一、哈希表概念
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构,它通过映射函数把关键码值映射到表中一个位置来访问记录,以加快查找的速度。关键码值(Key value)也可以当成是key的hash值,这个映射函数叫做散列函数。而存放记录的数组叫做散列表
二、哈希表原理
根据上述的概念,我们可以理解:所有的key都会根据一个方法计算出对应的Hash值,而Hash值都会存储在一个数组中。数组是一个内存连续的内存块,查询速度快。如果我们得到一个key,就可以快速定位到数组的某个位置。而key存储到一个节点中,这个节点的前一个节点地址就是数组中存储hash的内存地址。所以,每个key的hash都存在数组中,而key则存在以数组对应的某个元素为头节点的链中。
现在我有一组key值[23,45,8,49,99,56],其中每一个key都会根据某函数计算出hash,具体的存储方式如下图:
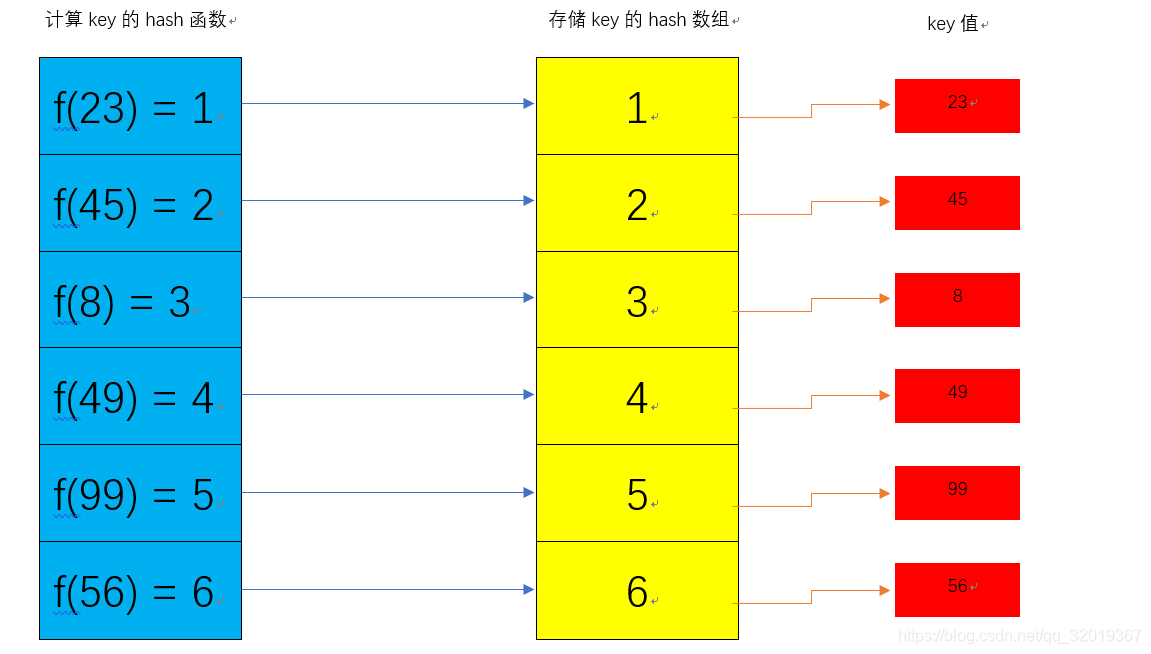
这样会存在一个问题,那就是hash冲突。也就是不同的key根据某函数计算出的hash是一样,那该怎么办呢?看过HashMap源码的小伙伴都知道,HashMap是采用链地址的方法来解决hash冲突的。如下图,如果存在一个key=17的hash和key=49的hash值是一样的。
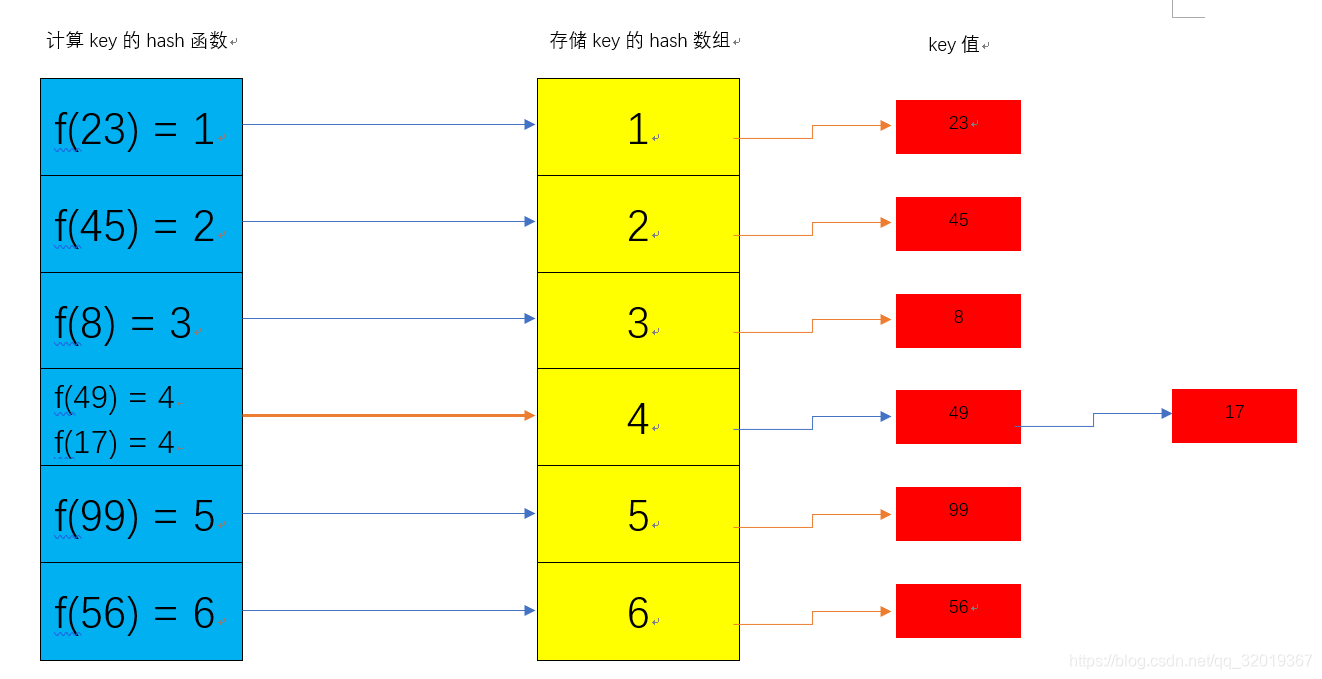
由上图可以看到,冲突的key值会连接到重复hash的key值所在的链中,这样就解决了hash冲突的问题。而链表对于增删改查来说,效率是非常高。
对于存储key的hash数组来说,当hash值的数量达到一定限度时,会自动进行扩容。而这个限度叫做装填因子。但是数组的扩容是非常耗性能的操作,所以在实际的应用中,这个数组的容量是固定的,不进行扩容的操作。比如手机电话薄的容量,微信好友容量等。
三、JDK1.8之后哈希表源码的不同
在JDK1.8之后,HashMap在处理Hash冲突时的细节操作会有不同。当添加相同hash的key时,数量达到一定限度就会采用树的结构来进行数据的存储。因为涉及千万级的数据时,链的长度会非常的长,非常不利于数据的查询。而树的结构会大大减少查询的时间。在下一篇博客,我会介绍树状这个数据结构。
欢迎提问,欢迎纠错!