前几天由于面试需要,整理了一些关于推荐系统中相似度计算方法的内容,加上一些自己的理解,总结如下。
1. 欧几里得距离
又称欧式距离。对于任两个用户ui和uj,欧式距离就是计算这两个用户的评分向量在n维向量空间中的绝对距离,计算公式如下:
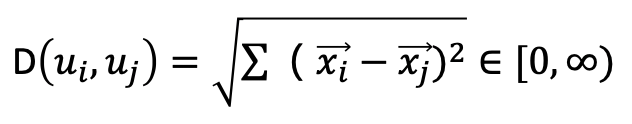
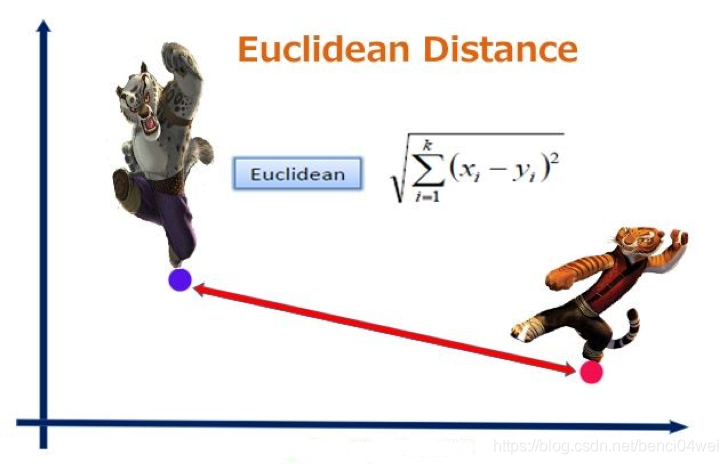
由公式可以看出,欧式距离就是计算这两个向量的差的模长。例如在下图所示平面直角坐标中,欧式距离就是两个向量表示的两点间的实际距离,这很符合我们的常规思维,即向量表示的两点间的距离越近,那么这两个向量之间就越相似。
实际使用中,我们一般还要进行如下转换:
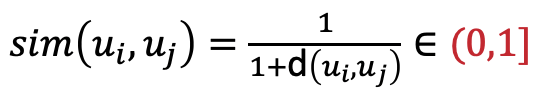
将欧式距离所得结果进行归一化处理,相对于欧式距离的值域范围[0,正无穷大]来说,归一化后的结果能够更好的对向量间的相似度值进行量化。此时,欧式距离越小,欧几里得相似度的值越大,用户u1、u2的相似程度就越高。
欧式距离直接计算两点之间的绝对距离,当数据很稠密时,这是一种很好的相似度度量方式,但是欧式距离将所有维度对距离的贡献度都当作是同等的,没有考虑不同特征变量间的取值范围和单位刻度的差异,所以在多维不同属性应用中的效果不佳。比如:特征a取值范围是[0,1],而特征b取值范围是[0,1000],此时计算欧式距离,变量b上微小的差异就会决定运算结果。或者特征a描述的是身高数据,而特征b描述的是体重数据,此时使用欧式距离可能会使结果失效。
2. 余弦相似度
余弦相似度通过计算两用户评分向量间的夹角的余弦值来表示用户间的相似程度,公式如下:
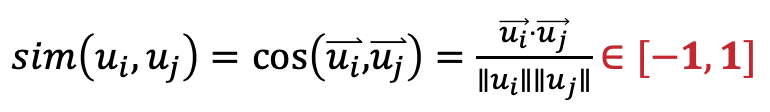
即用向量的内积除以向量各自的模长的乘积。其取值范围在-1到1之间,余弦值越接近1,向量夹角越接近0度,也就是两个向量越相似。
-
欧式距离 VS 余弦相似度
欧氏距离是最常见的距离度量,而余弦相似度则是最常见的相似度度量,很多的距离度量和相似度度量方法都是基于这两者的变形和衍生,所以下面重点比较下两者在衡量个体差异时的实现方式和应用环境上的区别。我们借助三维坐标系来看下这两者的区别:

从图上可以看出,欧式距离度量的是向量间的绝对距离,更加注重数值上的绝对差异,对点的位置坐标,即向量各个维度内的数值特征非常敏感;而余弦相似度衡量的是空间向量的夹角,更加注重两个向量在方向上的相对差异。例如:如果保持A点的位置不变,B点朝原方向远离坐标轴原点移动,那么这个时候余弦相似度cosθ是保持不变 的,因为夹角不变,但是A、B两点的绝对距离,也就是欧式距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处。
因此,在推荐系统场景下,欧式距离一般用于需要从维度的数值大小中体现差异的相关度分析。例如,当我们分析用户活跃度,以登陆次数(单位:次)和平均观看时长(单位:分钟)作为特征时,余弦相似度会认为(1,10)、(10,100)两个用户距离很近,但显然这两个用户的活跃度是有着很大差异的,(10,100)这个用户的价值更高,此时我们更关注数值绝对差异,应当使用欧氏距离。
3. 修正的余弦相似度(Adjusted Cosine Similarity)
我们先看个例子:假设现有两个用户u1和u2,他们的电影评分向量分别为(4,4,3)和(2,1,3),此时使用余弦相似度的结果是0.869,两者非常相似。但我们进一步观察他们各自的评分数值会发现,用户u1对电影1、2的评分分别为5和4,似乎比较喜欢这两部电影,而u2的评分只有2和1,他不喜欢,直观上判断,用户u1,u2的喜好不甚相似,那为什么这两个用户之间的余弦相似度的值还这么高呢?
这是余弦相似度对绝对数值的不敏感性导致的。余弦相似度度量的是向量的夹角,更看重向量在方向上的差距,无法适应不同用户的评分数值标准的差异性所带来的影响。为了改进这种不合理性就出现了修正的余弦相似度,公式如下所示:
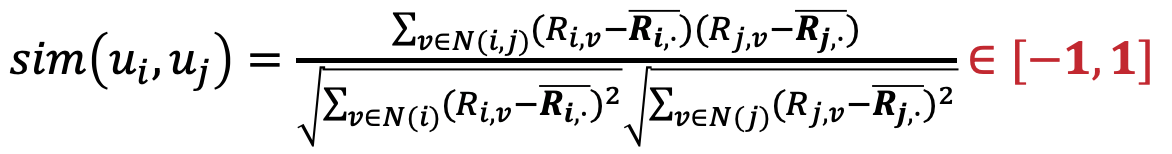
其中,N(i,j)表示用户u_i和用户u_j 都评过分的项目集合。
修正的余弦相似度在余弦相似度的基础上,进一步把所有评分都减去该评分所对应的用户的评分均值,结果越大,相似度越高。
比如上个例子中的用户u1、u2,他俩的评分均值分别是4和2,那么根据修正的余弦相似度调整后的评分向量就变为(1,0,-1)和(0,-1,1),此时再用余弦相似度计算,得到结果-0.5,相似度为负值并且差异不小,这显然更加符合现实。
4. Pearson相关系数
要理解Pearson相关系数,首先要理解协方差,我们都知道协方差是一个反映两个随机变量相关程度的指标,如果两个变量的变化趋势一致,那么这两个变量的协方差就是正值,反之则为负值,公式如下:
![]()
但是协方差数值上受量纲的影响很大,不能简单地从协方差的数值大小给出变量相关程度的判断。为了消除这种量纲的影响,于是就有了皮尔森相关系数的概念。
Pearson相关系数反映了两个变量之间的线性相关程度,公式如下:

由公式可知,Pearson 相关系数就是协方差和标准差的商。当相关系数为正值时,变量呈正相关;系数为负值时呈负相关,相关系数的绝对值越大,线性相关性越强。
-
修正的余弦相似度 VS Pearson相关系数
Perason相关系数的公式与修正的余弦相似度很相似,很容易混淆。那么他们有哪些区别呢?由定义可知,修正的余弦相似度是为了修正不同用户的评分数值标准的差异性的影响,所以不论是计算用户间的相似度,还是计算项目间的相似度,中心化时所减去的均值总是该评分所对应的用户的评分均值;而Pearson定义为协方差和标准差的商,所以自然地进行了中心化处理,减去的均值可能是用户均值,也可能是项目均值。
具体而言,首先是他们中心化的方式不同,如下公式所示:

即使是在计算项目间相似度时,修正的余弦相似度所减去的均值仍是对该项目打过分的每个用户u,其评分均值;而Pearson相关系数则是减去该项目所获得的打分的均值。举个例子:

如图一个5分制的用户-电影评分矩阵,现在需要计算出电影F1和电影F3的相似度,那么针对User2-Film1这个评分项进行中心化处理的时候,修正的余弦相似度减去的是这个评分值所对应的行向量,即用户U2的评分均值2.00,而Pearson减去的均值则这个评分项所对应的列向量,即F1这一列的得分均值3.75。
此外,他们分母上使用的评分集范围也不同。修正的余弦相似度使用的是对象各自的评分集,因为它计算的是评分向量各自的模长;而Pearson相关系数采用的则是两个对象的共同评分集,因为Pearson相关系数处理的两个变量得是一一对应,得是非缺失值。
以上,就是二者的不同之处。
5. Jaccard系数
Jaccard系数通过计算集合A和B的交集元素在其并集中所占的比例来表示这两个集合的相似度。常用于符号型或布尔型数据,因为此类数据无法衡量彼此之间差异的具体大小,只能用是否相同来衡量,其计算公式如下:
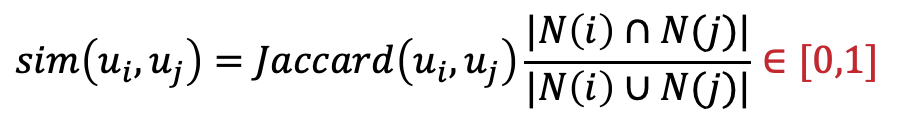
其中,N(i)表示用户u_i评过分的项目集合,N(j)用户u_j评过分的项目集合。
其取值范围在0到1之间,值越大,相似度越高。
以上就是常见的基本的五种相似度计算方法。当然,这些相似度计算方法都没有绝对的好坏优劣之分,适用场景也都不是绝对的,要根据实际的应用场景、数据特点灵活选择,甚至组合。