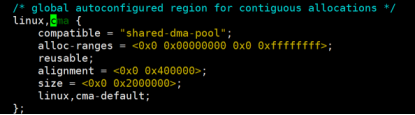
CMA 最早是三星公司提交的patch,CMA可以是的这些CMA区域(dts里面通常可以指定)的内存平时分配给应用程序使用,应用程序的内存一般是movable 的,当摄像头的DMA 需要申请连续内存的时候,就需要把应用程序的占用的CMA的内存挤走,就导出申请小的4k页,接着把应用程序占用CMA区域内容调到新申请的4k页中,接着改下应用程序的页表,这样应用程序察觉不到内存发生变化,从而预留出足够的CMA连续内存给摄像头使用了。这就是CMA算法巧妙的地方,这样即不乱费内存,有不影响DMA 使用。