Window的作用:
Window是无限流上的一种核心机制,可以将流按照用户指定的策略分隔为一个个有限大小的窗口,然后对窗口中的数据进行聚合或者一些复杂计算的操作,例如统计最近5分钟某网站的点击数。
在流式计算领域,Window概念具有通用性,并非是Flink特有的机制。
Window中的一些概念:
先再来回顾下Flink中的几种时间概念:
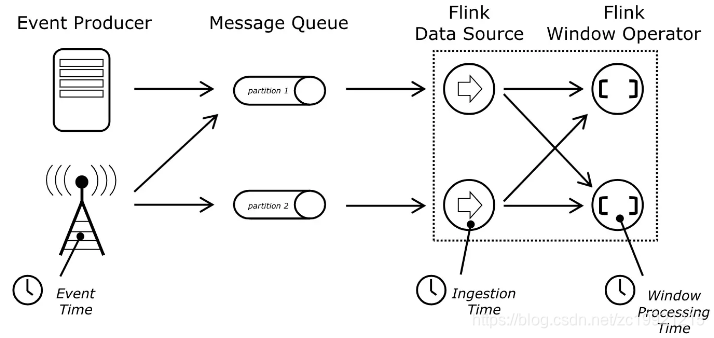
Event Time:
事件时间指的是数据真实发生的时间,这个时间在进入Flink之前已经记录到了数据中(相当于数据中要有一个字段表示这个时间),然后Flink可以提取该时间(用户写代码指定如何获取到这个时间)。
基于Event Time的程序在处理数据时候能够做到
在一定时间内按照真实时间发生的先后顺序性对数据进行处理
(
需要配合WaterMark一起使用)
。
Process Time:
处理时间指的是Flink处理该条记录的时间,即处理这条数据时每台机器的系统时间。由于它不需要协调流和机器之间的时间,所以它能提供最好的性能和最低的延迟,但是不能提供对数据处理的顺序性保证。
Ingest Time:
注入时间指的是时间注入到Flink的时间。时间在Source算子处获取Source的当前时间作为时间注入时间,后续的基于时间的处理算子会使用改时间处理数据。它也是不能处理无序或者是延迟的事件,但是它会自动生成WaterMark和时间戳分配。
选择不同的时间,划分的Window是不一样的
,绝大多数业务使用的都是Event Time,较少使用Process Time,并且Flink没有基于Ingest Time的Window。
窗口的区间都是前闭后开的,Window默认的时区是UTC-0,也就是说
第一个Window开始时间的时间戳是0
,即1970-01-01 00:00:00。如果数据使用的是本地时区,并且时间戳也是本地时区的时间戳,那么可以设定偏移量对Window的开始时间调整。例如北京设置,我们设置偏移量+8小时,那么第一个Window的开始时间就是1970-01-01 08:00:00。
Keyed Stream VS Non-Keyed Stream:
Flink根据上游数据是否为Keyed Stream类型(是否将数据按照某个指定的Key进行分区),将Window划分为Keyed Window和Non-Keyed Windows。两者的区别在于
KeyStream
调用相应的window()方法来指定window类型,数据会
根据Key在不同的Task中并行计算
,而
Non-Keyed Stream
需要调用WindowsAll()方法来指定window类型,所有的数据都会在窗口的算子中
路由到一个Task中进行计算
,相当于没有并行
。
一般我们都是对KeyStream进行Window操作,例如针对用户的购物数据,指定用户所在的省份作为Key,然后对分别统计每个省份的消费总金额,诸如这样的业务。所以本文也只详细介绍KeyStream相关的Window操作,Non-Keyed Stream先做个概念上的了解,后面用到再说。
Keyed Windows API
使用方式:
stream.keyBy(…) <- keyed类型的数据流
.window(…) <- 指定window类型,即下文的Window Assigner
[.trigger(…)] <- optional: 指定触发器类型
[.evictor(…)] <- optional: 用于数据剔除
[.allowedLateness(…)] <- optional: 是否允许迟到的数据
[.sideOutputLateData(…)] <- optional: 给数据打上标签”output tag”,可以通过getSideOutput将窗口中的打上某些标签的数据输出
.reduce/aggregate/fold/apply() <- required: 窗口函数,定义窗口中的数据的处理逻辑
[.getSideOutput(…)] <- optional: “output tag”,将打标签的数据复制到另一条流中
(带[]表示可选,其他的表示必填)
Flink中Window种类(Window Assigners):
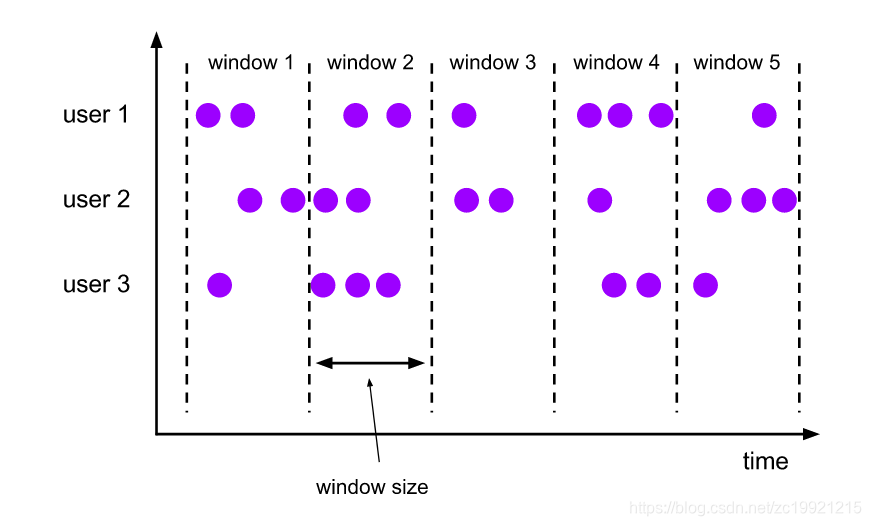
1. 固定窗口(Tumbling Windows)
根据
固定时间(Window Size)
切分窗口,窗口与窗口之间
元素互不重叠
,即一条数据只会属于一个窗口:
使用示例如下:
DataStream<T> input = …;
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
2. 滑动窗口(Sliding Windows)
和固定窗口类似,它的特点固定窗口(Window Size)基础之上增加了窗口的滑动时间(Slide Size),且允许窗口数据发生重叠,因此一条记录可以属于多个窗口。
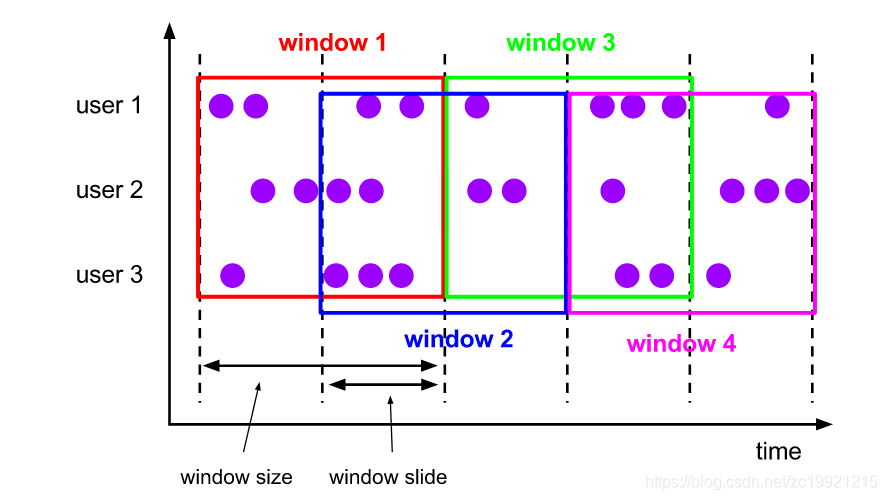
Slide Size和 Window Size相等的话,那么它其实就是固定窗口。如果Slide Size小于Window Size,那么便会出现数据重叠。如果Slide Size大于Window Size,那么便会出现窗口不连续,即会丢数据。
这个窗口的用法可以举个例子,每个30s统计最近10min内活跃用户的数目。
3. 会话窗口(Session Windows)
Session Window的目的主要是将某段时间内活跃度高的数据聚合形成一个窗口进行计算。窗口的触发条件是SessionGap,意思是如果在SessionGap时间内没有活跃的数据到来,那么就会触发窗口的计算。和固定窗口一样,Session Window窗口与窗口之间
元素是互不重叠的。
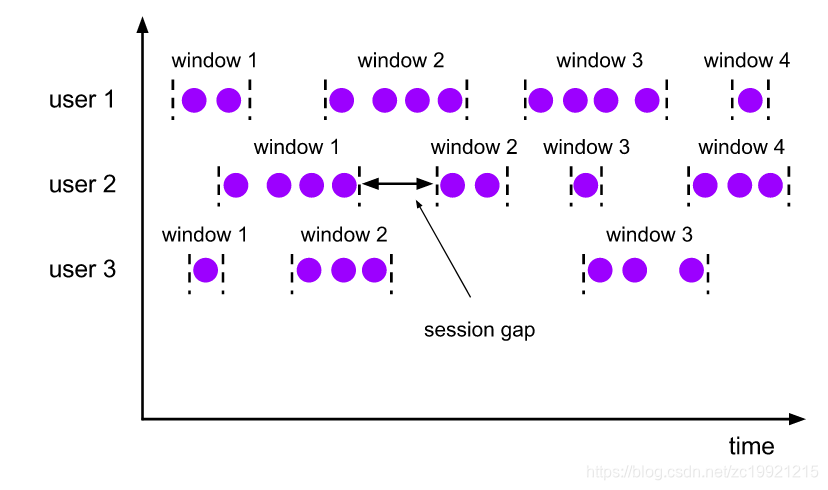
Session Window适合那种非连续类型的数据,例如一些周期性产生数据的场景。它的Session Gap也支持动态调整,后续有时间再看看…
4. 全局窗口(Global Windows)
全局窗口会将所有相同的Key分配到单个窗口中计算结果,全局窗口
没有起始和结束时间
,需要使用者
自行指定Trigger以及数据清理机制
。
不过Flink自身封装了一些Global Window的实现,例如CountWindow,用于指定当数据条数达到指定数量时触发Window计算。
窗口的内部计算流程(window & Trigger & Process):
了解Window的计算流程就是回答如下三个问题:
- Window何时被创建
- Window何时被触发
- Window何时被销毁
这些内容都在WindowOperator类中的processElement()方法中,下文以TumblingEventTimeWindows为例来详细研究下这个类:
每条数据过来都会创建属于它窗口周期的TimeWindow:
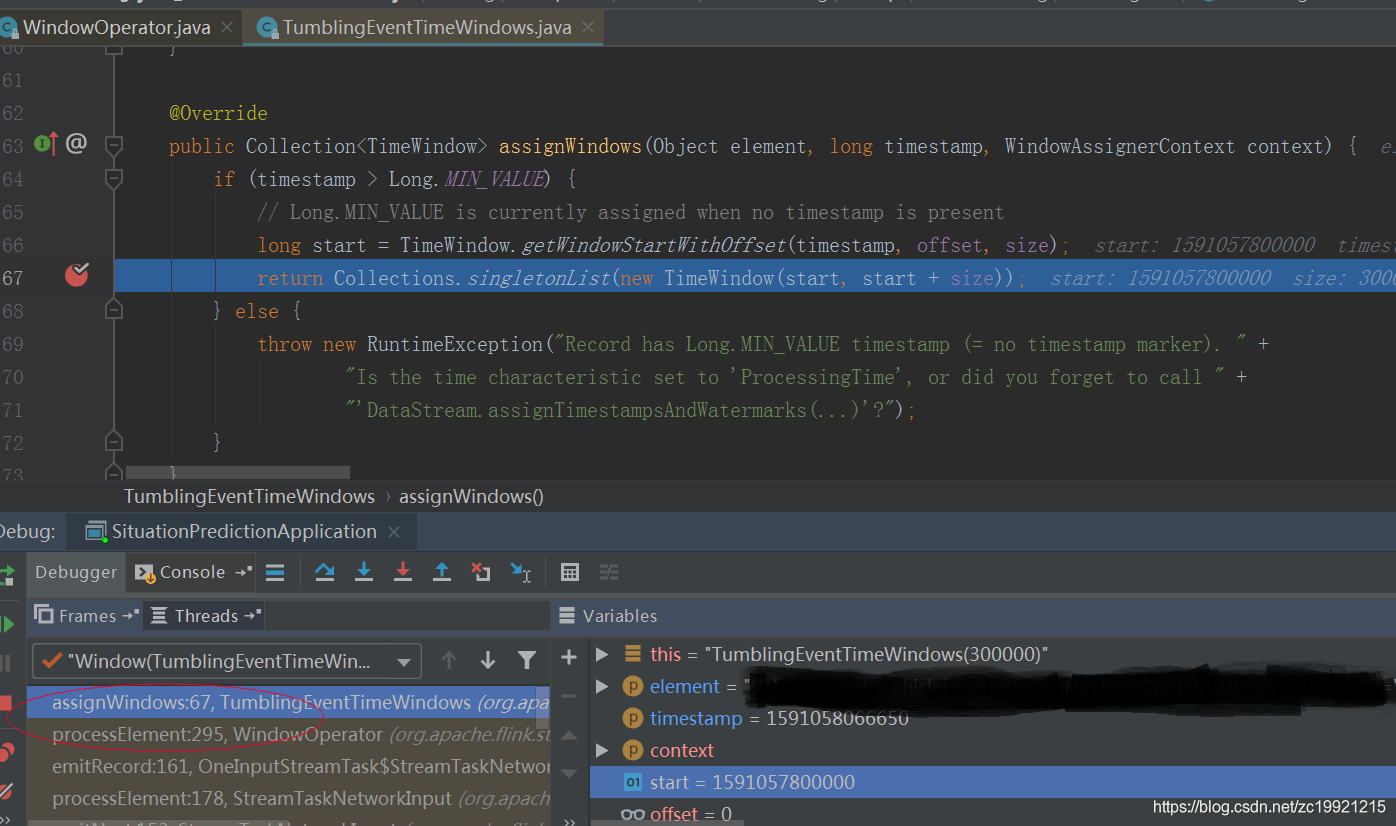
TimeWindow可以理解为是一个标识,WindowState是一个Map对象,Key为TimeWindow,Value为数据集合。也就是说相同时间范围内的数据会追加到Map中的Value中:
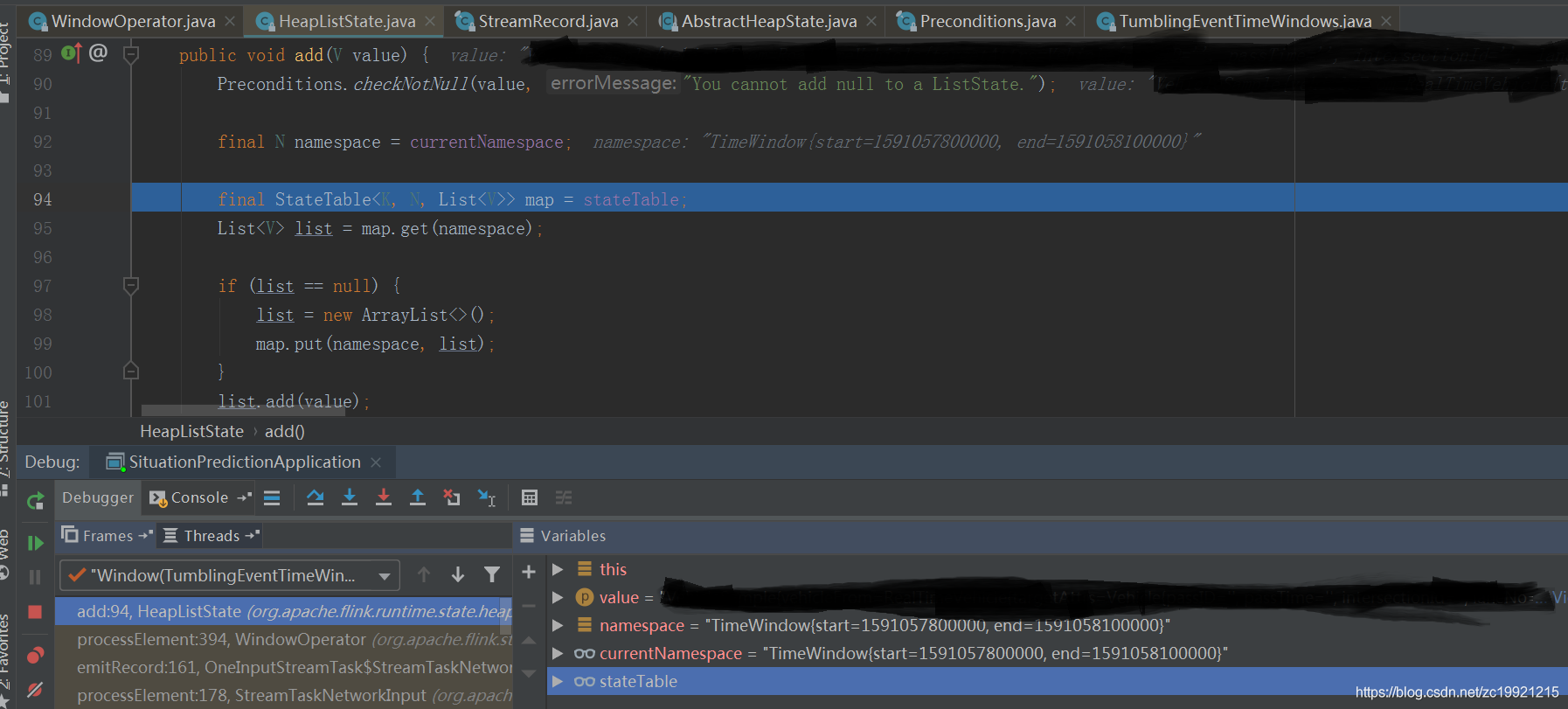
然后Trigger使用当前数据来判断是不是需要触发窗口的计算:
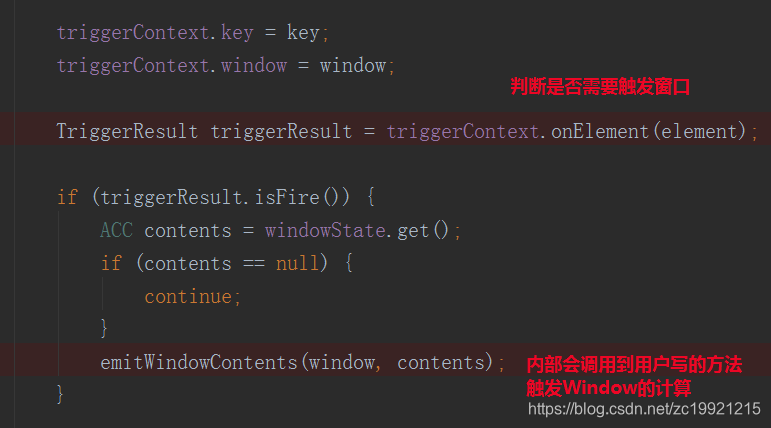
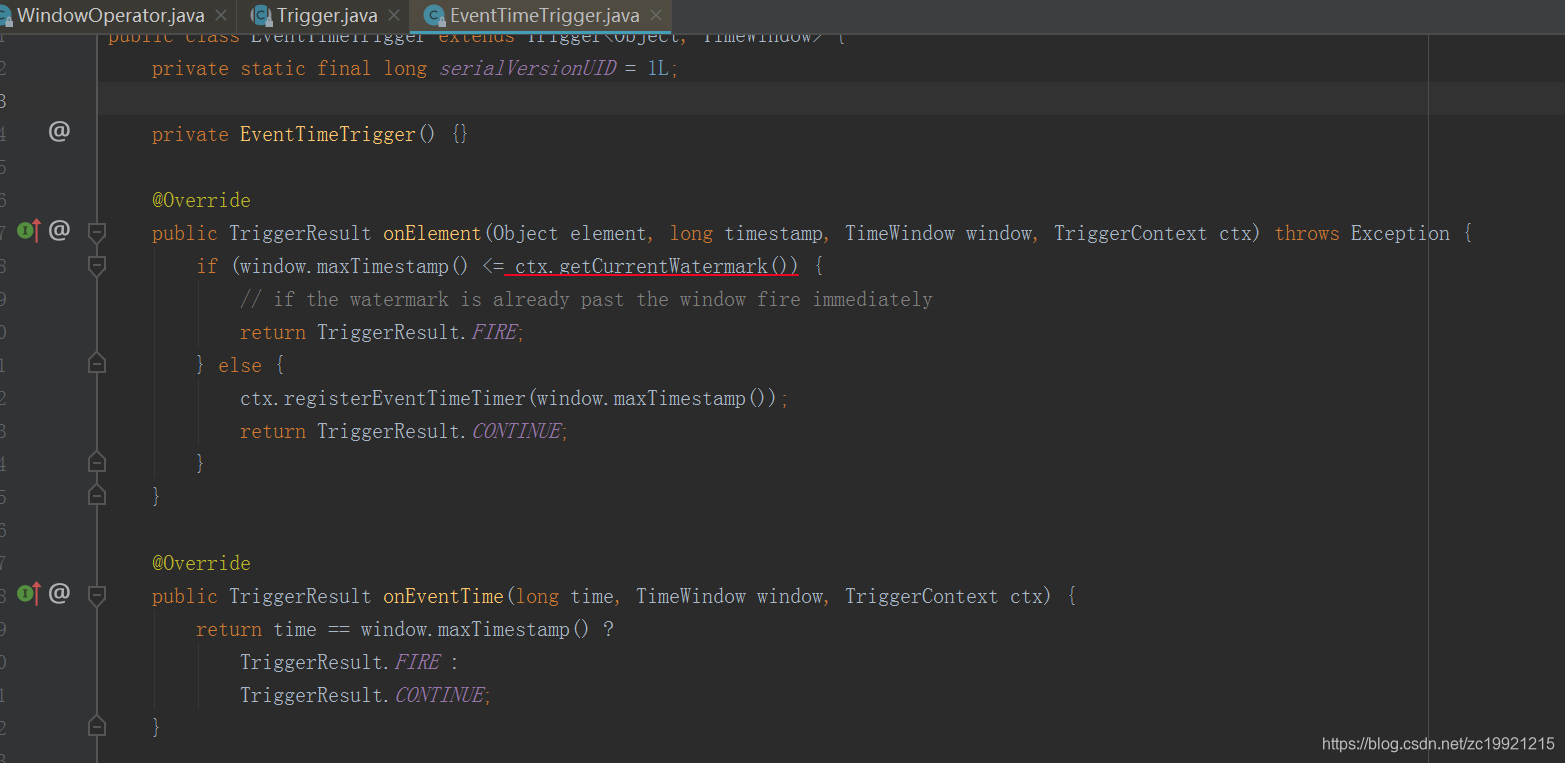
Trigger会判断当前的WaterMark是否超过了Window的EndTime,如果超过了则触发当前Window的计算。如果当前Window未到触发计算的时间的话,那么就会执行ctx.regiserEventTimeTimer(window.maxTimestamp())方法,将Window的触发时间注册成一个定时器,当水印时间达到窗口触发时间的时候,将窗口触发:
无论Window是否触发,都要判断下当前的Window是不是需要销毁。如果Trigger检测到Window需要被Purge,那么就会直接清空WindowState。然后会注册一个定时任务,清理Window信息(Purge是PurgingTrigger特有的状态,对应全局Window)。
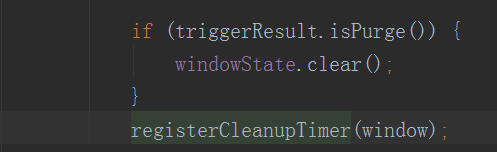
Window的销毁会注册一个定时任务,在WaterMark达到windwEndTimestamp + allowedLateness的时候,将window销毁掉,此时我allowedLateness设置的是30s,可以看出来Window的结尾确实是个开区间:
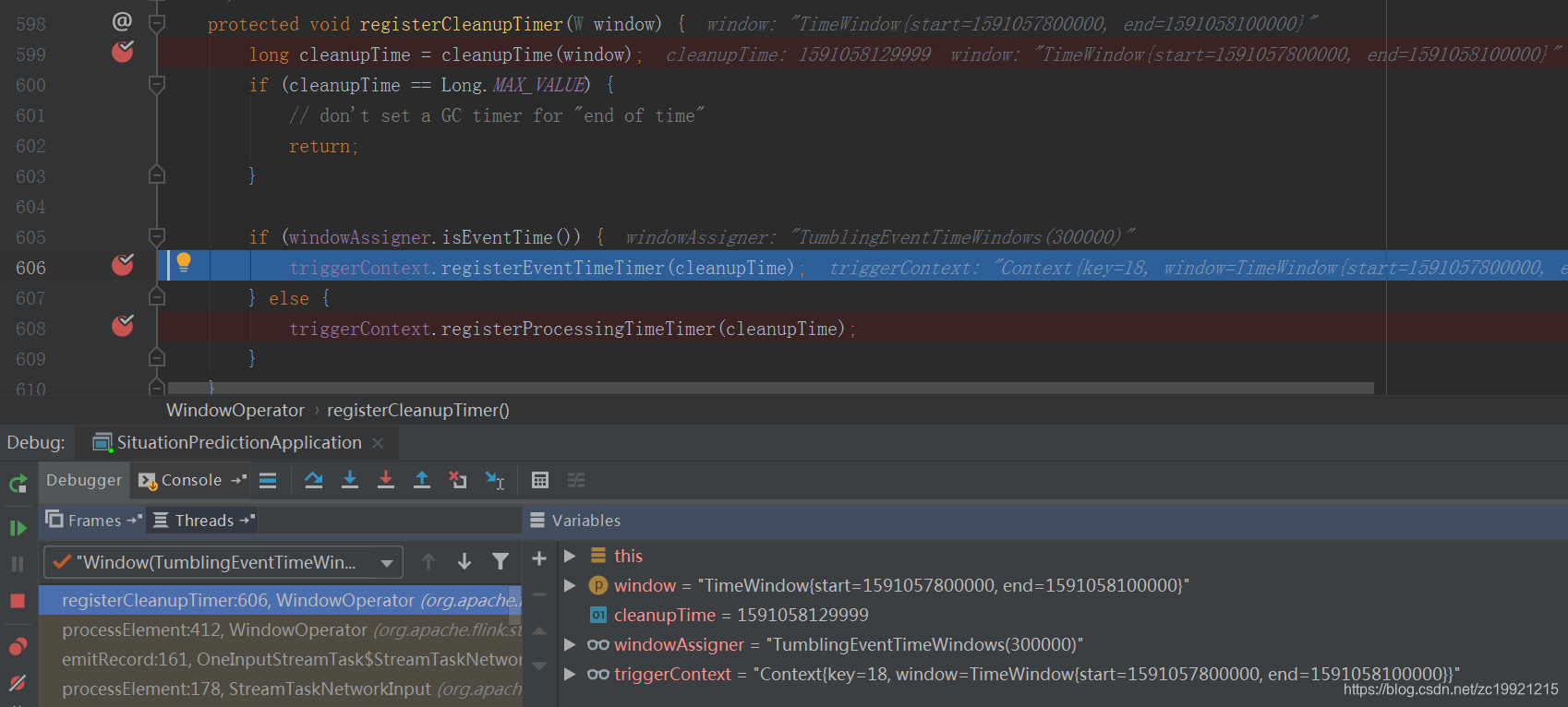
PS:看了源码突然想到了一个问题,假设Flink Job有A、B两个Task,窗口的时间的0-5,A中数据的时间戳为4,B中数据的时间戳为6,那么此时全局的WaterMark为4,A和B上的Window都不会被触发。这个时候A中来了一条数据的时间戳为6,那么A中的Window就会被触发了,那么如果此时B一直不来数据,那么B上的Window是不是就不能被触发了?!因为Task和Task之间是没有通信交互的,B不知道A上的Window已经触发了。
侧输出(sideOutput-也可以叫分流器):
大部分的 DataStream API 的算子的输出是单一输出,也就是输出某种数据类型的流。但是假设现在有这么一种使用场景,有一篇文章,单词长度不一,但是我们想对单词长度小于5的单词进行wordcount操作,同时又想记录下来哪些单词的长度大于了5,那么我们该如何做呢?首先能想到的做法是:
datastream.filter(word.length>=5); //获取单词长度大于等于5。
datastream.filter(word.length <5); //获取需要进行wordcount的单词。
虽然使用filter算子也能实现这样的需求,但是这样会造成数据流被复制多份,显然很浪费性能,假如能够
在一个流了多次输出就好了
,flink的侧输出提供了这个功能,
侧输出的输出(sideoutput)类型可以与主流不同,并且可以有多个侧输出(sideoutput),每个侧输出不同的类型
。
Side Output简单来说就是在你程序执行过程中,你需要将从主流stream中获取额外的流的方式,也就是在处理一个数据流的时候,将
这个流中的不同的业务类型或者不同条件的数据分别输出到不同的地方
。
侧输出使用示例如下:
// this needs to be an anonymous inner class, so that we can analyze the type OutputTag<String> outputTag = new OutputTag<String>("side-output"){}; // 侧输出 DataStream<Integer> input = ...; final OutputTag<String> outputTag = new OutputTag<String>("side-output"){}; SingleOutputStreamOperator<Integer> mainDataStream = input .process(new ProcessFunction<Integer, Integer>() { @Override public void processElement( Integer value, Context ctx, Collector<Integer> out) throws Exception { // emit data to regular output out.collect(value); // emit data to side output ctx.output(outputTag, "sideout-" + String.valueOf(value)); } }); // 获取侧输出 SingleOutputStreamOperator<Integer> mainDataStream = ...; DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);
不是所有的方法都能使用侧输出,官方说明,产生的sideoutput的方法主要包含以下:
CoProcessFunction
KeyedCoProcessFunction
ProcessAllWindowFunction
从源码中可以看出侧输出流是一个单独的Task,不会进行chaining操作:

允许数据延迟(allowedLateness & sideOutputLateData):
在
使用EventTime
的时候,由于设备的时间不同步或者是网络延迟问题,不同设备同一时刻产生的数据到达系统中的时间有先有后。一般采用的方式是让WaterMark的时间滞后于事件时间。比如事件时间为3点,你可以设置watermark为2点50,可以滞后10分钟。
但是,如果超过了WaterMark的延迟时间,仍有数据到达怎么办?这个时候Window已经被销毁了,这些数据是会被丢弃的,但是业务方一定要求对这些非常滞后达到的数据也要进行处理。
其实Flink针对
Window
关闭之后的迟到数据的处理方式有三种
:
- 默认情况下allowedLateness的值为0,数据会被丢弃
- 设置了allowedLateness,那么Window的关闭时间会延迟,Flink内部会重新计算Window以修正结果
-
sideOutputLateData是最后兜底的操作,在
窗口彻底关闭后
,将迟到的数据侧输出,让用户决定如何处理
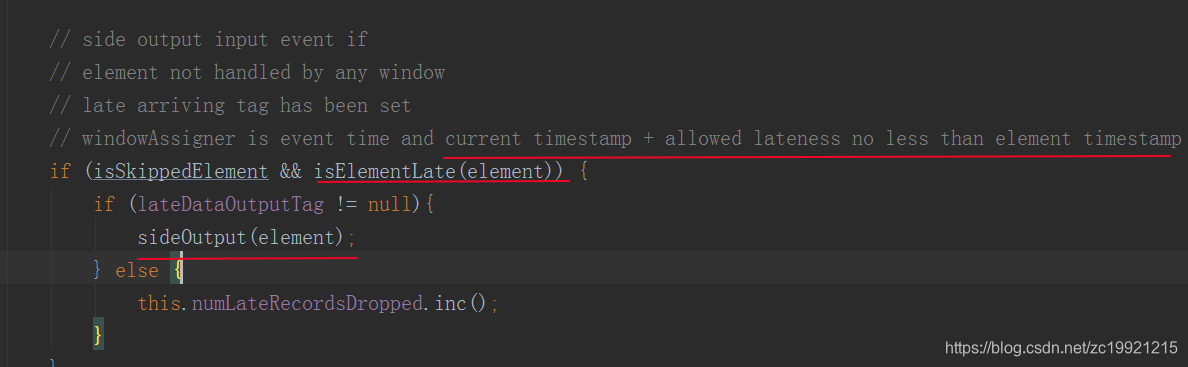
对于trigger是默认的EventTimeTrigger的情况下,allowedLateness会再次触发窗口的计算,而Window会直到WaterMark超过end-of-window + allowedLateness的时间,窗口的数据及元数据信息才会被删除。
设置了allowedLateness之后,是来一条数据就修正一次么,还是说,是等到lateness之后,一起触发?测试结果是来一条数据就修正一次,allowedLateness只针对一个特定的window operator。
PS1:也就是说如果数据迟到太久,超过了Allowed Lateness的时间,那么是无法触发Window计算了,Flink无法解决这个问题。
PS2:这么说来,我们可以通过WaterMark、Allowed Lateness、sideOutputLateData三重机制来处理EventTime乱序的数据。
数据剔除器(Evictor):
Evictor的作用是对进入Window Function之前或者之后的数据进行剔除,默认是在进入WindowFunction之前剔除。
Flink内部实现了三种Evictor:
CountEvictor: 用于保持window中固定数量的记录,剔除数据的逻辑比较随意。
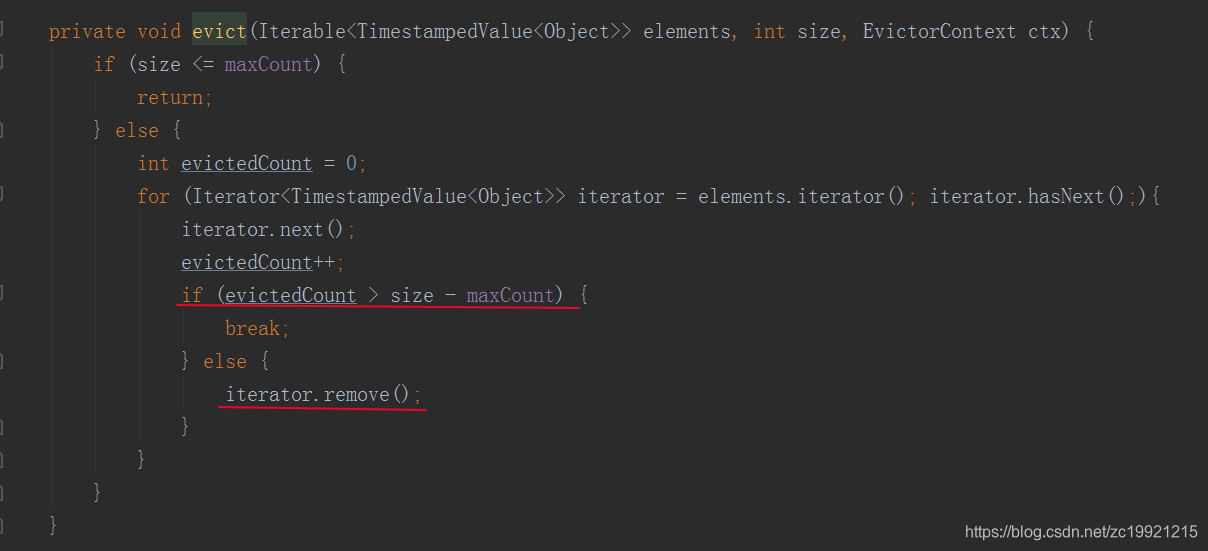
DeltaEvictor: 定义了一个DelataFunction以及一个threshold,比较window中元素和最新元素之间的delta大小,超过了则删除window中的元素
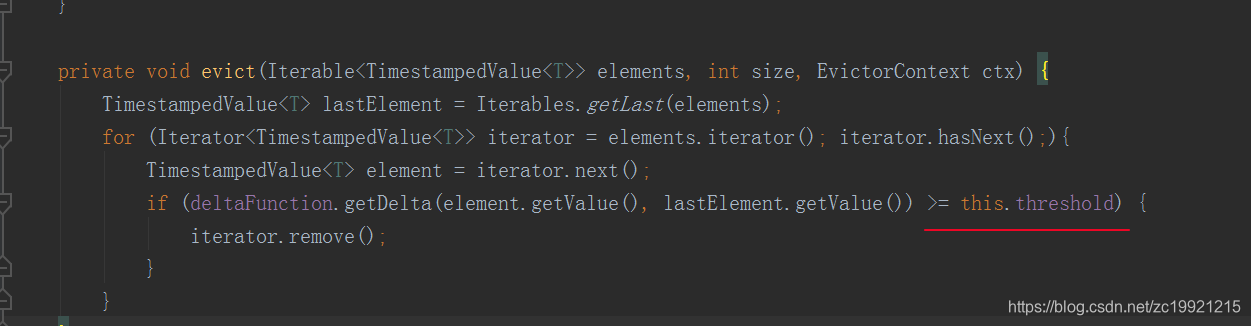
TimeEvictor: 指定一个时间,将window中最大元素的时间减去这个size,然后将低于这个减掉后的时间的旧元素全部剔除掉
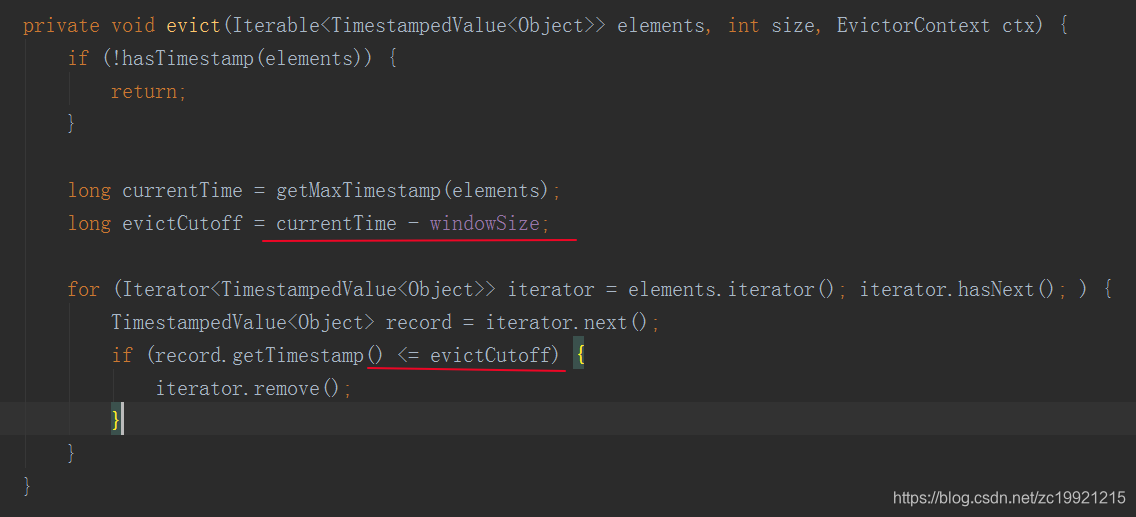
当然Evictor也支持自定义
参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html#window-lifecycle (Flink
Window 官方文档介绍)
https://www.cnblogs.com/163yun/p/9882093.html(Flink
Window机制介绍)
https://www.vldb.org/pvldb/vol8/p1792-Akidau.pdf (Google
DataFlow论文)
https://yq.aliyun.com/articles/64911
(阿里云翻译的论文)
https://blog.csdn.net/CODEROOKIE_RUN/article/details/106062414(Flink
如何处理迟到的数据)
https://www.jianshu.com/p/a9617a02fd23(Flink
SQL Window解析)