下面将有实例引入缓冲区溢出的介绍:
void main()
{
int i=0;
int a[]={1,2,3,4,5,6,7,8,9,10};
for(i=0;i<=10;i++)
{
a[i]=0;
printf("Hello World!\n");
}
}
首先,这段代码会出现死循环,为什么?因为数组溢出了,而溢出的位置正好是变量i的位置,所以当i=10时,a[10]的位置正好是i的位置,所以i会被重新赋值为0,从而导致无线循环,这是缓冲区溢出最简单的实例演示。
要了解缓存区溢出原理,首先必须得明白程序运行时在内存中的情况。深层次的原理这里不讨论,我们只需要知道在函数调用时会发生如下步骤:
1、将被调用函数的下一条指令地址压入栈(保存被调用函数的下一条指令)
2、将当前的EPB压入栈(保持当前的基址)
3、将ESP值赋给EPB(改变基址)
4、移动ESP指针(开辟空间,以便保存函数执行时需要的数据,如保存函数内定义的变量)
……函数运行完毕后,将会执行如下操作……
5、将EPB出栈(还原调用前的基址)
6、将EIP出栈(返回到调用函数的下一条指令)
此时的内存模型如下:
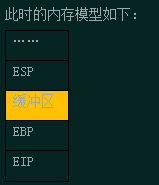
根据上面的流程及内测模型,我们可以知道,缓冲区下面就是EBP与EIP,而EIP是直接影响程序的执行流程,正常情况下它保存的是函数返回的地址,如果我们在操作缓冲区时出现异常,导致缓冲区后面的EBP与EIP被修改了,就会改变程序的执行流程,甚至引起缓冲区溢出攻击。
现在回到第一个实例:
在详细剖析程序前,我们还需要知道一个知识点,在上面的内存模型中,我们在函数内定义的变量是保存在缓冲区中,那么具体在缓冲区内部是如何分配的呢?通常情况下,都是从下往上顺序分配的,即先定义的变量在下面,后定义的变量在上面,如:

试想一下:如果数组a的范围越界了,覆盖掉了i的值那会这样?
上面给出的是内存的抽象模型,下面将给出在VS2010调试中它的内存情况 如下图:

有底色的数据区分别是:数组a(10*4个字节),变量i(一个字节),EBP(4字节),EIP(4字节)。显然如果数组寻址越界,就可能覆盖掉变量i的值,例如:这个实例运行中当i=10时,执行下面代码:
a[i]=0;
printf(“Hello World!\n”);
当执行a[10]=0后,内存情况如下图:

显然,数组a的最大范围是a[9],但这里越界了,而a[10]正好是变量i的地址,故变量i的值被覆盖了,变成了0,所以程序会不停地循环。你可试下a[12]=0看会出现什么情况,a[12]正好是保持的是EIP的地址。
通过上面的例子,我想对缓冲区溢出应该有了最基本的认识,下面在看第2例子:
代码:
#include “stdafx.h”
#include
#include
void fuzprin()
{
printf(“test”);
}
void gettest1()
{
char str[11]={‘0’};
}
void main()
{
gettest1()
}
我们的目的是要在gettest1函数中添加溢出代码,改变EIP从而使执行fuzprin函数。

通过第一个实例的,我们知道只要找到保存EIP的地址就可以直接修改,关键是找到这个地址,我们打开VS2010在调试中内存情况如下:

底色部分分别是数组str(11个字节)、EBP(4字节)、EIP(4字节),所以我们知道保存EIP的地址是str[16]开始的4个字节(0x002e161e,注意是倒放的),只要改写掉这4个字节就能改变程序的流程,算法如下:
1、找到函数fuzprin的地址假设为:ap
2、用ap的地址改写保存有EIP的地址的内容。
具体代码如下:
void gettest1()
{
char str[11]={‘0’};
int p=(int)&fuzprin;//获取函数fuzprin地址
char ap[4];//将函数fuzprin地址分为4个字节
ap[0]=p>>24&0x000000FF;//分离地址的前2位
ap[1]=p<<8>>24&0x000000FF;
ap[2]=p<<16>>24&0x000000FF;
ap[3]=p<<24>>24&0x000000FF;//分离地址的后两位
str[16]=ap[3];//用fuzprin地址后两位改写保存EIP地址的前两位
str[17]=ap[2];
str[18]=ap[1];
str[19]=ap[0];//用fuzprin地址前两位改写保存EIP地址的后两位
}
上面的代码可能有人看不太明白,这里用具体的例子讲解下:
假设保存EIP的地址0X001e1356,而此时str[16]=56,str[17]=13,str[18]=1e,str[19]=00,假设函数fuzprin的地址为:0x004514ba,我们要把这个地址分离成字节:00,45,14,ba,可以通过移位运算来实现,分离之后,就可以改写EIP的地址。这里具体的实现过程不要求能看懂,但思想一定要懂!思想就是:获取fuzprin的地址,然后改写返回EIP的地址!
添加溢出代码后,程序的运行结果如下图:
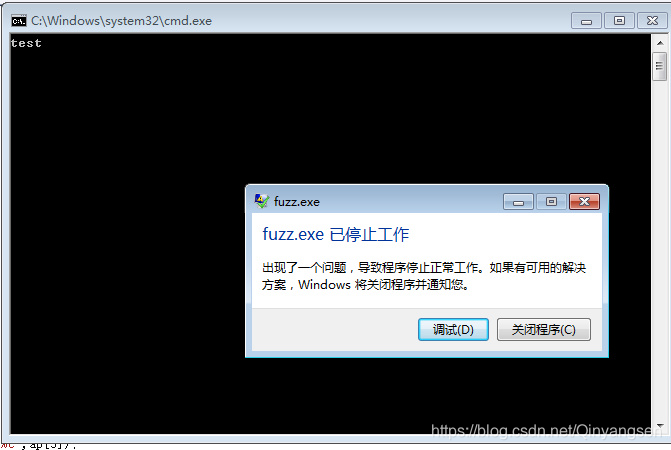
可以看到,程序已经被改写了,我们的目的达到了,但却弹出了错误框,为什么会这样?因为我们并非通过正常的函数调用跳到fuzprin函数,所以函数执行完后,没有返回地址,而是直接往下执行,fuzprin函数下面的机器指令未知,所以可能就会出现错误!你可以通过fuzprin函数后面的加上JMP指令跳回来解决,在这里我们没有必要再讨论,因为我们的目的是改写EIP了解缓冲区溢出。
再次强调:不要纠结于如何实现溢出的技巧,而是要清晰明白溢出的原理!思想很重要!
下面来看实例3:
#include “stdafx.h”
#include
#include
void fuzprin()
{
printf(“test”);
}
void gettest()
{
char str[11]={‘0’};
scanf(“%s”,str);
printf(“%s\n”,str);
}
void main()
{
gettest1();
}
我们的目的是在gettest()中添加溢出代码,使得我们可以手动输入经过构造的特殊字符以改写程序流程去执行fuzprin(),是不是更接近于实际的应用了?
首先来看下gettest函数,这里面有个scanf函数,所以我们可以手动输入字符来使得缓冲区溢出,这里的内存模型可实例2的一样,就不再画了,通过实例2的内存模型我们可以知道str(11个字节),EBP(4字节),EIP(4字节),所以str+16就是返回EIP的地址,于是我们可以这样输入:
aaaaaaaaaaaaaaaaXXXX,16个a之后接上fuzprin函数的地址就能改写掉返回EIP的地址。
上面就是我们的思路,下面是实现算法,再强调一遍:思路很重要,实现是次要的!
void gettest()
{
char str[11]={‘0’};
int p=(int)&fuzprin;
char ap[4];
ap[0]=p>>24&0x000000FF;
ap[1]=p<<8>>24&0x000000FF;
ap[2]=p<<16>>24&0x000000FF;
ap[3]=p<<24>>24&0x000000FF;//前面都一样,就是获取fuzprin地址并分离成字节
printf(“\n”);
printf(“%c”,ap[3]);
printf(“%c”,ap[2]);
printf(“%c”,ap[1]);
printf(“%c”,ap[0]);//输出函数的地址的ascall符号
printf(“\n”);
scanf(“%s”,str);//输入,构造溢出字符
printf(“%s\n”,str);
}
程序运行结果,如下图:
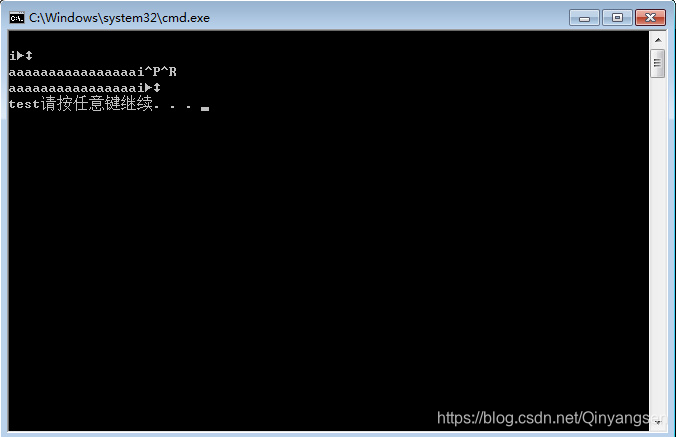
已成功改写程序流程!我们构造的输入是:aaaaaaaaaaaaaaaa在跟上fuzprin函数地址的ascall符号,这里我们之所以先输出fuzprin的ascall的符号,是为了获取fuzprin的地址,并且要以ascall符号输入才行,而这个地址的ascall符号可能是特殊符号不太好手动输入的,所以我们先打印出来,然后复制、粘贴即可得到该ascall符号。
明白实例2,我们再来看实例3,代码如下:
#include “stdafx.h”
#include
#include
void fuzprin()
{
printf(“test”);
}
void gettest2()
{
char buf[11]={‘0’};
FILE *fp;
fp = fopen(“fuz.txt”, “r”);
if(!fp) {
perror(“fopen”);
}
fread(buf, 20, 1, fp);
fclose(fp);
}
void main()
{
void *(p)=&fuzprin;//获取fuzprin地址,方便调试
gettest2();
}
同样目的是改写程序流程,使得函数fuzprin得以执行,但这里是通过构造特殊文件来实现缓存区溢出,并改写EIP的。函数 gettest2的流程是读取fuz.txt的文件,然后保存至缓冲区buf,但读取的长度是20大于buf的长度,所以会出现溢出,通过上面的实例2,我想应该对缓冲区溢出改写EIP有了足够的了解,所以这里不再详讲,直接给出思路:通过在下断点获取fuzprin的地址然后将该地址以16进制的形式写入fuz.txt文件的16、17、18、19个字节出,即可完成。过程图如下:
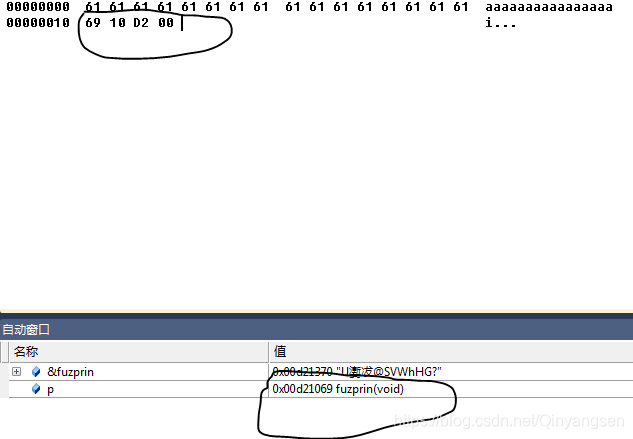
上图是调试过程中的获取函数fuzprin地址并改写文件fuz.txt的过程图,注意画圈的地方。
改写之后结果如下:
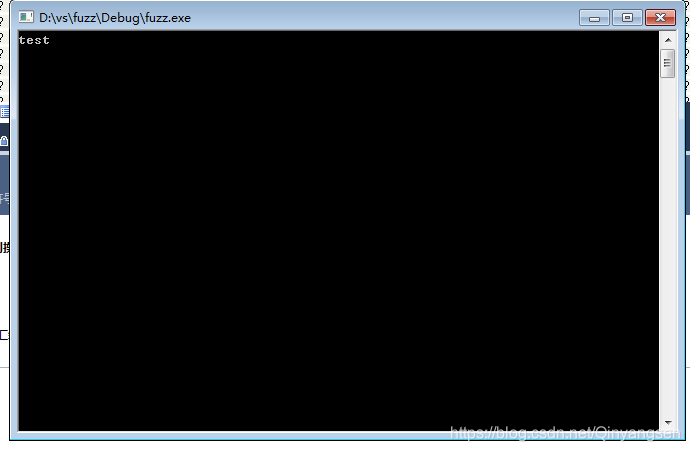
目的达到,会报错属正常情况。如果你想练习,你可以把文件指针定义在buf数组之上,即:
FILE *fp;
char buf[11]={‘0’};
进行改写试试!结合实例1的讲解,如果你真的通过本文了解缓冲区溢出,那么你很容易就能实现!如果你能实现了,说明缓冲区溢出的基本原理你已经掌握了!
完整实验代码如下:
#include “stdafx.h”
#include
#include
/by 潇阳残霜
void fuzprin()
{
printf(“test”);
}
void gettest1()
{
char str[11]={‘0’};
int p=(int)&fuzprin;
char ap[4];
ap[0]=p>>24&0x000000FF;
ap[1]=p<<8>>24&0x000000FF;
ap[2]=p<<16>>24&0x000000FF;
ap[3]=p<<24>>24&0x000000FF;
str[16]=ap[3];
str[17]=ap[2];
str[18]=ap[1];
str[19]=ap[0];
}
void gettest()
{
char str[11]={‘0’};
int p=(int)&fuzprin;
char ap[4];
ap[0]=p>>24&0x000000FF;
ap[1]=p<<8>>24&0x000000FF;
ap[2]=p<<16>>24&0x000000FF;
ap[3]=p<<24>>24&0x000000FF;
printf(“\n”);
printf(“%c”,ap[3]);
printf(“%c”,ap[2]);
printf(“%c”,ap[1]);
printf(“%c”,ap[0]);
printf(“\n”);
scanf(“%s”,str);
printf(“%s\n”,str);
}
void gettest2()
{
char buf[11]={‘0’};
FILE *fp;
fp = fopen(“fuz.txt”, “r”);
if(!fp) {
perror(“fopen”);
}
fread(buf, 20, 1, fp);
fclose(fp);
// printf(“%s”,buf);
}
void main()
{
///by 潇阳残霜
//int i=0;
//int a[]={1,2,3,4,5,6,7,8,9,10};
//for(i=0;i<=10;i++)
//{
// a[i]=0;
// printf(“Hello World!\n”);
//}
//gettest();
gettest1();
//void *§=&fuzprin;
//gettest2();
}
转载来源:http://blog.sina.com.cn/s/blog_50d705670102yrng.html
转载来源