程明明组的论文,针对问题和解决方案都比较直接,相关代码也已经开源了
论文地址:
https://arxiv.org/pdf/2003.13328.pdf
Github:
https://github.com/Andrew-Qibin/SPNet

Abstract:
事实证明,空间池化在捕获用于场景解析等像素级预测任务的远程上下文信息方面非常有效。在本文中,除了通常具有N x N规则形状的常规空间池化之外,我们通过引入一种称为
strip pooling
的新池化策略来重新考虑空间池化的公式,该策略考虑了一个长而窄的核,即1 x N或N x1。基于strip pooling,我们进一步研究空间池化体系结构的设计,方法是:
1)引入一个新的strip pooling模块,该模块使骨干网络能够有效地对远程依赖性进行建模;
2)提出一种具有多种空间池化的新颖构建块
3)系统地比较t提出的strip pooling和常规空间池化技术的性能。
两种新颖的基于池的设计都是轻量级的,并且可以在现有场景解析网络中用作有效的即插即用模块。在流行的基准(例如ADE20K和Cityscapes)上进行的广泛实验表明,我们的简单方法取得了最好的结果。
Introduction:

对于语义分割任务来说,
感受野大小及全局上下文信息对于最终的预测结果非常重要
。空间池化(如全局平均池化)通常用于对特征尺度进行降采样的同时,提取全局上下文信息。
然而,如上图所示,规则的N X N
空间池化对于长而窄的目标,往往会丢失部分信息。同时在处理具有不规则形状的目标时,它可能不可避免地包含许多不相关的区域
。
因此,本文针对这个问题:
1.首先设计一个strip pooling模块(SPM),以有效地扩大骨干网络的感受野范围。 更具体地说,SPM由两个途径组成,它们专注于沿水平或垂直空间维度对远程上下文进行编码。对于池化特征图中的每个空间位置,它会对其全局的水平和垂直信息进行编码,然后使用这些编码来平衡其自身的权重以进行特征优化。
2.此外,提出了一种新颖的附加残差构建模块,称为混合池模块(MPM),以进一步在高语义级别上对远程依赖性进行建模。 它通过利用具有不同内核形状的池操作来收集内容丰富的上下文信息,以探查具有复杂场景的图像。
3.利用改进的ResNet+上述两个设计,提出SPNet网络,在相关评测数据集上取得了SOTA的效果。
Methodology:
1.Strip Pooling Module
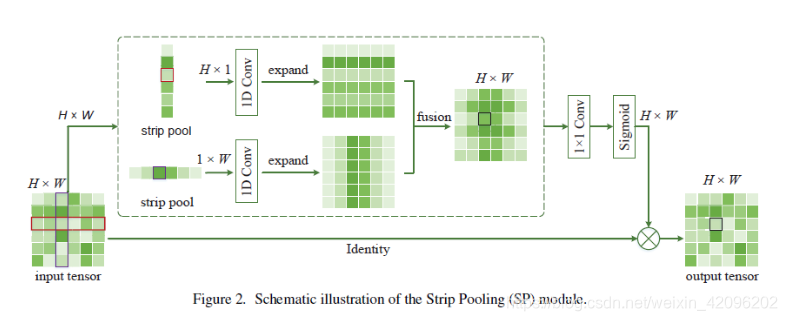
如上图所示,具体实现方式:
1.对输入H X W的特征,分别使用strip pooling(只在H或者W的维度上pooling)的方式得到 H X 1与 1 X W的特征
2.分别对1中的特征使用卷积得到扩张后的两个H X W大小特征
3.对2中特征进行相加融合,使用卷积+Sigmoid函数得到H X W大小的编码权重
4.与输入特征进行权重融合
2.Mixed Pooling Module
考虑到标准空间池和本文提出的Strip Pooling的优点,我们改进了PPM并设计了一个混合池化模块(
MPM
),该模块致力于通过各种池操作汇总不同类型的上下文信息,以使特征表示更具区分性。

MPM具体由两个子分支组成,具体来说:
1.如上图(a),为原始的PPM模块,可以用于捕获特征位置的短距离依赖关系。
2.如上图(b),使用strip pooling的方式,可以捕获更长距离特征之间的依赖关系。
这两种依赖关系对于网络的预测来说都至关重要。因此,
MPM分别使用这两个分支生成对应的特征图,然后将两个子模块的输出拼接并用1×1卷积得到最终的输出特征
。
代码:
#即对应文中的MPM模块
class StripPooling(nn.Module):
"""
Reference:
"""
def __init__(self, in_channels, pool_size, norm_layer, up_kwargs):
super(StripPooling, self).__init__()
#空间池化
self.pool1 = nn.AdaptiveAvgPool2d(pool_size[0])
self.pool2 = nn.AdaptiveAvgPool2d(pool_size[1])
#strip pooling
self.pool3 = nn.AdaptiveAvgPool2d((1, None))
self.pool4 = nn.AdaptiveAvgPool2d((None, 1))
inter_channels = int(in_channels/4)
self.conv1_1 = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 1, bias=False),
norm_layer(inter_channels),
nn.ReLU(True))
self.conv1_2 = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 1, bias=False),
norm_layer(inter_channels),
nn.ReLU(True))
self.conv2_0 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels))
self.conv2_1 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels))
self.conv2_2 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels))
self.conv2_3 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, (1, 3), 1, (0, 1), bias=False),
norm_layer(inter_channels))
self.conv2_4 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, (3, 1), 1, (1, 0), bias=False),
norm_layer(inter_channels))
self.conv2_5 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels),
nn.ReLU(True))
self.conv2_6 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, 1, 1, bias=False),
norm_layer(inter_channels),
nn.ReLU(True))
self.conv3 = nn.Sequential(nn.Conv2d(inter_channels*2, in_channels, 1, bias=False),
norm_layer(in_channels))
# bilinear interpolate options
self._up_kwargs = up_kwargs
def forward(self, x):
_, _, h, w = x.size()
x1 = self.conv1_1(x)
x2 = self.conv1_2(x)
x2_1 = self.conv2_0(x1)
x2_2 = F.interpolate(self.conv2_1(self.pool1(x1)), (h, w), **self._up_kwargs)
x2_3 = F.interpolate(self.conv2_2(self.pool2(x1)), (h, w), **self._up_kwargs)
x2_4 = F.interpolate(self.conv2_3(self.pool3(x2)), (h, w), **self._up_kwargs)
x2_5 = F.interpolate(self.conv2_4(self.pool4(x2)), (h, w), **self._up_kwargs)
#PPM分支的输出结果
x1 = self.conv2_5(F.relu_(x2_1 + x2_2 + x2_3))
#strip pooling的输出结果
x2 = self.conv2_6(F.relu_(x2_5 + x2_4))
#拼接+1x1卷积
out = self.conv3(torch.cat([x1, x2], dim=1))
return F.relu_(x + out)
3. SPNet
以原始的ResNet网络为基础,进行了如下修改
:
1.使用空洞卷积策略修改了ResNet网络作为骨干网络,并将最终特征图的大小设置为输入图像的1/8
2.在骨干网络每个阶段中最后一个构建块的3 x 3卷积层和最后一个阶段中的所有构建块之后,添加SPM。 SPM中的所有卷积层共享与输入张量相同数量的通道
3.在骨干网络后加入MPM。由于骨干网的输出具有2048个通道,们首先将1×1卷积层连接到骨干网网络,以将输出通道从2048减少到1024,然后添加两个MPM。 在末尾添加卷积层以预测分割图
Experiments:
1.Ablation Studies:
1)MPM效果

2)SPM效果
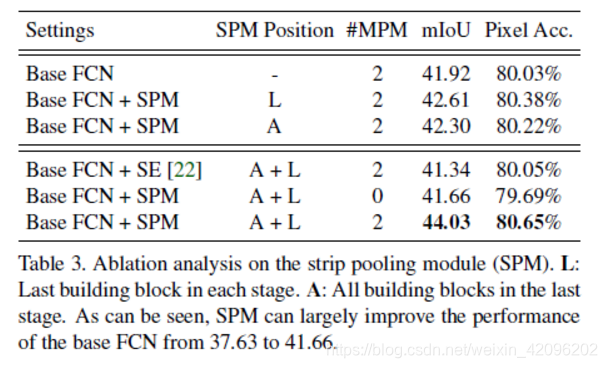
2.ADE20K:

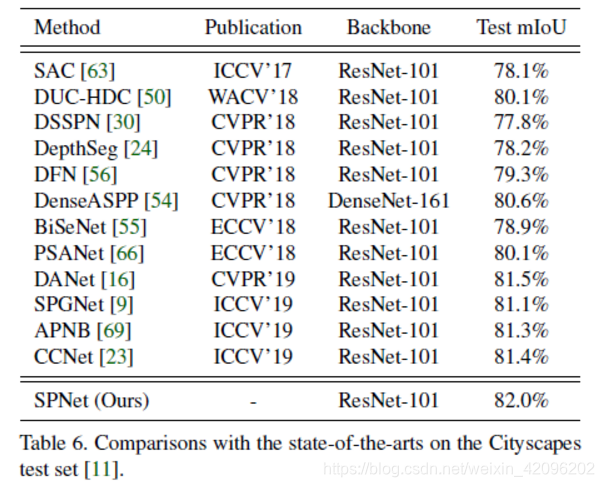
3.Cityspace:
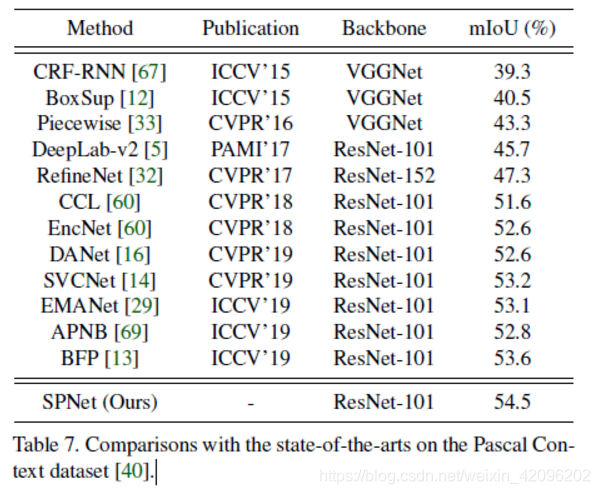
4.Pascal Context:
5.效果展示:
