周老师讲的redis,“全网最权威的讲解”.
文章目录
前言
几个常识:
-
计算机中,数据存在磁盘里,磁盘有两个关键的维度指标:1.寻址,ms级速度;2.带宽,G/M 每秒.
内存的两个指标:1.寻址,ns级(秒->毫秒->微秒->纳秒),在寻址上磁盘比内存满了10W倍;2.带宽,也比磁盘大很多 -
I/O buffer:成本问题,如果访问硬盘的时候,都以
磁盘有磁道和扇区,每个扇区512Byte.
如果一个磁盘以512字节为单位读写,会使索引成本变大.(每块数据很小的话,需要索引的块就会很多)
格式化磁盘的时候,有个4K对齐的概念(也可以格式化8K 16K等,看需求),真正使用硬件的时候,并不是以512字节为一次读写量,无论读多少,操作系统都是最少4K从磁盘拿. - 计算机信息系统 2个基础设施:1.冯诺伊曼体系的硬件;2.以太网,tcp/ip的网络
数据存储发展历史:
- 很早以前,刚有计算机的时候,数据可以存在文件里,使用grep awk等获取数据.随着文件变大,查询速度会变慢,硬盘I/O成为瓶颈(需要全量遍历)
-
这时候关系型数据库出现了,带着两个特点
- 从软件从把数据分为一个个的data page,每个data page大小为4K(和磁盘保持一致),但是只有这个并没有什么用.
- 索引,也是硬盘中4K的存储模型,从全量数据中抽取一些特征列作为索引,指向原始数据的data page;查询的时候通过B+树,树干(区间和偏移)在内存中,它的叶子节点是索引和数据的data page,减少I/O.
关系型数据库建表的时候必须给出schema,表有多少列(字段),每一列的类型(字节宽度).
写数据时倾向于行级存储,往data page写入数据的时候不管有没有值都会开辟空间,没值的字段也会(用0)占位.这样的好处是未来添加或修改字段的时候,不需要移动数据,直接覆盖写入即可.
数据库的表很大的时候,性能下降?
如果表有索引,增删改会变慢,时间花在索引的维护上.
那查询速度呢?
对于查询的速度,假设内存够大,可以把B+tree的树干存下,B+tree不受影响,查询条件能够命中索引的话,少量查询依然很快;
当查询并发很大,查询的数据散在不同data page上,会受硬盘带宽影响,速度变慢.因为需要把每个数据块以此从硬盘读到内存中
-
内存级别的关系型数据库
当年SAP出的HANA,内存级别的关系型数据库,很强大很贵,2T内存的一个设备套餐下来2亿人民币
一是因为内存在寻址和带宽上表现优于磁盘;
二是数据在磁盘和内存中体积不一样,磁盘中没有”指针”概念,数据不能被引用而复用,数据会冗余”胀出”;所以同样的数据,内存中会生一些空间 -
缓存,memcached,redis
业务发展需要应对高并发和大数据量的场景,但是内存级别的关系型数据库太贵,所以有人想到了折中的方案:把一些高频访问的数据放入内存中,缓存.
redis介绍
架构师必须有的能力:技术对比,技术选型.技术选型对公司很重要.
数据库引擎百科网站:
db-engines
Redis:The world’s fastest In-memory database.
1.5M ops/sec,<1ms latency(with a single AWS EC2 Server)
一般来说,redis秒级10W操作;关系型数据库(MySQL一般是千级)
redis官网:redis.io,中文网站:redis.cn
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
redis比memcached强在哪里?
redis的value有很多类型:
memcached也是键值对,但是value没有类型的概念,想存储复杂的数据大概需要json格式
json,可以表示很复杂的数据结构,世界上有3种数据表示:
1.单元素 k=a,k=1
2.线性元素 k=[1,2,3],k=[a,x,f]
3.对象k={x=y},复杂的格式k=[{对象},{}]
假设value需要存储一个数组,
-
memcached的弊端在于
1.存储一个json,那么需要返回value所有的数据到客户端.对server段网卡IO压力较大
2.客户端要去解码 -
redis的优势,其实类型不是很重要,优势在于
计算向数据移动
redis的server中对每种类型都有自己的方法,index(),lpop等,server直接返回所需值,IO压力小,client不必解码计算解析json.
实操
安装redis服务
0. 官网下载,解压:tar xf xxx.tar.gz (不加v规避IO)
这是Redis源码,(基本上Linux中的源码都是C开发的),上来先看README,里面有各种介绍和编译安装步骤
编译:把源码编译成可执行程序;
安装:其实就是一个拷贝的过程
编译安装过程如下,进入源码目录后:
1. make
make是Linux自带的编译工具,可面向多个语言,自动根据同目录下的Makefile编译
Redis用C写的,需要cc命令
如果是新系统(我们大概用的都是centOS),那就 yum install gcc(g是GNU一个开源组织)
安装完gcc后执行make distclean清除上次的编译结果,然后重新执行make
编译后src目录下已经有redis-cli redis-server等可执行程序,这里也可以直接(前台)运行程序
2. make install PREFIX=/data/redis
会把编译后的可执行程序复制一份到指定文件夹,不会和源码混在一起了;但此时还没有成为系统的服务
3. utils/install_server.sh安装服务
先配置redis的环境变量:
vi /etc/profile
在最后面添加两行:
export REDIS_HOME=/data/redis
export PATH=$PATH:$REDIS_HOME/bin
保存后刷新配置文件:source /etc/profile
此时echo $PATH 应该会输出包括Redis/bin的一些路径,说明配置成功了.
这时候就可以在任何地方使用redis-cli等命令运行程序了
进入源码目录的util目录,然后执行./install_server.sh
根据提示一步步配置安装
会配置端口,日志文件路径,数据持久化路径,可执行程序路径
其实是往/etc/init.d/ 路径下复制了一份执行脚本redis_6379,然后加入了chkconfig
我们可以在任意位置service redis_6379 start/status/stop
可以安装多个实例(进程),通过port区分
继续执行./install_server.sh即可,端口,日志,持久化路径不要相同,程序路径可以相同(没必要搞两份程序).
其实也可以复制多份redis.conf,手动改改配置文件,然后执行redis-server redis.conf指定配置文件启动多个redis实例
了解IO NIO
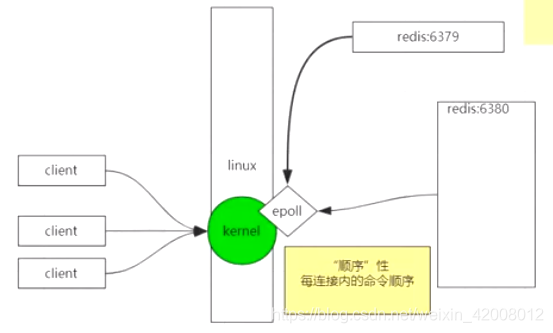
redis是单进程,单线程,单实例的,那为啥会很快呢?
并不是说整个redis服务只有一个线程在工作,而是单线程来处理用户对数据的操作,还有别的线程在做其他事情.
因为redis用了epoll多路复用,所以很快
而redis是单进程的,所以对于同一个客户端的命令的处理是有”顺序”的
nginx的每个worker也是用了epoll,非阻塞多路复用
Linux系统中,一切皆文件,连接其实就是文件描述符
fd:file descriptor,0标准输入,1标准输出,2错误输出,以及其他的…
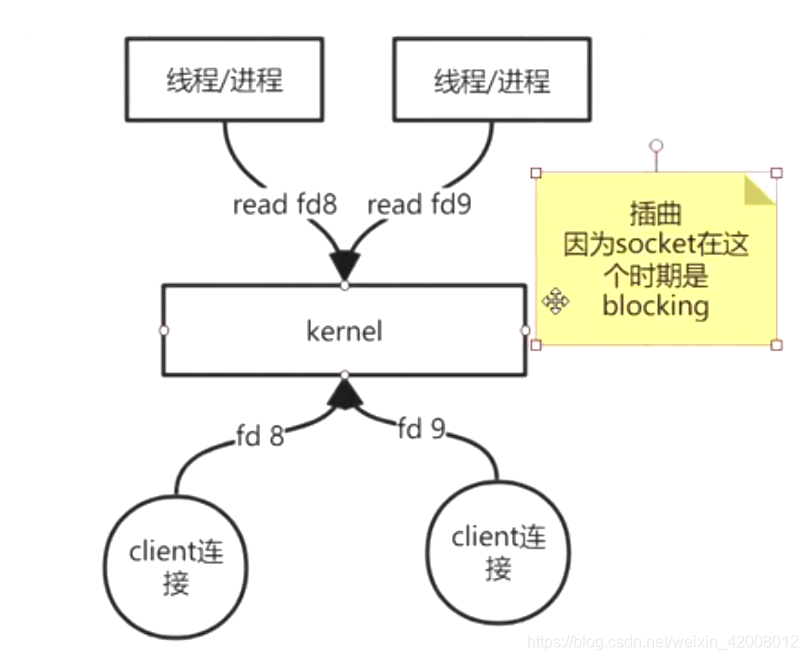
早期的BIO(Blocking IO):
socket产生文件描述符
线程/进程通过read命令读文件描述符(fd)
当一个进程去读fd时,如果client数据包还没到,read命令是阻塞的.
一个链接对应一个线程/进程这样就造成很多资源浪费,切换线程成本等
JVM中,一个线程的成本:
堆是共享空间,线程栈是独立的 默认1MB,可调整线程栈的大小
1.线程多了,CPU调度成本增加
2.内存成本,线程栈
内核发展-同步非阻塞socket nonblock(NIO)
yum install man man-pages 安装一个工具
man可以看8中类型的文档
1类文档:man ls 查看一个Linux命令(e.g.:ls)的详细用法
2类文档: 查看系统调用,内核给用户暴露的方法
man 2 read
可以看看redis进程对应的IO fd:
ps -fe | grep redis 找到redis进程号,假设为6244
ll /proc/6244/fd 会看到各种fd
man 2 socket
可以看到socket可以nonblock
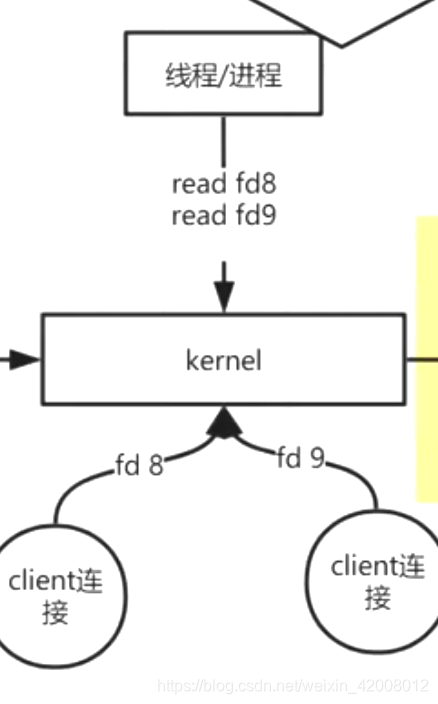
redis一个进程不断的轮询fd
有数据的话就处理,处理完才下一个;没有数据的话就继续轮询.
这个时期的问题:
轮询发生在用户空间,redis写一个死循环不断轮询
如果有很多fd,那么用户进程就需要轮询调用很多次fd,每次查询fd都要调一次系统调用,内核就会在内核态和用户态切换,
内核发展-select多路复用NIO
man 2 select
allow a program to monitor multiple fds,waiting util one or more fds become “ready” .
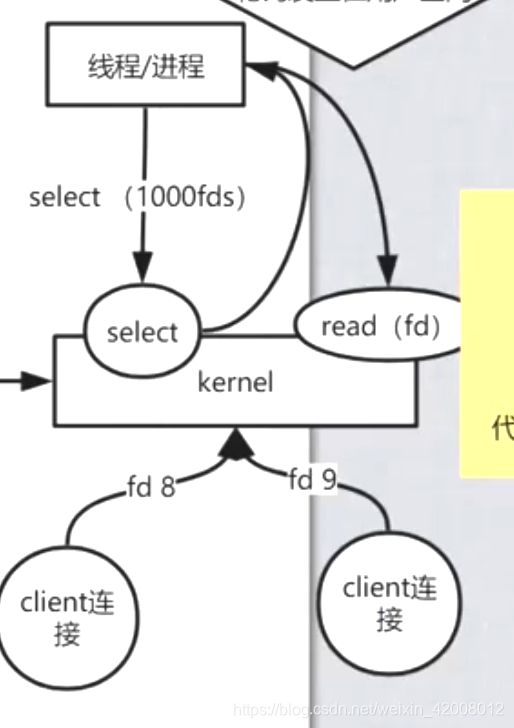
多路复用:
先调用select,一次监控很多fd,返回有数据的fd
遍历返回的结果,然后再read有数据的fd
这个时期的问题:
1.传递数据的成本,调select的时候,传参会有数据拷贝(在用户态和内核态间),很多的fd参数会成为累赘
2.粒度不够细,在遍历的时候有可能数据到达了
内核发展-mmap,epoll
Linux目前还不能实现AIO,只有Windows可以真正实现;Linux可以做到伪AIO,发展过程很复杂
epoll也是属于NIO,而不是AIO
man 2 mmap
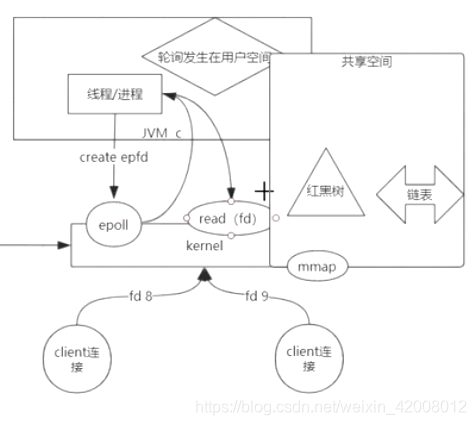
用户空间和内核空间相互独立;这里相当于通过mmap搞了块共享空间,把描述符数据存储在共享空间,而不是进程和内核各自维护一份fd;
man epoll
epoll不是一个系统调用,而是一个整体facility,它里面有3个系统调用
大致过程如下:
1.进程先调用epoll的create,返回一个epoll的fd;
epoll通过mmap开辟一块共享空间,增删改由内核完成,查询内核和用户进程都可以
这块共享空间中有一个红黑树和一个链表
2.进程调用epoll的ctl add/delete sfd,把新来的链接放入红黑树中,
2.1进程调用wait(),等待事件(
事件驱动
)
3.当红黑树中的fd有数据到了,就把它放入一个链表中并维护该数据可写还是可读,wait返回;
4.上层用户空间(通过epoll)从链表中取出fd,然后调用read/write读写数据.
所以epoll也是NIO,不是AIO
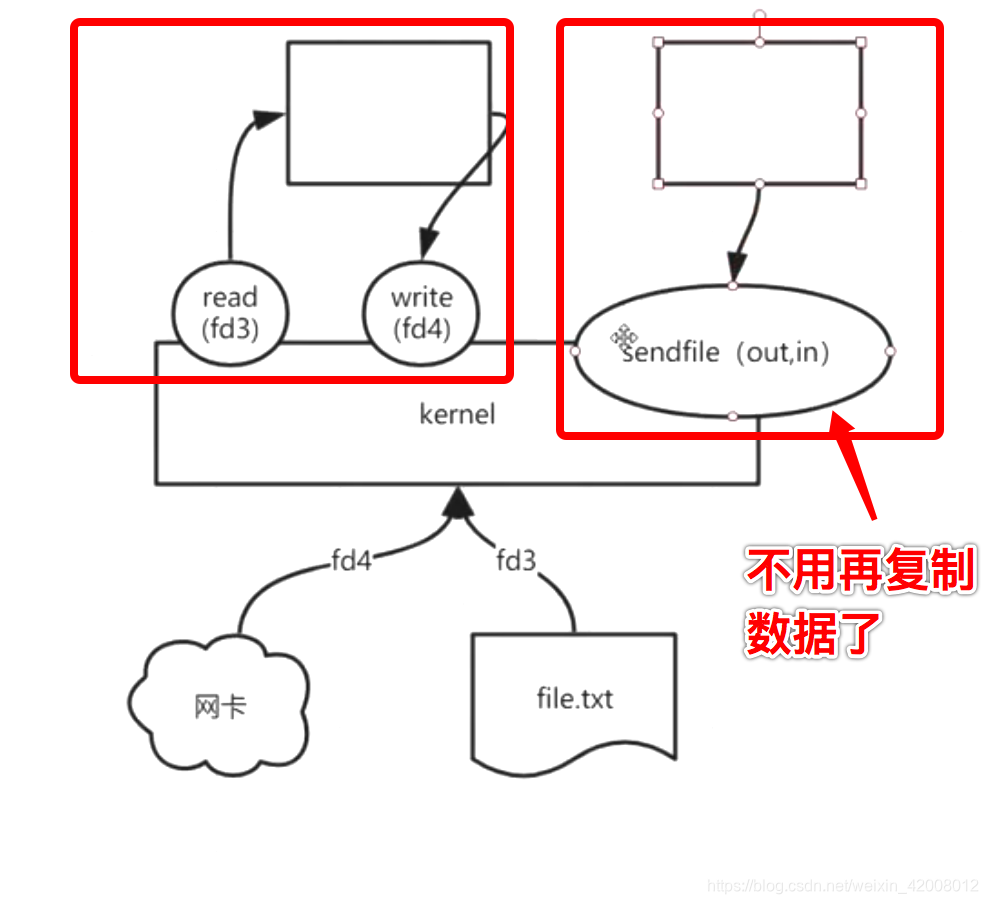
mmap和零拷贝不是一回事,啥是零拷贝?
man 2 sendfile
两个文件描述符之间的0拷贝
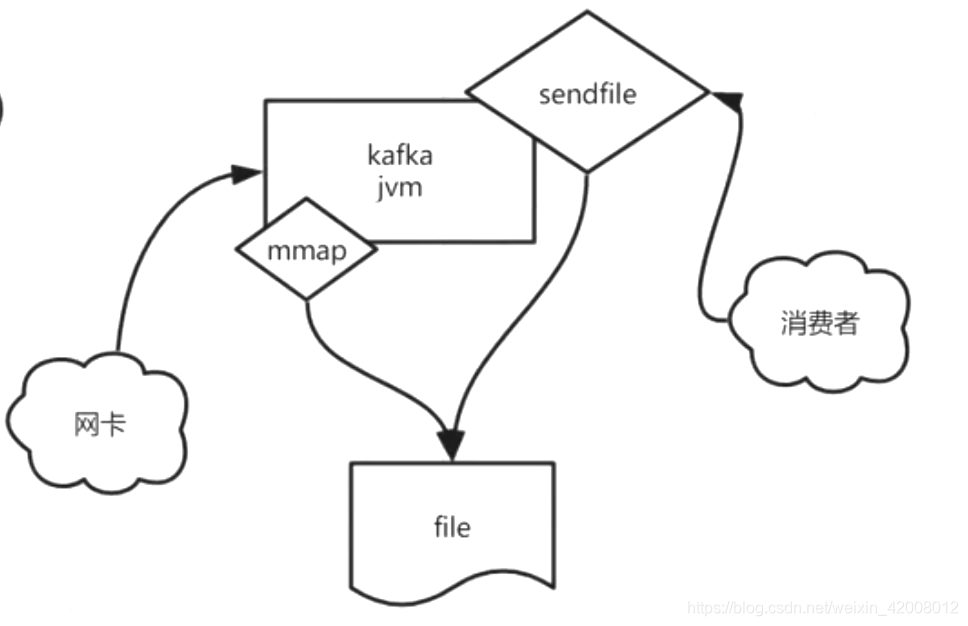
sendfile + mmap可以组成kafka:
kafka是运行在JVM上的一个用户进程
关于epoll和mmap
早期epoll使用mmap共享空间,有个过度,后来丰富了3个api,改变了
这是早期的,后面内核有了响应的sc create ctl wait 就不用自己mmap 了:
The files fs/pipe.c and include/linux/pipe_fs_i.h has been also modified to extend /dev/epoll to pipes ( pipe() ).
The /dev/epoll implementation resides in two new files driver/char/eventpoll.c and the include/linux/eventpoll.h include file.
The interface of the new /dev/epoll is quite different from the previous one coz it works only by mmapping the device file descriptor while the copy-data-to-user-space has been discarded for efficiency reasons. By avoiding unnecessary copies of data through a common set of shared pages the new /dev/epoll achieves more efficency due 1) less CPU cycles needed to copy the data 2) a lower memory footprint with all the advantages on modern cached memory architectures.
The /dev/epoll implementation uses the new file callback notification machanism to register its callbacks that will store events inside the event buffer. The initialization sequence is :
if ((kdpfd = open("/dev/epoll", O_RDWR)) == -1) {
}
if (ioctl(kdpfd, EP_ALLOC, maxfds))
{
}
if ((map = (char *) mmap(NULL, EP_MAP_SIZE(maxfds), PROT_READ,
MAP_PRIVATE, kdpfd, 0)) == (char *) -1)
{
}
where maxfds is the maximum number of file descriptors that it's supposed to stock inside the polling device. Files are added to the interest set by :
struct pollfd pfd;
pfd.fd = fd;
pfd.events = POLLIN | POLLOUT | POLLERR | POLLHUP;
pfd.revents = 0;
if (write(kdpfd, &pfd, sizeof(pfd)) != sizeof(pfd)) {
...
}
and removed with :
struct pollfd pfd;
pfd.fd = fd;
pfd.events = POLLREMOVE;
pfd.revents = 0;
if (write(kdpfd, &pfd, sizeof(pfd)) != sizeof(pfd)) {
...
}
The core dispatching code looks like :
struct pollfd *pfds;
struct evpoll evp;
for (;;) {
evp.ep_timeout = STD_SCHED_TIMEOUT;
evp.ep_resoff = 0;
nfds = ioctl(kdpfd, EP_POLL, &evp);
pfds = (struct pollfd *) (map + evp.ep_resoff);
for (ii = 0; ii < nfds; ii++, pfds++) {
...
}
}
这么一句
if ((map = (char *) mmap(NULL, EP_MAP_SIZE(maxfds), PROT_READ,
MAP_PRIVATE, kdpfd, 0)) == (char *) -1)