YOLOv5算法概述
Yolov5是一种目标检测算法,采用基于Anchor的检测方式,属于单阶段目标检测方法。相比于Yolov4,Yolov5有着更快的速度和更高的精度,是目前业界领先的目标检测算法之一。
YOLOv5算法基本原理
Yolov5基于目标检测算法中的one-stage方法,其主要思路是将整张图像划分为若干个网格,每个网格预测出该网格内物体的种类和位置信息,然后根据预测框与真实框之间的IoU值进行目标框的筛选,最终输出预测框的类别和位置信息。
特点
Yolov5具有以下几个特点:
-
高效性:相比于其他目标检测算法,Yolov5在保证高精度的前提下,速度更快,尤其是在GPU环境下可以实现实时检测。
-
精度高:通过使用多尺度预测和CIoU loss等机制,Yolov5可以提高目标检测的精度。
-
易用性强:Yolov5开源且易于使用,提供了PyTorch版本和ONNX版本,可以在不同的硬件上运行。
Yolov5可以应用于各种实际场景中的目标检测任务,例如物体检测、人脸检测、交通标志检测、动物检测等等。
YOLOv5模型结构
yolov5有五个版本:yolov5s、yolov5m、yolov5l、yolov5x和yolov5nano。其中,yolov5s是最小的版本,yolov5x是最大的版本。它们的区别在于网络的深度、宽度和参数量等方面。
下面以yolov5s为模板详解yolov5。其具有较高的精度和较快的检测速度,
同时参数量更少。
YOLOv5s 模型主要由 Backbone、Neck 和Head 三部分组成,网络模型见下图。其中:
Backbone
主要负责对输入图像进行特征提取。
Neck
负责对特征图进行多尺度特征融合,并把这些特征传递给预测层。
Head
进行最终的回归预测。

Backbone骨干网络
骨干网络是指用来提取图像特征的网络
,它的主要作用是将原始的输入图像转化为多层特征图,以便后续的目标检测任务使用。在Yolov5中,使用的是CSPDarknet53或ResNet骨干网络,这两个网络都是相对轻量级的,能够在保证较高检测精度的同时,尽可能地减少计算量和内存占用。
Backbone中的主要结构有Conv模块、C3模块、SPPF模块。
Conv模块
Conv模块是卷积神经网络中常用的一种基础模块,它主要由
卷积层
、
BN层
和
激活函数
组成。下面对这些组成部分进行详细解析。

- 卷积层是卷积神经网络中最基础的层之一,用于提取输入特征中的局部空间信息。卷积操作可以看作是一个滑动窗口,窗口在输入特征上滑动,并将窗口内的特征值与卷积核进行卷积操作,从而得到输出特征。卷积层通常由多个卷积核组成,每个卷积核对应一个输出通道。卷积核的大小、步长、填充方式等超参数决定了卷积层的输出大小和感受野大小。卷积神经网络中,卷积层通常被用来构建特征提取器。
- BN层是在卷积层之后加入的一种归一化层,用于规范化神经网络中的特征值分布。它可以加速训练过程,提高模型泛化能力,减轻模型对初始化的依赖性。BN层的输入为一个batch的特征图,它将每个通道上的特征进行均值和方差的计算,并对每个通道上的特征进行标准化处理。标准化后的特征再通过一个可学习的仿射变换(拉伸和偏移)进行还原,从而得到BN层的输出。
- 激活函数是一种非线性函数,用于给神经网络引入非线性变换能力。常用的激活函数包括sigmoid、ReLU、LeakyReLU、ELU等。它们在输入值的不同范围内都有不同的输出表现,可以更好地适应不同类型的数据分布。
综上所述,Conv模块是卷积神经网络中常用的基础模块,它通过卷积操作提取局部空间信息,并通过BN层规范化特征值分布,最后通过激活函数引入非线性变换能力,从而实现对输入特征的转换和提取。
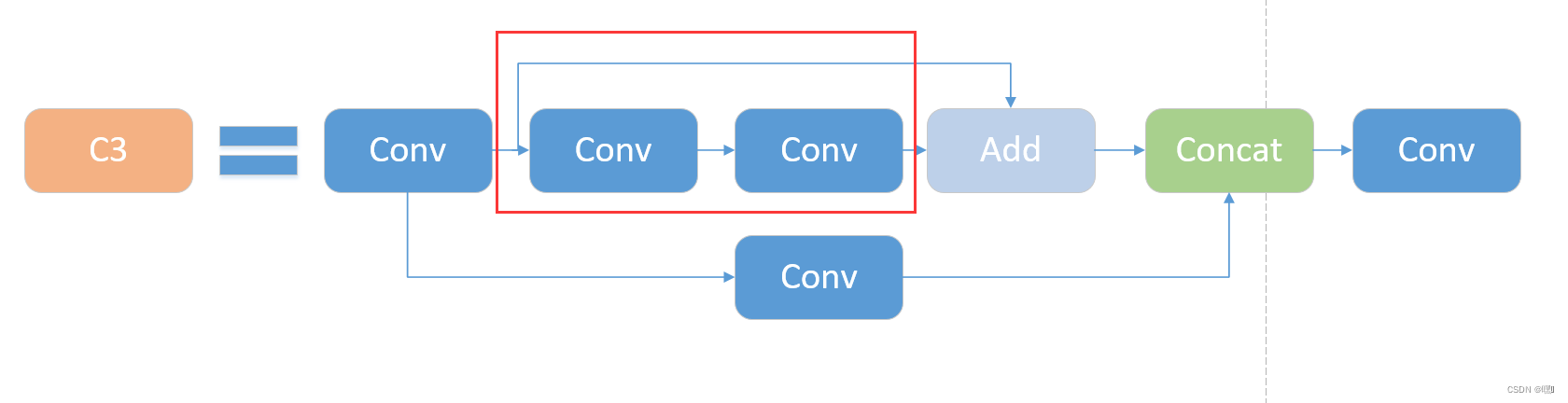
C3模块
C3模块是YOLOv5网络中的一个重要组成部分,其主要作用是增加网络的深度和感受野,提高特征提取的能力。
C3模块是由三个Conv块构成的,其中第一个Conv块的步幅为2,可以将特征图的尺寸减半,第二个Conv块和第三个Conv块的步幅为1。C3模块中的Conv块采用的都是3×3的卷积核。在每个Conv块之间,还加入了BN层和LeakyReLU激活函数,以提高模型的稳定性和泛化性能。
C3模块中的第一个Conv块的步幅为2,红色方框内两个Conv组成Bottleneck,这意味着它会将特征图的尺寸减半。这样做的目的是为了增加网络的感受野,同时减少计算量。通过将特征图的尺寸减半,可以使网络更加关注物体的全局信息,从而提高特征提取的效果。
C3模块中的第二个Conv块和第三个Conv块的步幅为1,这意味着它们不会改变特征图的尺寸。这样做的目的是为了保持特征图的空间分辨率,从而更好地保留物体的局部信息。同时,这两个Conv块的主要作用是进一步提取特征,增加网络的深度和感受野。
总的来说,C3模块通过增加网络的深度和感受野,提高了特征提取的能力。这对于目标检测等计算机视觉任务来说非常重要,因为这些任务需要对物体进行准确的识别和定位,而准确的识别和定位需要良好的特征提取能力。
SPP
SPP模块是一种池化模块,通常应用于卷积神经网络中,旨在实现输入数据的空间不变性和位置不变性,以便于提高神经网络的识别能力。其主要思想是将不同大小的感受野应用于同一张图像,从而能够捕捉到不同尺度的特征信息。在SPP模块中,首先对输入特征图进行不同大小的池化操作,以得到一组不同大小的特征图。然后将这些特征图连接在一起,并通过全连接层进行降维,最终得到固定大小的特征向量。
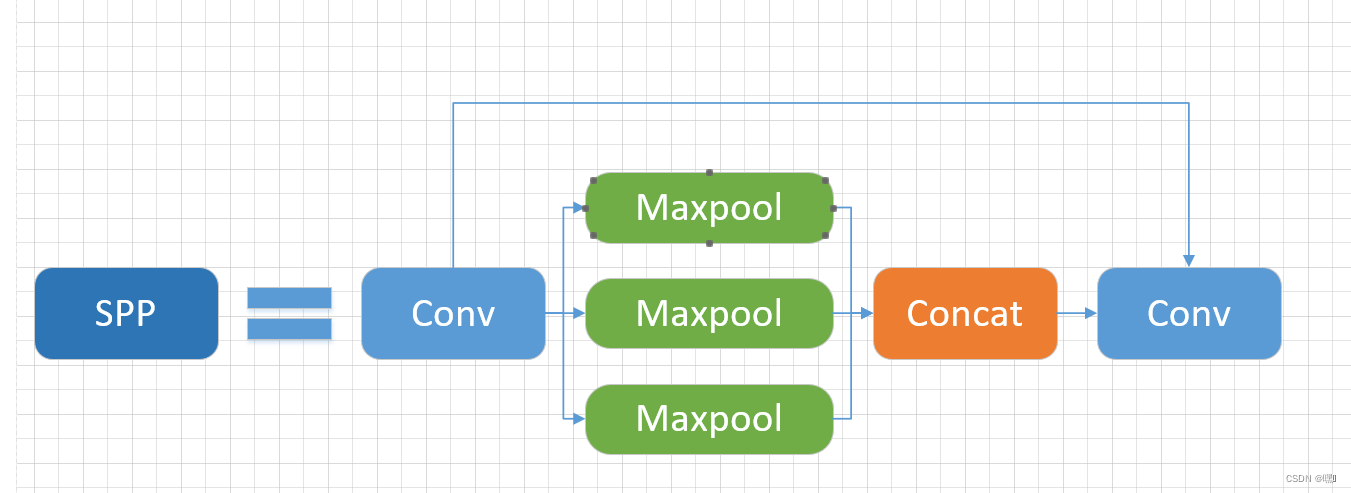
SPP模块通常由三个步骤组成:
- 池化:将输入特征图分别进行不同大小的池化操作,以获得一组不同大小的特征图。
- 连接:将不同大小的特征图连接在一起。
- 全连接:通过全连接层将连接后的特征向量降维,得到固定大小的特征向量。
Neck特征金字塔
由于物体在图像中的大小和位置是不确定的,因此需要一种机制来处理不同尺度和大小的目标。特征金字塔是一种用于处理多尺度目标检测的技术,它可以通过在骨干网络上添加不同尺度的特征层来实现。在Yolov5中,采用的是FPN(Feature Pyramid Network)特征金字塔结构,
通过上采样和下采样操作将不同层次的特征图融合在一起
,生成多尺度的特征金字塔。
自顶向下部分主要是通过上采样和与更粗粒度的特征图融合来实现不同层次特征的融合,而自下向上则是通过使用一个卷积层来融合来自不同层次的特征图。
在目标检测算法中,Neck模块通常被用于将不同层级的特征图结合起来,生成具有多尺度信息的特征图,以提高目标检测的准确率。在 YOLOv5 中,使用了一种名为 PANet 的特征融合模块作为 Neck 模块。
具体来说,自顶向下部分是通过上采样和与更粗粒度的特征图融合来实现不同层次特征的融合,主要分为以下几步:
1.对最后一层特征图进行上采样,得到更精细的特征图;
2.将上采样后的特征图与上一层特征图进行融合,得到更丰富的特征表达;
3.重复以上两个步骤,直到达到最高层。
自下向上部分主要是通过使用一个卷积层来融合来自不同层次的特征图,主要分为以下几步:
1.对最底层特征图进行卷积,得到更丰富的特征表达;
2.将卷积后的特征图与上一层特征图进行融合,得到更丰富的特征表达;
3.重复以上两个步骤,直到达到最高层。
最后,自顶向下部分和自下向上部分的特征图进行融合,得到最终的特征图,用于目标检测。
Head目标检测头
目标检测头是用来对特征金字塔进行目标检测的部分,它包括了一些卷积层、池化层和全连接层等。在 YOLOv5 模型中,检测头模块主要负责对骨干网络提取的特征图进行多尺度目标检测。该模块主要包括三个部分,此外,Yolov5还使用了一些技巧来进一步提升检测精度,比如GIoU loss、Mish激活函数和多尺度训练等。
- Anchors:用于定义不同大小和长宽比的目标框,通常使用 K-means 聚类对训练集的目标框进行聚类得到,可以在模型训练之前进行计算,存储在模型中,用于预测时生成检测框。
- Classification:用于对每个检测框进行分类,判断其是否为目标物体,通常采用全连接层加 Softmax 函数的形式对特征进行分类。
- Regression:用于对每个检测框进行回归,得到其位置和大小,通常采用全连接层的形式对特征进行回归。
YOLOv5的检测层由几个重要的组成部分构成,包括:
Anchors(锚框):
锚框是预定义的一组边界框,用于在特征图上生成候选框。
YOLOv5通过提前定义不同比例和尺寸的锚框来适应不同大小的目标。
Convolutional Layers(卷积层):
YOLOv5的检测层包含一系列卷积层,用于处理特征图和提取特征。
这些卷积层可以通过调整通道数和核大小来适应不同的检测任务。
Prediction Layers(预测层):
每个预测层负责预测一组边界框和类别。
每个预测层通常由卷积层和一个输出层组成。
输出层的通道数和形状决定了预测的边界框数量和类别数量。
Non-Maximum Suppression (NMS)(非极大值抑制):
在输出的边界框中,使用非极大值抑制算法来抑制重叠的边界框,只保留最具有代表性的边界框。
YOLOv5 的检测头模块采用了多层级特征融合的方法,首先将骨干网络输出的特征图经过一个 Conv 模块进行通道数的降维和特征图的缩放,然后再将不同层级的特征图进行融合,得到更加丰富的特征信息,从而提高检测性能。
YOLOv5总结
Yolov5是目标检测领域中的一种深度学习算法,是对Yolov4的改进版本,其在速度和精度方面都取得了很大的提升。Yolov5的整体架构由主干网络、FPN、Neck、Head等模块组成。
主干网络部分采用的是CSPDarknet53,通过使用残差结构和特征重用机制,可以有效地提高模型的特征提取能力。
FPN部分采用的是基于高斯加权的特征金字塔,可以解决多尺度目标检测的问题。Neck部分采用的是SPP和PAN结合的结构,能够在保持高效性的同时提升模型的性能。
Head部分采用的是YOLOv5头结构,可以输出网络的预测结果。
总的来说,Yolov5在各个模块上的设计都充分考虑了速度和精度的平衡,使得它在目标检测任务中表现出色。