为什么需要文件预读机制?
算法磁盘I/O性能的发展远远滞后于CPU和内存,因而成为现代计算机系统的一个主要瓶颈。预读可以有效的减少磁盘的寻道次数和应用程序的I/O等待时间,是改进磁盘读I/O性能的重要优化手段之一。
从寄存器、L1/L2高速缓存、内存、闪存,到磁盘/光盘/磁带/存储网络,计算机的各级存储器硬件组成了一个金字塔结构。越是底层存储容量越大。然而访问速度也越慢,具体表现为更小的带宽和更大的延迟。因而这很自然的便成为一个金字塔形的逐层缓存结构。由此产生了三类基本的缓存管理和优化问题:
预取(prefetching)算法,从慢速存储中加载数据到缓存;
替换(replacement)算法,从缓存中丢弃无用数据;
写回(writeback)算法,把脏数据从缓存中保存到慢速存储。
其中的预取算法,在磁盘这一层次尤为重要。磁盘的机械臂+旋转盘片的数据定位与读取方式,决定了它最突出的性能特点:擅长顺序读写,不善于随机I/O,I/O延迟非常大。由此而产生了两个方面的预读需求。
来自磁盘的需求
简单的说,磁盘的一个典型I/O操作由两个阶段组成:
1. 数据定位
平均定位时间主要由两部分组成:平均寻道时间和平均转动延迟。寻道时间的典型值是4.6ms。转动延迟则取决于磁盘的转速:普通7200RPM桌面硬盘的转动延迟是4.2ms,而高端10000RPM的是3ms。这些数字多年来一直徘徊不前,大概今后也无法有大的改善了。在下文中,我们不妨使用 8ms作为典型定位时间。
2. 数据传输
持续传输率主要取决于盘片的转速(线速度)和存储密度,最新的典型值为80MB/s。虽然磁盘转速难以提高,但是存储密度却在逐年改善。巨磁阻、垂直磁记录等一系列新技术的采用,不但大大提高了磁盘容量,也同时带来了更高的持续传输率。
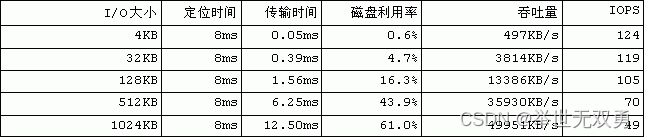
显然,I/O的粒度越大,传输时间在总时间中的比重就会越大,因而磁盘利用率和吞吐量就会越大。简单的估算结果如表所示。如果进行大量4KB的随机I/O,那么磁盘在99%以上的时间内都在忙着定位,单个磁盘的吞吐量不到500KB/s。但是当I/O大小达到1MB的时候,吞吐量可接近50MB /s。由此可见,采用更大的I/O粒度,可以把磁盘的利用效率和吞吐量提高整整100倍。因而必须尽一切可能避免小尺寸I/O,这正是预读算法所要做的。
来自程序的需求
应用程序处理数据的一个典型流程是这样的:while(!done) { read(); compute(); }。假设这个循环要重复5次,总共处理5批数据,则程序运行的时序图可能如图1所示。

不难看出,磁盘和CPU是在交替忙碌:当进行磁盘I/O的时候,CPU在等待;当CPU在计算和处理数据时,磁盘是空闲的。那么是不是可以让两者流水线作业,以便加快程序的执行速度?预读可以帮助达成这一目标。基本的方法是,当CPU开始处理第1批数据的时候,由内核的预读机制预加载下一批数据。这时候的预读是在后台异步进行的,如图所示。

注意,在这里我们并没有改变应用程序的行为:程序的下一个读请求仍然是在处理完当前的数据之后才发出的。只是这时候的被请求的数据可能已经在内核缓存中了,无须等待,直接就能复制过来用。在这里,异步预读的功能是对上层应用程序“隐藏”磁盘I/O的大延迟。虽然延迟事实上仍然存在,但是应用程序看不到了,因而运行的更流畅。
预读的概念
预取算法的涵义和应用非常广泛。它存在于CPU、硬盘、内核、应用程序以及网络的各个层次。预取有两种方案:启发性的(heuristic prefetching)和知情的(informed prefetching)。前者自动自发的进行预读决策,对上层应用是透明的,但是对算法的要求较高,存在命中率的问题;后者则简单的提供API接口,而由上层程序给予明确的预读指示。在磁盘这个层次,Linux为我们提供了三个API接口:posix_fadvise(2), readahead(2), madvise(2)。
不过真正使用上述预读API的应用程序并不多见:因为一般情况下,内核中的启发式算法工作的很好。预读(readahead)算法预测即将访问的页面,并提前把它们批量的读入缓存。
它的主要功能和任务可以用三个关键词来概括:
-
批量,也就是把小I/O聚集为大I/O,以改善磁盘的利用率,提升系统的吞吐量。
-
提前,也就是对应用程序隐藏磁盘的I/O延迟,以加快程序运行。
-
预测,这是预读算法的核心任务。前两个功能的达成都有赖于准确的预测能力。当前包括Linux、FreeBSD和Solaris等主流操作系统都遵循了一个简单有效的原则:把读模式分为随机读和顺序读两大类,并只对顺序读进行预读。这一原则相对保守,但是可以保证很高的预读命中率,同时有效率/覆盖率也很好。因为顺序读是最简单而普遍的,而随机读在内核来说也确实是难以预测的。
Linux的预读架构
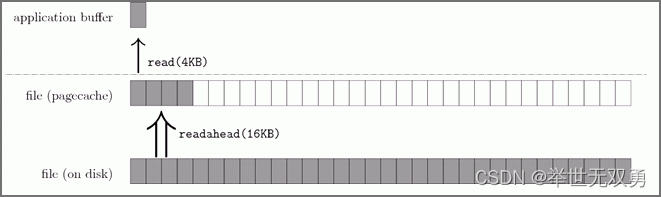
Linux内核的一大特色就是支持最多的文件系统,并拥有一个虚拟文件系统(VFS)层。早在2002年,也就是2.5内核的开发过程中,Andrew Morton在VFS层引入了文件预读的基本框架,以统一支持各个文件系统。如图所示,Linux内核会将它最近访问过的文件页面缓存在内存中一段时间,这个文件缓存被称为pagecache。如图所示。一般的read()操作发生在应用程序提供的缓冲区与pagecache之间。而预读算法则负责填充这个pagecache。应用程序的读缓存一般都比较小,比如文件拷贝命令cp的读写粒度就是4KB;内核的预读算法则会以它认为更合适的大小进行预读 I/O,比比如16-128KB。
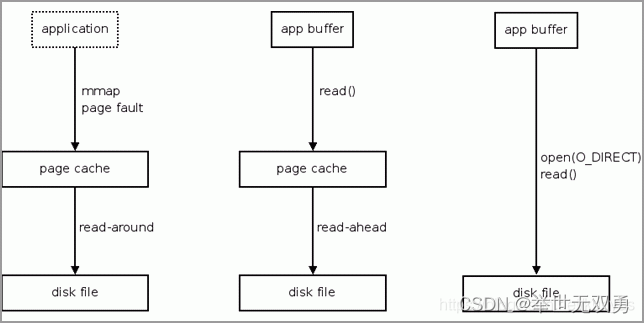
大约一年之后,Linus Torvalds把mmap缺页I/O的预取算法单独列出,从而形成了read-around/read-ahead两个独立算法(图4)。read- around算法适用于那些以mmap方式访问的程序代码和数据,它们具有很强的局域性(locality of reference)特征。当有缺页事件发生时,它以当前页面为中心,往前往后预取共计128KB页面。而readahead算法主要针对read()系统调用,它们一般都具有很好的顺序特性。但是随机和非典型的读取模式也大量存在,因而readahead算法必须具有很好的智能和适应性。
又过了一年,通过Steven Pratt、Ram Pai等人的大量工作,readahead算法进一步完善。其中最重要的一点是实现了对随机读的完好支持。随机读在数据库应用中处于非常突出的地位。在此之前,预读算法以离散的读页面位置作为输入,一个多页面的随机读会触发“顺序预读”。这导致了预读I/O数的增加和命中率的下降。改进后的算法通过监控所有完整的read()调用,同时得到读请求的页面偏移量和数量,因而能够更好的区分顺序读和随机读。