
http://shift-alt-ctrl.iteye.com/blog/2378868 (laoda.toutiao.im)
ActiveMQ是最常用、特性最丰富的消息中间件,通常用于消息异步通信、调用解耦等多种场景,是JMS规范的实现者之一。
一、架构设计概要
ActiveMQ提供两种可供实施的架构模型:“M-S”和“network bridge”;其中“M-S”是HA方案,“网络转发桥”用于实现“分布式队列”。
1、M-S
Master-Slave模型下,通常需要2+个ActiveMQ实例,任何时候只有一个实例为Master,向Client提供”生产”、“消费”服务,Slaves用于做backup或者等待Failover时角色接管。
M-S模型是最通用的架构模型,它提供了“高可用”特性,当Master失效后,Slaves之一提升为master继续提供服务,且Failover之后消息仍然可以恢复。(根据底层存储不同,有可能会有消息的丢失)
1)M-S架构中,设计到选举问题,选举的首要条件就是需要有“排它锁”的支持。排它锁,可以有共享文件锁、JDBC数据库排它锁、JDBC锁租约、zookeeper分布式锁等方式实现。这取决你的底层存储的机制。
2)M-S架构中,消息存储的机制有多种,“共享文件存储”、“JDBC”存储、“非共享存储”等。不同存储机制,各有优缺点。
2、网络转发桥(network bridge)
无论如何,一组M-S所能承载的消息量、Client并发级别总是有限的,当我们的消息规模达到单机的上限时,我们应该基于集群的方式,将消息、Client进行分布式和负载均衡。ActiveMQ提供了“网络转发桥”模式,核心思想是:集群中多个broker之间,通过“连接”互相通信,并将消息在多个Broker之间转发和存储,提供存储层面的“负载均衡”,以及根据Client的并发情况,对Client进行动态平衡,最终实现支持大规模生产者、消费者。
二、M-S架构设计详解
1、非共享存储模式
集群中有2+个ActiveMQ实例,每个实例单独存储数据,Master将消息保存在本地后,并将消息异步的方式转发给Slaves。
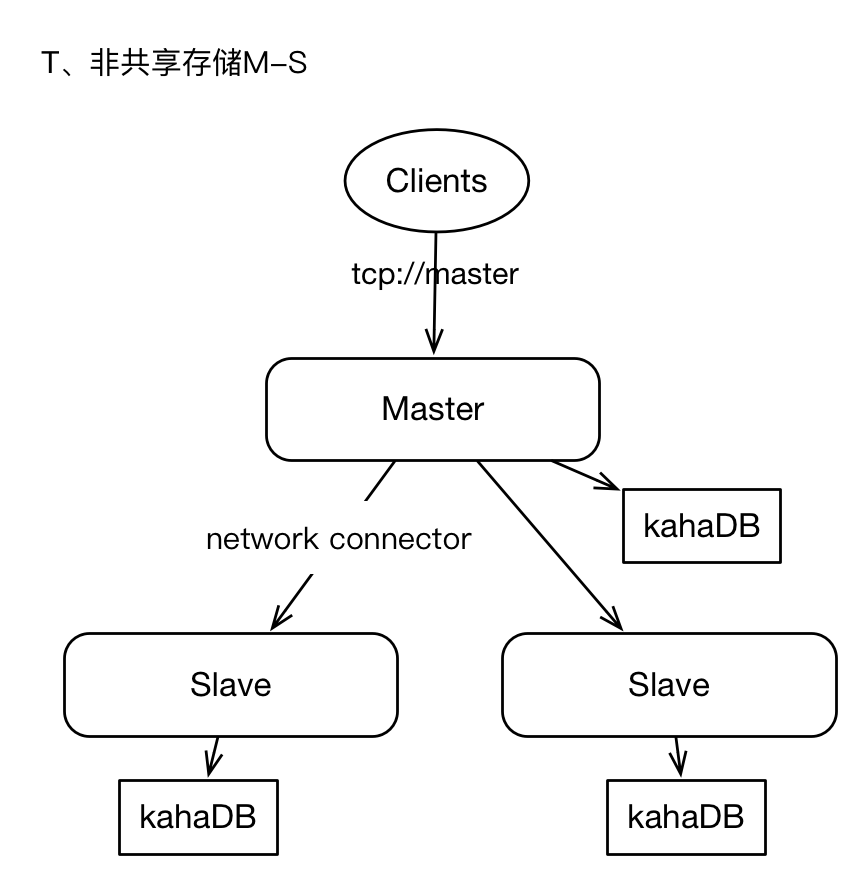
Master和slaves独立部署,各自负责存储,Master与slaves之间通过“network connector”连接,通常是Master单项与slaves建立连接。master上接收到的消息将会全量转发给slaves。
1)任何时候只有Master向Clients提供服务,slaves仅作backup。
2)slaves上存储的消息,有短暂的延迟。
3)master永远是master,当master失效时,我们不能随意进行角色切换,最佳实施方式就是重启master,只有当master物理失效时才会考虑将slave提升为master。
4)当slaves需要提升为master时,应该确保此slaves的消息是最新的。
5)如果slaves离线,那么在重启slaves之前,还应该将master的数据手动同步给slaves。否则slave离线期间的数据,将不会在slaves上复现。
6)Client端不支持failover协议;即Client只会与master建立连接。
这种架构,是最原始的架构,易于实时,但是问题比较严重,缺乏Failover机制,消息的可靠性我们无法完全保障,因为master与slaves角色切换没有仲裁者、或者说缺少分布式排它锁机制。
在Production环境中,不建议采用,如果你能容忍failover期间SLA水平降级的话,也可以作为备选。
2、共享文件存储
即采用SAN(GFS)技术,基于网络的全局共享文件系统模式,这种架构简单易用,
但是可架构、可设计的能力较弱,在Production环境下也可以采用
。
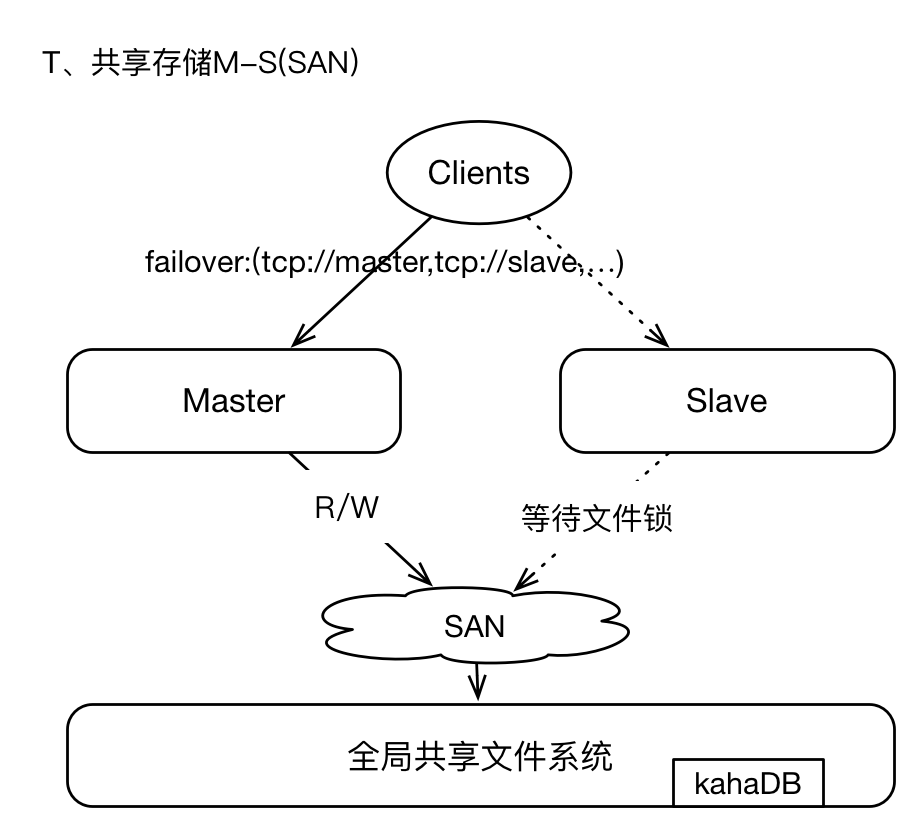
SAN存储,可以参考GFS。其中master和slaves配置保持一致,每个broker都需要有唯一的brokerName;broker实例在启动时首先通过SAN获取文件系统的排它锁,获取lock的实例将成为master,其他brokers将等待lock、并间歇性的尝试获取锁,slaves不提供Clients服务;因为brokers将数据写入GFS,所以在failover之后,新的master获取的数据视图仍然与原master保持一致,毕竟GFS是全局的共享文件系统。
我们通常使用kahaDB作为存储引擎,即使用日志文件方式;kahaDB的存储效率非常的高,TPS可以高达2W左右,是一种高效的、数据恢复能力强的存储机制。
这种架构模式下,支持failover,当master失效后,Clients能够通过failover协议与新的master重连,服务中断时间很短。因为基于GFS存储,所以数据总是保存在远端共享存储区域,所以不存在数据丢失的问题。
唯一的问题,就是GFS(SAN)的稳定性问题。这一点需要确定,SAN区域中的节点之间网络通信必须稳定且高效。
3、基于JDBC共享存储
我们可以将支持JDBC的数据库作为共享存储层,即master将数据写入数据库,本地不保存任何数据,在failover期间,slave提升为master之后,新master即可从数据库中读取数据,这也意味着在整个周期中,master与slaves的数据视图是一致的(同SAN架构),所以数据的恢复能力和一致性是可以保障的,也不存在数据丢失的情况(在存储层)。
但是我们需要知道JDBC存储机制,性能较低,与kahaDB这种基于日志存储层相比,性能相差近10倍左右。
如果你的业务需求,表明数据丢失是难以容忍的、且SLA水平很高,那么JDBC或许是你最好的选择。
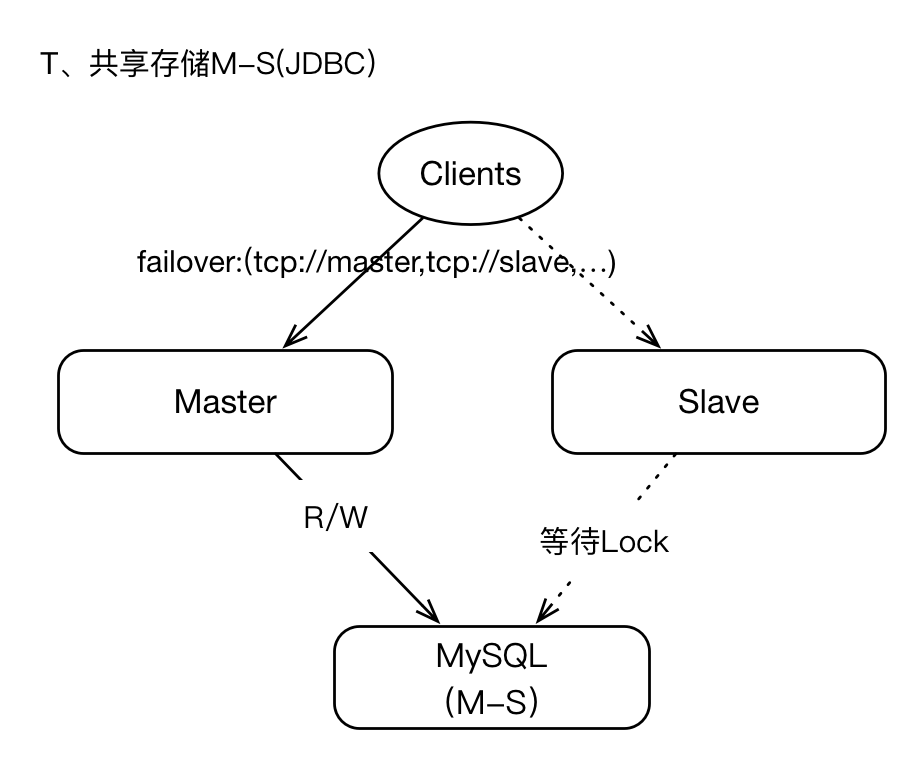
既然JDBC数据库为最终存储层,那么我们很多时候需要关注数据库的可用性问题,比如数据库基于M-S模式等;如果数据库失效,将导致ActiveMQ集群不可用。
三、network bridges模式架构
这种架构模式,主要是应对大规模Clients、高密度的消息增量的场景;它将以集群的模式,承载较大数据量的应用。
1)有大量Producers、Consumers客户端接入。只所以如此,或许是因为消息通道(Topic,Queue)在水平扩张的方向上,已经没有太大的拆分可能性。
2)或许消息的增量,是很庞大的,特别是一些“非持久化消息”。
我们寄希望于构建“分布式队列”架构
。
3)因为集群规模较大,我们可能允许集群某些节点短暂的离线,但数据恢复机制仍然需要提供,总体而言,集群仍然提供较高的可用性。
4)集群支持Clients的负载均衡,比如有多个producers时,这些producers会被动态的在多个brokers之间平衡。
5)支持failover,即当某个broker失效时,Clients可以与其他brokers重连;当集群中有的新的brokers加入时,集群的拓扑也可以动态的通知给Clients。
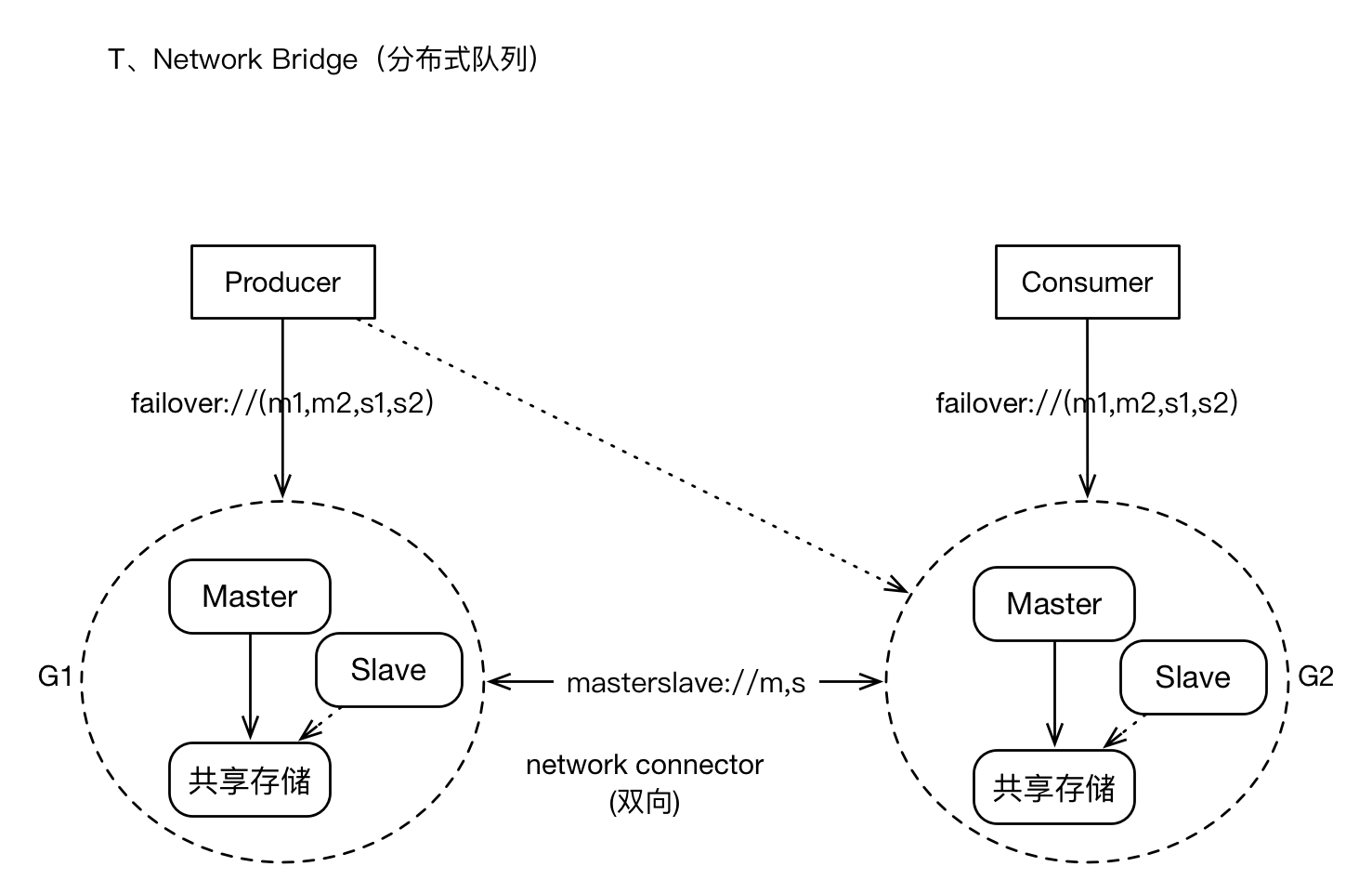
集群有多个子Groups构成,每个Group为M-S模式、共享存储;多个Groups之间基于“network Connector”建立连接(masterslave协议),通常为双向连接,所有的Groups之间彼此相连,Groups之间形成“订阅”关系,比如G2在逻辑上为G1的订阅者(订阅的策略是根据各个Broker上消费者的Destination列表进行分类),消息的转发原理也是基于此。对于Client而言,仍然支持failover,failover协议中可以包含集群中“多数派”的节点地址。
对于Topic订阅者的消息,将会在所有Group中复制存储,对弈Queue的消息,将会在brokers之间转发,并最终到达Consumer所在的节点。
Producers和Consumers可以与任何Group中的Master建立连接并进行消息通信,当Brokers集群拓扑变化时、Producers或Consumers的个数变化时,将会动态平衡Clients的连接位置。Brokers之间通过“advisory”机制来同步Clients的连接信息,比如新的Consumers加入,Broker将会发送advisory消息(内部的通道)通知其他brokers。
集群模式提供了较好的可用性担保能力,在某些特性上或许需要权衡,比如Queue消息的有序性将会打破,因为同一个Queue的多个Consumer可能位于不同的Group上,如果某个Group实现,那么保存在其上的消息只有当其恢复后才能对Clients可见。
“网络转发桥”集群模式,构建复杂,维护成本高,可以在Production环境中使用。
四、性能评估
综上所述,在Production环境中,我们能够真正意义上采用的架构,只有三种:
1)基于JDBC的共享数据库模式:HA架构,单一Group,Group中包含一个master和任意多个slaves;所有Brokers之间通过远端共享数据库存取数据。对客户端而言支持Failover协议。
2)基于Network Bridge构建分布式消息集群:Cluster架构,集群中有多个Group,每个Group均为M-S架构、基于共享存储;对于Clients而言,支持负载均衡和Failover;消息从Producer出发,到达Broker节点,Broker根据“集群中Consumers分布”,将消息转发给Consumers所在的Broker上,实现消息的按需流动。
3)基于Network Bridge的简化改造:与2)类似,但是每个“Group”只有一个Broker节点,此Broker基于kahaDB本地文件存储,即相对于2)Group缺少了HA特性;当Broker节点失效时,其上的消息将不可见、直到Broker恢复正常。这种简化版的架构模式,通过增加机器的数量、细分消息的分布,来降低数据影响故障影响的规模,因为其基于kahaDB本地日志存储,所以性能很高。
1、共享JDBC

-
Producer端(压力输出机器):
-
数量:
4
台
-
硬件配置:16Core、32G,云主机
-
软件配置:JDK
1.8
,JVM 24G
-
并发与线程:
32
并发线程,连接池为
128
,发送文本消息,每个消息
128
个字符实体。
-
消息:持久化,Queue,非事务
-
-
Broker端(压力承载)
-
数量:
2
台
-
硬件配置:16Core、32G,云主机
-
软件配置:JDK
1.8
,JVM 24G
-
架构模式:M-S模式,开启异步转发、关闭FlowControl,数据库连接池为
1024
-
-
数据库(存储层)
-
数量:
2
台
-
硬件配置:16Core、32G,SSD(IOPS
3000
),云主机
-
架构模式:M-S
-
数据库:MySQL
-
-
-
测试结果
-
1
、消息生产效率:
1500
TPS
-
2
、Broker负载情况:CPU
30
%,内存使用率
11
%
-
3
、MySQL负载情况:CPU
46
%,IO_WAIT
25
%
-
-
结论:
-
1
、基于共享JDBC存储架构,性能确实较低。
-
2
、影响性能的关键点,就是数据库的并发IO能力,当TPS在
1800
左右时,数据库的磁盘(包括slave同步IO)已经出现较高的IO_WAIT。
-
3
、通过升级磁盘、增加IOPS,可以有效提升TPS指标,建议同时提高CPU的个数。
-
2、基于非共享文件存储
测试单个ActiveMQ,基于kahaDB存储,kahaDB分为两种数据刷盘模式:
1)逐条消息刷盘
2)每隔一秒刷盘
-
<persistenceAdapter>
-
<kahaDB directory=
“${activemq.data}/kahadb”
journalDiskSyncStrategy=
“periodic”
journalDiskSyncInterval=
“2000”
/>
-
</persistenceAdapter>
压力测试环境与1)保持一致,只是ActiveMQ的机器的磁盘更换为:SSD (600 IOPS)。
-
1
)逐条刷新磁盘
-
TPS:
660
-
Broker IO_WAIT:
19
%
-
2
)每隔一秒刷新磁盘
-
TPS:
9800
-
Broker IO_WAIT:
1.6
%
由此可见,基于日志文件的存储性能比JDBC高了接近5倍,其中逐条刷盘策略,消息的可靠性是最高的,但是性能却低于JDBC。如果基于“每隔一秒刷盘”策略,在极端情况下,可能导致最近一秒的数据丢失。
3、基于转发桥
基于转发桥的架构,实施成本较高,维护成本较高,架构复杂度也相对较大。本人根据实践经验,不推荐使用此模式。如果你希望尝试,也无妨,毕竟它是ActiveMQ官方推荐的“分布式队列实现机制”,从原理上它可以支持较大规模的消息存储。
4、最佳实践
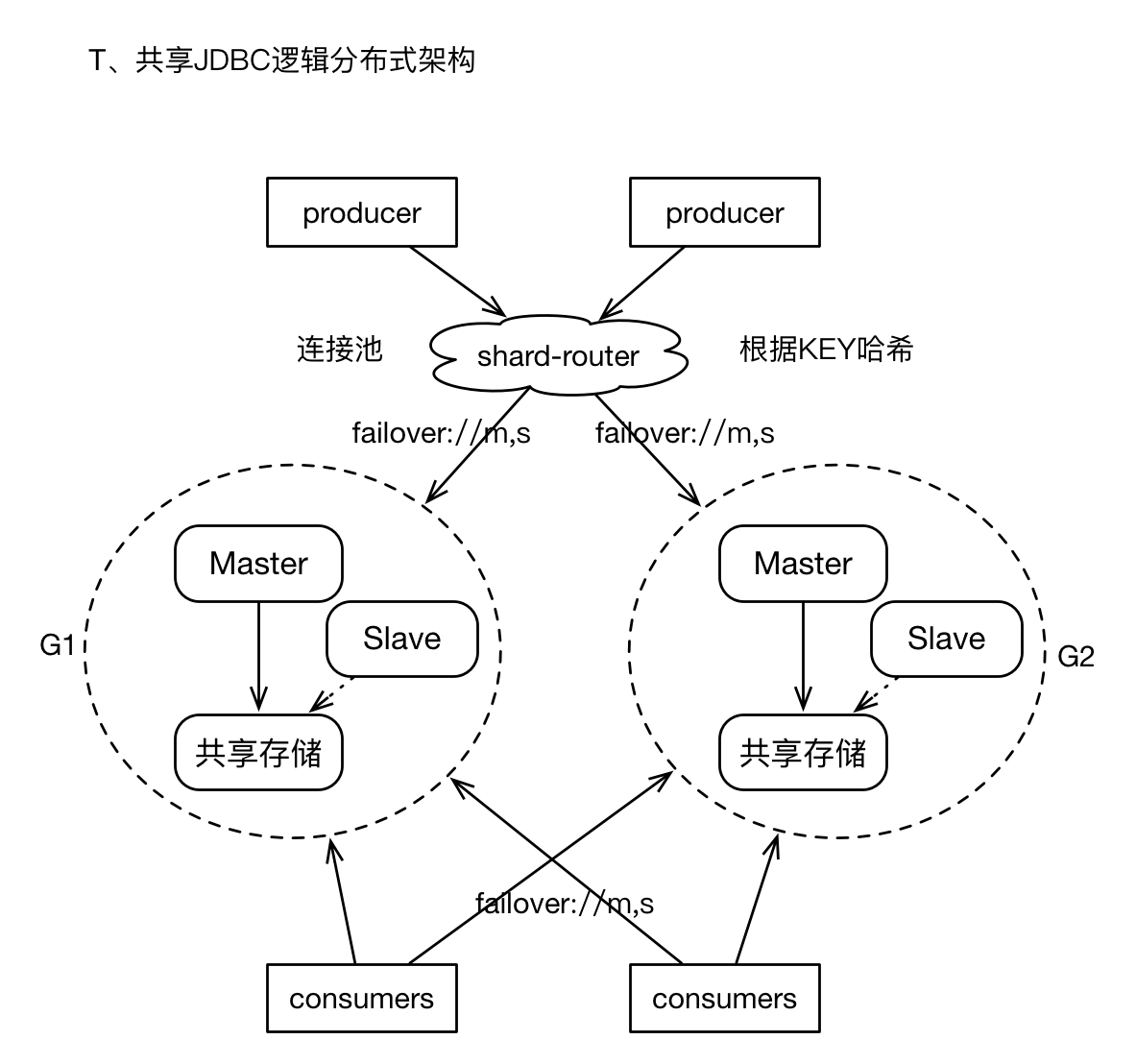
终归,我们需要面对“海量消息”的存储,我们在按照业务进行队列拆分之后,仍然需要面临某个单纯业务的消息量仍然是“单个M-S架构”无法满足,我们又不愿意承担Cluster模式复杂度所带来的潜在问题,此时,我们可以采用比较通用的“逻辑分布式”机制。
1)我们构建多个M-S组,但是每个Group之间在物理上没有关联,即它们之间互不通信,且不共享存储。
2)我们再Producer的客户端,增加“router”层面, 即开发一个Client Wrapper,此wrapper提供了Producer常用的接口,且持有多个M-S组的ConnectionFactory,在通过底层通道发送消息之前,根据message中的某个property、或者指定的KEY,进行hash计算,进而选择相应的连接(或者Spring的包装类),然后发送消息。这有点类似于基于客户端的数据库读写分离的策略。
3)对于Consumers,则只需要配置多个ConnectionFactory即可。
4)经过上述实践,我们将消息sharding到多个M-S组,解决了消息发送效率的问题,且逻辑集群可以进行较大规模的扩展。而且对Client是透明的。
5)
如果你不想开发shard-router层面,我们仍然可以基于failover协议来实现“逻辑分布式”的消息散列存储,此时需要在failover协议中指明所有Groups的brokers节点列表,且randomize=true。这种用法,可以实现消息在多个Group上存储,唯一遗憾的地方时,因为缺乏“自动负载均衡策略”,可能导致消息分布不均。
-
failover:(tcp:
//G1.master,tcp://G1.slave,tcp://G2.master,tcp://G2.slave)?randomize=true
-
//randomize必须为true
五、ActiveMQ配置样例(基于共享JDBC)
根据本人深思,最终还是决定采用共享JDBC数据库的方式,因为我无法承担业务团队叫嚣“消息丢失”所带来的“非技术性”压力与纠葛。虽然单个Group性能稍差,但是我们可以进行多Groups扩容。
-
<?xml version=
“1.0”
encoding=
“utf-8”
?>
-
<beans xmlns=
“http://www.springframework.org/schema/beans”
-
xmlns:xsi=
“http://www.w3.org/2001/XMLSchema-instance”
-
xsi:schemaLocation=”http:
//www.springframework.org/schema/beans
-
http:
//www.springframework.org/schema/beans/spring-beans.xsd
-
http:
//activemq.apache.org/schema/core
-
http:
//activemq.apache.org/schema/core/activemq-core.xsd”>
-
<!–
-
配置与授权
-
–>
-
<bean
class
=
“org.springframework.beans.factory.config.PropertyPlaceholderConfigurer”
>
-
<property name=
“locations”
>
-
<value>file:${activemq.conf}/credentials.properties</value>
-
</property>
-
</bean>
-
<!– 审计日志 –>
-
<bean id=
“logQuery”
class
=
“io.fabric8.insight.log.log4j.Log4jLogQuery”
-
lazy-init=
“false”
-
scope=
“singleton”
-
init-method=
“start”
-
destroy-method=
“stop”
>
-
</bean>
-
<!–
-
<bean id=
“mysql-ds”
class
=
“org.apache.commons.dbcp.BasicDataSource”
destroy-method=
“close”
>
-
<property name=
“driverClassName”
value=
“com.mysql.jdbc.Driver”
/>
-
<property name=
“url”
value=
“jdbc:mysql://localhost/activemq?relaxAutoCommit=true”
/>
-
<property name=
“username”
value=
“activemq”
/>
-
<property name=
“password”
value=
“activemq”
/>
-
<property name=
“maxActive”
value=
“128”
></property>
-
<property name=
“maxIdle”
value=
“2”
></property>
-
<property name=
“minIdle”
value=
“1”
></property>
-
<property name=
“maxWait”
value=
“3000”
></property>
-
<property name=
“defaultAutoCommit”
value=
“true”
></property>
-
<property name=
“poolPreparedStatements”
value=
“true”
/>
-
</bean>
-
–>
-
<!–
-
1
、brokerName
-
每个broker必须持有唯一不同的名称,我们通常,以broker + {IP}方式
-
2
、useJmx
-
我们开启jmx,适用于组件监控,配合下文中的<managementContext/>
-
3
、dataDirectory
-
数据目录,包括日志,cursor文件,数据文件等。数据文件可以在persistence配置中“重写”。
-
4
、enableStatistics
-
开启统计,此后可以通过active ${status}等相关指令查看,开启有一定的性能损耗。
-
5
、persistent
-
开启持久化功能,即数据将会写入Store.
-
如果为
false
,那么所有的消息都将以内存方式存储,请使用<memoryPersistenceAdapter>
-
6
、schedulerSupport
-
开启调度,如果需要Broker执行,比如定期清理过期消息、检测磁盘和内容容量、清理离线订阅者等,此时必须开启。
-
7
、useVirtualTopics
-
开启虚拟Topics功能
-
8
、offlineDurableSubscriberTimeout
-
对于“持久订阅者”,如果长期离线,将导致Topic消息积压,验证影响Topic的转发效率。
-
我们应该将那些“长期离线”的订阅者删除。此值为
7
天,单位:毫秒
-
9
、offlineDurableSubscriberTaskSchedule
-
用于“检测”离线订阅者的定时器调度间隔,此值为
1
个小时
-
10
、schedulePeriodForDestinationPurge
-
如果一个空的Destination(没有消息积压)在一定时间内,没有Consumer消费时,将会被删除。
-
需要配合才能生效
-
<policyEntry gcInactiveDestinations=
“true”
inactiveTimeoutBeforeGC=
“30000”
/>
-
本实例中为
7
天有效期,每隔
1
小时检测一次
-
11
、advisorySupport
-
开启通知,主要用于监控,当出现慢消费者、DLQ、容量不足等问题时,将会在“advisory”相关的Queue、Topic中发送内置的消息,
-
对于监控程序,可以通过消费advisory,实现组件监控机制。
-
有一定的性能开支
-
12
、schedulePeriodForDiskUsageCheck
-
每个
5
分钟检测一次磁盘存储使用率。参见<systemUsage>
-
-
–>
-
<broker xmlns=
“http://activemq.apache.org/schema/core”
-
brokerName=
“broker-01”
-
useJmx=
“true”
-
dataDirectory=
“${activemq.data}”
-
enableStatistics=
“true”
-
persistent=
“true”
-
useVirtualTopics=
“true”
-
schedulerSupport=
“true”
-
offlineDurableSubscriberTimeout=
“604800000”
-
offlineDurableSubscriberTaskSchedule=
“3600000”
-
schedulePeriodForDestinationPurge=
“3600000”
-
advisorySupport=
“true”
-
schedulePeriodForDiskUsageCheck=
“300000”
>
-
<destinationPolicy>
-
<policyMap>
-
<policyEntries>
-
<!–
-
关于持久化订阅者的相关配置
-
http:
//activemq.apache.org/manage-durable-subscribers.html
-
通道策略
-
http:
//activemq.apache.org/per-destination-policies.html
-
删除不活跃通道
-
http:
//activemq.apache.org/delete-inactive-destinations.html
-
–>
-
<!–
-
1
、topic
-
通用正则表达式,表示“全部topic”
-
2
、expireMessagesPeriod
-
每个
5
分钟检测一次消息,对于TLL过期的消息将会被移除。(根据DLQ策略)
-
3
、advisoryForSlowConsumers
-
如果“advisorySupport”开启时,当Broker判定某个消费者为慢速消费者(待确认消息 >=
2
* prefetch)
-
将会发送通知。
-
4
、advisoryWhenFull
-
如果cursor、store溢满时,发送通知
-
5
、maxPageSize
-
从store中pageIn消息列表的批量大小
-
6
、producerFlowControl
-
是否开启“生产者流量控制”,如果开启,当内存溢满、“待发送消息达到阈值”将会阻塞producer。
-
因为我们采用store存储,所以不需要流量控制
-
7
、durableTopicPrefetch
-
8
、gcInactiveDestinations
-
不活跃的通道,是否允许被删除。
-
9
、inactiveTimeoutBeforeGC
-
当一个通道中没有消息,且没有消费者时,此通道将会被认定为“不活跃”
-
–>
-
-
<policyEntry topic=
“>”
expireMessagesPeriod=
“0”
-
advisoryForSlowConsumers=
“true”
-
advisoryWhenFull=
“true”
-
maxPageSize=
“512”
-
producerFlowControl=
“false”
-
durableTopicPrefetch=
“200”
-
gcInactiveDestinations=
“true”
-
inactiveTimeoutBeforeGC=
“604800000”
-
>
-
<!– 转发策略 –>
-
<dispatchPolicy>
-
<!– 对于Topic,我们通常采用轮训机制 –>
-
<roundRobinDispatchPolicy/>
-
</dispatchPolicy>
-
<!–
-
对于non-durable Topic,积压的消息数量 ,如果超过限制,则剔除
-
http:
//activemq.apache.org/slow-consumer-handling.html
-
仅对非持久化Topic有效,目的是提高Topic的转发效率。
-
–>
-
<pendingMessageLimitStrategy>
-
<constantPendingMessageLimitStrategy limit=
“256”
/>
-
</pendingMessageLimitStrategy>
-
<messageEvictionStrategy>
-
<oldestMessageEvictionStrategy/>
-
</messageEvictionStrategy>
-
<!–
-
不支持
“可回溯”
订阅者,即新加入的订阅者只能获取订阅操作发生之后的消息
-
http:
//activemq.apache.org/subscription-recovery-policy.html
-
–>
-
<subscriptionRecoveryPolicy>
-
<noSubscriptionRecoveryPolicy/>
-
</subscriptionRecoveryPolicy>
-
<!–
-
对于TTL过期的、或者临时存储溢满被剔除的、重发次数超过限制的等等,都有可能进入DLQ
-
1
、processExpired
-
TTL过期的消息,将直接移除,不会进入DLQ
-
2
、processNonPersistent
-
对于非持久化消息,无论如何都进入DLQ
-
3
、expiration
-
DLQ中消息的TTL,从进入DLQ开始。此值为“
3
天”
-
–>
-
<deadLetterStrategy>
-
<sharedDeadLetterStrategy processExpired=
“false”
-
processNonPersistent=
“false”
-
expiration=
“259200000”
/>
-
</deadLetterStrategy>
-
<!–
-
积压消息的转发策略,cursor机制
-
当Producer发送小于大于Consumer消费效率时,这意味着Broker在转发层面需要对
-
“积压”的消息进行buffer或者临时存储。
-
1
、对于非持久化订阅者,消息直接保存在内存中,存储量受限于systemUsage。
-
2
、对于持久化订阅者,消息将使用store(内部基于VM + File)
-
http:
//activemq.apache.org/message-cursors.html
-
–>
-
<pendingSubscriberPolicy>
-
<vmCursor/>
-
</pendingSubscriberPolicy>
-
<pendingDurableSubscriberPolicy>
-
<storeDurableSubscriberCursor/>
-
</pendingDurableSubscriberPolicy>
-
</policyEntry>
-
<!–
-
因为Queue总是基于prefetch批量推送机制,所有当consumer有多个,且消息的密度不大时,如果使用
-
strictOrderDispatch将会导致总是转发给一个consumer的问题。
-
strictOrderDispatch + prefetch需要注意
-
–>
-
<policyEntry queue=
“>”
expireMessagesPeriod=
“0”
-
maxPageSize=
“512”
-
producerFlowControl=
“false”
-
queuePrefetch=
“1000”
-
strictOrderDispatch=
“false”
-
useConsumerPriority=
“true”
-
sendAdvisoryIfNoConsumers=
“true”
-
advisoryForSlowConsumers=
“true”
-
advisoryWhenFull=
“true”
-
gcInactiveDestinations=
“true”
-
inactiveTimoutBeforeGC=
“604800000”
>
-
<deadLetterStrategy>
-
<!–
-
私信队列,统一使用一个,避免不必要的维护成本,易于监控
-
–>
-
<sharedDeadLetterStrategy processExpired=
“false”
-
processNonPersistent=
“false”
-
expiration=
“259200000”
/>
-
</deadLetterStrategy>
-
<!–
-
积压待发的消息,采用store
-
–>
-
<pendingQueuePolicy>
-
<storeCursor/>
-
</pendingQueuePolicy>
-
</policyEntry>
-
</policyEntries>
-
</policyMap>
-
</destinationPolicy>
-
<!–
-
虚拟Topic,我们让所有的Topic都支持虚拟化
-
http:
//activemq.apache.org/virtual-destinations.html
-
–>
-
<destinationInterceptors>
-
<virtualDestinationInterceptor>
-
<virtualDestinations>
-
<virtualTopic name=
“>”
prefix=
“VConsumers.*.”
selectorAware=
“false”
/>
-
</virtualDestinations>
-
</virtualDestinationInterceptor>
-
</destinationInterceptors>
-
<!–
-
JMX监控
-
http:
//activemq.apache.org/jmx.html
-
–>
-
<managementContext>
-
<managementContext createConnector=
“false”
/>
-
</managementContext>
-
<!–
-
PersistenceAdapter
-
http:
//activemq.apache.org/persistence.html
-
–>
-
<persistenceAdapter>
-
<jdbcPersistenceAdapter dataDirectory=
“${activemq.data}”
dataSource=
“#mysql-ds”
lockKeepAlivePeriod=
“5000”
>
-
<locker>
-
<lease-database-locker lockAcquireSleepInterval=
“10000”
/>
-
</locker>
-
</jdbcPersistenceAdapter>
-
</persistenceAdapter>
-
<!–
-
Memory Setting and Flow-Control
-
http:
//activemq.apache.org/producer-flow-control.html
-
–>
-
<systemUsage>
-
<systemUsage>
-
<memoryUsage>
-
<memoryUsage percentOfJvmHeap=
“70”
/>
-
</memoryUsage>
-
<storeUsage>
-
<storeUsage limit=
“50 gb”
/>
-
</storeUsage>
-
<tempUsage>
-
<tempUsage limit=
“20 gb”
/>
-
</tempUsage>
-
</systemUsage>
-
</systemUsage>
-
<!–
-
TransportConnector and Protocol Setting
-
http:
//activemq.apache.org/configuring-transports.html
-
–>
-
<transportConnectors>
-
<!– DOS protection, limit concurrent connections to
1000
and frame size to 100MB –>
-
<transportConnector name=
“openwire”
-
uri=
“tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600”
/>
-
<transportConnector name=
“amqp”
-
uri=
“amqp://0.0.0.0:5672?maximumConnections=1000&wireFormat.maxFrameSize=104857600”
/>
-
<transportConnector name=
“stomp”
-
uri=
“stomp://0.0.0.0:61613?maximumConnections=1000&wireFormat.maxFrameSize=104857600”
/>
-
<transportConnector name=
“mqtt”
-
uri=
“mqtt://0.0.0.0:1883?maximumConnections=1000&wireFormat.maxFrameSize=104857600”
/>
-
<!–
-
<transportConnector name=
“ws”
uri=
“ws://0.0.0.0:61614?maximumConnections=1000&wireFormat.maxFrameSize=104857600”
/>
-
–>
-
</transportConnectors>
-
<!– destroy the spring context on shutdown to stop jetty –>
-
<shutdownHooks>
-
<bean xmlns=
“http://www.springframework.org/schema/beans”
-
class
=
“org.apache.activemq.hooks.SpringContextHook”
>
-
</bean>
-
</shutdownHooks>
-
<!–
-
私信队列处理
-
http:
//activemq.apache.org/message-redelivery-and-dlq-handling.html
-
–>
-
<plugins>
-
<simpleAuthenticationPlugin>
-
<users>
-
<authenticationUser username=
“amq_manager”
password=
“012345”
-
groups=
“users,admins”
/>
-
<authenticationUser username=
“amq_common”
password=
“123456”
-
groups=
“users”
/>
-
</users>
-
</simpleAuthenticationPlugin>
-
<redeliveryPlugin fallbackToDeadLetter=
“true”
-
sendToDlqIfMaxRetriesExceeded=
“true”
>
-
<redeliveryPolicyMap>
-
<!– 重发策略,对于超过重发次数的消息将会被添加到DLQ –>
-
<redeliveryPolicyMap>
-
<redeliveryPolicyEntries>
-
<!–
-
重发机制,默认重发
6
,重发延迟基于backOff模式
-
–>
-
<redeliveryPolicy maximumRedeliveries=
“6”
-
initialRedeliveryDelay=
“1000”
-
useExponentialBackOff=
“true”
-
backOffMultiplier=
“5”
-
queue=
“>”
/>
-
</redeliveryPolicyEntries>
-
<defaultEntry>
-
<!– 其他策略 –>
-
<redeliveryPolicy maximumRedeliveries=
“6”
-
initialRedeliveryDelay=
“1000”
-
useExponentialBackOff=
“true”
-
backOffMultiplier=
“5”
/>
-
</defaultEntry>
-
</redeliveryPolicyMap>
-
</redeliveryPolicyMap>
-
</redeliveryPlugin>
-
</plugins>
-
</broker>
-
<!–
-
Web Manager
-
–>
-
<
import
resource=
“jetty.xml”
/>
-
</beans>
需要特别注意“
expireMessagesPeriod
”这个参数,我们发现这个参数一旦开启,Broker将会间歇性全量获取数据,特别是在JDBC存储模式下,会导致Broker与数据库之间的数据流量巨大,导致内存OOM的问题。
六、Producer配置(基于Spring)
-
<?xml version=
“1.0”
encoding=
“UTF-8”
?>
-
<beans xmlns=
“http://www.springframework.org/schema/beans”
-
xmlns:xsi=
“http://www.w3.org/2001/XMLSchema-instance”
-
xmlns:amq=
“http://activemq.apache.org/schema/core”
-
xmlns:jms=
“http://www.springframework.org/schema/jms”
-
xsi:schemaLocation=”http:
//www.springframework.org/schema/beans
-
http:
//www.springframework.org/schema/beans/spring-beans-4.0.xsd
-
http:
//www.springframework.org/schema/jms
-
http:
//www.springframework.org/schema/jms/spring-jms-4.0.xsd
-
http:
//activemq.apache.org/schema/core
-
http:
//activemq.apache.org/schema/core/activemq-core-5.8.0.xsd”>
-
-
<!– Spring提供的JMS工具类,它可以进行消息发送、接收等 –>
-
<bean id=
“jmsTemplate”
class
=
“org.springframework.jms.core.JmsTemplate”
>
-
<property name=
“connectionFactory”
ref=
“amqPooledConnectionFactory”
/>
-
<property name=
“defaultDestination”
ref=
“testQueue”
/>
-
<!– 非持久化:
1
,持久化:
2
–>
-
<property name=
“deliveryMode”
value=
“2”
/>
-
<property name=
“explicitQosEnabled”
value=
“true”
/>
-
<property name=
“messageIdEnabled”
value=
“true”
/>
-
<property name=
“messageTimestampEnabled”
value=
“true”
/>
-
<!–
0
:基于事务的确认机制
1
:基于session的自动确认,
2
:客户端确认,此值对consumer生效 –>
-
<property name=
“sessionAcknowledgeMode”
value=
“2”
/>
-
<property name=
“sessionTransacted”
value=
“false”
/>
-
<!–
72
小时 –>
-
<!– 所有的消息,都应该表明其TTL –>
-
<property name=
“timeToLive”
value=
“259200000”
/>
-
</bean>
-
<bean id=
“amqPooledConnectionFactory”
class
=
“org.apache.activemq.pool.PooledConnectionFactory”
destroy-method=
“stop”
>
-
<!– 当session池(连接池)已满时,getSession()操作阻塞的最大时间,超时后抛出异常 –>
-
<property name=
“blockIfSessionPoolIsFullTimeout”
value=
“6000”
/>
-
<property name=
“connectionFactory”
ref=
“amqConnectionFactory”
/>
-
<!– 单个连接的生命周期,TTL,从创建开始,当其服务时长达到timeout时,且没有Consumer、Producer使用,则会关闭 –>
-
<property name=
“expiryTimeout”
value=
“0”
/>
-
<!– 一个正常的连接,当没有producer或者消费者进行数据交互时、空闲timeout之后,应该被关闭并移出pool –>
-
<property name=
“idleTimeout”
value=
“30000”
/>
-
<!– 最大连接数,应该合理,建议与应用的并发级别保持一致 –>
-
<property name=
“maxConnections”
value=
“128”
/>
-
<!– 每个连接上,允许创建的、并发的session数量(createSession,PooledSession)–>
-
<property name=
“maximumActiveSessionPerConnection”
value=
“500”
/>
-
</bean>
-
-
<bean id=
“amqConnectionFactory”
class
=
“org.apache.activemq.ActiveMQConnectionFactory”
>
-
<property name=
“brokerURL”
value=
“failover:(tcp://10.0.1.100:61616,tcp://10.0.1.101:61616)?randomize=false”
/>
-
<property name=
“userName”
value=
“amq_common”
/>
-
<property name=
“password”
value=
“123456”
/>
-
<!– 连接ID的前缀,建议与项目名保持一致 –>
-
<property name=
“connectionIDPrefix”
value=
“sample-”
/>
-
<!– 消息转发和消费时,校验TTL是否过期 –>
-
<property name=
“consumerExpiryCheckEnabled”
value=
“true”
/>
-
<!– 要求Broker端进行异步转发,提高消息的发送效率 –>
-
<property name=
“dispatchAsync”
value=
“true”
/>
-
<property name=
“prefetchPolicy”
>
-
<bean
class
=
“org.apache.activemq.ActiveMQPrefetchPolicy”
>
-
<property name=
“queuePrefetch”
value=
“100”
/>
-
</bean>
-
</property>
-
<property name=
“sendTimeout”
value=
“10000”
/>
-
<!– 异步发送,可能导致消息丢失,通常对于非持久化消息可以采用异步发送 + producerWindowSize –>
-
<property name=
“useAsyncSend”
value=
“false”
/>
-
</bean>
-
-
<bean id=
“testQueue”
class
=
“org.apache.activemq.command.ActiveMQQueue”
>
-
<constructor-arg value=
“test-queue”
/>
-
</bean>
-
</beans>
我们使用ActiveMQ提供的PooledConnectionFactory,底层基于连接池(session对象池)机制,在一定程度上可以提高底层消息的通信效率,特别是在高并发环境中。我们并没有采用Spring-JMS中提供的CachingConnectionFactory,因为它是单连接机制,而且在Consumer层面,稍有不慎可能导致消息的重发问题。
上述配置中,有些细微的参数需要特别注意,否则可能导致问题。(配置中并不是所有的参数都是为Producer服务的,有些是针对Consumers)
七、Consumer端(基于Spring)
-
<bean
class
=
“org.springframework.jms.listener.DefaultMessageListenerContainer”
>
-
<property name=
“connectionFactory”
ref=
“amqPooledConnectionFactory”
/>
-
<property name=
“destination”
ref=
“testQueue”
/>
-
<property name=
“messageListener”
>
-
<bean
class
=
“com.demo.jms.sample.TestListener”
>
-
</bean>
-
</property>
-
<property name=
“concurrentConsumers”
value=
“2”
/>
-
<property name=
“maxConcurrentConsumers”
value=
“5”
/>
-
<!– 会话确认机制,默认为:
1
,自动确认,我们建议使用:
2
,手动确认 –>
-
<property name=
“sessionAcknowledgeMode”
value=
“2”
/>
-
<!– Topic订阅者有效 –>
-
<!–
-
<property name=
“clientId”
value=
“${clientId}”
/>
-
–>
-
</bean>
TestListener.java样例
-
public
class
TestListener
implements
MessageListener {
-
private
static
final
Logger LOGGER = LoggerFactory.getLogger(TestListener.
class
);
-
-
@Override
-
public
void
onMessage(Message message) {
-
try
{
-
if
(message
instanceof
TextMessage) {
-
String text = ((TextMessage) message).getText();
-
LOGGER.error(
“<Consumer>:”
+ text);
-
}
-
message.acknowledge();
-
}
catch
(Exception e) {
-
LOGGER.error(
“”
,e);
//遇到异常,如果你希望回滚或者重发,你应该重新抛出
-
}
-
}
-
}
转载于:https://my.oschina.net/javahongxi/blog/1531591