https://blog.csdn.net/fzy629442466/article/details/122109956?share_token=7561c807-e86d-4ae9-ad8c-09ae99ca437e
1.MySQL配置打开bin-log日志
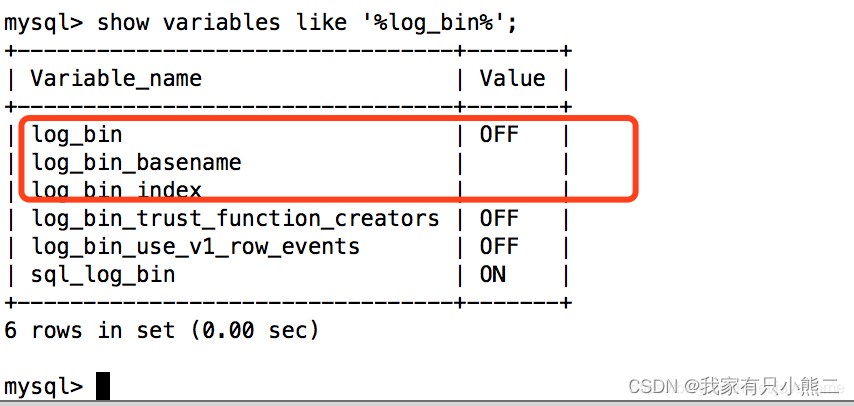
(1).查看状态
show variables like '%log_bin%';
(2).创建binlog存放目录并授权
mkdir /var/lib/mysql-bin
mkdir /var/lib/mysql-bin/log-bin
chown -R mysql:mysql /var/lib/mysql-bin
chmod -R 755 /var/lib/mysql-bin
(3).修改mysql配置文件
增加以下配置
vi /conf/my.cnf
# server-id表示单个结点的id,这里由于只有一个结点,所以可以把id随机指定为一个数,这里将id设置成1。若集群中有多个结点,则id不能相同
server-id=1
# log-bin日志文件的名字为mysql-bin,以及其存储路径
log-bin=/var/lib/mysql-bin/log-bin/mysql-bin
(4).重启mysql,登录检查binlog状态
service mysql restart
2.canal-deployer安装配置
(1).解压安装包
tar -zxvf canal.deployer-1.1.5.tar.gz -C /usr/local/canal/canal-deployer
(2).配置监听MySQL
vi conf/example/instance.properties
# position info
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
canal.instance.dbUsername=root
canal.instance.dbPassword=root
canal.instance.connectionCharset = UTF-8
canal.instance.filter.regex=.*\\..*
- filter 过滤
canal.instance.filter.regex用于配置白名单,也就是我们希望订阅哪些库,哪些表,默认值为.*\\..*,也就是订阅所有库,所有表。
canal.instance.filter.black.regex用于配置黑名单,也就是我们不希望订阅哪些库,哪些表。没有默认值,也就是默认黑名单为空。

(3).启动
sh bin/startup.sh
//log下查看启动日志
3.Kafka模式
vi canal.properties
改动 3 处
#################################################
######### common argument #############
#################################################
# 配置 服务IP
canal.ip = hadoop106
# 配置 模式
canal.serverMode = kafka
#################################################
######### destinations #############
#################################################
# 配置 目标实例
canal.destinations = example
##################################################
######### Kafka #############
##################################################
# 配置 Kafka
kafka.bootstrap.servers = hadoop106:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
vi conf/example/instance.properties
# 更改 kafka 消息主题
canal.mq.topic=employeeTopic
配置完成后重启canal-deployer
4.TCP模式-自定义canal-client
(1).修改canal配置
vi canal.properties
# 配置 模式
canal.serverMode = tcp
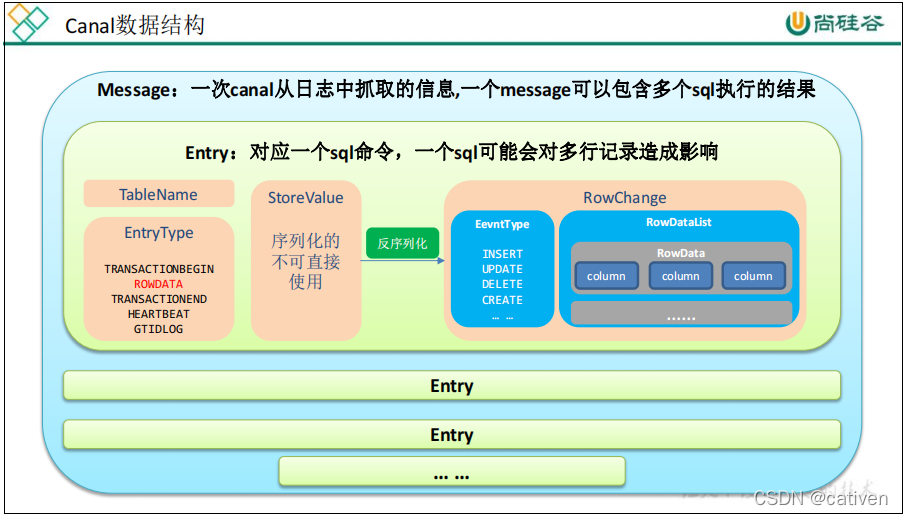
(2).canal数据结构
(3).编写客户端代码
1).pom
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
</dependencies>
2).客户端代码
public class CanalClient {
public static void main(String[] args) throws Exception {
//获取连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("1.1.1.1", 11111), "example", "", "");
//连接
connector.connect();
//指定数据库
connector.subscribe(".*..*");
while (true) {
//4.获取 Message
Message message = connector.get(100);
List<CanalEntry.Entry> entries = message.getEntries();
if (entries.size() <= 0) {
//没有数据等待
System.out.println("没有数据,等待一下");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
for (CanalEntry.Entry entry : entries) {
//获取表名
String tableName = entry.getHeader().getTableName();
//类型
CanalEntry.EntryType entryType = entry.getEntryType();
if (entryType.equals(CanalEntry.EntryType.ROWDATA)) {
ByteString storeValue = entry.getStoreValue();
//反序列化
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//获取事件的类型
CanalEntry.EventType eventType = rowChange.getEventType();
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
for (CanalEntry.RowData rowData : rowDatasList) {
JSONObject beforeData = new JSONObject();
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
for (CanalEntry.Column column : beforeColumnsList) {
beforeData.put(column.getName(), column.getValue());
}
JSONObject afterData = new JSONObject();
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
afterData.put(column.getName(), column.getValue());
}
System.out.println("beforeData:" + beforeData + "afterData:" + afterData + "TableName:" + tableName + "eventType:" + eventType);
}
}
}
}
}
}
}
canal-adapter安装配置
略,使用较少
5.配置ClickHouse
(1).首先创建一张Kafka表引擎的表,用于从Kafka中读取数据
-- 创建Kafka引擎表
CREATE TABLE kafka_user_behavior_src (
user_id UInt64 COMMENT '用户id',
item_id UInt64 COMMENT '商品id',
cat_id UInt16 COMMENT '品类id',
action String COMMENT '行为',
province UInt8 COMMENT '省份id',
ts UInt64 COMMENT '时间戳'
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'cdh04:9092',
kafka_topic_list = 'user_behavior',
kafka_group_name = 'group1',
kafka_format = 'JSONEachRow'
;
(2).创建一张普通表引擎的表,比如MergeTree,面向终端用户使用
CREATE TABLE kafka_user_behavior (
user_id UInt64 COMMENT '用户id',
item_id UInt64 COMMENT '商品id',
cat_id UInt16 COMMENT '品类id',
action String COMMENT '行为',
province UInt8 COMMENT '省份id',
ts UInt64 COMMENT '时间戳'
) ENGINE = MergeTree()
ORDER BY user_id
(3).创建物化视图,用于将Kafka引擎表实时同步到终端用户所使用的表中
CREATE MATERIALIZED VIEW user_behavior_consumer TO kafka_user_behavior
AS SELECT * FROM kafka_user_behavior_src ;
(4).查询数据
select * from kafka_user_behavior;
6.配置kafka
安装:见https://blog.csdn.net/qq_41466440/article/details/121327503
(1).创建topic
sh bin/kafka-topics.sh --bootstrap-server kafkahost:9092 --create --topic user_behavior --partitions 1
(2).生产消息
bin/kafka-console-producer.sh --broker-list kafkahost:9092 --topic user_behavior
{"user_id":63401,"item_id":6244,"cat_id":143,"action":"pv","province":3,"ts":1573445919}
{"user_id":9164,"item_id":2817,"cat_id":611,"action":"fav","province":28,"ts":1573420486}
{"user_id":63401,"item_id":6244,"cat_id":143,"action":"pv","province":3,"ts":1573445919}
7.经验
经验证,使用mysql+canal+kafka+ck模式并不会很适合mysql同步到ck的场景。
因:canal同步到kafka中的json数据格式其实已经不是想要同步到ck的数据格式了,它附加了一些其他属性信息
疑问:是否为配置的canal、kafka有问题,还请大佬指点。
{"data":[{"id":"645304050783825920","department_code":"cyykjcxb","project_code":"bkml","adjust_time":"2022-01","adjust_range":"earlyMonth","amount":"5655.0","note":"112211","created_user":"lcbss@inspur.com","created_time":"2022-11-16 16:47:55","updated_user":"lcbss@inspur.com","updated_time":"2022-11-16 16:47:55"}],"database":"inspur_pss","es":1668669005000,"id":4,"isDdl":false,"mysqlType":{"id":"bigint(20)","department_code":"varchar(32)","project_code":"varchar(32)","adjust_time":"varchar(10)","adjust_range":"varchar(16)","amount":"decimal(20,8)","note":"varchar(1024)","created_user":"varchar(32)","created_time":"datetime","updated_user":"varchar(32)","updated_time":"datetime"},"old":[{"note":"11221"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"department_code":12,"project_code":12,"adjust_time":12,"adjust_range":12,"amount":3,"note":12,"created_user":12,"created_time":93,"updated_user":12,"updated_time":93},"table":"profit_adjust","ts":1668669006066,"type":"UPDATE"}
基于当前情况,个人建议若要使用该架构,可以自己开发一个服务,监听kafka topic,将数据进行转换后写入ck。
版权声明:本文为qq_41466440原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。