操作步骤:
准备工作:一台虚拟机(Centos 7),虚拟机已安装好jdk。
1、首先使用Xftp将
hadoop-2.6.0-cdh5.14.2.tar.gz
包放入 /opt/install文件夹下,
install文件夹需要自己新建一下,参考命令
mkdir install

2、输入命令
tar -zxvf hadoop-2.6.0-cdh5.14.2.tar.gz -C ../soft
-C用于指定目录,操作完成后,进入soft目录下查看

名字太长不方便以后使用,我们修改一下文件名
mv hadoop-2.6.0-cdh5.14.2/ hadoop260

3、接下来去添加环境变量,首先先查看一下当前路径。
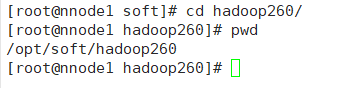
记住这个路径
/opt/soft/hadoop260
,然后进入/etc/profile 添加环境变量

添加完成之后,source一下。

然后输入hadoop来检查一下。
如果出现这个样子,恭喜你 环境变量配置正确。
4、接着我们进入 etc/hadoop目录下修改一些配置文件(注意是etc/hadoop,不是我们常用的那个/etc 两个不是一个路径)
首先
vim ./hadoop-env.sh
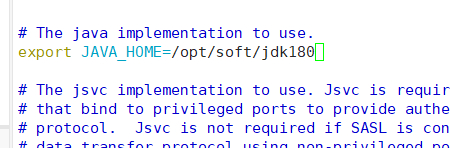
在这一行输入jdk安装路径。
mapred-env.sh 和 yarn-env.sh 也是同理
vim ./mapred-env.sh
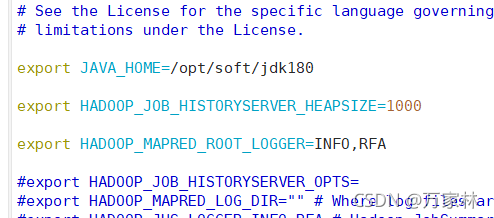
接着修改配置文件。
vim core-site.xml
<configuration>
<property>
<!-- HDFS namenode地址 -->
<name>fs.defaultFS</name>
<value>hdfs://nnode1:9000</value>
</property>
<property>
<!-- HADOOP 运行时存储路径 -->
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop260/hadooptmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<!-- 设置hadoop存储文件的副本数,默认3份 -->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- secondary设置 -->
<name>dfs.namenode.secondary.http.address</name>
<value>nnode1:50090</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nnode1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nnode1:19888</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!-- reducer获取数据的方式 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!-- 指定YARN的resourceManager的地址 -->
<name>yarn.resourcemanager.hostname</name>
<value>nnode1</value>
</property>
<property>
<!-- 日志聚集功能 -->
<name>yarn.log.aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 设置日志记录保留天数为7天 -->
<name>yarn.log.aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
修改一些 slaves 的主机名
vim ./slaves
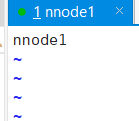
接着重头戏来了,初始化Hadoop
hadoop namenode -format
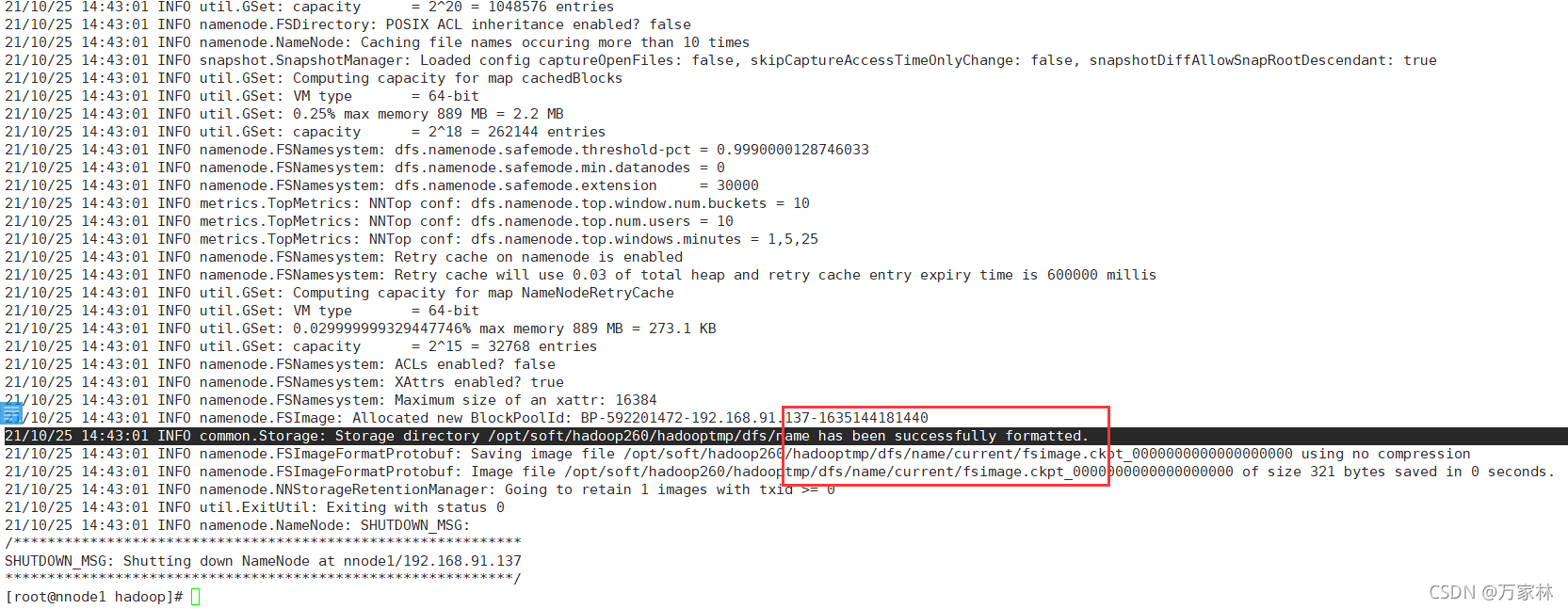
显示
has been successfully formatted.
就说明初始化成功了。
hadoop-daemon.sh start/stop namenode
启动或关闭namenode
hadoop-daemon.sh start/stop secondarynamenode
启动或关闭secondarynamenode
启动yarn资源管理器
start-yarn.sh
启动或关闭nodemanager
yarn-daemon.sh start/stop nodemanager
启动或关闭resourcemanager
yarn-daemon.sh start/stop resourcemanager
启动jobhistory
mr-jobhistory-daemon.sh start historyserver
好了,接着送上终极命令
start-all.sh
stop-all.sh
使用jps查看一下当前进程
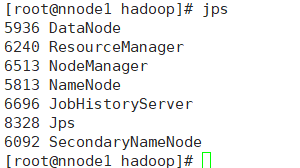
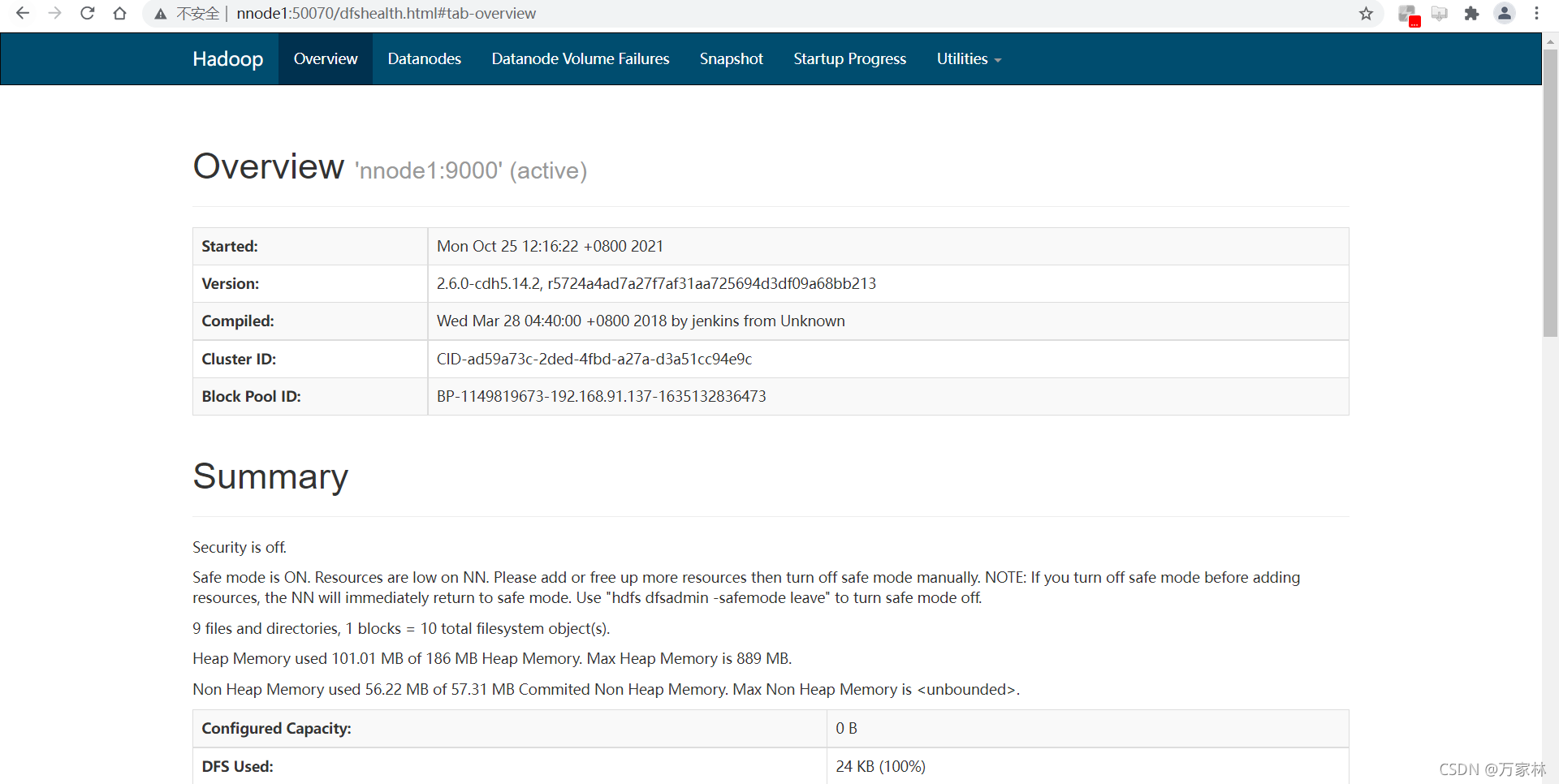
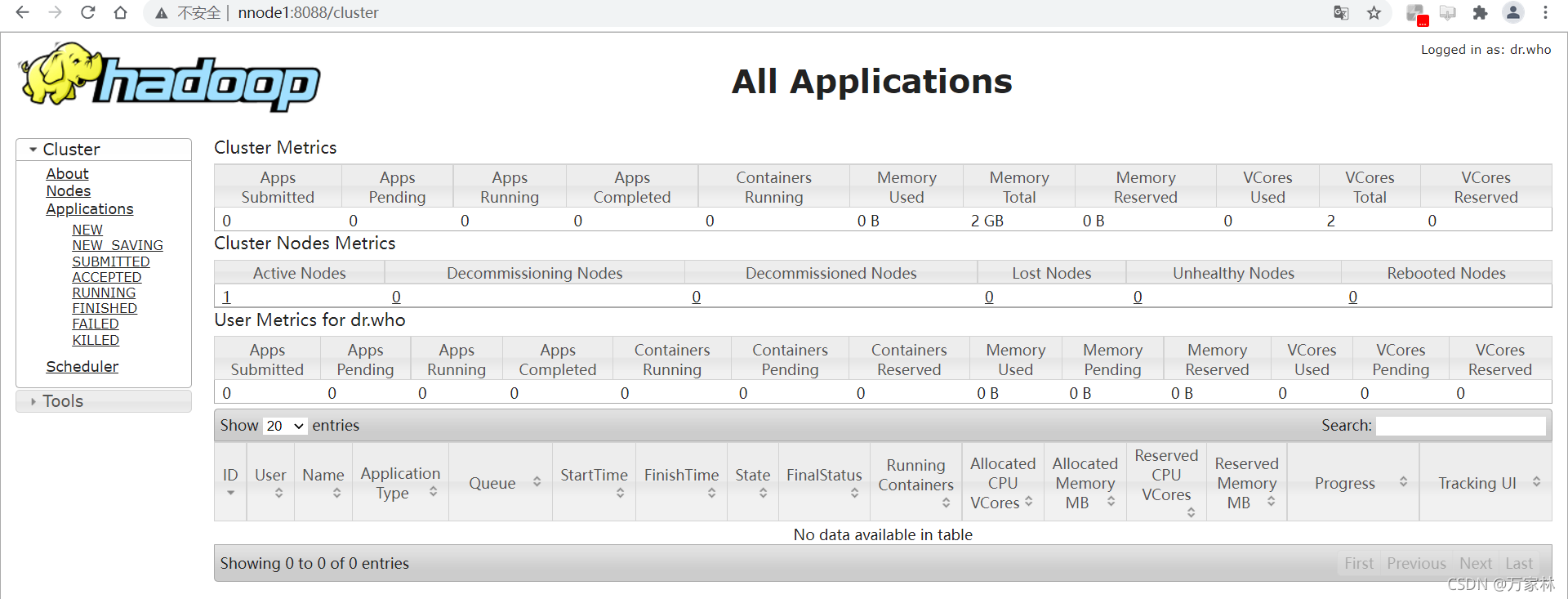
至此,配置完成。谢谢观看,互相学习共同进步。