(
未完待续,持续更新中
)
目录
序言
Linux的存储栈包括,
- API,将POSIX系统调用接口引入VFS层
- VFS,维护page cache、dcache、inode cache等结构的组织和内容,同时向下对接文件系统
- FS,包括各种文件系统,ext2、ext4、xfs、btrfs等
- Logical-Block,包括基于device-mapper的lvm、md-raid、bcache、multi-path等
- Block,即通常我们所讲的块层,向下对接存储协议,抽象存储设备的物理特性,包括最大IO size、是否支持cache等,同时提供各种IO调度(电梯算法可以认为是默认)策略
- 设备驱动,比如nvme和scsi类的存储设备;
- 物理存储设备
0 存储设备
存储栈的组件在设计时,一个重要的考量因素,就是如何更好的使用存储设备,使其发挥出最好的性能;所以,在研究Linux存储栈之前,我们先要了解下,各种存储设备的特点。
0.1 机械盘
我们评估价下磁盘以下性能指标:
Host:Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz
HDD:ST2000NM0055-1V4,磁盘容量1.8T
顺序IO,不同IOsize (–bs)
fio –bs=256K –size=512G –rw=read –norandommap –direct=1 –ioengine=libaio –iodepth=1 –runtime=60 –name=test –filename=/dev/sdb
| 512 | 4K | 8K | 16K | 32K | 64K | 128K | 256K | 512K | 1M | 4M |
| 24us | 30us | 39us | 79us | 157us | 314us | 629us | 1.26ms | 2.52ms | 5.04ms | 20.24ms |
随机IO,不同IO Range (–size)
fio –bs=512 –size=1536G –rw=randread –norandommap –direct=1 –ioengine=libaio –iodepth=1 –runtime=60 –name=test –filename=/dev/sdb –group_reporting
| 32M | 64M | 128M | 256M | 512M | 1G | 2G |
| 106us | 954us | 3.02ms | 4.08ms | 4.63ms | 5.06ns | 5.29ms |
| 4G | 8G | 16G | 32G | 64G | 128G | 256G | 512G | 1T | 1.5T |
| 5.51ms | 5.69ms | 5.85ms | 6.09ms | 6.34ms | 6.78ms | 7.36ms | 8.1ms | 9.44ms | 10.52ms |
通过以上数据,我们可以大致估算,磁盘执行IO主要分成三部分的时间:
- 软件栈开销,包括host和firmware,参考512字节顺序IO,应该在24 us以下;
- 磁头从磁盘上拷贝数据,大致200M/s,这与测试机械盘的理论带宽上限接近;
- 磁头移动,在移动范围超过128M之后,磁头移动时间就已经达到3ms,超过1G之后达到5ms;
所以,这块机械盘的瓶颈有个决定因素:
- 200M/s的带宽上限,这个通常只有在测试中使用纯顺序IO才能达到。
-
磁头移动范围,在实践中,这才是真正决定磁盘性能的因素
;
还是以这个磁盘为例,如果是xfs,默认4个Allocation Group,每个AG的大小512G(最后一个不足512G),不同目录的文件,通常会被分配到不同的AG,
当多个目录的文件同时IO时
,其范围很可能在256G以上,也就是磁头移动造成的时间大概在7ms;那么,每秒处理的IO数,也就是IOPS最高只能在143,这就是此时盘的瓶颈;此时,IOsize越大,盘的带宽就会越高。
0.2 SSD
(占坑)
0.3 NVDIMM
NVDIMM这个名字中包含了该种类型设备的两个特性:
- Non-Volatile,非易失性,即掉电不丢失;
- DIMM,这是该种设备的接口形式,跟DDR一样,这意味着,它有非常高的带宽上限,并且可以通过load/store指令访问;
即NVDIMM指的是一种使用DIMM接口的非易失性存储设备;
Intel近些年推出的Optane DC PMM就是其中的一种,其基于3D XPoint存储技术;同样的存储技术还基于NVMe接口实现了Optane SSD;其实我们也可以给硬盘实现DIMM接口,只不过成本和性能就看不过去了。
Optane DCPMM第一代产品代号为Apache Pass,也就是我们常说的AEP,其第二代产品代号为Barlow Pass,不过,网传英特尔将终止基于 3D XPoint 技术的 Optane 业务。


NVDIMM的性能数据来自网络上的两篇Paper《Basic Performance Measurements of the Intel Optane DC Persistent Memory Module》《Initial Experience with 3D XPoint Main Memory》,感兴趣的同学可以到
https://download.csdn.net/download/home19900111/86736994
![]()
https://download.csdn.net/download/home19900111/86736994


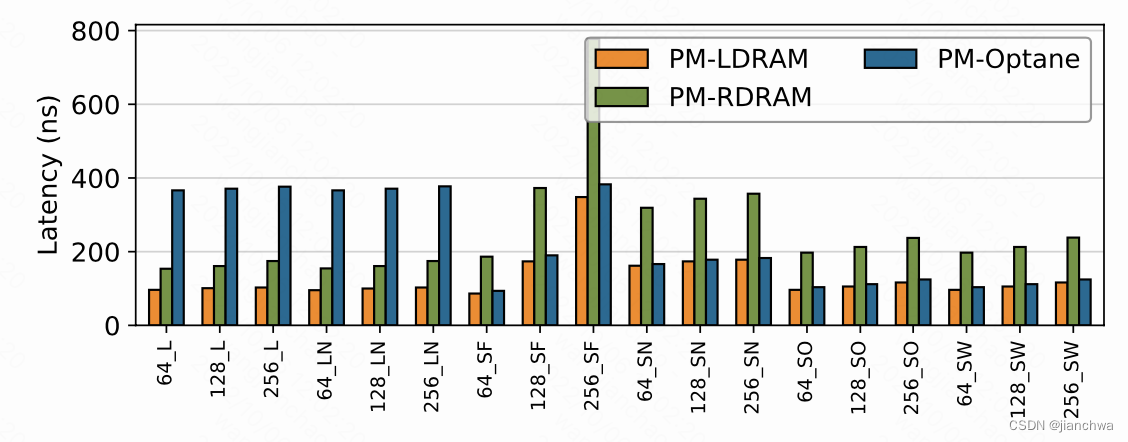
图中的LDRAM的意思是本地内存访问,RDRAM跨numa内存访问;
L stands for regular loads,
LN stands for non-temporal loads,
SF stands for stores followed by clflush
SN stands for non- temporal stores
SO stands for stores followed by clflushopt
SW stands for stores followed by clwb.
从图中的数据来看,虽然Opane的数据与真正的内存相比依然有些差距,但是已经基本在一个数量级;结合《Initial Experience with 3D XPoint Main Memory》中的结论,
The memory access performance of 3D XPoint is mod- estly lower than that of DRAM. Compared to DRAM, 3D XPoint’s read performance can be up to
2.5x slower
, and its write performance can be up to
2.3x slower.
The write performance of 3D XPoint is quite similar to its read performance. Writes are at most 2.3x slower than reads. The asymmetric effect of NVM reads and writes are modest.
Persisting writes to 3D XPoint incur drastic cost for sequential and random writes. The slowdowns can be at least 10.7x and 2.9x for sequential writes and random writes, respectively.
The performance of 3D XPoint degrades as an application accesses more data.
We suspect that techniques such as caching are exploited in the 3D Xpoint modules to improve performance
. This effect is less significant when the size of data visited is 32GB or larger for the 256GB 3D XPoint module.
与HDD或者Nand SSD对比,这无疑是”史诗级”的性能提升;但是,在实际使用中,我们发现AEP最大的问题是,由于其使用load/store指令直接访问,无法实现异步,这造成相关应用的CPU利用率显著升高。
Intel后来推出了基于FPGA的硬件加速模块,使用内部的几百上千的并发单元访问AEP。
不过,现阶段AEP仍然无法真正在引发计算系统革命;当NVDIMM的性能达到DDR且成本可控时,才会真正颠覆现有的架构。
关于nvdimm的持久化编程,参考掉电保护域,
Asynchronous DRAM Refresh (ADR) is a feature supported on Intel products which flushes the write-protected data buffers and places the DRAM in self-refresh. This process is critical during a power loss event or system crash to ensure the data is in a safe and consistent state on persistent memory. By default, ADR does not flush the processor caches. A platform that supports ADR only includes persistent memory and the memory controller’s write pending queues within the persistence domain. This is the reason data in the CPU caches must be flushed by the application using the CLWB, CLFLUSHOPT, CLFLUSH, non-temporal stores, or WBINVD machine instructions.
Enhanced Asynchronous DRAM Refresh (eADR) requires that a non-maskable interrupt (NMI) routine be called to flush the CPU caches before the ADR event can begin. Applications running on an eADR platform do not need to perform flush operations because the hardware should flush the data automatically, but they are still required to perform an SFENCE operation to maintain write order correctness. Stores should be considered persistent only when they are globally visible, which the SFENCE guarantees.

实现持久化编程的几个关键指令:
- CLFLUSH,This instruction, supported in many generations of CPU, flushes a single cache line. Historically, this instruction is serialized, causing multiple CLFLUSH instructions to execute one after the other, without any concurrency.
- CLFLUSHOPT This instruction, newly introduced for persistent memory support, is like CLFLUSH but without the serialization. To flush a range, software executes a CLFLUSHOPT instruction for each 64-byte cache line in the range, followed by a single SFENCE instruction to ensure the flushes are complete before continuing. CLFLUSHOPT is optimized (hence the name) to allow some concurrency when executing multiple CLFLUSHOPT instructions back-to-back
- CLWB Another newly introduced instruction, CLWB stands for cache line write back. The effect is the same as CLFLUSHOPT except that the cache line may remain valid in the cache (but no longer dirty, since it was flushed). This makes it more likely to get a cache hit on this line as the data is accessed again later
- NT stores Another feature that has been around for a while in x86 CPUs is the non-temporal store. These stores are “write combining” and bypass the CPU cache, so using them does not require a flush.
- WBINVD,This kernel-mode-only instruction flushes and invalidates every cache line on the CPU that executes it. After executing this on all CPUs, all stores to persistent memory are certainly in the persistence domain, but all cache lines are empty, impacting performance. In addition, the overhead of sending a message to each CPU to execute this instruction can be significant. Because of this, WBINVD is only expected to be used by the kernel for flushing very large ranges, many megabytes at least.
1 VFS
1.0 基础组件
1.0.1 iov_iter
参考
What is iov_iter
![]()
https://jianchwa.github.io/fs/xfs_v2.html#iov_iter
1.0.2 iomap
我们首先看下iomap结构
#define IOMAP_HOLE 0 /* no blocks allocated, need allocation */
#define IOMAP_DELALLOC 1 /* delayed allocation blocks */
#define IOMAP_MAPPED 2 /* blocks allocated at @addr */
#define IOMAP_UNWRITTEN 3 /* blocks allocated at @addr in unwritten state */
#define IOMAP_INLINE 4 /* data inline in the inode */
struct iomap {
u64 addr; /* disk offset of mapping, bytes */
loff_t offset; /* file offset of mapping, bytes */
u64 length; /* length of mapping, bytes */
u16 type; /* type of mapping */
u16 flags; /* flags for mapping */
struct block_device *bdev; /* block device for I/O */
...
const struct iomap_page_ops *page_ops;
};iomap描述的是从文件的(iomap.offset, iomap.lengh)到block设备上(iomap.addr, iomap.length)的映射;其意义类似ext2的block mapping和ext4的extent;参考generic_perform_write(),执行aops->write_begin()是以page为单位的;而xfs_file_write_iter()使用的iomap_file_bufferred_write(),其调用iomap_start操作的是一个范围;这对于大块的连续IO可以提高代码执行效率。
我们看下iomap的标准操作流程:
dax_iomap_rw()
---
while ((ret = iomap_iter(&iomi, ops)) > 0)
---
(1) iomap_end
(2) advance iter by iter.processed
(3) iomap_begin, based on iter.inode, iter.pos, iter.len, get iomap.addr, iomap.offset, iomap.length
---
iomi.processed = dax_iomap_iter(&iomi, iter);
---
read/write on iomap.addr + (iomap.offset - iter.pos)
---
---这里需要特别说明的是,iomap_begin返回的iomap范围可能会比需要的要大。
1.1 inode
Linux讲究万物皆文件,这个文件就是inode,我们可以将其比作一个c++类,其内部包含了:
- 数据,包括属性(i_mode、i_uid、i_gid、i_a/c/mtime等)和page cache(i_mapping),
- 方法,包括inode_operations(i_op)、file_operations(i_fop)和address_space_operations
以及其他一些辅助性质的成员。
注
:需要注意file和inode的区别,file代表的是一个操作文件的上下文,其中甚至包含了文件操作的偏移,所以,当我们用read/write连续读写文件的时候,不需要传入偏移。
1.1.1 inode的生命周期
一个inode有两个生命周期的计数:
- i_nlink, 代表有一个目录项指向它,它代表的是inode on-disk的生命周期;
- i_count, 代表的是该inode在内存中的生命周期;
本小节,我们主要关注i_count,即inode cache的生命周期。
-
I_NEW
,inode处于创建期间,元数据正在填充过程中;代码可以参考ext2_iget()
注
:元数据填充需要IO,时间不定,所以,内核先创建一个I_NEW状态的inode在inode cache中占个坑,其他所有想要访问该inode的任务都需要等待I_NEW状态的解除。
ext2_iget()
---
inode = iget_locked(sb, ino);
if (!(inode->i_state & I_NEW))
return inode;
ei = EXT2_I(inode);
ei->i_block_alloc_info = NULL;
//这个步骤需要跟存储设备做IO
raw_inode = ext2_get_inode(inode->i_sb, ino, &bh);
// Fill the in-core inode from on-disk inode
unlock_new_inode(inode);
---
iget_locked()
---
spin_lock(&inode_hash_lock);
inode = find_inode_fast(sb, head, ino);
spin_unlock(&inode_hash_lock);
if (inode) {
...
//在此处等待I_NEW被清除掉
wait_on_inode(inode);
return inode;
}
inode = alloc_inode(sb);
if (inode) {
struct inode *old;
spin_lock(&inode_hash_lock);
/* We released the lock, so.. */
old = find_inode_fast(sb, head, ino);
if (!old) {
inode->i_ino = ino;
spin_lock(&inode->i_lock);
inode->i_state = I_NEW;
hlist_add_head(&inode->i_hash, head);
spin_unlock(&inode->i_lock);
inode_sb_list_add(inode);
spin_unlock(&inode_hash_lock);
/* Return the locked inode with I_NEW set, the
* caller is responsible for filling in the contents
*/
return inode;
}
...
}
---
-
被引用
,即i_count > 0,inode通常被dentry引用,之后,文件系统的标准操作都从dentry切入;同时,只有dentry被释放时,才会放掉对inode的引用。具体代码可以参考__d_add()和dentry_unlink_inode(); -
待回收
,在inode的最后一个引用计数被释放后,inode会被存放在per-super的lru list里,等待被回收;同时,dirty inode并不会加入lru list,在writeback完成之后,inode_sync_complete()存入lru list ;参考代码iput_final();
iput_final()
---
if (op->drop_inode)
drop = op->drop_inode(inode);
else
drop = generic_drop_inode(inode);
// !inode->i_nlink || inode_unhashed(inode);
//引用计数为0之后,将inode放到lru中,等待回收
if (!drop && (sb->s_flags & SB_ACTIVE)) {
inode_add_lru(inode);
spin_unlock(&inode->i_lock);
return;
}
...
//对于已经被文件系统除名的文件,即i_nlink = 0, 不必再保留inode,直接释放掉
inode->i_state |= I_FREEING;
if (!list_empty(&inode->i_lru))
inode_lru_list_del(inode);
spin_unlock(&inode->i_lock);
evict(inode);
}
----
执行回收
,当系统内存低于low水线,执行shrink_slab时,会扫描lru list上的inode,按照下面的条件挑选可以回收的inode (此过程可以参考函数inode_lru_isolate):- i_count = 0, 当inode处于lru list期间,其可能被其他任务引用,并增加其引用计数,这种inode会被移出lru list,否则,进行下一步检查;
- 不是dirty inode,如果inode是dirty的,也不能被回收,将inode移出 lru list,否则,进行下一步检查;
-
没有I_REFERENCED标记,参考代码inode_lru_list_add(),只有第二次调用这个函数时,才会被设置这个标记;产生这个标记的一个情况是,
在inode处在lru list上,再次被访问,然后再被释放;
当有这个标记的时候,inode会在lru list中再轮一圈;
super_cache_scan()
-> prune_icache_sb()
-> inode_lru_isolate()
-> dispose_list()- I_FREEING,这个状态的inode最终一定会被evict()释放掉;在I_FREEING期间,其他尝试访问该inode的操作,会被暂时block,待evict()完成之后,再唤醒重试。
1.2 Dentry
Dentry,即Directory Entry-目录项;文件系统使用目录将文件组织成一个树形结构,目录项就是树的节点,它可以指向另外一个目录,即中间节点,也可以指向一个文件,即叶子节点。目录项可以由以下公式总结:
<Directory + Name> -> Inode Number
- On-disk,我们通过Directory所对应的磁盘数据结构(xfs的btree或者ext4的index tree),查询Name对应的项,取出其中Inode Number;
- In-Memory,我们通过Name + Parent dentry指针计算得到的Hash,在全局的Hash表中索引dentry结构,并通过其引用的struct inode结构指针,访问文件;
本小节,我们分析下dentry在内存中的实现。
1.2.1 dentry的功能
dentry在vfs层中,可以提供以下信息:
-
通过快速索引,查找到对应文件名对应的inode,
Hash值的生成,通过函数 full_name_hash() (exported) hash_name() //返回的hash值和len的一起的值 link_path_walk() --- hash_len = hash_name(nd->path.dentry, name); --- 在计算hash值的时候引入了dentry指针 __d_lookup() --- rcu_read_lock(); hlist_bl_for_each_entry_rcu(dentry, node, b, d_hash) { if (dentry->d_name.hash != hash) continue; spin_lock(&dentry->d_lock); if (dentry->d_parent != parent) goto next; if (d_unhashed(dentry)) goto next; if (!d_same_name(dentry, parent, name)) goto next; dentry->d_lockref.count++; found = dentry; spin_unlock(&dentry->d_lock); break; next: spin_unlock(&dentry->d_lock); } rcu_read_unlock(); --- 内核使用了基于链表解决冲突的hash表,我们看到其中比较了parent指针和name字符串; -
目录层级结构,可以访问父目录以及目录内的子dentry(仅限已经在dcache中的文件,即执行过open的,并不包括执行ls操作的);
dentry.d_parent/d_child/dentry.d_subdirs用来组织dentry的层级关系 相关操作在d_add()中完成,使用d_walk()可以遍历一个目录下的子目录项 -
hardlink信息,多个目录项是可以指向同一个inode的,dentry也支持这个功能
harklink,即指向一个inode的多个目录项,dentry通过dentry.u.d_alias挂入inode.i_dentry, __d_find_alias(struct inode *inode)可以返回一个inode的dentry
注:不支持对目录进行hardlink操作,具体原因可以参考连接
filesystem – Why are hard links not allowed for directories? – Ask Ubuntuz
其中最重要的一点事,环形目录问题,如
mkdir -p /tmp/a/b
cd /tmp/a/b
ln -d /tmp/a lcd /tmp/a/b/l/b/l/b/l/b/l/b ….
这破坏了文件组织的树形结构
hardlink是一个目录项,是树的节点,而symlink是一个文件,是叶子节点;两者都可以实现跳转,但是是线上是有本质区别的。
1.2.2 dentry操作
dentry几种状态及其切换:
-
Allocted
从d_alloc()中申请出来的dentry可以被称为'Allocated',此时, - 与父目录dentry的层级关系已经建立, - __d_entry_type(dentry) == 0,即d_is_miss()或者d_is_negative() - 并没有加入dcache的hash table,即d_unhashed() -
Hashed
即该dentry是否被插入了dcache的hash table,主要调用方式: - __d_add(),对应的是通常对应的是lookup操作,比如 ext2_lookup() -> d_splice_alias() -> __d_add() - __d_move(),对应的是rename操作 -
Positive/Negative
这个状态取决于__d_entry_type(dentry),如果为0,则表示此dentry为空, d_is_negative()为TRUE d_flags_for_inode()根据inode的类型返回不同的dentry type, __d_set_inode_and_type()将inode和type设置给dentry, d_is_positive()为TRUE __d_set_inode_and_type()调用方主要有两个, - __d_add(),对应lookup操作,参考ext2_lookup(),如果对应的文件 存在,则获取对应的inode,__d_add()会把inode安装到dentry里; 否则inode为空,此时被加入到hash table里的dentry就是negative的; - __d_instantiate(),针对上一步中,negative的dentry,我们通过 这个接口,给dentry安装inode,之后,inode变为positive;常见的 场景包括:link、create、mkdir
注
:
dcache会故意创建一些negative的dentry,这样可以迅速判断一个文件不存在,而不用执行文件系统的lookup,参考
The value of negative dentries [LWN.net]
1.2.3 root dentry
文件系统的root inode和挂载目录的dentry是怎样的关系呢?参考函数
follow_managed()
---
struct vfsmount *mounted = lookup_mnt(path);
if (mounted) {
dput(path->dentry);
if (need_mntput)
mntput(path->mnt);
path->mnt = mounted;
path->dentry = dget(mounted->mnt_root);
need_mntput = true;
continue;
}
---
struct mount *__lookup_mnt(struct vfsmount *mnt, struct dentry *dentry)
{
struct hlist_head *head = m_hash(mnt, dentry);
struct mount *p;
hlist_for_each_entry_rcu(p, head, mnt_hash)
if (&p->mnt_parent->mnt == mnt && p->mnt_mountpoint == dentry)
return p;
return NULL;
}
do_new_mount()
-> vfs_kern_mount()
-> do_add_mount()
-> graft_tree()
-> attach_recursive_mnt()
-> commit_tree()
-> __attach_mnt()
static void __attach_mnt(struct mount *mnt, struct mount *parent)
{
hlist_add_head_rcu(&mnt->mnt_hash,
m_hash(&parent->mnt, mnt->mnt_mountpoint));
list_add_tail(&mnt->mnt_child, &parent->mnt_mounts);
}从中我们可以得到如下:
- 被挂载的文件系统的root inode并不是被安装在mount point的dentry上,而是以mount point dentry和vfsmount(可区分namespace)为索引,在m_hash中找对应的mount结构,然后获得挂载文件系统的root inode的dentry (IS_ROOT);
- mount结构每次否会被insert到队首,所以,我们看到的都是最新挂载的目录;
1.2.4 d_splice_alias
文件系统的inode.lookup方法大多使用了d_splice_alias(),参考ext2_lookup、ext4_lookup和xfs_vn_lookup等;其中对directory的处理,比较让人困惑,为什么会存在”inode已经有dentry”的情况?因为vfs_rename已经通过d_move对dentry进行了修改。
通过查看d_splice_alias的commit信息,发现了下面这个commit,
commit b5ae6b15bd73e35b129408755a0804287a87e041
Author: Al Viro <viro@zeniv.linux.org.uk>
Date: Sun Oct 12 22:16:02 2014 -0400merge d_materialise_unique() into d_splice_alias()
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
当前的d_splice_alias还包括了原d_materialise_unique的一部分;通过这个commit,我们看看原d_splice_alias:
struct dentry *d_splice_alias(struct inode *inode, struct dentry *dentry)
{
- struct dentry *new = NULL;
-
if (IS_ERR(inode))
return ERR_CAST(inode);
- if (inode && S_ISDIR(inode->i_mode)) {
- spin_lock(&inode->i_lock);
- new = __d_find_any_alias(inode);
- if (new) {
- if (!IS_ROOT(new)) {
- spin_unlock(&inode->i_lock);
- dput(new);
- iput(inode);
- return ERR_PTR(-EIO);
- }
// 如果dentry位于new树下,这会造成loop
- if (d_ancestor(new, dentry)) {
- spin_unlock(&inode->i_lock);
- dput(new);
- iput(inode);
- return ERR_PTR(-EIO);
- }
- write_seqlock(&rename_lock);
- __d_move(new, dentry, false);
- write_sequnlock(&rename_lock);
- spin_unlock(&inode->i_lock);
- security_d_instantiate(new, inode);
- iput(inode);
- } else {
- /* already taking inode->i_lock, so d_add() by hand */
- __d_instantiate(dentry, inode);
- spin_unlock(&inode->i_lock);
- security_d_instantiate(dentry, inode);
- d_rehash(dentry);
- }
- } else {
- d_instantiate(dentry, inode);
- if (d_unhashed(dentry))
- d_rehash(dentry);
- }
- return new;
-}
-EXPORT_SYMBOL(d_splice_alias);
所以,现版本中d_splice_alias令人费解的部分,即__d_unalias,主要来自_materialise_unique;而后者的主要使用者是NFS client;NFS是网络共享文件系统,但是它是弱一致性,参考连接,
nfs-cache-coherence.txt · GitHub
其中关于dentry cache一致性,有以下描述:
Directory entry caching
The Linux NFS client caches the result of all NFS LOOKUP requests. If the requested directory entry exists on the server, the result is referred to as a positive lookup result. If the requested directory entry does not exist on the server (that is, the server returned ENOENT), the result is referred to as negative lookup result.
To detect when directory entries have been added or removed on the server, the Linux NFS client watches a directory’s mtime. If the client detects a change in a directory’s mtime, the client drops all cached LOOKUP results for that directory
. Since the directory’s mtime is a cached attribute, it may take some time before a client notices it has changed. See the descriptions of the acdirmin, acdirmax, and noac mount options for more information about how long a directory’s mtime is cached.Caching directory entries improves the performance of applications that do not share files with applications on other clients. Using cached information about directories can interfere with applications that run concurrently on multiple clients and need to detect the creation or removal of files quickly, however. The lookupcache mount option allows some tuning of directory entry caching behavior.
Before kernel release 2.6.28, the Linux NFS client tracked only positive lookup results. This permitted applications to detect new directory entries created by other clients quickly while still providing some of the performance benefits of caching. If an application depends on the previous lookup caching behavior of the Linux NFS client, you can use lookupcache=positive.
If the client ignores its cache and validates every application lookup request with the server, that client can immediately detect when a new directory entry has been either created or removed by another client. You can specify this behavior using lookupcache=none. The extra NFS requests needed if the client does not cache directory entries can exact a performance penalty. Disabling lookup caching should result in less of a performance penalty than using noac, and has no effect on how the NFS client caches the attributes of files.
结合下划线部分,参考d_splice_alias中关于__d_unalias的部分,内核并没有直接将目录下的所有的dentry全部drop掉,而是在发现存在对于同一个directory inode已经存在dentry的时候,使用__d_unalias替换掉。
IS_ROOT的分支,也来自NFS,参考函数d_obtain_alias(),具体原因待研究。。。
1.2.5 lookup
参考连接:
Dcache scalability and RCU-walk [LWN.net]
Pathname lookup in Linux [LWN.net]
RCU-walk: faster pathname lookup in Linux [LWN.net]
Scaling dcache with RCU | Linux Journal
当我们尝试打开文件/home/will/Desktop/linux-stable时,内核实际上把它分解成:
1. lookup "/"
2. lookup "home" in dentry of "/"
3. lookup "will" in dentry of "/home"
4. lookup "Desktop" in dentry of "/home/will"
5. lookup "linux-stable" in dentry of "/home/will/Desktop"
dcache lookup只会保证每一步的lookup操作的原子性,而不会保证整个对/home/will/Desktop/linux-stable的lookup的原子性
;换句话说,我们最终得到的可能是/home/kate/Desktop/linux-stable。
lookup操作分为两种ref-walk和rcu-walk两种,ref和rcu其实对应的是,如何保证在执行操作期间dentry结构不会被释放,尤其是rcu:
- ref-walk使用dentry.d_lock保护dentry.d_parent和dentry.d_name不会被rename;使用dentry.d_lockref来保证父dentry以及dentry.d_inode不会被释放,这使得我们可以执行更加复杂的操作,比如进入文件系统的lookup方法,甚至等待IO;
- rcu-walk使用rcu read cirtical section保护父dentry不会被释放,使用parent dentry.d_seq保护其不会被修改,尤其是unlink操作;使用dentry.d_seq保护dentry.d_name和dentry.d_parent不会被rename;如果发现异常,会回退到ref-walk;
The cases where rcu-walk cannot continue are: * NULL dentry (ie. creat or negative lookup) * parent with ->d_op->d_hash * parent with d_inode->i_op->permission or ACLs * Following links * Dentry with ->d_op->d_revalidate
为什么seqcount_t的扩展性更好? 其中没有任何原子操作;
typedef struct seqcount {
unsigned sequence;
} seqcount_t;
static inline unsigned __read_seqcount_begin(const seqcount_t *s)
{
unsigned ret;
repeat:
ret = READ_ONCE(s->sequence);
if (unlikely(ret & 1)) {
cpu_relax();
goto repeat;
}
return ret;
}
static inline void raw_write_seqcount_begin(seqcount_t *s)
{
s->sequence++;
smp_wmb();
}
static inline void raw_write_seqcount_end(seqcount_t *s)
{
smp_wmb();
s->sequence++;
}
Note:
内核之所以使用list处理hashtable的冲突,是因为list可以实现rcu版,rcu下的lookup操作扩展性更好。
当dcache中没有找对对应dentry,或者negative的dentry,会进入__lookup_slow,其主要分成两个步骤:
- d_lookup_parallel(),申请dentry并插入lookup hashtable,注意,此处并不是dcache的hashtable;此时的dentry处于unhashed状态,不会被lookup到;其他的并发的lookup操作都会进入到这个函数;
- inode->i_op->lookup(),文件系统的lookup操作,会产生两个IO操作,目录项的lookup和获取on-disk inode;不论是否找对对应的目录项,都会对dentry插入d_hash;
这里需要特别说明的是,因为文件系统的lookup操作是IO操作,可能速度较慢,并行的其他lookup操作,通过in_lookup_hash的hash lock的同步,会睡眠在d_wait_lookup();
Note:
一个问题是,在lookup期间,所有的任务都会进入到该路径的任务,执行d_alloc(),这里是不是有点多余?是不是可以将该negative的dentry + in_lookup插入到d_hash,这样其他lookup该dentry的任务可以直接等待
1.2.6 symbol link
symbol link的本质是在一个文件中保存一个路径,其相当于一个文件系统指向文件的指针;
在分析symbol link的处理之前,我们需要首先看下内核是如何解析文件路径的。
“/home/will/Desktop/linux-stable”这样的路径,是完全由内核解析的,具体代码如下:
以下代码已经将部分错误分支处理去掉,以使代码变得更清晰
link_path_walk()
---
while (*name=='/')
name++;
if (!*name)
return 0;
for(;;) {
//对路径中 .. 和 . 的处理,类似于/home/will/Deskop/../Download
type = LAST_NORM;
if (name[0] == '.') switch (hashlen_len(hash_len)) {
case 2:
if (name[1] == '.') {
type = LAST_DOTDOT;
nd->flags |= LOOKUP_JUMPED;
}
break;
case 1:
type = LAST_DOT;
}
// hash_name函数会以'/'作为name的结尾来返回len
hash_len = hash_name(nd->path.dentry, name);
nd->last.hash_len = hash_len;
nd->last.name = name;
nd->last_type = type;
// 指向路径的下一个元素
name += hashlen_len(hash_len);
if (!*name)
goto OK;
// 路径中加几个'/'都没有关系
do {
name++;
} while (unlikely(*name == '/'));
if (unlikely(!*name)) {
} else {
//处理当前的路径元素
/* not the last component */
err = walk_component(nd, WALK_FOLLOW | WALK_MORE);
}
...
}
}简单来说,就是依次对path的每一个元素调用walk_component()。
引入symbol link之后,路径的某一个元素,会变成一个另外一个路径,甚至,symlink路径的一部分也可能是另外一个symlink,所以,这里引入了一个stack的概念,例如:
/home/will/Desktop/sourcecode/linux-stable
|
+--> /mnt/disk1/AAAA/sourcecode
|
+--> /mnt/disk2/BBBB
路径的解析过程为
stack[0] home -> will -> Dektop -> sourcecode +-> linux-stable
____________/\__________ |
/ \ |
stack[1] mnt -> disk1 -> AAAA |
____________/\__________ |
/ \ |
mnt -> disk2 -> BBBB -+
与symlink stack有关的代码为:
扩展stack,
push stack:
walk_component() -> step_into() -> pick_link() -> nd_alloc_stack()
link_path_walk()
---
if (err) {
// 此处调用的是文件系统的get_link方法
const char *s = get_link(nd);
...
if (unlikely(!s)) {
} else {
nd->stack[nd->depth - 1].name = name;
name = s;
continue;
}
}
---
pop stack:
link_path_walk()
---
if (unlikely(!*name)) {
OK:
/* pathname body, done */
if (!nd->depth)
return 0;
// Stack is popped here
name = nd->stack[nd->depth - 1].name;
/* trailing symlink, done */
if (!name)
return 0;
/* last component of nested symlink */
err = walk_component(nd, WALK_FOLLOW);
} else {
/* not the last component */
err = walk_component(nd, WALK_FOLLOW | WALK_MORE);
}
---
NO WALK_MORE
walk_component() -> step_into() -> put_link() -> nd->depth--
1.3 mount
关于mount有两个关键点需要掌握:
-
mount操作是将一棵目录树”
嫁接
“到另外一棵目录树上;根文件系统为其他所有文件系统提供了一棵根树; - mount namespace,即在不同的namespace里,进程看到的挂载点并不相同
另外,有两个看起来比较相似的结构体,mount和vfsmount;具体来源可以参考:
vfs: start hiding vfsmount guts series
Almost all fields of struct vfsmount are used only by core VFS (and
a fairly small part of it, at that). The plan: embed struct vfsmount
into struct mount, making the latter visible only to core parts of VFS.
Then move fields from vfsmount to mount, eventually leaving only
mnt_root/mnt_sb/mnt_flags in struct vfsmount. Filesystem code still
gets pointers to struct vfsmount and remains unchanged; all such
pointers go to struct vfsmount embedded into the instances of struct
mount allocated by fs/namespace.c. When fs/namespace.c et.al. get
a pointer to vfsmount, they turn it into pointer to mount (using
container_of) and work with that.This is the first part of series; struct mount is introduced,
allocation switched to using it.Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
总之,vfsmount和mount结构可以看成是一个。
1.3.1 嫁接
实现目录树嫁接的关键是__lookup_mnt()函数,如下:
struct mount *__lookup_mnt(struct vfsmount *mnt, struct dentry *dentry)
{
struct hlist_head *head = m_hash(mnt, dentry);
struct mount *p;
hlist_for_each_entry_rcu(p, head, mnt_hash)
if (&p->mnt_parent->mnt == mnt && p->mnt_mountpoint == dentry)
return p;
return NULL;
}
函数通过vfsmount和dentry指针,找到匹配的mount结构;
- dentry,挂载点的目录项指针;
-
vfsmount,注意,这里的vfsmount是挂载点所在的目录的vfsmount,它在path_init()被设置;
path_init() --- if (*s == '/') { .... // nd->root = current->fs->root set_root(nd); // nd->path = nd->root if (likely(!nd_jump_root(nd))) return s; ... } else if (nd->dfd == AT_FDCWD) { if (flags & LOOKUP_RCU) { ... } else { //nd->path = current->fs->pwd get_fs_pwd(current->fs, &nd->path); nd->inode = nd->path.dentry->d_inode; } return s; } ---
mount,这是要寻找的挂载点的mount结构,其mnt_parent指向挂载点目录的mount;参考代码:
do_add_mount()
---
parent = real_mount(path->mnt);
err = graft_tree(newmnt, parent, mp);
-> attach_recursive_mnt()
-> mnt_set_mountpoint()
---当从一棵目录树通过挂载点进入另外一棵目录树时,dentry和vfsmount都要切换:
walk_component()
-> follow_managed()
---
if (managed & DCACHE_MOUNTED) {
struct vfsmount *mounted = lookup_mnt(path);
if (mounted) {
dput(path->dentry);
if (need_mntput)
mntput(path->mnt);
path->mnt = mounted;
path->dentry = dget(mounted->mnt_root);
need_mntput = true;
continue;
}
---
-> step_into()
-> path_to_nameidata()
---
nd->path.mnt = path->mnt;
nd->path.dentry = path->dentry;
---
1.3.2 loop mount
或者叫bind mount,其操作如下:
mkdir /tmp/foo
touch /tmp/foo/will
mkdir /tmp/barmount –bind /tmp/foo /tmp/bar
之后,我们就可以通过/tmp/bar访问/tmp/foo了;但是,使用symlink也能实现类似的功能,如下
mkdir /tmp/foo
touch /tmp/foo/willln -s /tmp/foo /tmp/bar
两者有什么区别呢?我们可以从两者的原理上分析:
- symlink,在解析symlink的时候,是基于当前的目路树,对路径进行重新解析,进而转向另外一个目录或者文件;
- bind mount,通过vfsmount+dentry找到一个新的mount,跳转到另外一个目录; 文中提到:
Bind mounts can be thought of as a sort of symbolic link at the filesystem level. Using mount –bind, it is possible to create a second mount point for an existing filesystem, making that filesystem visible at a different spot in the namespace.
Bind mounts are thus useful for creating specific views of the filesystem namespace; one can, for example, create a bind mount which makes a piece of a filesystem visible within an environment which is otherwise closed off with chroot().
我们先看下chroot是如何实现的,
修改task_struct.fs.root
ksys_chroot()
---
error = user_path_at(AT_FDCWD, filename, lookup_flags, &path);
set_fs_root(current->fs, &path);
---
mntget(path->mnt);
dget(path->dentry);
spin_lock(&fs->lock);
write_seqcount_begin(&fs->seq);
old_root = fs->root;
fs->root = *path;
write_seqcount_end(&fs->seq);
spin_unlock(&fs->lock);
if (old_root.dentry) {
dput(path->dentry);
mntput(path->mnt);
}
---
---
这个结构会在fork的时候,被子任务继承
copy_process()
-> copy_fs()
-> copy_fs_struct()
---
spin_lock(&old->lock);
fs->root = old->root;
path_get(&fs->root);
fs->pwd = old->pwd;
path_get(&fs->pwd);
spin_unlock(&old->lock);
---
结合解析路径时,如果symlink是绝对路径,在chroot之后,解析出的inode会改变;而bind mount,如果chroot的路径依然原文件系统下,那么vfsmount不会变化,在dentry没有改变的情况下,得到的结果是不变的。
那么bind mount如何实现呢?
do_loopback()
---
// bind mount directory
old = real_mount(old_path.mnt);
// mount point
parent = real_mount(path->mnt);
mnt = clone_mnt(old, old_path.dentry, 0);
---
mnt = alloc_vfsmnt(old->mnt_devname);
...
//增加bind mount directory所在文件系统的sb的引用计数
atomic_inc(&sb->s_active);
mnt->mnt.mnt_sb = sb;
// bind mount的root就是bind mount directory
mnt->mnt.mnt_root = dget(root);
//这个会在set_mount_point的时候再次更新
mnt->mnt_mountpoint = mnt->mnt.mnt_root;
mnt->mnt_parent = mnt;
lock_mount_hash();
list_add_tail(&mnt->mnt_instance, &sb->s_mounts);
unlock_mount_hash();
---
err = graft_tree(mnt, parent, mp);
-> attach_recursive_mnt()
-> mnt_set_mountpoint(dest_mnt, dest_mp, source_mnt);
bind mount实现read only,基于的是mount结构上的RDONLY flag
mount -t bind /home/will/Desktop/sourcecode /mnt/readonly
mount -o remount,ro /mnt/readonly
filename_create()
do_renameat2()
do_unlinkat()
do_last()
....
mnt_want_write()
-> __mnt_want_write()
---
preempt_disable();
mnt_inc_writers(mnt);
...
smp_rmb();
if (mnt_is_readonly(m)) {
mnt_dec_writers(mnt);
ret = -EROFS;
}
preempt_enable();
return ret;
---
1.4 page cache
本小节我们主要看Page Cache在系统中如何组织和使用,至于其回收和Writeback,可以参考:
Linux 内存管理_jianchwa的博客-CSDN博客_内存管理器
1.4.1 radix tree
page cache使用radix tree维护,本小节,我们看下radix tree如何实现,并讨论下,使用radix tree的原因。
radix tree,本质上是一个数组,容量与每个节点的slot的个数和高度有关,即N^H,如下:
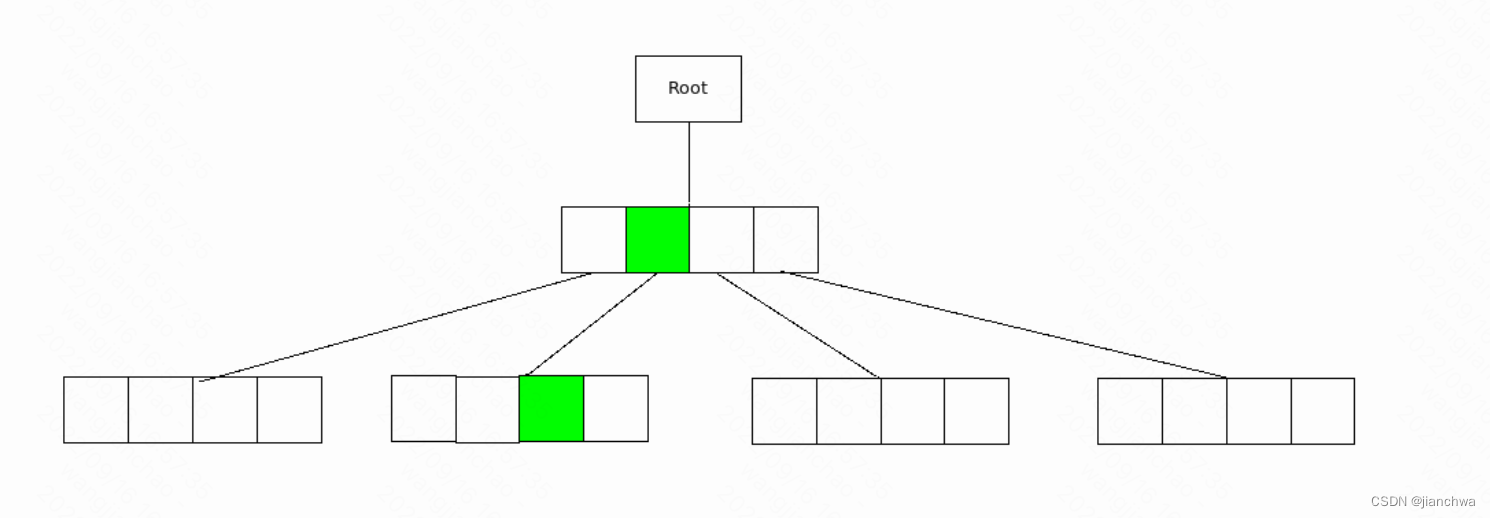
与普通数组不同的是,radix tree支持空洞,如下:
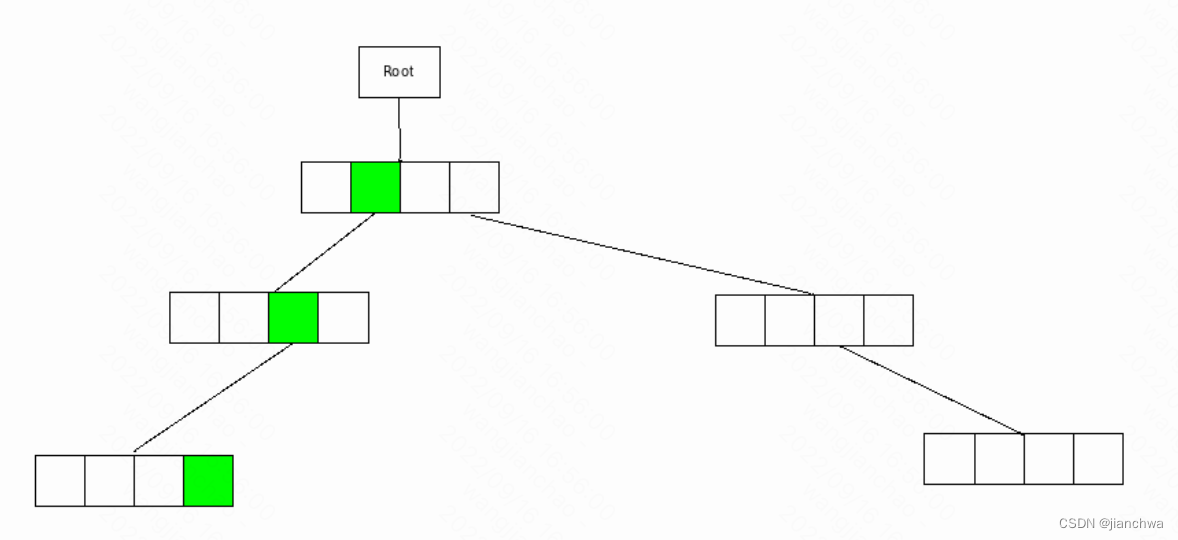
所以,他比一般的数组节省内存,同时,也保留了数组查询块的特点,radix tree不是O1,而是OH,而H = logN(S),其中S是总容量,N越大,H越小。
下面,我们看下Linux内核中,radix tree是如何实现的:
-
radix_tree_node
,我们看下radix_tree_node的实现:struct radix_tree_node { unsigned int count; ... void __rcu *slots[RADIX_TREE_MAP_SIZE]; unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]; }; #define RADIX_TREE_MAP_SHIFT (6) #define RADIX_TREE_MAP_SIZE (1UL << RADIX_TREE_MAP_SHIFT) #define RADIX_TREE_MAX_TAGS 3 #define RADIX_TREE_TAG_LONGS \ ((RADIX_TREE_MAP_SIZE + BITS_PER_LONG - 1) / BITS_PER_LONG) - 每个node的容量为32, - count,保存这个node中已经安装的slot的数量, - tags,每个slot还有3bits的tag,用来保存一些属性信息,比如page cache的三个属性是: /* * Radix-tree tags, for tagging dirty and writeback pages within the pagecache * radix trees */ #define PAGECACHE_TAG_DIRTY 0 #define PAGECACHE_TAG_WRITEBACK 1 #define PAGECACHE_TAG_TOWRITE 2 -
extend
,当插入的元素的index超过了当前的最大容量,则需要拓展radix tree的Height,extend的过程大致如下: Root Root / \ -\ / Node0 Node1 -/ Node2 / \ Node0 Node1 static int radix_tree_extend(struct radix_tree_root *root, unsigned long index) { ... /* Figure out what the height should be. */ height = root->height + 1; while (index > radix_tree_maxindex(height)) height++; ... do { if (!(node = radix_tree_node_alloc(root))) return -ENOMEM; ... /* Increase the height. */ newheight = root->height+1; node->count = 1; node->parent = NULL; slot = root->rnode; if (newheight > 1) { slot = indirect_to_ptr(slot); slot->parent = node; } //将原来的root node安装到新的root node的slot[0] node->slots[0] = slot; node = ptr_to_indirect(node); rcu_assign_pointer(root->rnode, node); root->height = newheight; } while (height > root->height); out: return 0; }
4系内核中,radix tree引入了order的概念,参考下图:
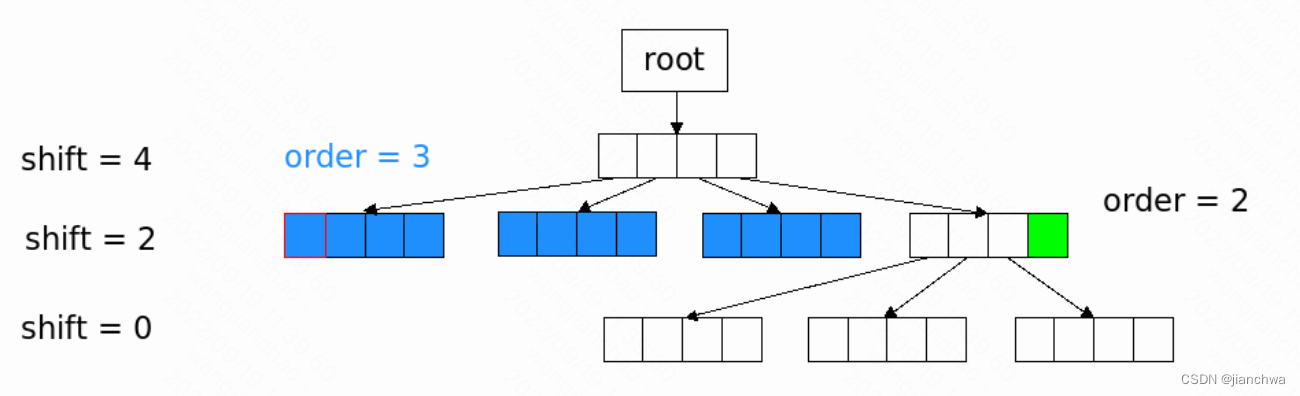
这个版本的radix tree,使用shift替换了height的概念;order代表的是,按2^order对齐的范围,如上图所示的order = 3和order = 2;在order范围内,slot都指向其第一个成员(蓝色红框),同时,子成员都被释放;参考代码:
__radix_tree_create()
---
//遍历的停止条件,比较order
while (shift > order) {
shift -= RADIX_TREE_MAP_SHIFT;
if (child == NULL) {
/* Have to add a child node. */
child = radix_tree_node_alloc(gfp, node, root, shift,
offset, 0, 0);
rcu_assign_pointer(*slot, node_to_entry(child));
if (node)
node->count++;
} else if (!radix_tree_is_internal_node(child))
break;
/* Go a level down */
node = entry_to_node(child);
offset = radix_tree_descend(node, &child, index);
slot = &node->slots[offset];
}
---
insert_entries()
---
if (node) {
if (order > node->shift)
n = 1 << (order - node->shift);
else
n = 1;
offset = get_slot_offset(node, slot);
} else {
n = 1;
offset = 0;
}
if (n > 1) {
offset = offset & ~(n - 1);
slot = &node->slots[offset];
}
sibling = xa_mk_sibling(offset);
...
for (i = 0; i < n; i++) {
struct radix_tree_node *old = rcu_dereference_raw(slot[i]);
// 第一个成员保存item,其他保存sibling指针
if (i) {
rcu_assign_pointer(slot[i], sibling);
} else {
rcu_assign_pointer(slot[i], item);
}
//释放掉所有子成员
if (xa_is_node(old))
radix_tree_free_nodes(old);
if (xa_is_value(old))
node->nr_values--;
}
---
1.4.2 page cache tags
page cache在radix tree中存在三个tag,即
-
PAGECACHE_TAG_DIRTY ,用来标记脏页,
标记脏页 __set_page_dirty() --- xa_lock_irqsave(&mapping->i_pages, flags); if (page->mapping) { /* Race with truncate? */ account_page_dirtied(page, mapping); radix_tree_tag_set(&mapping->i_pages, page_index(page), PAGECACHE_TAG_DIRTY); } xa_unlock_irqrestore(&mapping->i_pages, flags); --- 在writeback时,使用该标记将脏页写出 write_cache_pages() --- if (wbc->sync_mode == WB_SYNC_ALL || wbc->tagged_writepages) tag = PAGECACHE_TAG_TOWRITE; else tag = PAGECACHE_TAG_DIRTY; if (wbc->sync_mode == WB_SYNC_ALL || wbc->tagged_writepages) tag_pages_for_writeback(mapping, index, end); done_index = index; while (!done && (index <= end)) { int i; nr_pages = pagevec_lookup_range_tag(&pvec, mapping, &index, end, tag); if (nr_pages == 0) break; for (i = 0; i < nr_pages; i++) { struct page *page = pvec.pages[i]; done_index = page->index; lock_page(page); if (!clear_page_dirty_for_io(page)) goto continue_unlock; ret = (*writepage)(page, wbc, data); if (--wbc->nr_to_write <= 0 && wbc->sync_mode == WB_SYNC_NONE) { done = 1; break; } } pagevec_release(&pvec); cond_resched(); } --- dirty转为writeback __test_set_page_writeback() --- if (mapping && mapping_use_writeback_tags(mapping)) { ... xa_lock_irqsave(&mapping->i_pages, flags); ret = TestSetPageWriteback(page); if (!ret) { radix_tree_tag_set(&mapping->i_pages, page_index(page), PAGECACHE_TAG_WRITEBACK); ... } if (!PageDirty(page)) radix_tree_tag_clear(&mapping->i_pages, page_index(page), PAGECACHE_TAG_DIRTY); if (!keep_write) radix_tree_tag_clear(&mapping->i_pages, page_index(page), PAGECACHE_TAG_TOWRITE); xa_unlock_irqrestore(&mapping->i_pages, flags); } --- -
PAGECACHE_TAG_WRITEBACK,IO发出但是还没有完成的Page标记为writeback,参考代码:
__test_set_page_writeback() test_clear_page_writeback() 等待处于wrieteback状态,即写IO发出但未完成 __filemap_fdatawrite_range() --- pagevec_init(&pvec); while (index <= end) { unsigned i; nr_pages = pagevec_lookup_range_tag(&pvec, mapping, &index, end, PAGECACHE_TAG_WRITEBACK); if (!nr_pages) break; for (i = 0; i < nr_pages; i++) { struct page *page = pvec.pages[i]; wait_on_page_writeback(page); ClearPageError(page); } pagevec_release(&pvec); cond_resched(); } --- -
PAGECACHE_TAG_TOWRITE,TOWRITE tag的存在是为了避免sync的时候livelock,具体参考函数及其注释:
This function scans the page range from @start to @end (inclusive) and tags all pages that have DIRTY tag set with a special TOWRITE tag. The idea is that write_cache_pages (or whoever calls this function) will then use TOWRITE tag to identify pages eligible for writeback. This mechanism is used to avoid livelocking of writeback by a process steadily creating new dirty pages in the file (thus it is important for this function to be quick so that it can tag pages faster than a dirtying process can create them). tag_pages_for_writeback() --- xa_lock_irq(&mapping->i_pages); radix_tree_for_each_tagged(slot, &mapping->i_pages, &iter, start, PAGECACHE_TAG_DIRTY) { if (iter.index > end) break; radix_tree_iter_tag_set(&mapping->i_pages, &iter, PAGECACHE_TAG_TOWRITE); tagged++; if ((tagged % WRITEBACK_TAG_BATCH) != 0) continue; ... } xa_unlock_irq(&mapping->i_pages); }
1.4.3 mmap
对page cache的访问有两方式:
- read/write系统调用
- mmap到地址空间内,直接访问
通过mmap访问可以节省系统调用相关代码的开销,并减少一次内存拷贝,是最高效的访问方式。
mmap主要涉及两个点:
-
创建vma,vma代表的是一段进程的地址空间,其中保存的是相关地址发生page cache之后的策略,
- 通过file_operations.get_unmapped_area()回调获取虚拟地址,换句话说,文件系统可以通过该回调影响文件的映射的地址;
-
把涉及文件访问的相关策略设置到vma中;具体可以参考以下函数:
-
generic_file_map() 设置vma->ops为generic_file_vm_ops vma_set_anonymous() 设置vma->ops为NULL handle_pte_fault() --- if (!vmf->pte) { if (vma_is_anonymous(vmf->vma)) // check vma->ops return do_anonymous_page(vmf); else return do_fault(vmf); } ---
-
-
发生page fault之后,handle_pte_fault() 处理,其中有几个关键的函数:
__do_fault() -> filemap_fault() __do_fault()负责准备好page,并且为读操作准备好page,其中使用了filemap_read_page() do_page_mkwrite() 则负责为写操作准备好page, 比如 filemap_page_mkwrite() --- file_update_time(vmf->vma->vm_file); set_page_dirty(page); --- 比如 ext4_page_mkwrite() --- /* Delalloc case is easy... */ if (test_opt(inode->i_sb, DELALLOC) && !ext4_nonda_switch(inode->i_sb)) { do { err = block_page_mkwrite(vma, vmf, ext4_da_get_block_prep); } while (err == -ENOSPC && ext4_should_retry_alloc(inode->i_sb, &retries)); goto out_ret; } --- 如果是非delay allocation模式,还会在这里分配空间 finish_fault() -> do_set_pte() 设置页表 do_fault_around() -> filemap_map_pages() 这是一个优化,do_fault_around()尝试将发生fault周围的page都map起来 fault_dirty_shared_page() -> balance_dirty_pages_ratelimited() 这点跟正常的write系统调用一样
另外,我们考虑下,系统如何感知到mmap的page上的写操作?答案是,writeprotect,我们看下函数:
handle_pte_fault()
---
// vmf->pte is not NULL and present
if (vmf->flags & FAULT_FLAG_WRITE) {
if (!pte_write(entry))
return do_wp_page(vmf);
entry = pte_mkdirty(entry);
}
---
do_wp_page()会调用到page_mkwrite,其中会调用set_page_dirty()和
file_update_time()等;
而write_cache_pages()则会调用
clear_page_dirty_for_io() -> page_mkclean()清除相关标记位
1.4.4 direct IO
buffer read IO且cache miss时,IO分为两步:
- 用cache page组成bio提交给block层并直到设备;存储设备通过DMA向cache page中写入数据,然后返回IO成功;
- 从cache page中将数据拷贝到用户buffer
Direct IO是指,直接通过用户Buffer组装成bio提交给block层并直到设备,由此,我们可以获得以下:
- 避免引入page cache,有时用户想要在自己的程序里维护cache;
- 使用异步IO,Linux内核的buffer IO都是同步的,其内部并没有维护异步上下文的机制;io-uring其实也是伪异步,它本质上是使用了一个内核线程上下文等待IO;但是使用direct IO,其可以使用bio中的异步上下文,实现真异步;
direct IO的实现分为两个关键部分:
-
准备好用户态buffer;在buffer IO或者其他与内核交互时,我们会用到copy_from/to_user系列接口,如果访问的用户态地址依然没有分配物理内存,则会在page fault中分配(如果地址的非法的,则会返回-EFAULT,参考
5. Kernel level exception handling — The Linux Kernel documentation
);但是,显然,我们不能给这样一个地址到设备中,于是,direct IO需要使用get_user_pages_fast()保证这些page都申请好了,并增加引用计数; -
组装bio,其中最重要的是获取所需内容在磁盘上的地址,目前主要有两种框架:
generic_file_read_iter() -> mapping->a_ops->direct_IO() ext2_direct_IO() -> blockdev_direct_IO(iocb, inode, iter, ext2_get_block); ext4_file_read_iter() -> ext4_dio_read_iter() -> iomap_dio_rw(iocb, to, &ext4_iomap_ops, NULL, 0, 0);
1.5 DAX
DAX,direct access extensions, 其官方定义为,
File system extensions to bypass the page cache and block layer to mmap persistent memory, from a PMEM block device, directly into a process address space
DAX的引入有两几方面的原因:
- 兼容现有的通用存储架构,目前绝大多数应用都是基于POSIX API和树形目录文件存储和组织数据的,所以NVDIMM也必须如此;
- 通过0.3小节中的介绍,NVDIMM的存储的访问延迟已经达到DDR的相同数量级,这时,额外的内存拷贝甚至系统调用及内核代码开销都会显现出来,所以,我们需要的是direct IO + mmap;
- NVDIMM设备的另一个优势是支持字节级访问,这对于存储数据结构的设计是革命性的(虽然目前的AEP实际表现并没有那么好);所以,我们还需要bypass只支持块级访问的Block层;
所以,DAX在整个Linux内核存储栈上开了一个旁路,bypass page cache和block layer,如下:

1.5.1 Pmem
Pmem设备是用来支持DAX模式的块设备;嗯?既然bypass了block层,为什么还需要块设备?原因在于,DAX要兼容原来的文件系统,比如Ext2、Ext4、XFS等,而这些文件系统的元数据依然是基于块设备,所以nvdimm设备依然需要块设备访问接口;参考如下代码:
pmem_submit_bio()
---
bio_for_each_segment(bvec, bio, iter) {
if (op_is_write(bio_op(bio)))
rc = pmem_do_write(pmem, bvec.bv_page, bvec.bv_offset,
iter.bi_sector, bvec.bv_len);
else
rc = pmem_do_read(pmem, bvec.bv_page, bvec.bv_offset,
iter.bi_sector, bvec.bv_len);
if (rc) {
bio->bi_status = rc;
break;
}
}
bio_endio(bio);
---
pmem_submit_bio()
-> pmem_do_write()
//数据的写入地址,从sector转换而来
-> phys_addr_t pmem_off = sector * 512 + pmem->data_offset;
-> write_pmem();
-> memcpy_flushcache()
-> __memcpy_flushcache()
//写入size一定是512对齐的
---
/* 4x8 movnti loop */
while (size >= 32) {
asm("movq (%0), %%r8\n"
"movq 8(%0), %%r9\n"
"movq 16(%0), %%r10\n"
"movq 24(%0), %%r11\n"
"movnti %%r8, (%1)\n"
"movnti %%r9, 8(%1)\n"
"movnti %%r10, 16(%1)\n"
"movnti %%r11, 24(%1)\n"
:: "r" (source), "r" (dest)
: "memory", "r8", "r9", "r10", "r11");
dest += 32;
source += 32;
size -= 32;
}
---
上图中,最终的拷贝操作使用到了ntstore操作,该指令可以保证指令返回时,数据落入非易失性存储介质。但是,从实现上,我们可以看到,
pmem并不支持sector级更新的原子性
。
这对文件系统metadata更新正确性是否会造成影响?
- Ext4和Xfs都通过日志来保证metadata更新的原子性,即all or nothing;
- Ext4所使用的jbd2和Xfs log,都有checksum机制,在异常重启后recovery过程中,可以识别出不完整的日志,尤其是最后的commit record;
1.5.2 fs/dax
fs/dax.c内提供了文件系统实现dax的几个通用功能:
read/write dax访问
,也就是调用read/write系列接口时,dax_iomap_rw()通过文件系统提供的iomap_begin/end回调,获取文件的映射,然后直接访问pmem,这个过程中bypass了page cache和block层;另外,对于写操作,参考上一小节,其使用的ntstore,可以保证数据落入掉电保护域。
dax_iomap_rw()
---
while ((ret = iomap_iter(&iomi, ops)) > 0)
---
(1) iomap_end
(2) advance iter by iter.processed
(3) iomap_begin, based on iter.inode, iter.pos, iter.len, get iomap.addr, iomap.offset, iomap.length
---
iomi.processed = dax_iomap_iter(&iomi, iter);
---
read/write on iomap.addr + (iomap.offset - iter.pos)
---
---
dax_iomap_iter()
---
/*
iter->pos iter->len
| |
|--------------------------------|
mmapped chunk in file
iomap.offset iomap.length
*/
length = min(iter->len, iter->iomap.offset + iter->iomap.length - iter->pos);
pos = iter->pos;
end = pos + length;
while (pos < end) {
// Copy one page per round
unsigned offset = pos & (PAGE_SIZE - 1);
const size_t size = ALIGN(length + offset, PAGE_SIZE);
const sector_t sector = (iomap->addr + (pos & PAGE_MASK) - iomap->offset) >> 9;
// Get the address of pmem for direct access
ret = bdev_dax_pgoff(bdev, sector, size, &pgoff);
map_len = dax_direct_access(dax_dev, pgoff, PHYS_PFN(size),
&kaddr, NULL);
...
if (iov_iter_rw(iter) == WRITE)
xfer = dax_copy_from_iter(dax_dev, pgoff, kaddr,
map_len, iter);
else
xfer = dax_copy_to_iter(dax_dev, pgoff, kaddr,
map_len, iter);
pos += xfer;
length -= xfer;
...
}
---
剩下的大都是关于page fault相关
,其中比较特殊的是,本来用来存储page cache address_space.i_pages中存储了一种特殊的entry,其包含以下信息:
-
pfn,对应的pmem的page的页帧号,这个信息在执行truncate_inode_pages_range()时有用到,参考代码:
truncate_inode_pages_range() -> truncate_exceptional_pvec_entries() -> dax_delete_mapping_entry() -> __dax_invalidate_entry() -> dax_disassociate_entry() --- for_each_mapped_pfn(entry, pfn) { struct page *page = pfn_to_page(pfn); page->mapping = NULL; page->index = 0; } --- 此处获取pfn信息,虽然也可以通过iomap,但是此过程需要访问元数据,效率不如直接保存在 address_space.i_pages里效率高 page->mapping和page->index代表的是该page所在的文件及在文件中的偏移 -
entry状态,目前有以下几种:
-
LOCKED,用于将一定范围锁起来,以保证整个操作的原子性,尤其是在insert pte时可能会申请内存,并且sleep;在正常的page fault中,这个操作是通过lock_page实现的;这里之所以没有使用这个标记,可能是因为在pmem的page结构体可能是保存在nvdimm上的(参考nvdimm create-namespace –map参数)
-
PMD or PTE,如果PMD bit设置了,就代表这个entry是pmd的;
-
ZERO,对应read fault on unmapped page,此时会给其分配一个zero page;zero page可能是pmd的,在有pte fault(没能分配到pmd大小的page导致pmd fault fallback to pte fault)发生的时候,是可以降级拆分的;
-
EMPTY,与LOCKED配合用来占坑的
-
之前提到read/write dax路径访问pmem的时候,写操作直接通过ntstore,可以保证数据直接落入掉电保护域。mmap的文件将pmem直接暴露给用户,并不能强制用户使用持久化编程技术,为了保证fsync的语义,dax虽然bypass page cache,但是依然使用了writeback子系统,并借此实现数据的flsuh,如下:
-
Mark the entry and hand the inode to writeback subsystem
dax_fault_iter() -> dax_insert_entry() --- if (dirty) __mark_inode_dirty(mapping->host, I_DIRTY_PAGES); xas_reset(xas); xas_lock_irq(xas); if (dax_is_zero_entry(entry) || dax_is_empty_entry(entry)) { ... } else { xas_load(xas); /* Walk the xa_state */ } if (dirty) xas_set_mark(xas, PAGECACHE_TAG_DIRTY); xas_unlock_irq(xas); --- -
flush page out and make page write-protected again in writepages
ext2_dax_writepages/ext4_dax_writepages/xfs_dax_writepages() -> dax_writeback_mapping_range() --- xas_lock_irq(&xas); xas_for_each_marked(&xas, entry, end_index, PAGECACHE_TAG_TOWRITE) { ret = dax_writeback_one(&xas, dax_dev, mapping, entry); ... } xas_unlock_irq(&xas); --- dax_writeback_one() --- /* Lock the entry to serialize with page faults */ dax_lock_entry(xas, entry); pfn = dax_to_pfn(entry); count = 1UL << dax_entry_order(entry); index = xas->xa_index & ~(count - 1); // Make the page become writeprotected dax_entry_mkclean(mapping, index, pfn); dax_flush(dax_dev, page_address(pfn_to_page(pfn)), count * PAGE_SIZE); /* * After we have flushed the cache, we can clear the dirty tag. There * cannot be new dirty data in the pfn after the flush has completed as * the pfn mappings are writeprotected and fault waits for mapping * entry lock. */ xas_reset(xas); xas_lock_irq(xas); xas_store(xas, entry); xas_clear_mark(xas, PAGECACHE_TAG_DIRTY); ---这里使用mark_inode_dirty()将inode交给writeback子系统,可以保证sync语义;参考代码:
sync_filesystem() --- writeback_inodes_sb(sb, WB_REASON_SYNC); if (sb->s_op->sync_fs) { ret = sb->s_op->sync_fs(sb, 0); if (ret) return ret; } ... ---
2 文件系统
目前我们常见的文件系统,如本地文件系统ext2、ext4、xfs,网络文件系统nfs、ocfs2、cephfs等,都包含以下元素:
- 文件,一段线性存储空间,可以用来存储数据;
- 目录,将若干个文件或者目录按照树形结构组织起来;
- 其他额外属性,例如修改日期、所有者、权限信息等;
- 空间管理机制,以上这些信息都需要存储空间来管理,文件系统需要知道哪些还是空闲的;
我们可以通过任何方式构造文件系统,只要最终效果包含以上元素即可。
为了构建起以上文件系统的基本元素,还需要一些额外数据,即元数据,包括:
- 文件属性,例如日期、所有者、权限等;
- 文件Block Mapping,即文件与存储设备空间之间的对应关系,也可能是多台主机的多个存储设备;
- 目录项,即某个目录下包含哪几个文件;
- 空间管理相关元数据;
- 其他辅助性元数据,例如日志;
文件系统的目的,是将一段线性的存储空间,组织成一种符合人脑习惯的形式。
非人脑习惯,可以参考对象存储,它只有一个object ID;我们可以很容易的记住,/home/will/Desktop/sourcecode/linux-stable,但是你能记住这样一段ID吗?
489f6d8b8553722f4c6f34b256aac5cacbee52eb
本节参考文档连接:
File systems ext2, ext3 and ext4
![]()
https://students.mimuw.edu.pl/ZSO/Wyklady/11_extXfs/extXfs_short.pdf
Ext4 block and inode allocator improvements
![]()
https://landley.net/kdocs/ols/2008/ols2008v1-pages-263-274.pdf
The new ext4 filesystem: current status and future plans
![]()
https://www.kernel.org/doc/ols/2007/ols2007v2-pages-21-34.pdf
Scalability in the XFS File System
![]()
https://users.soe.ucsc.edu/~sbrandt/290S/xfs.pdf
XFS Algorithms & Data Structures
![]()
http://ftp.ntu.edu.tw/linux/utils/fs/xfs/docs/xfs_filesystem_structure.pdf
下文中,会使用如下简称:
- fsblk ,filesytem block,文件系统管理空间的基本单位,可以是512/1K/2K/4K,当前默认基本都是4K
2.1 空间管理
空间管理,用于记录文件系统中块的使用情况,主要是Free Block的数量和位置;除此之外,还会配以一定的分配算法,用于提供性能。
2.1.1 ext4 Allocator
ext4正在空间管理上,使用block group(以下简称bg)来组织磁盘的空间,然后使用bitmap记录fsblk的使用情况;每个bg使用一个fsblk来承载bitmap,于是fsblk大小就决定了每个bg所管理的空间的大小,例如:fsblk=4K,一个bg所管理的空间大小就是4K * 8 * 4K = 128M。
可参考参考连接,
Ext4 Disk Layout – Blocks
![]()
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Blocks
为什么要这么要引入block group?bg继承自ext2,一种说法是:
Disk blocks are divided into groups including adjacent tracks, thanks to which reading a file located within a single group is associated with a short seek time
这个说法没毛病,但是,避免磁盘seek,
其实可以利用文件相邻的fsblk作为线索,查找附件的空闲fsblk
,而且ext2确实也是这样做的,参考代码:
ext2_get_block()
-> ext2_find_goal()
-> ext2_find_near()
-> ext2_alloc_branch()
-> ext2_alloc_blocks()
-> ext2_new_blocks()
---
grp_target_blk = ((goal - le32_to_cpu(es->s_first_data_block)) % EXT2_BLOCKS_PER_GROUP(sb));
bitmap_bh = read_block_bitmap(sb, group_no);
grp_alloc_blk = ext2_try_to_allocate_with_rsv(sb, group_no, bitmap_bh, grp_target_blk, my_rsv, &num);
---
grp_target_blk will used as 'offset' parameter of
find_next_zero_bit_le()
block group的引入,应该是因为bitmap
;如果你用bitmap管理1G的空间,试想一下,find_next_zero_bit的时候,效率极差。
ext4引入了flexible block group,参考连接:
Ext4 Disk Layout – Flexible Block Groups
![]()
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Flexible_Block_Groups
它会将多个bg并起来,进而可以让GB级的文件空间连续性更强;试想下,没有这个feature,一个文件最大的extent也就接近128M(除去bitmap和inode table)。
对应bitmap保存free fsblk的方式,ext4采用buddy的方式维护每个block group中的fsblk;类似内存的buddy系统;参考连接:
ext4 blocks buddy
![]()
https://jianchwa.github.io/fs/xfs_v2.html#ext4_blocks
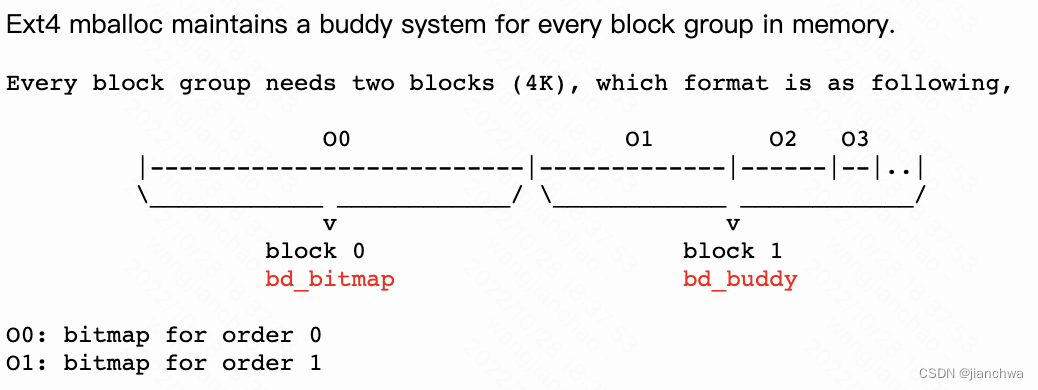

bitmap buddy可以用来快速定位到所需长度的fsblk,而不需要进行bitmap scan
;
bitmap buddy并不on-disk结构,而是在内存中,在load bg的bitmap时,会有构建buddy bitmap,参考函数ext4_mb_init_cache()。
在执行申请操作之前,ext4首先需要确定一个goal,也就是申请的的目标位置,以增加文件的locality ,参考代码:
ext4_ext_map_blocks()
-> ext4_ext_find_goal()
---
if (path) {
int depth = path->p_depth;
ex = path[depth].p_ext;
if (ex) {
ext4_fsblk_t ext_pblk = ext4_ext_pblock(ex);
ext4_lblk_t ext_block = le32_to_cpu(ex->ee_block);
if (block > ext_block)
return ext_pblk + (block - ext_block);
else
return ext_pblk - (ext_block - block);
}
/* it looks like index is empty;
* try to find starting block from index itself */
if (path[depth].p_bh)
return path[depth].p_bh->b_blocknr;
}
/* OK. use inode's group */
return ext4_inode_to_goal_block(inode);
---
ext4_inode_to_goal_block()
---
block_group = ei->i_block_group;
if (flex_size >= EXT4_FLEX_SIZE_DIR_ALLOC_SCHEME) {
/*
* If there are at least EXT4_FLEX_SIZE_DIR_ALLOC_SCHEME
* block groups per flexgroup, reserve the first block
* group for directories and special files. Regular
* files will start at the second block group. This
* tends to speed up directory access and improves
* fsck times.
*/
block_group &= ~(flex_size-1);
if (S_ISREG(inode->i_mode))
block_group++;
}
bg_start = ext4_group_first_block_no(inode->i_sb, block_group);
if (test_opt(inode->i_sb, DELALLOC))
return bg_start;
...
---
确定了goal之后,会首先尝试goal所指向的位置,参考代码:
ext4_ext_map_blocks()
-> ext4_mb_new_blocks()
-> ext4_mb_regular_allocator()
-> ext4_mb_find_by_goal()
-> mb_find_extent()
---
buddy = mb_find_buddy(e4b, 0, &max);
//这里会确定goal所指向的位置是否free
if (mb_test_bit(block, buddy)) {
ex->fe_len = 0;
ex->fe_start = 0;
ex->fe_group = 0;
return 0;
}
//确定free长度的代码此处省略
---
--
//需要确定长度是否满足
if (max >= ac->ac_g_ex.fe_len) {
ac->ac_found++;
ac->ac_b_ex = ex;
ext4_mb_use_best_found(ac, e4b);
}
--
ext4_mb_find_by_goal()会去确定goal所指向的位置,free的fsblk是否满足需求,如果不满足,则进入下一种策略;
ext4_mb_regular_allocator()
---
// 如果申请的fsblk长度是power of 2,并且其order值大于mb_order2_reqs,
// 设置 ac_2order;此时cr从0开始,在申请fsblk时,也可以直接使用buddy
i = fls(ac->ac_g_ex.fe_len);
ac->ac_2order = 0;
if (i >= sbi->s_mb_order2_reqs && i <= sb->s_blocksize_bits + 2) {
if ((ac->ac_g_ex.fe_len & (~(1 << (i - 1)))) == 0)
ac->ac_2order = array_index_nospec(i - 1, sb->s_blocksize_bits + 2);
}
cr = ac->ac_2order ? 0 : 1;
repeat:
//cr逐渐增长,申请策略会逐渐激进;
for (; cr < 4 && ac->ac_status == AC_STATUS_CONTINUE; cr++) {
ac->ac_criteria = cr;
group = ac->ac_g_ex.fe_group;
//优先从目标group申请
for (i = 0; i < ngroups; group++, i++) {
if (group >= ngroups)
group = 0;
//部分代码省略,以优先表达申请策略
ret = ext4_mb_good_group(ac, group, cr);
if (ret <= 0)
continue;
if (cr == 0)
//因为此时fe_len是power of 2,可以直接使用buddy判断和申请
ext4_mb_simple_scan_group(ac, &e4b);
else if (cr == 1 && sbi->s_stripe &&
!(ac->ac_g_ex.fe_len % sbi->s_stripe))
ext4_mb_scan_aligned(ac, &e4b);
else
ext4_mb_complex_scan_group(ac, &e4b);
if (ac->ac_status != AC_STATUS_CONTINUE)
break;
}
}
---
该算法的核心在于这个函数,
ext4_mb_good_group()
---
switch (cr) {
case 0:
BUG_ON(ac->ac_2order == 0);
// 此策略是不是可以也放到cr 1里?
/* Avoid using the first bg of a flexgroup for data files */
if ((ac->ac_flags & EXT4_MB_HINT_DATA) &&
(flex_size >= EXT4_FLEX_SIZE_DIR_ALLOC_SCHEME) &&
((group % flex_size) == 0))
return 0;
if ((ac->ac_2order > ac->ac_sb->s_blocksize_bits+1) ||
(free / fragments) >= ac->ac_g_ex.fe_len)
return 1;
if (grp->bb_largest_free_order < ac->ac_2order)
return 0;
return 1;
case 1:
// free/fragments 可以认为是这个bg的free segments的平均大小
if ((free / fragments) >= ac->ac_g_ex.fe_len)
return 1;
break;
case 2:
if (free >= ac->ac_g_ex.fe_len)
return 1;
break;
case 3:
return 1;
default:
BUG();
}
---fallback策略,依然会优先从目标bg开始申请;在遍历各个bg的时候,依然是优先考虑选择满足所需长度的bg,以保证IO size;
2.1.2 xfs Allocator
xfs也将磁盘划分成不同的区域,称为allocation group(以下简称ag);不过,与ext2的无可奈何相比,xfs的这种设计有明显的目的性的,参考《Scalability in the XFS File System》:
-
To avoid requiring all structures in XFS to scale to the 64 bit size of the file system;举个例子,xfs的ag内部的空间管理结构,只需要使用32bit的指针就可以,在4K的fsblk下,这个32bit的指针可以覆盖2^44 = 16T的空间,参考代码:
typedef uint32_t xfs_agblock_t; /* blockno in alloc. group */ xfs_alloc_vextent() ---- if (args->agbno == NULLAGBLOCK) args->fsbno = NULLFSBLOCK; else { args->fsbno = XFS_AGB_TO_FSB(mp, args->agno, args->agbno); ... } --- #define XFS_AGB_TO_FSB(mp,agno,agbno) \ (((xfs_fsblock_t)(agno) << (mp)->m_sb.sb_agblklog) | (agbno)) -
Partitioning the file system into AGs
limits the size of the individual structures used for tracking free space and inodes
. 这一点与ext2使用bg的原因类似,减小相关数据结构的size; - Improve parallelism in the management of free space and inode allocation;各个ag之间的空间和Inode管理结构可以完全并行操作;如果在底层存储设备层级上引入lvm,则可以保证各个ag之间代码和IO的完全隔离;
Note:
对于空间局部性的问题,xfs并不是靠ag,考虑ag的size往往都是几十上百GB,参考<0.1 机械盘>中的数据,保证在一个ag内,对于降低磁盘seek没有任何意义。xfs使用的基于临近fsblk的原则,在下面的章节里,我们会详解这一块。
xfs的空间管理使用的是一对保存fsblk extent (agbno, length)的B+ tree,他们使用不同的元素作为index,
- agbno,即bnobt,基于临近fsblk原则寻找free fsblk,可以降低磁盘seek;
- length,即cntbt,方便快速找到满足长度要求的extent,降低文件的碎片化;
在执行分配操作之前,首先需要确定以下参数:
-
blkno,执行分配的目标位置,
xfs_bmap_btalloc() --- // t_firstblock是当前transaction首次执行分配操作的记录,xfs_bmap_btalloc()可能 // 会被xfs_bmapi_write()调用多次;是否为空代表着是否是第一次分配操作。 nullfb = ap->tp->t_firstblock == NULLFSBLOCK; ... if (nullfb) { // 选择目标位置的时候参考的inode fsblk位置 ap->blkno = XFS_INO_TO_FSB(mp, ap->ip->i_ino); } xfs_bmap_adjacent(ap) --- /* * If allocating at eof, and there's a previous real block, * try to use its last block as our starting point. */ /* * If not at eof, then compare the two neighbor blocks. * Figure out whether either one gives us a good starting point, * and pick the better one. */ --- --- xfs_bmap_adjacent()代表比较长,这里暂时忽略 从代码中,可以看到,在文件为空的时候,选择inode所在fsblk作为目标,这可以保证inode和 数据尽量近一些;在那之后,会议临近的fsblk作为目标。以此,来尽量避免磁盘seek -
ap,执行分配操作的allocation group;参考函数:
xfs_bmap_btalloc() --- // t_firstblock是当前transaction首次执行分配操作的记录,xfs_bmap_btalloc()可能 // 会被xfs_bmapi_write()调用多次;是否为空代表着是否是第一次分配操作。 nullfb = ap->tp->t_firstblock == NULLFSBLOCK; ... xfs_bmap_adjacent(ap); ... // ap的选择依赖blkno,即目标fsblk,发生在xfs_bmap_adjacent()之后标明,ag的选择 // 也会遵循临近原理 if (nullfb) { error = xfs_bmap_btalloc_nullfb(ap, &args, &blen); } --- xfs_bmap_btalloc_nullfb() --- args->type = XFS_ALLOCTYPE_START_BNO; args->total = ap->total; //args->fsbno来自ap->blkno即目标fsblk startag = ag = XFS_FSB_TO_AGNO(mp, args->fsbno); if (startag == NULLAGNUMBER) startag = ag = 0; //blen是该ag的包含的最长的extent的长度,在这里选择一个包含要求的maxlen的ag, //从这里也可以看出,申请一个块连续的fsblk的优先级是要高于临近原则的 while (*blen < args->maxlen) { error = xfs_bmap_longest_free_extent(args->tp, ag, blen, ¬init); if (++ag == mp->m_sb.sb_agcount) ag = 0; if (ag == startag) break; }¡ --- 每个ag的最长的extent,是被记录在agf,即xfs的ag空间管理结构里的,如下: cntbt的最后一个record就是最长的, xfs_allocbt_update_lastrec() --- agf->agf_longest = len; pag = xfs_perag_get(cur->bc_mp, seqno); pag->pagf_longest = be32_to_cpu(len); xfs_perag_put(pag); xfs_alloc_log_agf(cur->bc_tp, cur->bc_private.a.agbp, XFS_AGF_LONGEST); --- xfs_alloc_read_agf --- if (!pag->pagf_init) { ... pag->pagf_longest = be32_to_cpu(agf->agf_longest); ... } --- 综上,在选择ag的时候,会优先选择有所需长度fsblk的ag,而且xfs为了保存每个ag的最长extent, 还着实费了些功夫
在选定了ag和blkno之后,借助bnobt和cntbt,选择合适的fsblk;
fsblk分配有以下五种策略:
-
XFS_ALLOCTYPE_START_BNO,near this block else anywhere,该策略分成两段,会首先尝试NEAR_AG,如果失败则fallback到THIS_AG,参考代码:
xfs_alloc_vextent() --- switch (type) { ... case XFS_ALLOCTYPE_START_BNO: /* * Try near allocation first, then anywhere-in-ag after * the first a.g. fails. */ args->agbno = XFS_FSB_TO_AGBNO(mp, args->fsbno); args->type = XFS_ALLOCTYPE_NEAR_BNO; /* FALLTHROUGH */ case XFS_ALLOCTYPE_FIRST_AG: for (;;) { args->pag = xfs_perag_get(mp, args->agno); error = xfs_alloc_fix_freelist(args, flags); /* * If we get a buffer back then the allocation will fly. */ if (args->agbp) { if ((error = xfs_alloc_ag_vextent(args))) goto error0; break; } /* * For the first allocation, we can try any AG to get * space. However, if we already have allocated a * block, we don't want to try AGs whose number is below * sagno. Otherwise, we may end up with out-of-order * locking of AGF, which might cause deadlock. */ if (++(args->agno) == mp->m_sb.sb_agcount) { if (args->tp->t_firstblock != NULLFSBLOCK) args->agno = sagno; else args->agno = 0; } if (args->agno == sagno && type == XFS_ALLOCTYPE_START_BNO) args->type = XFS_ALLOCTYPE_THIS_AG; xfs_perag_put(args->pag); } break; default: ASSERT(0); /* NOTREACHED */ } if (args->agbno == NULLAGBLOCK) args->fsbno = NULLFSBLOCK; else { args->fsbno = XFS_AGB_TO_FSB(mp, args->agno, args->agbno); } --- -
XFS_ALLLOCTYPE_FIRST_AG,最终fallback策略,通常意味着文件系统存储空间处于低位,参考代码:
xfs_bmap_btalloc() --- if (args.fsbno == NULLFSBLOCK && nullfb) { args.fsbno = 0; args.type = XFS_ALLOCTYPE_FIRST_AG; args.total = ap->minlen; if ((error = xfs_alloc_vextent(&args))) return error; ap->tp->t_flags |= XFS_TRANS_LOWMODE; } ----
以下三种是基础策略,以上两种策略会最终转换成基础策略,参考函数xfs_alloc_ag_vextent():
- XFS_ALLOCTYPE_THIS_AG,Allocate a variable extent anywhere in the allocation group agno,这里主要基于cntbt,选择一个长度满足要求的fsblk extent,完全不考虑fsblk临近的问题;XFS_ALLOCTYPE_FIRST_AG会转换成该策略,或者作为XFS_ALLOCTYPE_START_BNO()的fallback策略,
-
XFS_ALLOCTYPE_NEAR_AG,Allocate a variable extent near bno in the allocation group agno,这里会同时参考cntbt和bnobt;通常作为XFS_ALLOCTYPE_START_BNO的优先策略;
xfs_alloc_ag_vextent_near() --- 代码此处省略了此ag中没有要求长度extent的情况,源码也为了提高可读性省略一些分支 /* * Loop going left with the leftward cursor, right with the * rightward cursor, until either both directions give up or * we find an entry at least as big as minlen. */ do { if (bno_cur_lt) { error = xfs_alloc_get_rec(bno_cur_lt, <bno, <len, &i); ... if (ltlena >= args->minlen && ltbnoa >= args->min_agbno) break; error = xfs_btree_decrement(bno_cur_lt, 0, &i); } if (bno_cur_gt) { error = xfs_alloc_get_rec(bno_cur_gt, >bno, >len, &i); if (gtlena >= args->minlen && gtbnoa <= args->max_agbno) break; error = xfs_btree_increment(bno_cur_gt, 0, &i); } } while (bno_cur_lt || bno_cur_gt); --- -
XFS_ALLOCTYPE_THIS_BNO,Allocate a variable extent at exactly agno/bno,基于cntbt,这种策略用在file append操作时,进而可以保证文件的fsblk的连续性,参考代码:
xfs_bmap_btalloc() --- if (!(ap->tp->t_flags & XFS_TRANS_LOWMODE) && ap->aeof) { // offset in file filling in if (!ap->offset) { } else { /* * First try an exact bno allocation. * If it fails then do a near or start bno * allocation with alignment turned on. */ atype = args.type; tryagain = 1; args.type = XFS_ALLOCTYPE_THIS_BNO; args.alignment = 1; ... } } ---
Note:
- 如果对比下一小节的xfs,在尝试在goal位置申请失败之后,xfs的策略时,从goal位置,同时想左右搜索;而ext4这里只是向右;所以,xfs在磁盘seek上表现应该会更好一些;
- xfs采用B+tree结构,对于维护大存储空间和大文件extent,非常高效;但是如果是频繁的小文件场景,B+tree会最终会变的碎片化,B+tree的IO也会变得非常沉重;相反,ext4 bitmap的方式,此时反倒IO很轻;
2.1.3 ext4 预申请
Delay Allocation理论上也是一种预申请机制,只不过它只是在内存中保留了额度,而没有真正的在分配器中申请对应的空间;在执行writeback时,可以一次性执行批量申请,获取更大的连续fsblk;但是,DA也不一定是万能的,比如,一些日志文件会持续append写操作,同时为保证数据的持久性,写完之后就会立刻fsync,但是后续可能还需要大批量的读上来;当然,还有很多其他场景,我们分别看下ext4和xfs的预申请机制。
The Ext4 multiple block allocator maintains two preallocated spaces from which block requests are satisfied: A per-inode preallocation space and a per-CPU locality group prealloction space. The per-inode preallocation space is used for larger request and helps in making sure larger files are less interleaved if blocks are allocated at the same time. The per-CPU locality group preallocation space is used for smaller file allocation and helps in making sure small files are placed closer on disk
首先看下ext4的per-file allocation,其包括以下几个关键点:
-
fsblk跟文件的offset是有对应关系的,否则就无法形成连续IO;所以,我们看到ext4_prealloc_space中还包括了文件offset,
struct ext4_prealloc_space { ... ext4_fsblk_t pa_pstart; /* phys. block */ ext4_lblk_t pa_lstart; /* log. block */ ext4_grpblk_t pa_len; /* len of preallocated chunk */ ... }在尝试从预申请的资源中中获取空间时,参考函数:
ext4_mb_new_blocks() -> xt4_mb_use_preallocated() --- if (!(ac->ac_flags & EXT4_MB_HINT_DATA)) return 0; rcu_read_lock(); list_for_each_entry_rcu(pa, &ei->i_prealloc_list, pa_inode_list) { //检查文件的偏移是否符合 if (ac->ac_o_ex.fe_logical < pa->pa_lstart || ac->ac_o_ex.fe_logical >= (pa->pa_lstart + EXT4_C2B(sbi, pa->pa_len))) continue; /* found preallocated blocks, use them */ spin_lock(&pa->pa_lock); if (pa->pa_deleted == 0 && pa->pa_free) { atomic_inc(&pa->pa_count); //根据pa的pa_start获取fsblk的地址和长度 ext4_mb_use_inode_pa(ac, pa); spin_unlock(&pa->pa_lock); rcu_read_unlock(); return 1; } spin_unlock(&pa->pa_lock); } rcu_read_unlock(); ---注意,在使用prealloc space时,并不会考虑要求申请的长度;
-
preallocate的长度,可以参考如下使用dd命令进行顺序IO的log,
dd if=/dev/zero of=/mnt/test/big.1G bs=4K count=$((256<<10)) oflag=direct goal: 16(was 17) blocks at 16 goal: 32(was 33) blocks at 32 goal: 64(was 65) blocks at 64 goal: 128(was 129) blocks at 128 goal: 256(was 257) blocks at 256 goal: 512(was 513) blocks at 512 goal: 1024(was 1025) blocks at 1024 goal: 2048(was 2049) blocks at 2048 goal: 2048(was 4097) blocks at 4096 goal: 2048(was 6145) blocks at 6144 goal: 2048(was 8193) blocks at 8192 goal: 2048(was 10241) blocks at 10240 goal: 2048(was 12289) blocks at 12288 goal: 2048(was 14337) blocks at 14336 goal: 2048(was 16385) blocks at 16384 goal: 2048(was 18433) blocks at 18432 goal: 2048(was 20481) blocks at 20480 goal: 2048(was 22529) blocks at 22528 goal: 2048(was 24577) blocks at 24576 goal: 2048(was 26625) blocks at 26624 goal: 2048(was 28673) blocks at 28672 goal: 2048(was 30721) blocks at 30720 goal: 2048(was 32769) blocks at 32768 goal: 2048(was 34817) blocks at 34816 goal: 2048(was 36865) blocks at 36864 preallocate size, original file size, preallocate offset概括起来就是,在8M以前,每次preallocate的size是文件大小的一倍,之后,每次申请8M;需要特别注意的是preallocate的文件的偏移,其有一个基于Preallocate的调整,参考如下代码:
ext4_mb_normalize_request() --- rcu_read_lock(); list_for_each_entry_rcu(pa, &ei->i_prealloc_list, pa_inode_list) { pa_end = pa->pa_lstart + EXT4_C2B(EXT4_SB(ac->ac_sb), pa->pa_len); if (pa->pa_lstart >= end || pa_end <= start) { spin_unlock(&pa->pa_lock); continue; } /* adjust start or end to be adjacent to this pa */ if (pa_end <= ac->ac_o_ex.fe_logical) { start = pa_end; } else if (pa->pa_lstart > ac->ac_o_ex.fe_logical) { end = pa->pa_lstart; } } --- -
preallocation的block并不会被持久化,只有被文件申请之后,才会被记入log,参考代码:
ext4_mb_use_preallocated() -> ext4_mb_use_inode_pa() --- start = pa->pa_pstart + (ac->ac_o_ex.fe_logical - pa->pa_lstart); end = min(pa->pa_pstart + EXT4_C2B(sbi, pa->pa_len), start + EXT4_C2B(sbi, ac->ac_o_ex.fe_len)); len = EXT4_NUM_B2C(sbi, end - start); ext4_get_group_no_and_offset(ac->ac_sb, start, &ac->ac_b_ex.fe_group, &ac->ac_b_ex.fe_start); ac->ac_b_ex.fe_len = len; --- ext4_mb_new_blocks() -> ext4_mb_use_preallocated() -> ext4_mb_mark_diskspace_used() --- ext4_lock_group(sb, ac->ac_b_ex.fe_group); ext4_set_bits(bitmap_bh->b_data, ac->ac_b_ex.fe_start, ac->ac_b_ex.fe_len); ext4_unlock_group(sb, ac->ac_b_ex.fe_group); err = ext4_handle_dirty_metadata(handle, NULL, bitmap_bh); ---
另外,ext4还支持per-cpu的preallocation,参考
The per-CPU locality group preallocation space is used for smaller file allocation and helps in making sure small files are placed closer on disk. Which preallocation space to use depends on the total size derived out of current file size and allocation request size. The allocator provides a tunable /prof/fs/ext4/ /stream_req that defaults to 16
per-cpu的preallocation工作原理与per-file大致相同,参考如下几点:
-
per-file or per-cpu,参考代码:
ext4_mb_initialize_context() -> ext4_mb_group_or_file() --- if (sbi->s_mb_group_prealloc <= 0) { ac->ac_flags |= EXT4_MB_STREAM_ALLOC; return; } /* don't use group allocation for large files */ size = max(size, isize); if (size > sbi->s_mb_stream_request) { ac->ac_flags |= EXT4_MB_STREAM_ALLOC; return; } /* * locality group prealloc space are per cpu. The reason for having * per cpu locality group is to reduce the contention between block * request from multiple CPUs. */ ac->ac_lg = raw_cpu_ptr(sbi->s_locality_groups); ac->ac_flags |= EXT4_MB_HINT_GROUP_ALLOC; mutex_lock(&ac->ac_lg->lg_mutex); --- - 每次预申请的size,这是一个可配置的值,/sys/fs/ext4/vdb/mb_group_prealloc,默认是512个fsblk
2.1.4 xfs 预申请
xfs的预申请机制正式名称为speculative preallocation,以下内容参考链接:
-
The XFS speculative preallocation algorithm allocates extra blocks
beyond end of file (EOF)
to combat fragmentation under parallel sequential write workloads. - This post-EOF block allocation is included in ‘st_blocks’ counts via stat() system calls and is accounted as globally allocated space by the filesystem.
- Speculative preallocation is not enabled for files smaller than a minimum size (64k by default, but can vary depending on filesystem geometry and/or mount options). Preallocations are capped at a maximum of 8GB on 4k block filesystems. Preallocation is throttled automatically as the filesystem approaches low free space conditions or other allocation limits on a file (such as a quota).
-
In most cases, speculative preallocation is automatically reclaimed when a file is closed. The preallocation may persist after file close if an open, write, close pattern is repeated on a file. In this scenario, post-EOF preallocation is trimmed once the inode is reclaimed from cache
or the filesystem unmounted.Linux 3.8 (and later) includes a scanner to perform background trimming of files with lingering post-EOF preallocations. The scanner bypasses files that have been recently modified to not interfere with ongoing writes. A 5 minute scan interval is used by default and can be adjusted via the following file (value in seconds):
/proc/sys/fs/xfs/speculative_prealloc_lifetime
- XFS block allocation algorithm can be configured to use a fixed allocation size with the ‘allocsize=’ mount option
2.2 配额管理
2.2.1 概述
文件系统配额管理有两个维度:
-
资源,配额限制的资源有两种,同时也是文件系统的两个基本单位:
- inode
- block
-
角色,可以通过三种角色限制资源:
- user
- group
- project
资源限制有两种方式,
- soft limit,如果超过该限额,内核会发出告警;同时,soft limit还可以配置一个grace period,如果超过soft limit同时经过grace period之后,会返回失败EDQUOT;
- hard limit,如果超过该限额,返回失败EDQUOT;
目前内核主流本地文件系统重中,quota机制有两种类型,
-
自成体系,例如:
- xfs quota,xfs并不是linux’本地人’,而是移植自SGI的IRIX ;
- btrfs quota,btrfs是copy-on-write文件系统,与ext4和xfs有很大区别;
- dquot,linux文件系统通用quota机制,目前ext2、ext4等使用此机制;
接来,我们将主要介绍xfs quota和ext4使用的quota机制。
Chapter 30. Limiting storage space usage on ext4 with quotas Red Hat Enterprise Linux 9 | Red Hat Customer Portalhttps://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/9/html/managing_file_systems/limiting-storage-space-usage-on-ext4-with-quotas_managing-file-systems
![]()
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/9/html/managing_file_systems/limiting-storage-space-usage-on-ext4-with-quotas_managing-file-systems
Chapter 29. Limiting storage space usage on XFS with quotas Red Hat Enterprise Linux 9 | Red Hat Customer Portalhttps://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/9/html/managing_file_systems/assembly_limiting-storage-space-usage-on-xfs-with-quotas_managing-file-systems
![]()
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/9/html/managing_file_systems/assembly_limiting-storage-space-usage-on-xfs-with-quotas_managing-file-systems
2.2.2 ext4 quota
ext4使用的是Linux FS的通用quota机制,从代码引用情况来看,目前有ext2、ext4、jfs、ocfs2、f2fs、reiserfs在使用。接下来几个小结我们将主要看下它在ext4上的使用情况。
2.2.2.1 quota在ext4上的演变
相关信息参考自以下链接:
mount – Difference between journaled and plain quota – Unix & Linux Stack Exchangehttps://unix.stackexchange.com/questions/493199/difference-between-journaled-and-plain-quota
![]()
https://unix.stackexchange.com/questions/493199/difference-between-journaled-and-plain-quota
Design For 1st Class Quota in Ext4 – Ext4https://ext4.wiki.kernel.org/index.php/Design_For_1st_Class_Quota_in_Ext4
![]()
https://ext4.wiki.kernel.org/index.php/Design_For_1st_Class_Quota_in_Ext4
概括起来包括三个阶段:
- Plain Quota
- Journaled Quota
- Feature Quota
三种方式都使用两个文件保存inode和block的使用情况,存储格式相同;区别在于:
- Plain和Journaled Quota的区别在于,后者会将对Quota文件的更新记录在日志中,这样可以保证其更新与文件系统更新的事务性;而Plain Quota则类似ext2,如果遇到异常重启需要执行fsck来保证元数据一致,Plain Quota会执行quotacheck;
- Feature Quota会在文件系统格式化的时候,也就是mkfs时制定参数开启quota机制(quota=user,group,project),之后会默认为Quota文件分配inode(user quota 3, group quota 4),然后在运行过程中使用Journaled Quota;
2.2.2.2 quota框架
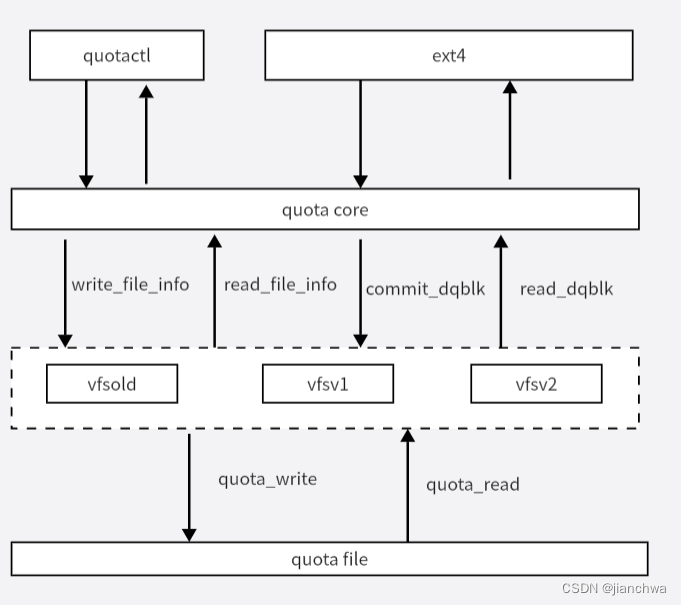
每个文件系统实现了一个quotactl_ops,用户态quotactl命令进入内核调用,对应着on、off、getfmt、getinfo、setinfo、getquota、setquota、sync等命令;
目前存在的几个格式包括:vfsold、vfsv1、vfsv2,format具体细节这里不做深入;我们只需要了解它向上和向下的接口:
-
向上,quota format主要通过read/write_file_info和read/commit_dqblk沟通;其中
- file info类似文件系统的super block;
- dqblk则类似file page,read/commit_dqblk用于向format层读出或者写入一个dquot
- 向下,format通过文件系统super_operatons quota_read和quota_write回调访问quota file;
ext4和quota core之间通过dquot_opertions回调沟通;其提供的功能包括:
- alloc/destroy_quota,申请/释放dquot结构;在ext4实现中,直接调用了dquot_alloc/destroy(),后者仅仅只是使用了kmem管理内存;
-
acquire/release_dquot,acquire_dquot回调被dqget()调用,参考代码:
ext4_acquire_dquot() -> dquot_acquire() --- if (!test_bit(DQ_READ_B, &dquot->dq_flags)) { ret = dqopt->ops[dquot->dq_id.type]->read_dqblk(dquot); ... } set_bit(DQ_READ_B, &dquot->dq_flags); // dq_off代表的是这个dquot在quota file中的偏移,如果为0代表还没有分配空间 if (!test_bit(DQ_ACTIVE_B, &dquot->dq_flags) && !dquot->dq_off) { ret = dqopt->ops[dquot->dq_id.type]->commit_dqblk(dquot); ... } set_bit(DQ_ACTIVE_B, &dquot->dq_flags); ---如果dquot已经存在,则读入,否则,在qouta file中问题申请空间;release_dquot与acquire_dquot相反,有可能释放某个dquot所占用的空间;
-
mark_dirty,这里关系到quota是是journaled还是writeback,在更新dquot之后,需要调用该回调,类似mark_inode_dirty;参考代码:
__dquot_alloc_space() __dquot_free_space() dquot_alloc_inode() dquot_free_inode() -> mark_all_dquot_dirty() -> mark_dquot_dirty() static int ext4_mark_dquot_dirty(struct dquot *dquot) { struct super_block *sb = dquot->dq_sb; if (ext4_is_quota_journalled(sb)) { dquot_mark_dquot_dirty(dquot); return ext4_write_dquot(dquot); } else { return dquot_mark_dquot_dirty(dquot); } }如果ext4开启了journaled quota,ext4_write_dquot()会被调用,参考其代码:
ext4_write_dquot() --- inode = dquot_to_inode(dquot); handle = ext4_journal_start(inode, EXT4_HT_QUOTA, EXT4_QUOTA_TRANS_BLOCKS(dquot->dq_sb)); ... ret = dquot_commit(dquot); -> dqopt->ops[dquot->dq_id.type]->commit_dqblk(dquot) v2_write_dquot() ... -> ext4_quota_write() err = ext4_journal_stop(handle); --- ext4_quota_write() --- handle_t *handle = journal_current_handle(); ... do { bh = ext4_bread(handle, inode, blk, EXT4_GET_BLOCKS_CREATE | EXT4_GET_BLOCKS_METADATA_NOFAIL); } while (PTR_ERR(bh) == -ENOSPC && ext4_should_retry_alloc(inode->i_sb, &retries)); ... err = ext4_journal_get_write_access(handle, sb, bh, EXT4_JTR_NONE); ... lock_buffer(bh); memcpy(bh->b_data+offset, data, len); flush_dcache_page(bh->b_page); unlock_buffer(bh); err = ext4_handle_dirty_metadata(handle, NULL, bh); brelse(bh); ... ---所有对quota的更新会被记录进入日志;
如果它所在的handle与ext4申请block或者inode相同,则可以保证quota操作和ext4本身的metadata操作的事务性
; -
write_quota,在mark_dirty时,dquot_mark_dquot_dirty()会将dquot挂进一个list,表示它是dirty的;write_quota回调用于将这些dirty的quota writeback;参考代码:
ext4_sync_fs() -> dquot_writeback_dquots() --- for (cnt = 0; cnt < MAXQUOTAS; cnt++) { ... spin_lock(&dq_list_lock); list_replace_init(&dqopt->info[cnt].dqi_dirty_list, &dirty); while (!list_empty(&dirty)) { dquot = list_first_entry(&dirty, struct dquot, dq_dirty); dqgrab(dquot); spin_unlock(&dq_list_lock); err = sb->dq_op->write_dquot(dquot); qqput(dquot); spin_lock(&dq_list_lock); } spin_unlock(&dq_list_lock); } --- ext4_write_dquot() --- inode = dquot_to_inode(dquot); handle = ext4_journal_start(inode, EXT4_HT_QUOTA, EXT4_QUOTA_TRANS_BLOCKS(dquot->dq_s)); ret = dquot_commit(dquot); err = ext4_journal_stop(handle); ---
实现quota限制的核心函数:
dquot_alloc_inode()
---
dquots = i_dquot(inode);
spin_lock(&inode->i_lock);
for (cnt = 0; cnt < MAXQUOTAS; cnt++) {
if (!dquots[cnt])
continue;
ret = dquot_add_inodes(dquots[cnt], 1, &warn[cnt]);
if (ret) {
...
}
}
warn_put_all:
spin_unlock(&inode->i_lock);
if (ret == 0)
mark_all_dquot_dirty(dquots);
srcu_read_unlock(&dquot_srcu, index);
---
dquot_add_inodes()
---
spin_lock(&dquot->dq_dqb_lock);
newinodes = dquot->dq_dqb.dqb_curinodes + inodes;
if (!sb_has_quota_limits_enabled(dquot->dq_sb, dquot->dq_id.type) ||
test_bit(DQ_FAKE_B, &dquot->dq_flags))
goto add;
if (dquot->dq_dqb.dqb_ihardlimit &&
newinodes > dquot->dq_dqb.dqb_ihardlimit &&
!ignore_hardlimit(dquot)) {
prepare_warning(warn, dquot, QUOTA_NL_IHARDWARN);
ret = -EDQUOT;
goto out;
}
if (dquot->dq_dqb.dqb_isoftlimit &&
newinodes > dquot->dq_dqb.dqb_isoftlimit &&
dquot->dq_dqb.dqb_itime &&
ktime_get_real_seconds() >= dquot->dq_dqb.dqb_itime &&
!ignore_hardlimit(dquot)) {
prepare_warning(warn, dquot, QUOTA_NL_ISOFTLONGWARN);
ret = -EDQUOT;
goto out;
}
if (dquot->dq_dqb.dqb_isoftlimit &&
newinodes > dquot->dq_dqb.dqb_isoftlimit &&
dquot->dq_dqb.dqb_itime == 0) {
prepare_warning(warn, dquot, QUOTA_NL_ISOFTWARN);
dquot->dq_dqb.dqb_itime = ktime_get_real_seconds() +
sb_dqopt(dquot->dq_sb)->info[dquot->dq_id.type].dqi_igrace;
}
add:
dquot->dq_dqb.dqb_curinodes = newinodes;
out:
spin_unlock(&dquot->dq_dqb_lock);
---
从中,我们可以看到以下信息:
- 每次quota申请操作,需要满足所有的规则,即user、group和project;
- dquot_add_inode()给出了soft-limit、grace period和hard-limit的逻辑,请参考代码;
Block quota的逻辑于此类似。
2.2.2.3 quota开启与关闭
old style的quota,即显式quota file,
参考ext4 quota开启步骤:
mount -t ext4 -o usrjquota=aquota.user,jqfmt=vfsv /dev/xxx /mnt
quotacheck -cum /home
quotaon -v /home
quotaoff -v /home我们先看当指定usrjquota时,内核是如何处理的;
__ext4_fill_super()
-> parse_apply_sb_mount_options()
-> parse_options()
-> ext4_parse_param()
-> note_qf_name() // Opt_usrjquota/Opt_grpjquota
-> ext4_orphan_cleanup()
-> ext4_quota_on_mount()
-> dquot_quota_on_mount(sb,EXT4_SB(sb)->s_qf_names[type], EXT4_SB(sb)->s_jquota_fmt, type)
指定usrjquota之后内核会自动开启usr quota ?
并不是如此
!
ext4_orphan_cleanup()
---
if (!es->s_last_orphan && !oi->of_blocks) {
return;
}
...
#ifdef CONFIG_QUOTA
/*
* Turn on quotas which were not enabled for read-only mounts if
* filesystem has quota feature, so that they are updated correctly.
*/
if (ext4_has_feature_quota(sb) && (s_flags & SB_RDONLY)) {
int ret = ext4_enable_quotas(sb);
...
}
/* Turn on journaled quotas used for old sytle */
for (i = 0; i < EXT4_MAXQUOTAS; i++) {
if (EXT4_SB(sb)->s_qf_names[i]) {
int ret = ext4_quota_on_mount(sb, i);
...
}
}
#endif
while (es->s_last_orphan) {
inode = ext4_orphan_get(sb, le32_to_cpu(es->s_last_orphan));
...
list_add(&EXT4_I(inode)->i_orphan, &EXT4_SB(sb)->s_orphan);
ext4_process_orphan(inode, &nr_truncates, &nr_orphans);
}
...
---
在处理orphan inode时,同样需要对inode和block quota进行处理,所以,如果文件系统有quota,就需要提前开启。这也告诉我们,mount参数中的quota file名称必须与以前的文件一致。
但是,是一个umount clean的文件系统,它并不会进入orphan的处理流程,也就不会自动开启quota机制;但usrjquota会被记录下,并且作为journaled quota开启的标记之一,参考函数ext4_is_quota_journalled()。
quotacheck代码参考
static int scan_dir(const char *pathname)
{
...
qspace = getqsize(pathname, &st);
if (ucheck)
add_to_quota(USRQUOTA, st.st_ino, st.st_uid, st.st_gid, st.st_mode,
st.st_nlink, qspace, 0);
if (gcheck)
add_to_quota(GRPQUOTA, st.st_ino, st.st_uid, st.st_gid, st.st_mode,
st.st_nlink, qspace, 0);
if ((dp = opendir(pathname)) == (DIR *) NULL)
die(2, _("\nCan open directory %s: %s\n"), pathname, strerror(errno));
chdir(pathname);
while ((de = readdir(dp)) != (struct dirent *)NULL) {
if (!strcmp(de->d_name, ".") || !strcmp(de->d_name, ".."))
continue;
...
if (S_ISDIR(st.st_mode)) {
...
}
else {
qspace = getqsize(de->d_name, &st);
if (ucheck)
add_to_quota(USRQUOTA, st.st_ino, st.st_uid, st.st_gid, st.st_mode,
st.st_nlink, qspace, 1);
if (gcheck)
add_to_quota(GRPQUOTA, st.st_ino, st.st_uid, st.st_gid, st.st_mode,
st.st_nlink, qspace, 1);
...
files_done++;
}
}
closedir(dp);
/*
* Traverse the directory stack, and check it.
*/
while (dir_stack != (struct dirs *)NULL) {
new_dir = dir_stack;
dir_stack = dir_stack->next;
ret = scan_dir(new_dir->dir_name);
^^^^^^^^
dirs_done++;
free(new_dir->dir_name);
free(new_dir);
if (ret < 0) /* Error while scanning? */
goto out;
}
return 0;
...
return -1;
}
从代码中我们看到,其通过嵌套调用scan_dir()遍历系统中的每一个文件,最终生成的结果按照不同的格式dump到quota file中;quota file的名称解析自文件系统的mount options,通过系统接口getmntent()获得;
ext4 quota feature,即隐式quota file
参考redhat官方提供的运维quota的文档,
dnf install quota
mkfs.ext4 -O quota -E quotatype=usrquota:grpquota:prjquota /dev/sda
mount /dev/sda
or
umount /dev/sda
tune2fs -Q usrquota,grpquota,prjquota /dev/sda
mount /dev/sda
The quota accounting is enabled by default after mounting the file system without any additional options, but quota enforcement is not.
mount /dev/sda /mnt
quotaon /mnt
or
mount -o usrquota,grpquota,prjquota /dev/sda /mnt这里用到的就是ext4的quota feature,它在文件系统mkfs的时候分配了默认quota file,并保存在super block中。参考代码:
ext4_enable_quotas()
---
unsigned long qf_inums[EXT4_MAXQUOTAS] = {
le32_to_cpu(EXT4_SB(sb)->s_es->s_usr_quota_inum),
le32_to_cpu(EXT4_SB(sb)->s_es->s_grp_quota_inum),
le32_to_cpu(EXT4_SB(sb)->s_es->s_prj_quota_inum)
};
bool quota_mopt[EXT4_MAXQUOTAS] = {
test_opt(sb, USRQUOTA),
test_opt(sb, GRPQUOTA),
test_opt(sb, PRJQUOTA),
};
sb_dqopt(sb)->flags |= DQUOT_QUOTA_SYS_FILE | DQUOT_NOLIST_DIRTY;
for (type = 0; type < EXT4_MAXQUOTAS; type++) {
if (qf_inums[type]) {
err = ext4_quota_enable(sb, type, QFMT_VFS_V1,
DQUOT_USAGE_ENABLED |
(quota_mopt[type] ? DQUOT_LIMITS_ENABLED : 0));
...
}
}
---DQUOT_USAGE_ENABLED一直开启;根据是否有相关mount option,决定是否开启DQOT_LIMITS_ENABLE,对应到代码中是:
dquot_add_inodes()
---
newinodes = dquot->dq_dqb.dqb_curinodes + inodes;
if (!sb_has_quota_limits_enabled(dquot->dq_sb, dquot->dq_id.type) ||
test_bit(DQ_FAKE_B, &dquot->dq_flags))
goto add;
if (dquot->dq_dqb.dqb_ihardlimit &&
newinodes > dquot->dq_dqb.dqb_ihardlimit &&
!ignore_hardlimit(dquot)) {
prepare_warning(warn, dquot, QUOTA_NL_IHARDWARN);
ret = -EDQUOT;
goto out;
}
...
add:
dquot->dq_dqb.dqb_curinodes = newinodes;
---
注意:ext4有两组关于quota的mount option,usrjquota,usrquota,两者差了一个j;一个用于开启显示quota file的Journal,一个用于开启隐式quota file
对已经存在的文件系统,开启quota机制,需要使用tune2fs,参考代码:
handle_quota_options()
-> quota_compute_usage()
---
while (1) {
ret = ext2fs_get_next_inode_full(scan, &ino,
EXT2_INODE(inode), inode_size);
...
if (ino == 0)
break;
if (!inode->i_links_count)
continue;
if (ino == EXT2_ROOT_INO ||
(ino >= EXT2_FIRST_INODE(fs->super) &&
ino != quota_type2inum(PRJQUOTA, fs->super) &&
ino != fs->super->s_orphan_file_inum)) {
space = ext2fs_get_stat_i_blocks(fs, EXT2_INODE(inode)) << 9;
quota_data_add(qctx, inode, ino, space);
quota_data_inodes(qctx, inode, ino, +1);
}
}
---tune2fs也会遍历所有的inode,并存储相关信息;不过,它存在一个方便遍历的条件,ext4的inode都保存在inode table中。
在这里,我们统一看下quotaon部分的执行,我们使用el9的quota,
main()
-> init_mounts_scan()
-> cache_mnt_table()
-> hasquota()
---
/*
* For ext4 we check whether it has quota in system files and if not,
* we fall back on checking standard quotas. Furthermore we cannot use
* standard GETFMT quotactl because that does not distinguish between
* quota in system file and quota in ordinary file.
*/
if (!strcmp(mnt->mnt_type, MNTTYPE_EXT4) || !strcmp(mnt->mnt_type, MNTTYPE_F2FS))
struct if_dqinfo kinfo;
if (quotactl(QCMD(Q_GETINFO, type), dev, 0, (void *)&kinfo) == 0) {
if (kinfo.dqi_flags & DQF_SYS_FILE)
return QF_META;
}
}
---
-> newstate()
---
if (mnt->me_qfmt[type] == QF_META) {
/* Must be non-empty because empty path is always invalid. */
ret = v2_newstate(mnt, type, ".", sflags, QF_VFSV0);
}
else {
int usefmt;
if (!me_hasquota(mnt, type))
return 0;
if (flags & FL_VERBOSE && !warned &&
!strcmp(mnt->me_type, MNTTYPE_EXT4) &&
ext4_supports_quota_feature()) {
warned = 1;
errstr(_("Your kernel probably supports ext4 quota "
"feature but you are using external quota "
"files. Please switch your filesystem to use "
"ext4 quota feature as external quota files "
"on ext4 are deprecated.\n"));
}
if (fmt == -1) {
if (get_qf_name(mnt, type, QF_VFSV0, NF_FORMAT, &extra) >= 0)
usefmt = QF_VFSV0;
else if (get_qf_name(mnt, type, QF_VFSV1, F_FORMAT, &extra) >= 0)
usefmt = QF_VFSV1;
else if (get_qf_name(mnt, type, QF_VFSOLD, F_FORMAT, &extra) >= 0)
usefmt = QF_VFSOLD;
else {
errstr(_("Cannot find quota file on %s [%s] to turn quotas on/off.\n"), nt->me_dir, mnt->me_devname);
return 1;
}
} else {
if (get_qf_name(mnt, type, fmt, NF_FORMAT, &extra) < 0) {
errstr(_("Quota file on %s [%s] does not exist or has wrong format.\n"), nt->me_dir, mnt->me_devname);
return 1;
}
usefmt = fmt;
}
if (is_tree_qfmt(usefmt))
ret = v2_newstate(mnt, type, extra, sflags, usefmt);
else
ret = v1_newstate(mnt, type, extra, sflags, QF_VFSOLD);
free(extra);
}
---
从中我们可以得到以下信息:
- quotaon命令通过quotactl系统调用获取相关挂载点的信息,其中包括了该挂载点是否使用system quota file,即隐式quota file;如果采用,传给quotactl的quota file是 ‘ . ‘ ;
-
如果使用显式的quota file,quotaon会从mnt options中获得quota file,如果没有,则采用系统默认,相关的代码为:
get_qf_name() --- if (has_quota_file_definition) { int len = strlen(qfullname); copy_mntoptarg(qfullname + len, pathname, sizeof(qfullname) - len); } else { snprintf(qfullname, PATH_MAX, "%s/%s.%s", mnt->me_dir, basenames[fmt], extensions[type]); } --- #define INITQFBASENAMES {\ "quota",\ "aquota",\ "aquota",\ "",\ "",\ "",\ } #define INITQFNAMES { \ N_("user"), /* USRQUOTA */ \ N_("group"), /* GRPQUOTA */ \ N_("project"), /* PRJQOTA */ \ N_("undefined"), \ }
进入内核态,两种方式也有不同的路径:
SYSCALL_DEFINE4(quotactl, unsigned int, cmd, const char __user *, special,
qid_t, id, void __user *, addr)
---
if (cmds == Q_QUOTAON) {
ret = user_path_at(AT_FDCWD, addr, LOOKUP_FOLLOW|LOOKUP_AUTOMOUNT, &path);
if (ret)
pathp = ERR_PTR(ret);
else
pathp = &path;
}
sb = quotactl_block(special, cmds);
...
ret = do_quotactl(sb, type, cmds, id, addr, pathp);
-> quota_quotaon()
---
if (!sb->s_qcop->quota_on && !sb->s_qcop->quota_enable)
return -ENOSYS;
if (sb->s_qcop->quota_enable)
return sb->s_qcop->quota_enable(sb, qtype_enforce_flag(type));
if (IS_ERR(path))
return PTR_ERR(path);
return sb->s_qcop->quota_on(sb, type, id, path);
---
如果是显式quota file走的是quota_on回调,如果是隐式 quota file走的是quota_enable;
到这里,真想吐槽下,这代码。。。
2.2.2.4 quota role
quota通过三种role控制配合,即:user,group和project;user和group比较常见;这里我们着重说下project。
ext4的inode的extra fields中新增了i_projid,要支持此功能,on disk inode size必须是256;这一点,centos7上默认mkfs都是满足的,可以通过/etc/mke2fs.conf确认,其中inode_size是256。
改变一个文件的project id,需要执行以下命令:
chattr +P foo // foo下的所有文件和目录都具有会继承其project id
chattr -p 123 foo // 设置其project id为123对应到内核的代码是:
ext4_fileattr_set() // FS_IOC_SETFLAGS
-> ext4_ioctl_setproject()
---
err = ext4_get_inode_loc(inode, &iloc);
...
err = dquot_initialize(inode);
...
handle = ext4_journal_start(inode, EXT4_HT_QUOTA, EXT4_QUOTA_INIT_BLOCKS(sb) + EXT4_QUOTA_DEL_BLOCKS(sb) + 3);
...
err = ext4_reserve_inode_write(handle, inode, &iloc);
...
transfer_to[PRJQUOTA] = dqget(sb, make_kqid_projid(kprojid));
if (!IS_ERR(transfer_to[PRJQUOTA])) {
down_read(&EXT4_I(inode)->xattr_sem);
err = __dquot_transfer(inode, transfer_to);
up_read(&EXT4_I(inode)->xattr_sem);
dqput(transfer_to[PRJQUOTA]);
...
}
EXT4_I(inode)->i_projid = kprojid;
inode->i_ctime = current_time(inode);
rc = ext4_mark_iloc_dirty(handle, inode, &iloc);
...
ext4_journal_stop(handle);
---
__ext4_new_inode()
---
if (ext4_has_feature_project(sb) &&
ext4_test_inode_flag(dir, EXT4_INODE_PROJINHERIT))
ei->i_projid = EXT4_I(dir)->i_projid;
else
ei->i_projid = make_kprojid(&init_user_ns, EXT4_DEF_PROJID);
---
在切换project id时,还进行了quota转移。
2.2.3 XFS Quota
引用其中的一段:
The XFS quota system differs from other file systems in a number of ways. Most importantly,
XFS considers quota information as file system metadata and uses journaling to provide a higher level guarantee of consistency
.
从之前的ext4 quota的实现的细节,我们可以感觉到,quota机制游离在ext4文件系统之外;而xfs quota机制是从设计之初就一直跟随的。参考链接:
2.2.3.1 Quota File
xfs的quota file是隐式的,在文件系统挂载时,如果开启了quota,并且还没有quota file inode,就动态申请:
xfs_qm_mount_quotas()
-> xfs_qm_init_quotainfo()
-> xfs_qm_init_quotainos()
-> xfs_qm_qino_alloc()
---
error = xfs_trans_alloc(mp, &M_RES(mp)->tr_create, need_alloc ? XFS_QM_QINOCREATE_SPACE_RES(mp) : 0, 0, 0, &tp);
...
if (need_alloc) {
xfs_ino_t ino;
error = xfs_dialloc(&tp, 0, S_IFREG, &ino);
if (!error)
error = xfs_init_new_inode(&init_user_ns, tp, NULL, ino,
S_IFREG, 1, 0, 0, false, ipp);
}
...
spin_lock(&mp->m_sb_lock);
...
if (flags & XFS_QMOPT_UQUOTA)
mp->m_sb.sb_uquotino = (*ipp)->i_ino;
else if (flags & XFS_QMOPT_GQUOTA)
mp->m_sb.sb_gquotino = (*ipp)->i_ino;
else
mp->m_sb.sb_pquotino = (*ipp)->i_ino;
spin_unlock(&mp->m_sb_lock);
xfs_log_sb(tp);
error = xfs_trans_commit(tp);
...
---而且还会将quota file的inode保存进super block中。
quota信息保存在xfs_dqblk_t中,quota file的每个file system block保存若干个xfs_dqblk_t;参考如下:
*
* This defines the unit of allocation of dquots.
*
* Currently, it is just one file system block, and a 4K blk contains 30
* (136 * 30 = 4080) dquots. It's probably not worth trying to make
* this more dynamic.
*
* However, if this number is changed, we have to make sure that we don't
* implicitly assume that we do allocations in chunks of a single filesystem
* block in the dquot/xqm code.
*
* This is part of the ondisk format because the structure size is not a power
* of two, which leaves slack at the end of the disk block.
/
#define XFS_DQUOT_CLUSTER_SIZE_FSB (xfs_filblks_t)1
xfs_qm_init_quotainfo()
---
/* Precalc some constants */
qinf->qi_dqchunklen = XFS_FSB_TO_BB(mp, XFS_DQUOT_CLUSTER_SIZE_FSB);
qinf->qi_dqperchunk = xfs_calc_dquots_per_chunk(qinf->qi_dqchunklen); //BBTOB(nbblks) / sizeof(xfs_dqblk_t);
---那么,xfs_dqblk_t保存在quota file的什么位置呢?参考代码:
xfs_create()
-> xfs_qm_vop_dqalloc()
---
f ((flags & XFS_QMOPT_UQUOTA) && XFS_IS_UQUOTA_ON(mp)) {
if (!uid_eq(inode->i_uid, uid)) {
...
error = xfs_qm_dqget(mp, from_kuid(user_ns, uid), XFS_DQTYPE_USER, true, &uq);
...
}
}
if ((flags & XFS_QMOPT_GQUOTA) && XFS_IS_GQUOTA_ON(mp)) {
if (!gid_eq(inode->i_gid, gid)) {
...
error = xfs_qm_dqget(mp, from_kgid(user_ns, gid), XFS_DQTYPE_GROUP, true, &gq);
...
}
}
if ((flags & XFS_QMOPT_PQUOTA) && XFS_IS_PQUOTA_ON(mp)) {
if (ip->i_projid != prid) {
...
error = xfs_qm_dqget(mp, prid, XFS_DQTYPE_PROJ, true, &pq);
...
}
}
---
xfs_qm_dqget()
-> xfs_qm_dqread()
-> xfs_dquot_alloc()
---
dqp->q_fileoffset = (xfs_fileoff_t)id / mp->m_quotainfo->qi_dqperchunk;
dqp->q_bufoffset = (id % mp->m_quotainfo->qi_dqperchunk) * sizeof(xfs_dqblk_t);
---
-> xfs_dquot_disk_read()
---
error = xfs_bmapi_read(quotip, dqp->q_fileoffset,
XFS_DQUOT_CLUSTER_SIZE_FSB, &map, &nmaps, 0);
---
-> xfs_dquot_from_disk()
---
struct xfs_disk_dquot *ddqp = bp->b_addr + dqp->q_bufoffset;
---不同的quota根据其role类型的id,比如user id、group id或者project id,
2.2.3.2 quota的开启与关闭
我们先看下xfs quota的开启步骤:
mount -o uquota /dev/xvdb1 /xfs
or
mount -o gquota /dev/xvdb1 /xfs
or
mount -o pquota /dev/xvdb1 /xfs注:xfs从一开始设计就支持quota功能,所以,它没有ext4那么多烂七八糟的步骤,非常简洁
下面我们看下,在执行该步骤的时候,内核发生了什么。
xfs_fs_parse_param()
---
...
case Opt_pquota:
case Opt_prjquota:
parsing_mp->m_qflags |= (XFS_PQUOTA_ACCT | XFS_PQUOTA_ACTIVE | XFS_PQUOTA_ENFD);
return 0;
case Opt_pqnoenforce:
parsing_mp->m_qflags |= (XFS_PQUOTA_ACCT | XFS_PQUOTA_ACTIVE);
parsing_mp->m_qflags &= ~XFS_PQUOTA_ENFD;
return 0;
...
---这里有三个flag,
-
ACTIVE,当相关quota功能被执行关闭时,会在开始时清除ACTIVE标记,此时,虽然ACCT还在,但是quota功能已经关闭了,参考comment:
/* * Incore only flags for quotaoff - these bits get cleared when quota(s) * are in the process of getting turned off. These flags are in m_qflags but * never in sb_qflags. */ - ACCT,即对相关的配额信息进行统计,不会对超过限额的操作执行强制操作;检查该标记的宏为XFS_IS_xQUOTA_RUNNING;
- ENFD,如果超过限额,则进行强制操作,检查该表的宏为XFS_IS_xQUOTA_ENFORCED,
关于ACCT和ENFD标记的作用位置,可以参考如下代码:
xfs_trans_reserve_quota_bydquots()
---
// ACCT和ACTIVE标记发挥作用的位置
if (!XFS_IS_QUOTA_RUNNING(mp) || !XFS_IS_QUOTA_ON(mp))
return 0;
...
if (pdqp) {
error = xfs_trans_dqresv(tp, mp, pdqp, nblks, ninos, flags);
if (error)
goto unwind_grp;
}
...
---
xfs_trans_dqresv()
---
if ((flags & XFS_QMOPT_FORCE_RES) == 0 && dqp->q_id &&
xfs_dquot_is_enforced(dqp)) {
...
quota_nl = xfs_dqresv_check(blkres, qlim, nblks, &fatal);
if (quota_nl != QUOTA_NL_NOWARN) {
xfs_quota_warn(mp, dqp, quota_nl + 3);
if (fatal)
goto error_return;
}
... // inode quota check here
}
/*
* Change the reservation, but not the actual usage.
* Note that q_blk.reserved = q_blk.count + resv
*/
blkres->reserved += (xfs_qcnt_t)nblks;
dqp->q_ino.reserved += (xfs_qcnt_t)ninos;
---
xfs_dquot_is_enforced()
---
switch (xfs_dquot_type(dqp)) {
case XFS_DQTYPE_USER:
return XFS_IS_UQUOTA_ENFORCED(dqp->q_mount);
case XFS_DQTYPE_GROUP:
return XFS_IS_GQUOTA_ENFORCED(dqp->q_mount);
case XFS_DQTYPE_PROJ:
return XFS_IS_PQUOTA_ENFORCED(dqp->q_mount);
}
---如果是一个已经运行了一段时间的xfs文件系统上开启quota功能,如何统计之前的数据?ext4的相关处理在e2fstune中,而xfs则直接放在了内核态,参考代码:
#define XFS_QM_NEED_QUOTACHECK(mp) \
((XFS_IS_UQUOTA_ON(mp) && \
(mp->m_sb.sb_qflags & XFS_UQUOTA_CHKD) == 0) || \
(XFS_IS_GQUOTA_ON(mp) && \
(mp->m_sb.sb_qflags & XFS_GQUOTA_CHKD) == 0) || \
(XFS_IS_PQUOTA_ON(mp) && \
(mp->m_sb.sb_qflags & XFS_PQUOTA_CHKD) == 0))
xfs_qm_mount_quotas()
---
if (XFS_QM_NEED_QUOTACHECK(mp)) {
error = xfs_qm_quotacheck(mp);
if (error) {
/* Quotacheck failed and disabled quotas. */
return;
}
}
---
xfs_qm_quotacheck()
---
xfs_notice(mp, "Quotacheck needed: Please wait.");
if (uip) {
error = xfs_qm_reset_dqcounts_buf(mp, uip, XFS_DQTYPE_USER, &buffer_list);
flags |= XFS_UQUOTA_CHKD;
}
if (gip) {
error = xfs_qm_reset_dqcounts_buf(mp, gip, XFS_DQTYPE_GROUP, &buffer_list);
flags |= XFS_GQUOTA_CHKD;
}
if (pip) {
error = xfs_qm_reset_dqcounts_buf(mp, pip, XFS_DQTYPE_PROJ, &buffer_list);
flags |= XFS_PQUOTA_CHKD;
}
error = xfs_iwalk_threaded(mp, 0, 0, xfs_qm_dqusage_adjust, 0, true, NULL);
/*
* We've made all the changes that we need to make incore. Flush them
* down to disk buffers if everything was updated successfully.
*/
if (XFS_IS_UQUOTA_ON(mp)) {
error = xfs_qm_dquot_walk(mp, XFS_DQTYPE_USER, xfs_qm_flush_one, &buffer_list);
}
if (XFS_IS_GQUOTA_ON(mp)) {
error2 = xfs_qm_dquot_walk(mp, XFS_DQTYPE_GROUP, xfs_qm_flush_one, &buffer_list);
}
if (XFS_IS_PQUOTA_ON(mp)) {
error2 = xfs_qm_dquot_walk(mp, XFS_DQTYPE_PROJ, xfs_qm_flush_one, &buffer_list);
}
error2 = xfs_buf_delwri_submit(&buffer_list);
mp->m_qflags &= ~XFS_ALL_QUOTA_CHKD;
mp->m_qflags |= flags;
...
xfs_notice(mp, "Quotacheck: Done.");
---相关流程,内核会打印出log提示。这里有必要详细解释下XFS_xQUOTA_CHKD这个标记;
- 如果super block中没有这个标记,在xfs挂载并且开启quota的情况下,会执行quotacheck;
- 在执行完quotacheck之后,会为super block设置上这个标记,参考xfs_qm_mount_quotas();
-
如果在运行中关闭quota功能,则会清除CHKD标记,这样再次开启时,可以保证开启quotacheck,参考代码:
xfs_qm_scall_quotaoff() --- if (flags & XFS_PQUOTA_ACCT) { dqtype |= XFS_QMOPT_PQUOTA; flags |= (XFS_PQUOTA_CHKD | XFS_PQUOTA_ENFD); inactivate_flags |= XFS_PQUOTA_ACTIVE; } error = xfs_qm_log_quotaoff(mp, &qoffstart, flags); --- error = xfs_trans_alloc(mp, &M_RES(mp)->tr_qm_quotaoff, 0, 0, 0, &tp); ... qoffi = xfs_trans_get_qoff_item(tp, NULL, flags & XFS_ALL_QUOTA_ACCT); xfs_trans_log_quotaoff_item(tp, qoffi); spin_lock(&mp->m_sb_lock); mp->m_sb.sb_qflags = (mp->m_qflags & ~(flags)) & XFS_MOUNT_QUOTA_ALL; spin_unlock(&mp->m_sb_lock); xfs_log_sb(tp); ... xfs_trans_set_sync(tp); error = xfs_trans_commit(tp); --- ---
另外,需要特别说明的是,quota关闭可以完全关闭acct和enforced,但是开启却仅能开启enforced。
2.2.4 拾遗
之前已经介绍了ext4和xfs的quota的实现,本小结主要介绍一些被遗漏的细节。
2.2.4.1 Quota & DA
这里简单介绍下Delayed Allocation及其好处,参考链接:
XFS: the big storage file system for Linux
![]()
https://www.usenix.org/system/files/login/articles/140-hellwig.pdf
In delayed allocation, specific disk locations are not chosen when a buffered write is submitted; only in-memory reservations take place. Actual disk blocks are not chosen by the allocator until the data is sent to disk due to memory pressure, periodic write-backs, or an explicit sync request.
With delayed allocation, there is a much better approximation of the actual size of the file when deciding about the block placement on disk. In the best case the whole file may be in memory and can be allocated in one contiguous region. In practice XFS tends to allocate contiguous regions of 50 to 100 GiB when performing large sequential I/O, even when multiple threads write to the file system at the same time
那么这两个机制之间如何配合?
ext4_da_map_blocks()
-> ext4_insert_delayed_block()
-> ext4_da_reserve_space()
-> dquot_reserve_block() // DQUOT_SPACE_WARN | DQUOT_SPACE_RESERVE
-> dquot_add_space()
---
tspace = dquot->dq_dqb.dqb_curspace + dquot->dq_dqb.dqb_rsvspace
+ space + rsv_space;
if (dquot->dq_dqb.dqb_bhardlimit &&
tspace > dquot->dq_dqb.dqb_bhardlimit &&
!ignore_hardlimit(dquot)) {
if (flags & DQUOT_SPACE_WARN)
prepare_warning(warn, dquot, QUOTA_NL_BHARDWARN);
ret = -EDQUOT;
goto finish;
...
if (!ret) {
dquot->dq_dqb.dqb_rsvspace += rsv_space;
dquot->dq_dqb.dqb_curspace += space;
}
---
ext4_ext_map_blocks()
-> ext4_da_update_reserve_space()
-> dquot_claim_block()
-> dquot_claim_space_nodirty()
---
spin_lock(&inode->i_lock);
for (cnt = 0; cnt < MAXQUOTAS; cnt++) {
if (dquots[cnt]) {
struct dquot *dquot = dquots[cnt];
spin_lock(&dquot->dq_dqb_lock);
dquot->dq_dqb.dqb_curspace += number;
dquot->dq_dqb.dqb_rsvspace -= number;
spin_unlock(&dquot->dq_dqb_lock);
}
}
/* Update inode bytes */
*inode_reserved_space(inode) -= number;
__inode_add_bytes(inode, number);
spin_unlock(&inode->i_lock);
mark_all_dquot_dirty(dquots);
---
dquot中也保存了一个rsvspace,同时也检查space limit;在真正进行空间分配时,才将更改记录进quota file。
(待续)
3 Block
3.1 bio
3.2 request
3.3 iostat
本小节分别看下block层几个核心指标的含义和数据来源
3.3.1 util%
根据iostat man page的解释:
Percentage of elapsed time during which I/O requests were issued to the device (bandwidth utilization for the device). Device saturation occurs when this value is close to 100% for devices serving requests serially. But for devices serving requests in parallel, such as RAID arrays and modern SSDs, this number does not reflect their performance limits
其中对于
设备利用率
提到了两种解释:
- 设备有inflight IO的时间的占比,直观理解为,设备处理IO的能力越强,则IO返回的速度越快,于是IO在设备的停留的时间就越短,有inlight IO的时间的占比自然越低;
- 带宽利用率,这个则更加直接,当前带宽占设备带宽上限的百分比;
接下来,我们分别做几个简单试验,内核版本为
Centos 4.18
:
fio –bs=4k –iodepth=32 –rw=randread –direct=1 –ioengine=libaio –numjobs=1 –runtime=60 –name=test –filename=/dev/sdb
| HDD ST4000NM0035-1V4 | ||
| 测试条件 | BW | Util% |
| rw=randread bs=4k iodepth=32 | 0.83 MB/s | 20% |
| rw=read bs=4k iodepth=32 | 202 MB/s | 100% |
| rw=read bs=1M iodepth=1 | 203 MB/s | 41% |
| NVMe SSD HUSMR7632BHP301 | ||
| 测试条件 | BW | Util% |
| rw=randread bs=4k iodepth=32 | 1454 MB/s | 100 % |
| rw=randread bs=4k iodepth=32 numjobs=16 | 5448 MB/s | 100 % |
对于两个测试结果,
带宽利用率
这个解释无疑是不成立的,下面,我们主要从
IO处理能力利用率
的角度分析,Util%结果的意义。
对于HDD机械盘来说,其处理IO的能力与IO Pattern强相关;参考随机小IO这个结果:
| rw=randread bs=4k iodepth=32 | 0.83 MB/s | 20% |
利用率只有20%,是不是说还有80%的能力未被利用?然而,无论我们如何加压,只要是随机IO,带宽和利用率始终无法上去,也就是说此时设备对随机IO的处理能力,或者准确的说,是
磁头的处理能力
,已经达到上限,即100%;我们再参考下面顺序IO的结果:
| rw=read bs=4k iodepth=32 | 202 MB/s | 100% |
| rw=read bs=1M iodepth=1 | 203 MB/s | 41% |
bs = 1M时,利用率只有40%,是说磁盘还有60%的使用空间?此时203MB/s其实已经达到带宽上限,如果我们再加压,带宽基本不会再有上升,当然,利用率确实有可能上升到100%。那么,在这个测试中,利用率有什么意义呢?
再看NVMe SDD的情况,结果更加明显,同样都是利用率100%,带宽差了几倍 ;造成这种差异的原因是,SSD内部的并发能力,详情可以参考论文,这里引用里面的一张图:
Parallel all the time: Plane Level Parallelism Exploration for High Performance SSDs
![]()
https://storageconference.us/2019/Research/ParallelAllTheTime.pdf
综上,从数据表现来看,util%这个指标对于表征存储设备的使用情况,参考意义不大。
那么util%到底是什么?
接下来,我们对照代码看下。
参考iostat代码中util的计算方法:
iostat源码
Performance monitoring tools for Linux. Contribute to sysstat/sysstat development by creating an account on GitHub.
![]()
https://github.com/sysstat/sysstat/blob/master/iostat.c
write_ext_stat()
-> compute_ext_disk_stats()
---
xds->util = S_VALUE(sdp->tot_ticks, sdc->tot_ticks, itv);
---
read_sysfs_dlist_part_stat()
-> read_sysfs_file_stat()
---
i = fscanf(fp, "%lu %lu %lu %lu %lu %lu %lu %u %u %u %u",
&rd_ios, &rd_merges_or_rd_sec, &rd_sec_or_wr_ios, &rd_ticks_or_wr_sec,
&wr_ios, &wr_merges, &wr_sec, &wr_ticks, &ios_pgr, &tot_ticks, &rq_ticks);
---
filename = /sys/block/xxx/stat
tot_ticks的值来自/sys/block/xxx/stat,参考内核代码diskstat_show,tot_ticks就是disk_stats.io_ticks;该统计数据的来源为:
void update_io_ticks(struct hd_struct *part, unsigned long now)
{
unsigned long stamp;
again:
stamp = READ_ONCE(part->stamp);
if (unlikely(stamp != now)) {
if (likely(cmpxchg(&part->stamp, stamp, now) == stamp)) {
__part_stat_add(part, io_ticks, 1);
}
}
if (part->partno) {
part = &part_to_disk(part)->part0;
goto again;
}
}
blk_mq_bio_to_request()
-> blk_account_io_start()
-> update_io_ticks()
__blk_mq_end_request()
-> blk_account_io_done()
-> update_io_ticks(io_ticks的统计,取决于io start和io done两个事件的间隔,当IO延迟高于1 jiffy(HZ = 1000, 1 jiffy = 1ms)时,统计的io_ticks是少于应该统计的值的;对比测试结果:
| 条件 | bw | rwait | util% |
| rw=read bs=1M iodepth=1 | 203.00 MB/s | 4.05 ms | 41.10 |
| rw=read bs=4M iodepth=1 | 206.69 MB/s | 11.98 ms | 32.30 |
bs = 4M时,其带宽稍高,利用率反到降低了。
其实这个算法并不是一直如此,而是经过一次修改,参考如下commit:
commit 5b18b5a737600fd20ba2045f320d5926ebbf341a
Author: Mikulas Patocka <mpatocka@redhat.com>
Date: Thu Dec 6 11:41:19 2018 -0500
block: delete part_round_stats and switch to less precise counting
We want to convert to per-cpu in_flight counters.
The function part_round_stats needs the in_flight counter every jiffy, it
would be too costly to sum all the percpu variables every jiffy, so it
must be deleted. part_round_stats is used to calculate two counters -
time_in_queue and io_ticks.
time_in_queue can be calculated without part_round_stats, by adding the
duration of the I/O when the I/O ends (the value is almost as exact as the
previously calculated value, except that time for in-progress I/Os is not
counted).
io_ticks can be approximated by increasing the value when I/O is started
or ended and the jiffies value has changed. If the I/Os take less than a
jiffy, the value is as exact as the previously calculated value. If the
I/Os take more than a jiffy, io_ticks can drift behind the previously
calculated value.
Signed-off-by: Mikulas Patocka <mpatocka@redhat.com>
Signed-off-by: Mike Snitzer <snitzer@redhat.com>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
在这个commit之前,io_tick的算法为:
static void part_round_stats_single(struct request_queue *q,
struct hd_struct *part, unsigned long now,
unsigned int inflight)
{
if (inflight) {
__part_stat_add(part, time_in_queue,
inflight * (now - part->stamp));
__part_stat_add(part, io_ticks, (now - part->stamp));
}
part->stamp = now;
}在这种算法下,只要存储设备上有inflight的IO,时间就会被计入io_ticks,
甚至,在diskstat_show()中,都会调用一次该函数;所以,如果有IO hung,util%会显示100%。
此时,util%的意义更接近于,在
过去的时间内,设备被使用的时间的在占比。
综上,util%不可以作为设备能力的利用率来参考
。
工具
blkid
当我们对着一个盘执行blkid是,会得到以下结果:
# blkid /dev/sda
/dev/sda: PTTYPE="dos"
# blkid /dev/sda1
/dev/sda1: UUID="3f37d310-ee74-4107-bebd-3b9a91d80846" TYPE="ext4"
# blkid /dev/sda2
/dev/sda2: UUID="0a62b9fb-40b6-45bd-ba25-1217fb815279" TYPE="ext4"
# blkid /dev/sda3
/dev/sda3: UUID="247b3815-327e-4764-9931-18fd5429eff5" TYPE="ext4"
# blkid /dev/sdb
/dev/sdb: PTTYPE="dos"
# blkid /dev/sdb1
/dev/sdb1: UUID="9f05a38c-5cd8-470a-a16f-153157eb029c" TYPE="xfs"
# blkid /dev/sdb2这样的结果是怎么来的呢?
blkid_new_probe()
---
for (i = 0; i < BLKID_NCHAINS; i++) {
pr->chains[i].driver = chains_drvs[i];
pr->chains[i].flags = chains_drvs[i]->dflt_flags;
pr->chains[i].enabled = chains_drvs[i]->dflt_enabled;
}
---
static const struct blkid_chaindrv *chains_drvs[] = {
[BLKID_CHAIN_SUBLKS] = &superblocks_drv,
[BLKID_CHAIN_TOPLGY] = &topology_drv,
[BLKID_CHAIN_PARTS] = &partitions_drv
};
superblocks_probe()
---
for ( ; i < ARRAY_SIZE(idinfos); i++) {
...
id = idinfos[i];
...
rc = blkid_probe_get_idmag(pr, id, &off, &mag);
...
if (rc != BLKID_PROBE_OK)
continue;
if (id->probefunc) {
rc = id->probefunc(pr, mag);
if (rc != BLKID_PROBE_OK) {
blkid_probe_chain_reset_values(pr, chn);
if (rc < 0)
break;
continue;
}
}
...
if (!rc && mag)
rc = blkid_probe_set_magic(pr, off, mag->len,
(const unsigned char *) mag->magic);
---
blkid_probe_get_idmag()
---
if (id)
mag = &id->magics[0];
// Aligned address to 1K
off = ((mag->kboff + (mag->sboff >> 10)) << 10);
buf = blkid_probe_get_buffer(pr, off, 1024);
-> read_buffer()
-> lseek()
-> read()
if (buf && !memcmp(mag->magic,
buf + (mag->sboff & 0x3ff), mag->len)) {
if (offset)
*offset = off + (mag->sboff & 0x3ff);
if (res)
*res = mag;
return BLKID_PROBE_OK;
}
---
static const struct blkid_idinfo *idinfos[] =
{
/* RAIDs */
&linuxraid_idinfo,
...
&bcache_idinfo,
&bluestore_idinfo,
&drbd_idinfo,
&lvm1_idinfo,
&snapcow_idinfo,
...
/* Filesystems */
&vfat_idinfo,
&swap_idinfo,
&xfs_idinfo,
&xfs_log_idinfo,
&exfs_idinfo,
&ext4dev_idinfo,
&ext4_idinfo,
&ext3_idinfo,
&ext2_idinfo,
&jbd_idinfo,
&ocfs2_idinfo,
&oracleasm_idinfo,
&vxfs_idinfo,
&btrfs_idinfo,
};
#define BLKID_EXT_MAGICS \
{ \
{ \
.magic = EXT_SB_MAGIC, \
.len = sizeof(EXT_SB_MAGIC) - 1, \
.kboff = EXT_SB_KBOFF, \
.sboff = EXT_MAG_OFF \
}, \
{ NULL } \
}
probe_ext4()
-> ext_get_info()
---
blkid_probe_set_uuid(pr, es->s_uuid);
---
blkid_probe_set_magic()
---
switch (chn->driver->id) {
case BLKID_CHAIN_SUBLKS:
if (!(chn->flags & BLKID_SUBLKS_MAGIC))
return 0;
rc = blkid_probe_set_value(pr, "SBMAGIC", magic, len);
if (!rc)
rc = blkid_probe_sprintf_value(pr,
"SBMAGIC_OFFSET", "%llu", (unsigned long long)offset);
break;
...
}
---
可以看到,blkid会用穷举法,遍历所有可能的类型,直到找到正确的。