一、问题介绍:
torch当中例如 mean(dim=1) Softmax(dim=-1)以及layer norm和batch norm到底是怎么算的,常常令人感到迷惑。其实它们的道理是一样的
二、维度的直观概念
首先,如果对维度和矩阵中数据的结构没有直观感受的请阅读我另一篇文章:
三、详细讲解:
1.核心观点:
function(dim=-1)就是说对dim=-1这个维度进行function操作
而
对某维度进行操作
的的意思就是:
每次把那些(
除了这个维度
以外其他维度的
位置坐标都相同
的)
一组数据
拿来运算

也就是说,这组数据里只有你指定的那个维度上位置坐标是不同的,是可以变化的
2.以mean为例:
先写个二维矩阵,之后向高维过渡
a=torch.tensor([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]], dtype=float)
a.mean(dim=-1)
mean(dim=-1):dim=-1是最低的维度,可以看做一个水平向右的轴,我们要对
2.1 几何直观理解:

2.2 位置坐标理解:
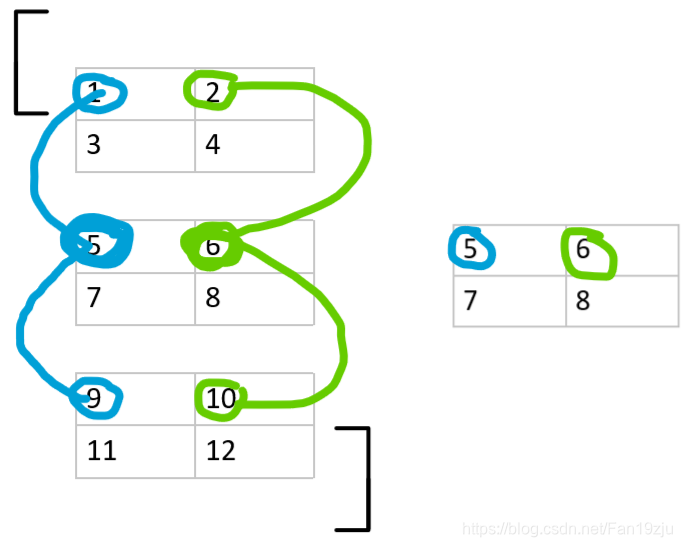
图中1,2,3,4,5这组数据都处于同一行,说明它们dim=-2这个维度上(或者说竖着向下的的轴)的位置坐标是一样的。它们唯一不同的是
dim=-1这 个轴的位置坐标
。他们加起来取了一次平均,得3
- 写数学通式的话,这五个数的位置坐标可以写为(0,x)。意思是:dim=-2这个轴位置坐标是0,dim=-1这个轴可以变化
- 6,7,8,9,10 通式为(1,x) , 取平均得8
- 11,12,13,14,15 通式为(2,x) ,取平均得13
-
这就是我说的,每次把除了dim=-1这个维度以外,位置坐标都相同的一组数据来运算
从位置坐标上的规律来理解更有利于我们向高维的mean过渡
2.3 三维矩阵的mean讲解:
a=torch.tensor([[[1., 2.],
[3., 4.]],
[[5., 6.],
[7., 8.]],
[[9., 10.],
[11., 12.]]])
a.mean(dim=-3)
mean(dim=-3)是不是乍一看不好看了
但是我们还是从那个核心概念出发,用位置坐标就很好理解
首先说,这个三维矩阵你可以理解为,有三个2×2的小矩阵被装在括号里了
- 最低维度dim=-1还是每个小矩阵中向右的横轴
- 次高维度dim=-2是每个小矩阵中向下的纵轴
- 最高维度dim=-3是区分每个小矩阵的
1 5 9 这仨数,在每个小矩阵中位置都一样,都是(0,0)。也就是说dim=-1和dim=-2上它们位置坐标一样。那它们啥不一样呢,就是
dim=-3这个维度上的位置坐标
,所以它们被拿来去了平均
2 6 10,3 7 11,4 8 12 也同样如此
2.4 mean输出矩阵的size:
通过观察可以得知,输出矩阵的size就是把你指定的那个维度删掉之后的size
原 size=(1,2,3)
若 mean(dim=-2)
则输出 size=(1,3)
四、softmax, batch_norm 和layer_norm:
1.softmax:
softmax其实跟mean拿数据来运算的方式是一样的,不过他不会让矩阵缩小就是了
a=torch.tensor([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]], dtype=float)
nn.Softmax(dim=-1)(a)

可以发现每一行被做了softmax运算,因为它们加起来等于1
2.batch norm 和 layer norm
- batch norm里面,batch就是那个被指定的维度 ,不同batch在每个feature位置进行norm
-
layer norm里面,seq_len是被指定的维度,是每个sequence内部进行norm
还是记住我们的:在这组数据中,只有你指定的那个维度上位置坐标可以变化
借一下别的博主的图:
Transformer 详解

竖着往下的那个维度应该是sequence length(seq_len)
伸向纸面内的是一个个词向量,那些数字你可以理解为词向量的第一个元素
以batch norm来说,计算的时候还是 136 norm一下,他仨背后的那三个数字norm一下这样类似的。道理是一样的。