JavaSE 集合类详解

简介
JavaSE中的集合类都实现了Iterator接口,这个接口用于集合对象的遍历,在接下来的集合工具类详解中会讲解如何遍历集合。
同样,各个集合类也都实现了Collection接口,其中定义了一些集合通用的方法,例如集合大小、遍历器、流、是否包含、移除元素、是否为空等等:
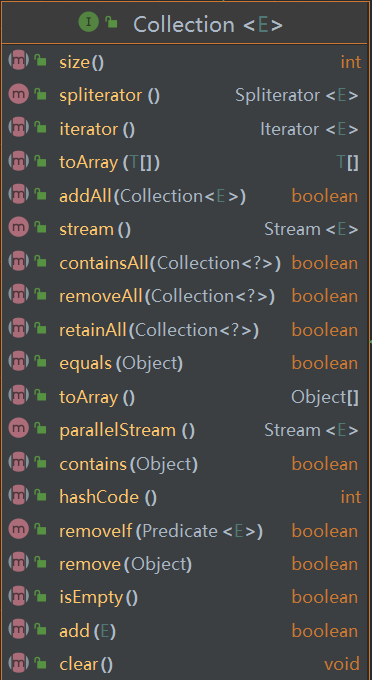
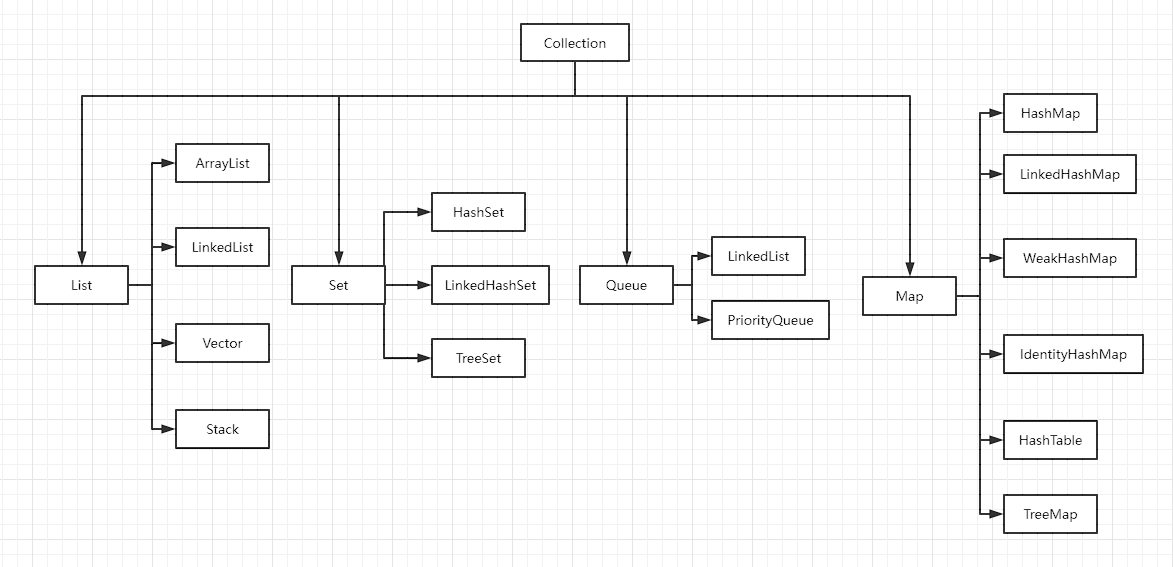
集合实现类主要可以分为四部分,即List(列表)、Set(集合)、Queue(队列)、Map(映射)。这些集合实现类除了Map外都实现了Collection接口。
List(列表)、Set(集合)、Queue(队列)、Map(映射)的常用实现类如下图所示:
集合与数组的区别
区别
- 长度区别:数组固定长度;集合通过封装表现出来长度可自适应
- 存储类型区别:数组可以存基本数据类型,也可以存引用类型(如String或自定义实体类);集合只能存引用类型,如需存储基本类型数据,需要使用对应的包装类(如Integer、Long、Charactor)。
- 类型数量:一个数组只能存定义好的一种类型的数据;一个集合可以存储不同类型的数据。
示例
import java.util.ArrayList;
import java.util.Arrays;
public class DifferenceBetweenArrayAndCollection {
public static void main(String[] args) {
//长度区别:
//数组固定长度
try {
String[] strings=new String[3];
for (int i = 0; i < 10; i++) {
strings[i]="String"+i;
}
} catch (Exception e) {
System.out.println("数组固定长度,不可以超过预定义长度");
}
//集合通过封装表现出来长度可自适应,除非内存爆满,才会存不下
try {
ArrayList<String> stringArrayList=new ArrayList<>();
int amount=100;
for(int i=0;i<amount;i++){
stringArrayList.add("String"+i);
}
System.out.println("集合存储了"+amount+"个字符串");
} catch (Exception e) {
System.out.println("只要内存够,一般不会报错");
}
//存储类型区别
// 数组可以存基本数据类型,也可以存引用类型(如String或自定义实体类)
char[] chars={'h','e','l','l','o'};
System.out.println("数组存储基本数据类型:"+ Arrays.toString(chars));
String[] strings={"aaa","bbb","ccc"};
System.out.println("数组存储引用类型:"+ Arrays.toString(strings));
// 集合只能存引用类型,如需存储基本类型数据,需要使用对应的包装类(如Integer、Long、Charactor)。
ArrayList<Double> doubleArrayList=new ArrayList<>();
doubleArrayList.add(0.1);
doubleArrayList.add(0.2);
doubleArrayList.add(0.3);
System.out.println("集合存储基本数据类型需要用包装类:"+ doubleArrayList);
// 类型数量:
// 一个数组只能存定义好的一种类型的数据
try {
//chars[0]="aaaa";
throw new Exception();
} catch (Exception e) {
System.out.println("数组只能存定义好的类型数据");
}
// 一个集合可以存储不同类型的数据。
ArrayList list=new ArrayList<>();
list.add("string");
list.add(1);
list.add(0.1);
list.add('c');
list.add(new ArrayList<>());
System.out.println("集合可以存不同类型的数据,但是一般情况用于存同类型数据:"+list);
}
}
List详解
List简介
List中常用实现类有ArrayList、LinkedList、Vector、Stack,它们的数据结构都是线性表,其中ArrayList、Vector、Stack底层是数组(顺序表),LinkedList底层是链表。
ArrayList
特点
底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
示例
import java.util.ArrayList;
public class ArrayListDemo {
public static void main(String[] args) {
ArrayList<Integer> integerArrayList=new ArrayList<>();
//添加元素
for (int i = 0; i < 20; i++) {
integerArrayList.add(i);
}
System.out.println("添加元素:"+integerArrayList);
integerArrayList.add(2,10);
System.out.println("指定位置插入元素"+integerArrayList);
//删除元素
integerArrayList.remove(1);
System.out.println("按索引1删除元素"+integerArrayList);
integerArrayList.remove(15);
System.out.println("按索引删除元素15"+integerArrayList);
integerArrayList.removeIf(integer -> {
if (integer>17)
return true;
return false;
});
System.out.println("按自定义规则删除大于17的元素"+integerArrayList);
//更新元素
integerArrayList.set(0,100);
System.out.println("按索引0更新元素100"+integerArrayList);
//查询
System.out.println("查询索引10的元素"+integerArrayList.get(10));
System.out.println("查询元素16的索引"+integerArrayList.indexOf(16));
System.out.println("查询列表的长度"+integerArrayList.size());
}
}
LinkedList
特点
底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
示例
import java.util.LinkedList;
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<Integer> integerLinkedList=new LinkedList<>();
//增
for (int i = 0; i < 10; i++) {
integerLinkedList.add(i);
}
System.out.println("普通新增"+integerLinkedList);
integerLinkedList.addFirst(-1);
System.out.println("新增到头部"+integerLinkedList);
integerLinkedList.addLast(11);
System.out.println("新增到尾部"+integerLinkedList);
integerLinkedList.push(-2);
System.out.println("push到头部"+integerLinkedList);
System.out.println("-----------------------------------");
//删
System.out.println("remove删除头部元素"+integerLinkedList.remove());
System.out.println("pollFirst删除头部元素"+integerLinkedList.pollFirst());
System.out.println("remove删除索引为6的元素"+integerLinkedList.remove(6));
System.out.println("remove删除内容为11的元素"+integerLinkedList.remove(new Integer(11)));
System.out.println("pop删除头部元素"+integerLinkedList.pop());
System.out.println("pollLast删除尾部元素"+integerLinkedList.pollLast());
System.out.println("删除操作结束后的链表"+integerLinkedList);
System.out.println("-----------------------------------");
//改
integerLinkedList.set(2,33);
System.out.println("按索引2修改元素为33"+integerLinkedList);
System.out.println("-----------------------------------");
//查
System.out.println("链表大小"+integerLinkedList.size());
System.out.println("输出链表"+integerLinkedList);
System.out.println("查询首个元素但是不删除"+integerLinkedList.peekFirst());
System.out.println("查询最后一个元素但是不删除"+integerLinkedList.peekLast());
System.out.println("查询索引为3的元素"+integerLinkedList.get(3));
}
}
Vector
特点
底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
示例
public class VectorDemo {
public static void main(String[] args) {
//Vector可以理解为ArrayList的线程安全的实现
Vector<Integer> vector=new Vector<>();
//增
for (int i = 0; i < 10; i++) {
vector.add(i);
}
System.out.println("普通新增"+vector);
vector.add(2,12);
System.out.println("插入新增"+vector);
//删
vector.remove(new Integer(12));
System.out.println("按元素删除"+vector);
vector.remove(5);
System.out.println("按索引删除"+vector);
//改
vector.set(1,11);
System.out.println("按索引修改"+vector);
vector.setElementAt(111,1);
System.out.println("按索引修改无返回值"+vector);
//查
int val=vector.get(1);
System.out.println("按索引查询"+val);
System.out.println("查询数组长度"+vector.size());
System.out.println("查询数组容量"+vector.capacity());
}
}
Stack
特点
继承自Vector,包含栈数据结构的操作,其中push和empty方法不是线程安全的,pop、peek、search方法是线程安全的。
示例
public class StackDemo {
public static void main(String[] args) {
//Stack继承Vector,是一个栈结构类
Stack<Integer> stack=new Stack<>();
//增
for (int i = 0; i < 10; i++) {
stack.push(i);
}
System.out.println("将元素压入栈"+stack);
//删
System.out.println("出栈一个元素"+stack.pop());
System.out.println("出栈另一个元素"+stack.pop());
//改
stack.set(3,33);
System.out.println("根据索引修改元素"+stack);
//查
System.out.println("获取栈顶元素"+stack.peek());
System.out.println("获取栈内元素数量"+stack.size());
System.out.println("获取站内某个索引的元素"+stack.get(3));
System.out.println("根据元素查从栈顶开始的序号"+stack.search(new Integer(2)));
}
}
Set详解
Set简介
Set中常用实现类包括HashSet、LinkedHashSet、TreeSet。它们底层都包含
HashSet中元素是无序的,底层是哈希表,无法通过索引检索其中存储的对象。
若两个元素的哈希值冲突了,那么在表中对应位置使用链表存储冲突的元素。
Set集合中不能插入相等的元素。
这里的相等是指对象的equals方法返回true,对于自己写的类,我们可以重写hashCode和equals方法,来自定义对象相等的判定条件,例如下面A类相等的条件就是两个对象id相等:
//使用id获取哈希值,在equals函数中最后以hashCode方法判定两个对象是否相等
class A{
private Integer id;
private String name;
public A(Integer id, String name) {
this.id = id;
this.name = name;
}
//如果id一样,则认为两个对象相等,否则不相等
@Override
public boolean equals(Object o) {
//若对象地址相等,返回true
if (this == o) return true;
//若对象类型不同,返回false
if (o == null || getClass() != o.getClass())
return false;
//若哈希值相等,返回true
A a = (A) o;
return this.hashCode()==o.hashCode();
}
@Override
public int hashCode() {
return Objects.hash(id);
}
@Override
public String toString() {
return "A{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
在hashCode的Object.hash方法中添加或删除参数就可以用其他成员变量生成哈希码。
HashSet
特点
底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素。
示例
import java.util.HashSet;
import java.util.Objects;
public class HashSetDemo {
public static void main(String[] args) {
HashSet<Integer> hashSet=new HashSet<>();
//增
for (int i = 0; i < 10; i++) {
hashSet.add(i);
}
System.out.println("新增"+hashSet);
//删
boolean flag=hashSet.remove(9);
System.out.println("删除元素9"+hashSet+",删除结果"+flag);
System.out.println("删除不存在的元素,删除结果"+hashSet.remove(10));
//改
if(hashSet.contains(7)){
hashSet.remove(7);
hashSet.add(77);
}
System.out.println("没有修改方法,替换元素只能先删后增"+hashSet);
//查
System.out.println("哈希表内容数量"+hashSet.size());
System.out.println("查询元素77是否存在"+hashSet.contains(77));
//根据自定义hashCode方法和equals方法,使得hashCode方法返回值相等的两个对象不能重复加入同一个hashSet
//这里的类A,如果两个对象id相等,就判定为相等
A a1=new A(1,"a1");
A a2=new A(1,"a2");
A a3=new A(2,"a3");
A a4=new A(3,"a4");
HashSet<A> aHashSet=new HashSet<>();
aHashSet.add(a1);
aHashSet.add(a2);
aHashSet.add(a3);
aHashSet.add(a4);
System.out.println("a1与a2的id相等,不能重复添加进哈希集合"+aHashSet);
}
}
//使用id获取哈希值,在equals函数中最后以hashCode方法判定两个对象是否相等
class A{
private Integer id;
private String name;
public A(Integer id, String name) {
this.id = id;
this.name = name;
}
//如果id一样,则认为两个对象相等,否则不相等
@Override
public boolean equals(Object o) {
//若对象地址相等,返回true
if (this == o) return true;
//若对象类型不同,返回false
if (o == null || getClass() != o.getClass())
return false;
//若哈希值相等,返回true
A a = (A) o;
return this.hashCode()==o.hashCode();
}
@Override
public int hashCode() {
return Objects.hash(id);
}
@Override
public String toString() {
return "A{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
LinkedHashSet
特点
底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
示例
import java.util.Iterator;
import java.util.LinkedHashSet;
public class LinkedHashSetDemo {
public static void main(String[] args) {
LinkedHashSet<Integer> linkedHashSet=new LinkedHashSet<>();
//增
for (int i = 0; i < 10; i++) {
linkedHashSet.add(i);
}
System.out.println("add新增"+linkedHashSet);
//删
linkedHashSet.remove(new Integer(1));
System.out.println("删除整数1"+linkedHashSet);
//改
if(linkedHashSet.contains(new Integer(9))){
linkedHashSet.remove(new Integer(9));
linkedHashSet.add(99);
}
System.out.println("先删除后新增达到改的目的"+linkedHashSet);
//查
Iterator<Integer> iterator=linkedHashSet.iterator();
System.out.print("使用iterator遍历");
while(iterator.hasNext()){
System.out.print(iterator.next()+" ");
}
System.out.println();
}
}
TreeSet
特点
TreeSet底层采用二叉树树结构实现,保证唯一性的方法和HashSet相同,二叉树结构保证元素有序性。
有序性的排序方式有两种:自然排序和比较器排序。
使用自然排序不需要额外配置。若使用比较器排序,需要在TreeSet对象初始化时,在构造函数中添加比较器参数以自定义排序规则,如下:
//自定义比较器,如果绝对值不同,绝对值大的排后面;绝对值相同,则值大的排后面
TreeSet<Integer> treeSet=new TreeSet<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
if(Math.abs(o1)!=Math.abs(o2))
return Math.abs(o1)-Math.abs(o2);
return o1-o2;
}
});
示例
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
//自定义比较器,如果绝对值不同,绝对值大的排后面;绝对值相同,则值大的排后面
TreeSet<Integer> treeSet=new TreeSet<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
if(Math.abs(o1)!=Math.abs(o2))
return Math.abs(o1)-Math.abs(o2);
return o1-o2;
}
});
//增
for (int i = -9; i < 10; i++) {
treeSet.add(i);
}
System.out.println("add新增元素"+treeSet);
//删
treeSet.remove(6);
System.out.println("删除6元素"+treeSet);
treeSet.pollFirst();
System.out.println("弹出排序后首个元素"+treeSet);
treeSet.pollLast();
System.out.println("弹出排序后末尾元素"+treeSet);
//改
if(treeSet.contains(new Integer(-6))){
treeSet.remove(new Integer(-6));
treeSet.add(-66);
}
System.out.println("先删除后新增达到改的目的"+treeSet);
//查
int num=treeSet.floor(10);
System.out.println("获取比参数排序靠前的第一个元素"+num);
num=treeSet.ceiling(65);
System.out.println("获取比参数排序靠后的第一个元素"+num);
}
}
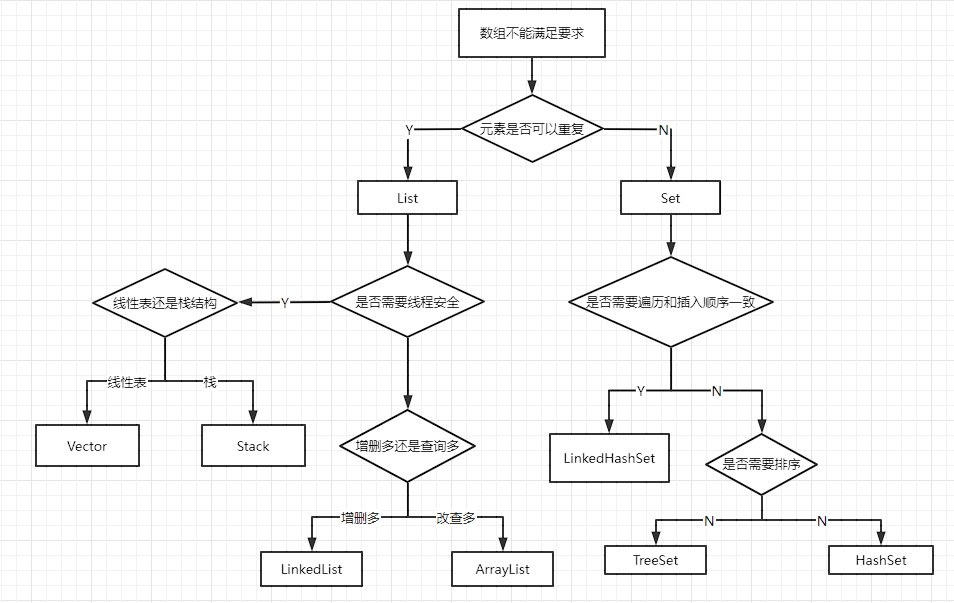
List与Set适用场景分析
根据之前列举的List和Set主要实现类,可以得到如下结论:
Map详解
Map简介
Map可以理解为映射集合,即Map的元数据是key-value(键值对),一个键对应一个值。
Map中不能同时包含key相同的两个键值对,即Map使用key来检索数据。
Map和List、Set不同,没有实现Collection接口,算是一个单独的分支:
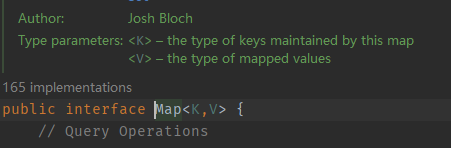
Map中常用的实现类有HashMap、HashTable和TreeMap。
HashMap
示例
import java.util.Collection;
import java.util.HashMap;
import java.util.Set;
import java.util.function.BiConsumer;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<Integer,String> hashMap=new HashMap();
//增
for (int i = 0; i < 10; i++) {
hashMap.put(i,"string"+i);
}
System.out.println(hashMap);
//删
hashMap.remove(2);
System.out.println("删除键为2的键值对"+hashMap);
hashMap.remove(3,"string3");
System.out.println("删除键为3,值为string3的键值对"+hashMap);
//改
hashMap.put(0,"string00");
hashMap.replace(1,"string11");
System.out.println("改"+hashMap);
//查
System.out.println("查询是否存在某个键"+hashMap.containsKey(4));
System.out.println("查询哈希映射大小"+hashMap.size());
Set<Integer> keySet=hashMap.keySet();
System.out.print("遍历所有键");
for (Integer integer : keySet) {
System.out.print(integer+" ");
}
System.out.println();
Collection<String> values=hashMap.values();
System.out.println("遍历所有值");
for (String value : values) {
System.out.print(value+" ");
}
System.out.println();
System.out.print("遍历所有键值对");
hashMap.forEach(new BiConsumer<Integer, String>() {
@Override
public void accept(Integer integer, String s) {
System.out.print(integer+" "+s+" ");
}
});
System.out.println();
}
}
HashTable
特点
HashTable与HashMap比较主要在于HashTable是线程安全的,而HashMap不是。
其他操作与HashMap类似。
其他区别将在本章后续小节介绍。
TreeMap
特点
TreeMap底层数据结构是红黑树,由红黑树对键进行排序。
由于内部排序,在查询元素时提供了查询首个、查询最后一个、查询某个键之前或之后一个键的方法。
示例
import java.util.Collection;
import java.util.Set;
import java.util.TreeMap;
import java.util.function.BiConsumer;
public class TreeMapDemo {
public static void main(String[] args) {
TreeMap<Integer,String> treeMap=new TreeMap();
//增
for (int i = 0; i < 10; i++) {
treeMap.put(i,"string"+i);
}
System.out.println(treeMap);
System.out.println("----------------------------------------");
//删
treeMap.remove(2);
System.out.println("删除键为2的键值对"+treeMap);
treeMap.remove(3,"string3");
System.out.println("删除键为3,值为string3的键值对"+treeMap);
System.out.println("弹出第一个键值对"+treeMap.pollFirstEntry());
System.out.println("弹出最后一个键值对"+treeMap.pollLastEntry());
System.out.println("----------------------------------------");
//改
treeMap.put(0,"string00");
treeMap.replace(1,"string11");
System.out.println("改"+treeMap);
System.out.println("----------------------------------------");
//查
System.out.println("查询是否存在某个键"+treeMap.containsKey(4));
System.out.println("查询哈希映射大小"+treeMap.size());
Set<Integer> keySet=treeMap.keySet();
System.out.print("遍历所有键");
for (Integer integer : keySet) {
System.out.print(integer+" ");
}
System.out.println();
Collection<String> values=treeMap.values();
System.out.println("遍历所有值");
for (String value : values) {
System.out.print(value+" ");
}
System.out.println();
System.out.print("遍历所有键值对");
treeMap.forEach(new BiConsumer<Integer, String>() {
@Override
public void accept(Integer integer, String s) {
System.out.print(integer+" "+s+" ");
}
});
System.out.println();
System.out.println("获取第一个键值对"+treeMap.firstEntry());
System.out.println("获取最后一个键值对"+treeMap.lastEntry());
}
}
HashMap与Hashtable的区别
- 继承父类不同:HashMap继承自AbstractMap类,Hashtable继承自Dictionary类(已废弃)。
- 线程安全:HashMap不是线程安全的,HashTable是线程安全的
- contains方法:HashMap没有contains方法,有containsValue和containsKey方法;hashtable保留了contains方法,效果同containsValue,还有containsValue和containsKey方法。
- 哈希值计算:HashMap通过将原哈希值右移16位后和原哈希值异或,得到最终哈希值,减少哈希冲突的可能性;HashTable直接使用原哈希值。
- 扩容:容量不足时,HashMap将容量翻倍,HashTable容量翻倍后加一。
- 解决冲突:HashMap中如果冲突量大于等于8,则该哈希位使用红黑树存储冲突的键值对,否则使用链表;Hashtable只使用链表。