背景
做公司项目(线上为tf1),为了更方便训练模型以及涉及到公司建议新项目使用TF2.*的大环境下,因此接手项目期间间均在TF2环境下训练模型和推断。
我的项目需要tf1和tf2模型共存在同一个环境中,这种情况下仅使用tf2的兼容无法实现。
问题
-
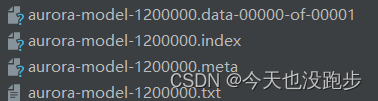
tf1保存的网络模型和权重如图所示(使用tf.Saver)
- tf2环境推断tf1模型并加载 tf1权重(restore)时,需要加入下面两行代码才可加载:
import tensorflow._api.v2.compat.v1 as tf
tf.disable_v2_behavior()
其中第一行代码为TF2兼容TF1设计,这行代码对TF2模型无影响,但是第二行代码,会禁用TF2很多功能,包含eager模式,因此在推断TF2模型时,会报以下错误,提示前后的Graph不一致:
ValueError: Tensor("Identity:0", dtype=float32) must be from the same graph as Tensor("kick_res/conv_block/conv2d/kernel:0", shape=(), dtype=resource) (graphs are <tensorflow.python.framework.ops.Graph object at 0x0000022D30B0C048> and <tensorflow.python.framework.ops.Graph object at 0x0000022D36754B70>).
- 尝试在tf2模型推断前加入:tf.compat.v1.enable_eager_execution(),仍然报错:
<class 'tensorflow.python.framework.ops.EagerTensor'>
An op outside of the function building code is being passed a "Graph" tensor. It is possible to have Graph tensors leak out of the function building context by including a tf.init_scope in your function building code.
解决方案:
将上述的文件转为pb格式,pb文件同时保存了网络和权重,并将图中的变量值以常量的形式保存(冻结),因此不存在图的加载。同时该文件也具有不同平台的移植性。
1.将meta文件转为pb格式
# _*_coding:utf-8_*_
import tensorflow as tf
from tensorflow.python.framework import graph_util
def freeze_graph(input_checkpoint, output_graph):
'''
:param input_checkpoint:
:param output_graph: PB 模型保存路径
:return:
'''
# 检查目录下ckpt文件状态是否可用
# checkpoint = tf.train.get_checkpoint_state(model_folder)
# 得ckpt文件路径
# input_checkpoint = checkpoint.model_checkpoint_path
# 指定输出的节点名称,该节点名称必须是元模型中存在的节点
output_node_names = "Add_12"
saver = tf.train.import_meta_graph(input_checkpoint + '.meta', clear_devices=True)
graph = tf.get_default_graph() # 获得默认的图
input_graph_def = graph.as_graph_def() # 返回一个序列化的图代表当前的图
with tf.Session() as sess:
saver.restore(sess, input_checkpoint) # 恢复图并得到数据
# 模型持久化,将变量值固定
output_graph_def = graph_util.convert_variables_to_constants(
sess=sess,
# 等于:sess.graph_def
input_graph_def=input_graph_def,
# 如果有多个输出节点,以逗号隔开
output_node_names=output_node_names.split(","))
# 保存模型
with tf.gfile.GFile(output_graph, "wb") as f:
f.write(output_graph_def.SerializeToString()) # 序列化输出
# 得到当前图有几个操作节点
print("%d ops in the final graph." % len(output_graph_def.node))
# 输入ckpt模型路径
input_checkpoint = './aurora-model-1200000'
# 输出pb模型的路径
out_pb_path = "models/frozen_model.pb"
# 调用freeze_graph将ckpt转为pb
freeze_graph(input_checkpoint, out_pb_path)
-
输出节点名称,分为两种情况
:- 输出节点训练时候定义占位符名称:此时直接赋值给output_node_names变量即可。
-
输出节点训练时候未定义占位符:我的项目情况是输出节点训练时候未定义占位符,该情况下建议:
-1)推断时可以打印输出变量,此时会输出节点的名字会显示(“Add_12”)
-2)使用tensorboard查看网络结构,找最终的输出节点,可采用下面代码保存图结构:
ckpt = './aurora-model-150000'
import tensorflow as tf
from tensorflow.summary import FileWriter
sess = tf.Session()
tf.train.import_meta_graph(ckpt + '.meta')
FileWriter("__tb", sess.graph)
-
最终网络权重以及变量的文件 保存在单个文件中,即pb文件
:
2.使用pb文件推断(TF2.*环境),此方法无需定义网络结构,因此可以与TF2模型共存:
import tensorflow._api.v2.compat.v1 as tf
# pb文件目录
path = 'models/frozen_model.pb'
# 网络输入
rnn_status = np.transpose(rnn_status, (1, 2, 0))
rnn_status = np.expand_dims(rnn_status, 0)
# 推断
with tf.Graph().as_default():
output_graph_def = tf.GraphDef()
with open(path, "rb") as f:
output_graph_def.ParseFromString(f.read())
tf.import_graph_def(output_graph_def, name="")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 定义输入的张量名称,对应网络结构的输入张量
input_image_tensor = sess.graph.get_tensor_by_name("IteratorGetNext:0")
Placeholder_tensor = sess.graph.get_tensor_by_name("Placeholder:0")
# 定义输出的张量名称
output_tensor_name = sess.graph.get_tensor_by_name("Add_12:0")
out = sess.run(output_tensor_name, feed_dict={input_image_tensor: rnn_status, Placeholder_tensor: False})
print("out:{}".format(out))
-
查找输入张量名称的方式(上面feed_dict的参数):
首先打断点查看图中所有节点:sess.graph._nodes_by_name,基本上输入节点是前几个节点
然后打印每个节点值:sess.graph.get_tensor_by_name(
节点.name
),维度与输入一致即为输入节点。
版权声明:本文为www22691原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。