环境及基础:
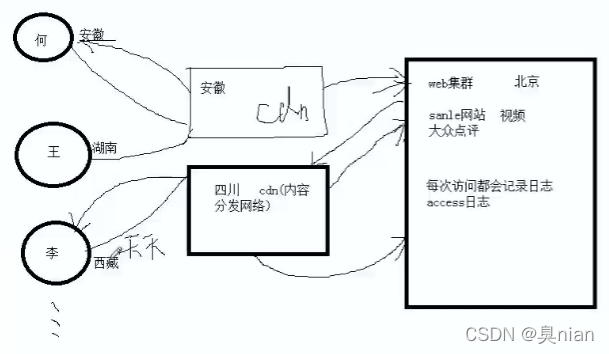
web集群:实现web功能的很多台机器
每次访问都会记录日志(access 日志)
cdn:内容分发网络(Content Delivery Network),也就是缓存,有的话直接返回,没有的话就回源,把它缓存下来,下次访问就快了
cdn的日志可以定时同步到总部的日志里面去
无论写代码还是做架构,没有什么问题是加入中间层解决不了的!!!!
一般会是去购买cdn服务(cdn按流量计费)
带宽的95值:也就是最小带宽到最大带宽的百分之九十五的位置
若是cdn出错 可以多个节点 或者访问原站
若是cdn出错,监控访问日志看访问量(过大或过小)就可以明显看出了
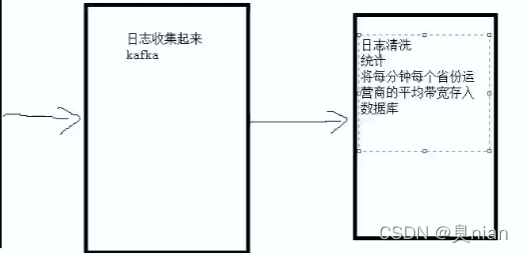
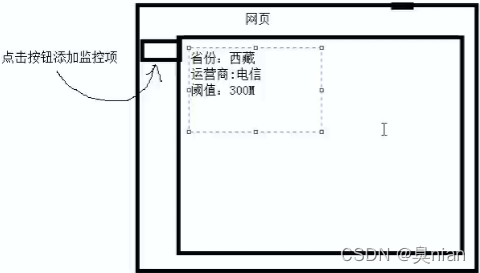
监控:(数据从MySQL来) flask框架(把数据和页面连接起来)
整个项目:
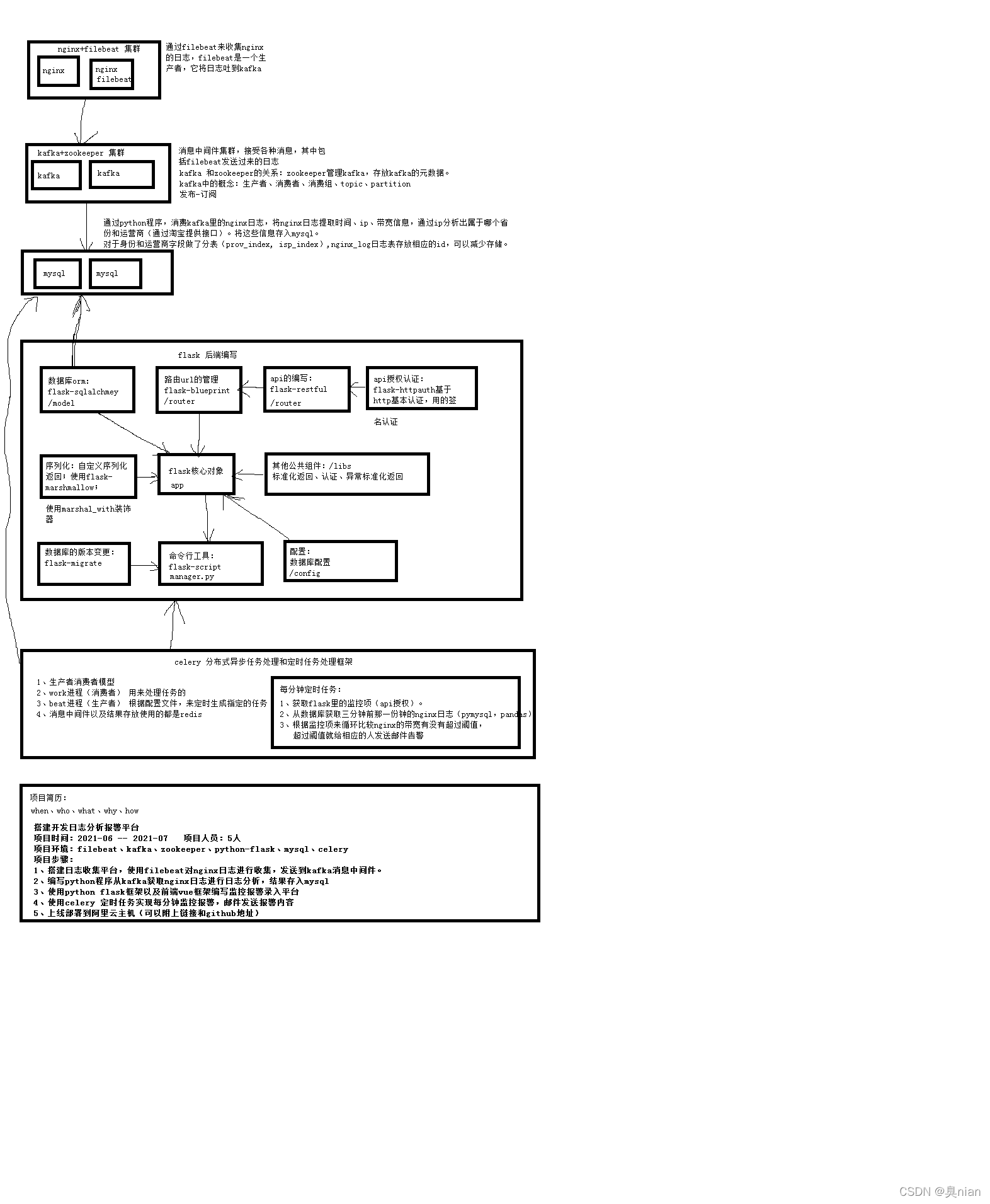
Kafka架构图:
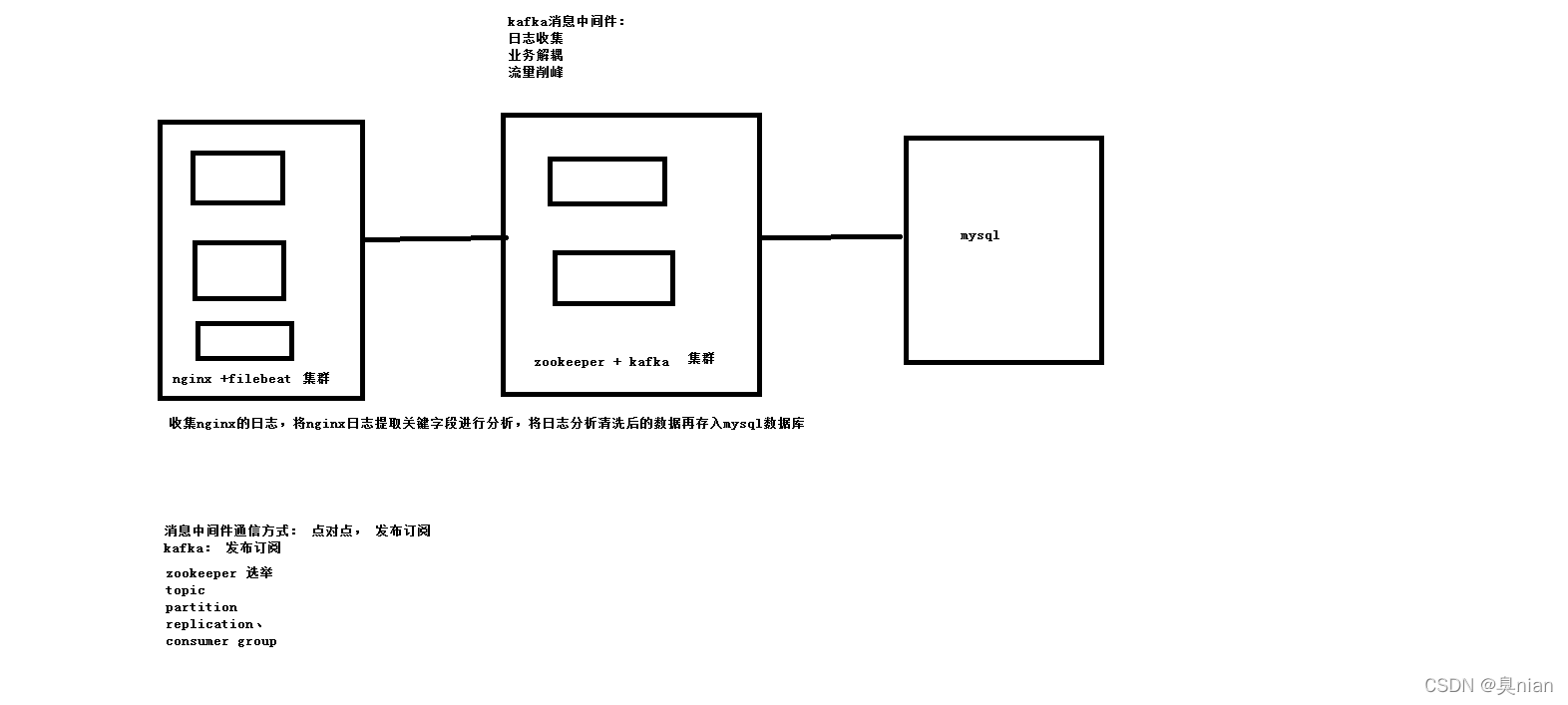
filebeat监控nginx acces.log日志变化
然后输出到kafka集群
而我们需要写python程序,消费kafka日志,进行清洗结算,将结果写入mysql
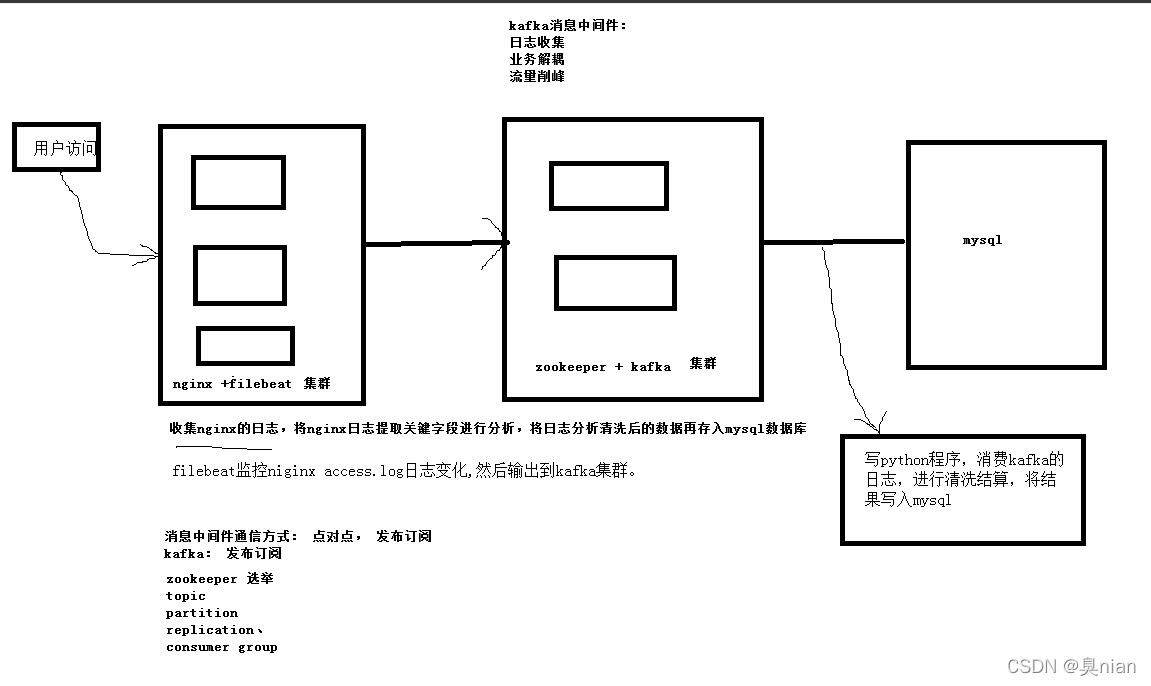
kafka一般称之为 消息中间件(中间件:与你的主体业务没有太多的关联 并不能为你创造直观的价值 只是在中间起到其他的作用)
其他消息中间件:redis rebbitmq nsq
#生产者 消费者模型(计算机里面的通用模型)
增加一个仓库(中间件)
消息中间件的作用(应用)(包括kafka):
1.实现了业务的解耦
–边缘业务运行失败不会影响核心业务
–方便某个组件扩展其他东西
2.流量削峰(如双十一 或者抢红包)
3.日志收集
flask是框架
下面的flask是生产者 发邮件就变成了消费者(实现了业务的解耦)
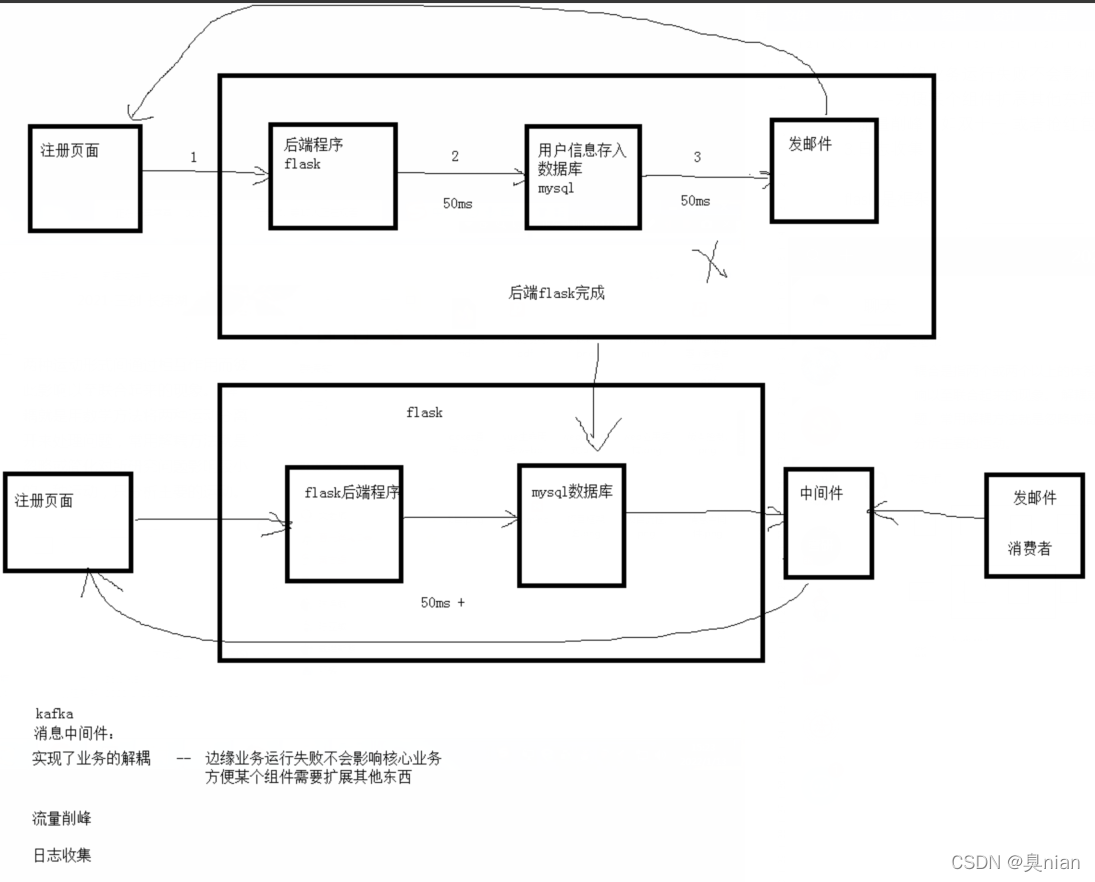
为什么我们这个项目要引入kafka?
1.解耦 防止处理程序的出错影响到核心业务(如是web访问不了)
2.集中存放任意程序里面的所有的日志 方便查看和分析(如nginx tomcat mysql等 不用一台一台机器去翻找)
3.因为大家都在用 想学习一下
消息的传递方式:
点对点:一对一 生产者消费者一一对应,消费者消费完,消息中间件就没有了
发布-订阅:可以多个消费者公用且各个消费者相互独立
会记录每个消费者的状态(kafka一般用发布-订阅的消息传递方式)
kafka的专业术语:
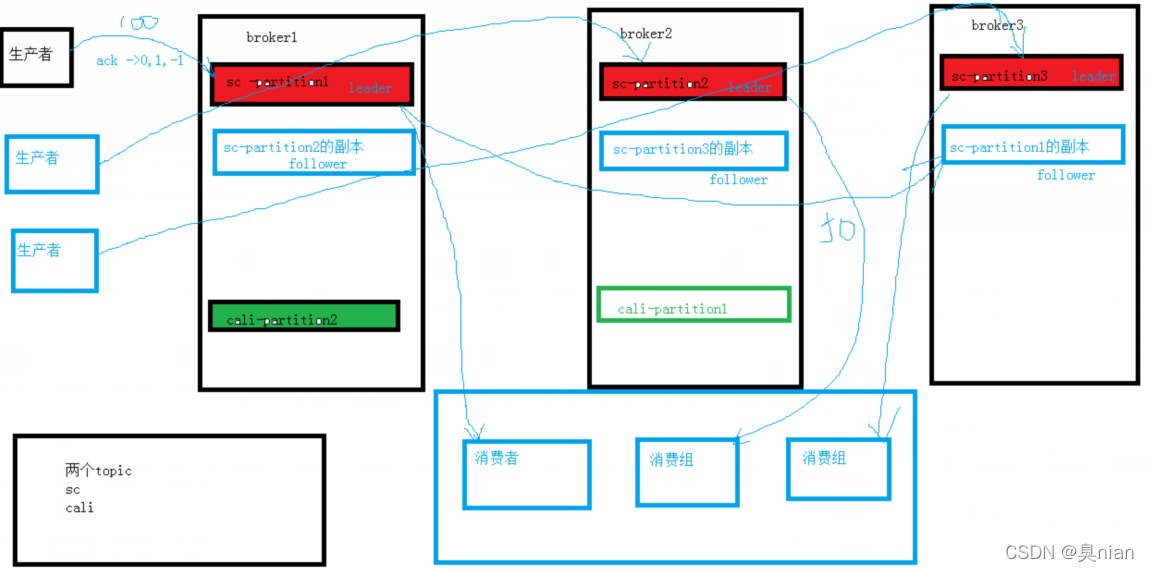
broker:kafka集群包括一个或多个服务器,服务器节点称为broker(如我们这个项目就三个broker)
topic:消息的类别
partition:分区 相当于消息的容器 提高吞吐量 提高效率
(一般你有几个broker就设置几个partition)
partition支持并发的读写
有多个partition的话,消息的顺序总体来说就跟别人不一样了,但在单独的partition里面还是顺序的
每个分区都有一个leader
producer:生产者 扔数据的 (生产者写入数据时会有一个ack标志位0 1 -1 写入时会得到响应)
consumer:消费者 读数据的
(消费组:多个消费者组成一个大的消费组 提高吞吐量 一般跟partition数量保持一致)
replicas:副本
(kafka消息高可用的最基本原理)
(针对partition的)
(指定2 则代表除了本身还有一个副本)
(所以partition也可以叫做副本 所以副本需要通过副本选举算法来选举leader 消费者生产者会往leader里面写入或读取数据 其他的副本叫做follower 只是备份 如果leader有问题了 就会重新选举)
(leader和follower会保持一致)
消息必须要创建了topic才能存储
一般来说 partition是平均分布的
Leader选举参考网站:
kafka知识体系-kafka leader选举 – aidodoo – 博客园
DNS:域名系统(Domain Name System,缩写:DNS)是
互联网
的一项服务。它作为将
域名
和
IP地址
相互
映射
的一个
分布式数据库
,能够使人更方便地访问
互联网
。
为什么选择这个项目?
-
实验室老师
-
师哥师姐
这里ack这个标志位不叫ack 只是生产者里面的配置
0:生产者只管发 不管服务器有没有发消息
1:只leader同步成功的消息 生产者会收到服务器的响应
如果消息无法到达leader节点(例如leader节点崩溃,新的leader节点还没有被选举出来)生产者就会收到一个错误响应,为了避免数据丢失,生产者会重发消息
如果一个没有收到消息的节点成为新leader,消息还是会丢失
-1:生产者要得到所有的副本(包括follower)都成功写入的反馈之后 才继续发
ISR:(in-sync-replica)相当于一个集合列表 需要同步的follower集合
比如说有5个副本,1个leader 4follower(follower都放在ISR里面)
有一条消息来了,leader怎么知道要同步哪些副本呢?
根据ISR来,如果一个follower挂了,那就从这个列表删除了
如果一个follower卡住或者过慢,它也会从ISR里删除,甚至可以删除为0,不会重新创建follower
kafka不保证数据是绝对一致的
kafka是如何保证高可用的(挂掉之后不影响运转)?
多个broker 多个partition 多个replica
kafka如何保证数据一致性?
更具request.required.acks的选择来看
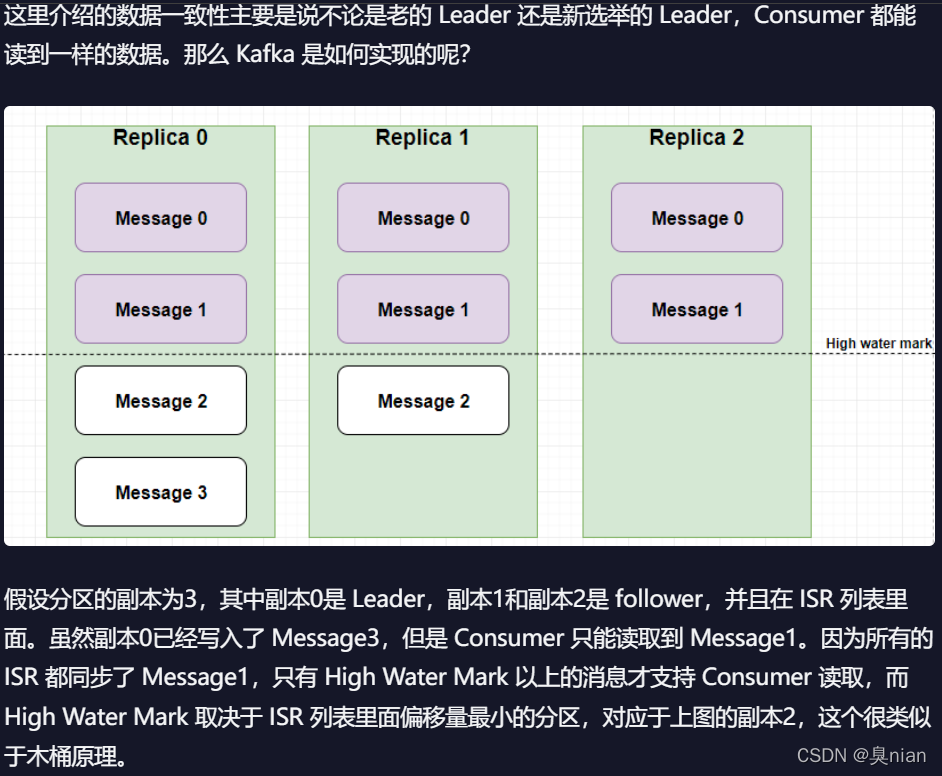
消费者的offest(偏移量):每消费一条就会记录一个偏移量
[root@kafka-3 ~]# cat install_kafka.sh
#!/bin/bash
#需要提前修改好每台服务器的名字,例如kafka-1 kafka-2 kafka-3
hostnamectl set-hostname kafka-1 #第1台机器的名字 ,以此类推,在第2台上执行脚本前,修改名字为kafka-2 ,第3台修改为kafka-3
#修改/etc/hosts文件,添加3台kafka服务器的ip对应的名字
cat >>/etc/hosts <<EOF
192.168.0.190 kafka-1
192.168.0.191 kafka-2
192.168.0.192 kafka-3
EOF
#安装软件,解决依赖关系
yum install wget lsof vim -y
#安装时间同步服务
yum install chrony -y
systemctl enable chronyd
systemctl start chronyd
#设置时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#关闭selinux
setenforce 0
sed -i ‘/^SELINUX=/ s/enforcing/disabled/’ /etc/selinux/config
安装的时候 只要看到glibc就不要退出 否则会down
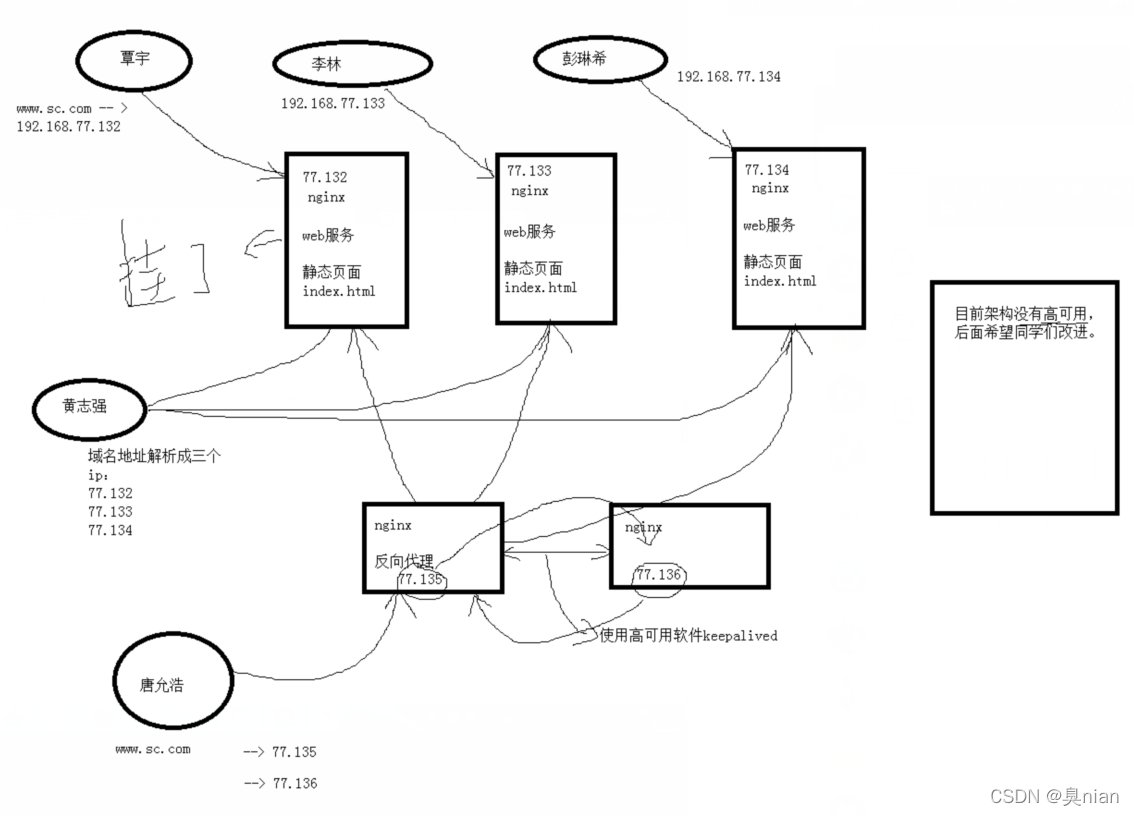
现在nginx只是提供web服务 提供了静态界面
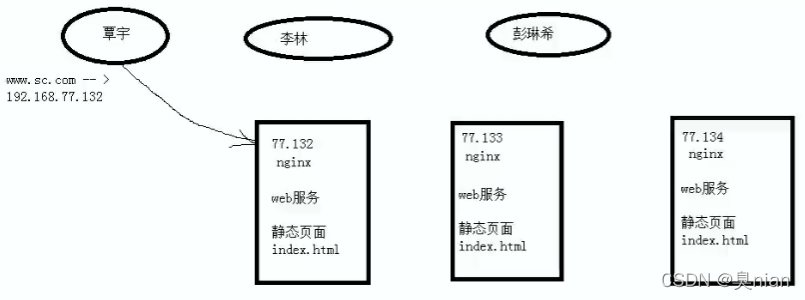
客户端(覃宇)连接域名
www.sc.com
若域名地址随机解析IP 解析到哪一台就连的哪一台
(若其中一台服务器挂了 刚好客户端连过来 也有可能访问不到页面 故目前页面没有高可用)
负载均衡器:load barancer 用来调度
调度算法:轮询(round rinbin 简称rr) 任何机器都是一视同仁
轮询里面有个加权轮询(加了一个weight:权重值,也就是不一视同仁 有权重值)
IP哈希:根据IP地址做哈希值
最小连接数:手里活少多派活 手里活多少干活
所有连接进出都要连接中间件 本质就是NAT连接 (full NAT)
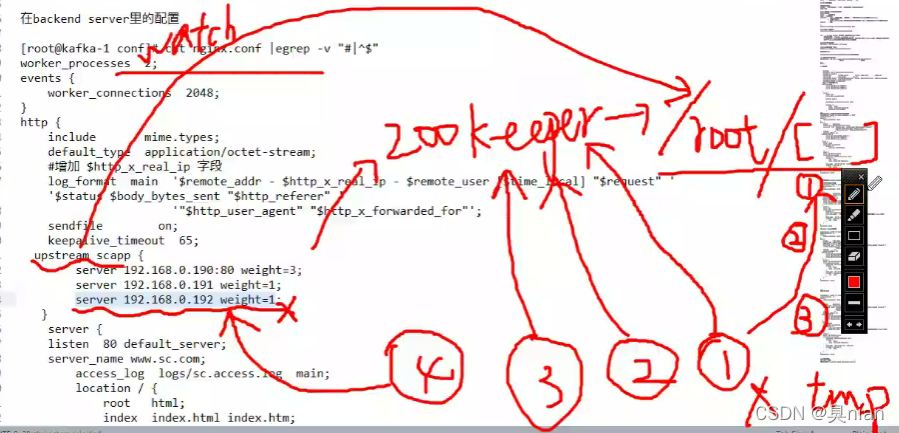
我们这次用的中间件是nginx
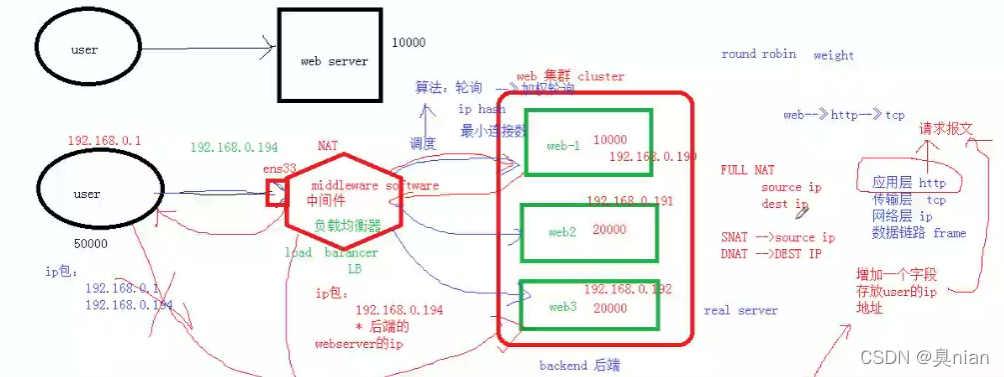
但是后面服务器的机器(backend 后端 real server 服务器)收不到user的IP地址
所以我们必须得加个模块保留user的IP地址 才能记录日志(在HTTP里面的请求报文增加一个可选首部字段保留原来的源IP地址)(中间件来操作这个过程)
scp:远程拷贝文件和文件名
scp 文件(传文件夹加-r) IP地址:路径 把这个文件推送到相应IP地址的相应路径
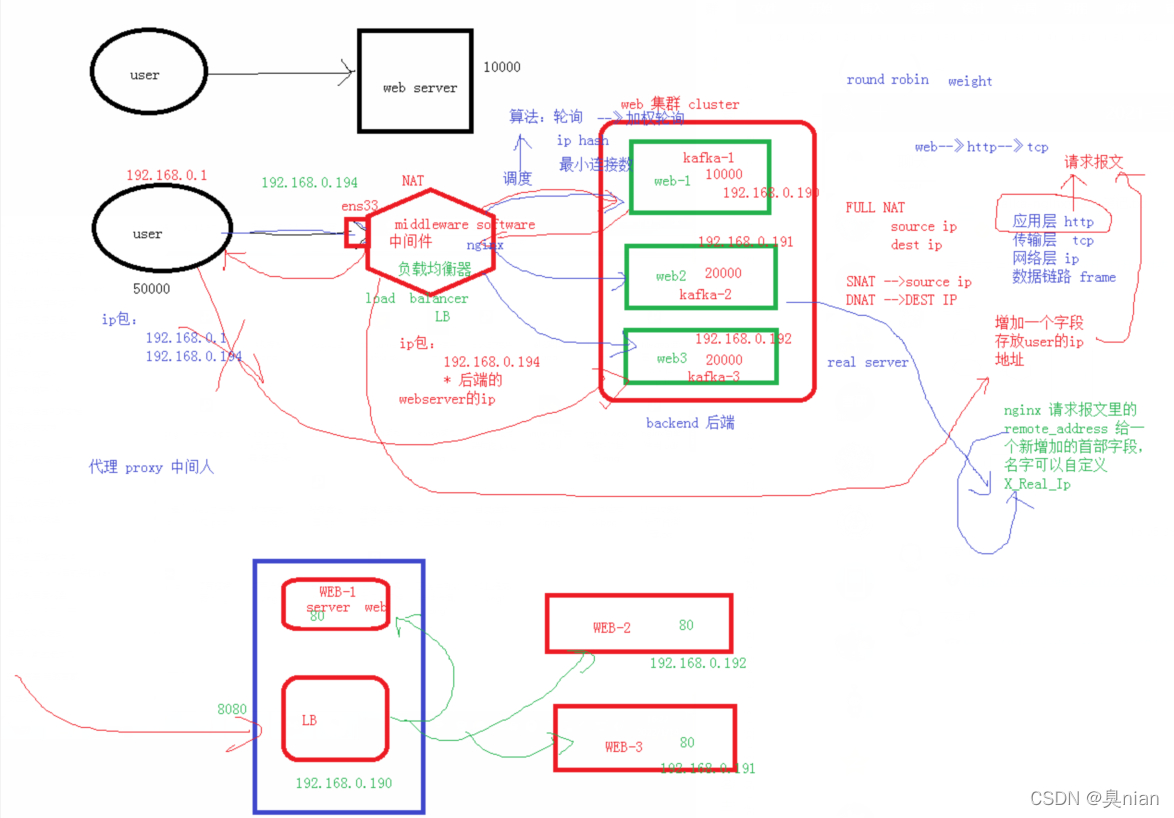
这个中间nginx两个功能:
-
负载均衡
修改配置文件 在http模块里加个负载均衡器(upstream):
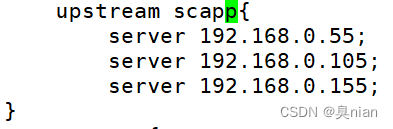
默认为轮询
而加权轮询就是在后面加weight (默认为1)

然后注释掉自己的页面 添加转发功能
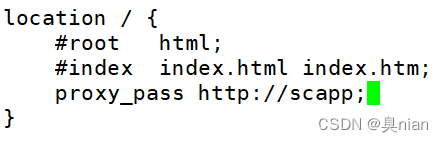
(这样后端服务的机器得到的源地址都是中间件的IP)
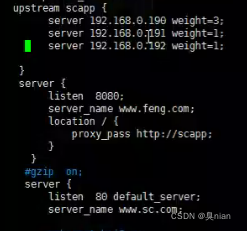
也可以把负载均衡放在kafka同一台机器上,配置一个虚拟主机就好:
加一个server和upstream
端口设置不一样就好了
-
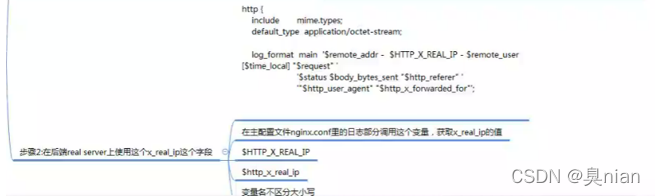
让后端的real server(backend)知道最前端的user的IP
rginx请求报文里的remote_address给一个新增加的首部字段 名字可以自定义,不能使用下划线(x-real-ip)

目前架构还是没有高可用
因为如果这个反向代理机器挂掉了还是会全盘崩掉 故我们后续使用一个高可用软件keepalived来实现高可用
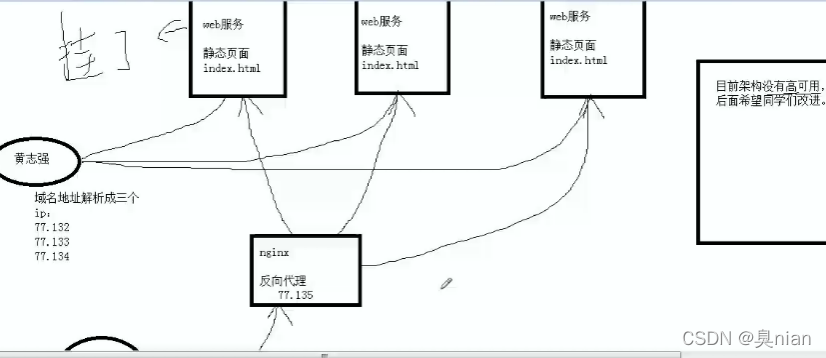
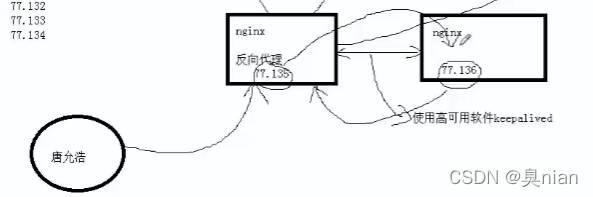
Nginx现在的架构
真实中最好kafka和nginx分开装
![]()
文件夹详解:
bin可执行文件
conf配置文件(.cfg就代表主配置文件)
docs文档
lib库
logs日志
zookeeper和kafka是两个完全不同的服务
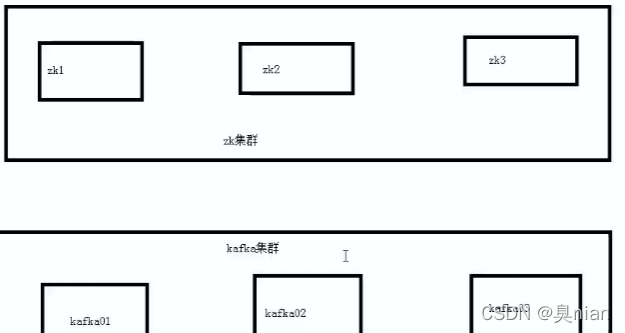
Zookeeper里面:
指定数据目录
![]()
指定端口号:
![]()
申明集群 1号主机 2号主机 3号主机
(.1 .2 .3是集群里面的唯一标识 不可以重复)
后面两个都是端口 一个用于数据传输 一个用于检验存活性和选举

代表往任意一个主机里面写数据 数据都会同步
查看日志:
vim zookeeper-root-server-nginx-kafka03.out
zookeeper集群里面也会选举:
一致性算法:raft
(选举原则:少数服从多数 票数超过半数以上才能当选成功)
(一般来说机器都是单数)
机器存活一定要超过半数
三个人进行协商 看谁投票谁 少数服从多数 选出候选人 (机器挂了也算一票 所以三台机器只能死一台 否则就达不到半数以上的条件了)
partition:针对topic的分区
tmux同步的效果
CTRL+B+: 多窗口同步
![]()
开启同步
![]()
取消同步
开启的时候 要先启动zk 在启动kafka
关闭服务的时候 先关kafka 再关zk
kafka配置文件
![]()
broker.id是broker 的唯一标识
zk的三个端口:
2181 提供服务(client访问)
下面是集群之间通信的 2888:3888
2888提供选举存活检测
3888提供数据交互
以守护进程去启动kafka:
bin/kafka-server-start.sh -daemon config/server.properties
停止kafka:
![]()
bin/kafka-topics.sh –create –zookeeper 192.168.0.95:2181 –replication-factor(指定副本数量) 1 –partitions 1 –topic sc
![]()
这套架构生产者是filebeat 消费者是我们主机写的python程序
Kafka数据会落地到磁盘上(/tmp/kadka-logs)
Kafka的日志可以按照两个维度来设置清除
按时间 默认是7天
按大小

任意一个按时间或者按大小的条件满足,都可以出发日志清理
segment:kafka日志保存时按段保存的 这样才能分时间和大小
命名时按照现在在哪个地方顺序存储的
假设有如下segment
00.log 11.log 22.log
00.log保存的时0-11条的日志
11.log保存的时12-22条的日志
22.log保存的时第22条之后的日志
Kafka创建生产者消费者的信息都在zk里面
连接zk:
![]()
Zookeeper是一个分布式的开源的配置管理服务
(一个文件树里面保存了很多信息 很多主机去监视这个文件树)
(upstream的信息从zookeeper里面去拿)
Zk里面进文件就是ls 绝对路径
看文件里面的数据 就是 get 绝对路径
zk里面的主题信息:
![]()
__consumer_offsets:保存的是消费者的偏移量
消费者消费完成之后,会有一个偏移量的设置,偏移量可以就保存在消费者本地,也可以保存至kafka服务端,保存在kafka服务端的话,存放__consumer_offests组里面 (默认给你分了50个分区)
Zk作用:
保留kafka的元数据(topic 副本等信息)
选举controller(选举一个kafka整个集群的controller 这个controller来协调副本的leader,follower选举)(这个controller是根据抢占的方式进行选举 先到先得 /controller)
于是这个版本的kafka不能脱离zookeeper
生产者发送消息的时候随机挑选任意一台都可以,会有协商,这个broker会返回给你副本leader的信息,生产者后续跟leader交互
退出之后直接进入tmux上一次状态
tmux ls
tmux a -t 0
beats:这是一组收集传输信息的工具
beats家族的六种工具:(都是elk架构的一员)

Filebeat:用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将他们转发到相应的位置 如:elasticsearch redeis kafka等
会为每一个监控的文件都开启一个harvester
Input组件是告知要监视哪一个文件,并为每一个文件都启动一个Harvester

Logstach(用Java写的):收集和过滤的工具
Filebeat:

rpm -qa是查看本机上安装的所有的软件
rpm 也是linux里的一个软件管理的命令 -q query a all
rpm -ql filebeat 查看filebeat安装到了哪里去了 牵扯的文件有哪些
![]()
这个配置文件为yml格式,完全不能错!!!
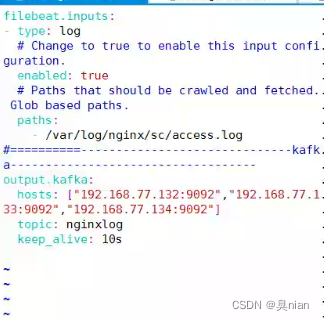
数据目录和日志目录
![]()

Fealbeat配置文件里的目录支持通配符
Kafka底层通过主机名进行通信
Zk默认的窗口是2181
生产者一致性是看ack
消费者一致性保持,是看最高水位线 也就是木桶效应
Filebeat就是生产者
Python程序就是消费者了
Python操纵kafka:Pykafka模块 自己写消费者,最后打印出我们拿到的日志message的信息
(我们现在用的消费者都是测试工具)