⭐一,聚合查询
当遇到常见的统计总数、计算平局值等操作,可以使⽤聚合函数来实现,常见的聚合函数有:
1, count函数
返回查询到的数据的条数。
– 统计班级共有多少同学
SELECT COUNT(*) FROM student;
SELECT COUNT(0) FROM student;
– 统计班级收集的 qq有多少个,qq_mail 为 NULL 的数据不会计⼊结果
SELECT COUNT(qq) FROM student;
2,sum函数
返回查询的数据总和,不是数字没有意义
– 统计数学成绩总分
SELECT SUM(math) FROM exam_result;
– 及格 < 60 的总分,没有结果,返回 NULL
SELECT SUM(math) FROM exam_result WHERE math > 60;
3,avg函数
返回数据的平均值,不是数据没有意义
统计平均总分
SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;
4,max函数
返回所查询数据的最大值,不是数字没有意义
– 返回数学最⾼分
SELECT MAX(math) FROM exam_result;
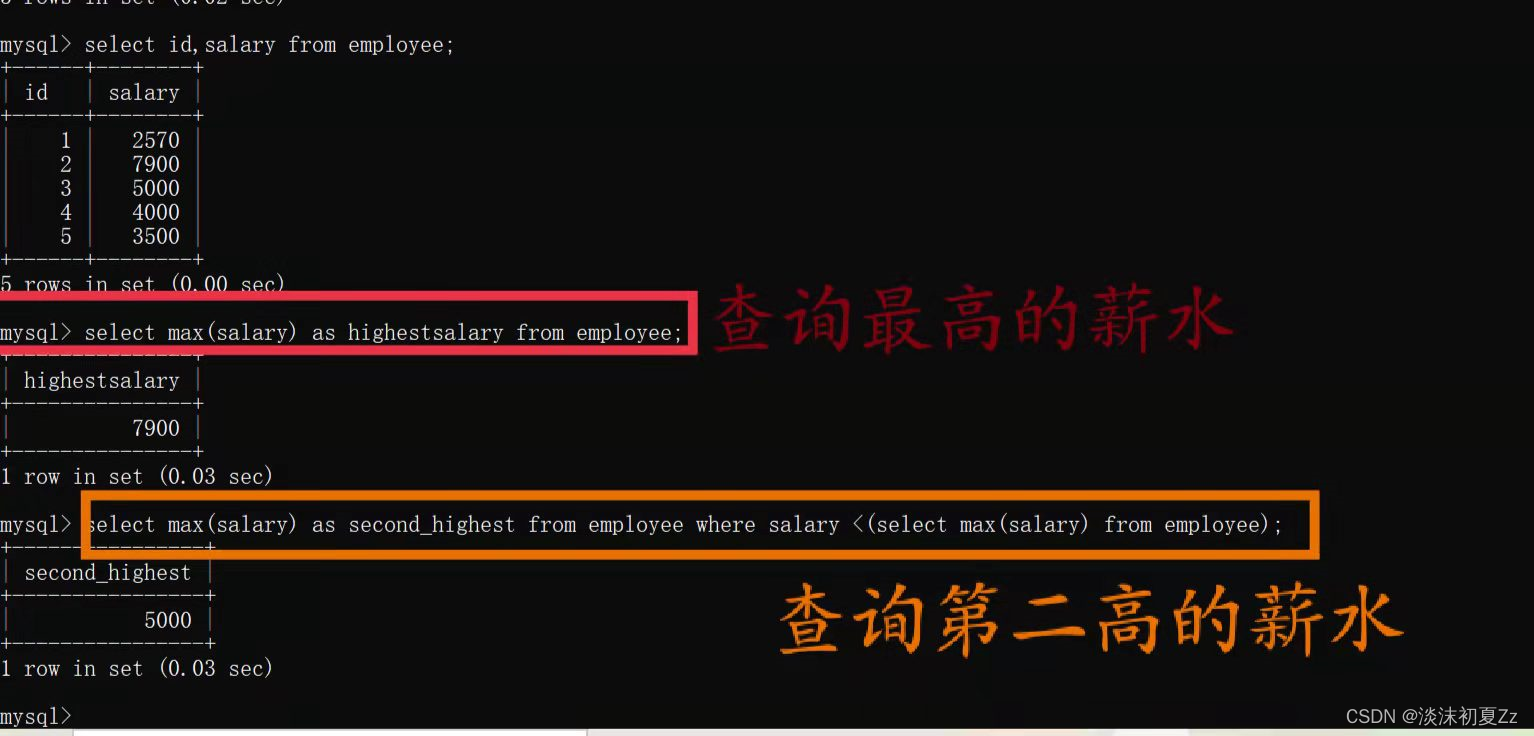
?max函数使用示例
编写一个SQL查询,获取Employee表中
第二高的薪水
(Salary)【陌陌科技2020届校招笔试题】
±—-±——+
| Id | Salary|
±—-±——+
| 1 | 100 |
±—-±——+
| 2 | 200 |
±—-±——+
| 3 | 300 |
±—-±——+
例如上述Employee表,SQL查询应该返回200作为第二高的薪水。如果不存在第二高的薪水,那么查询应该返回null。
SELECT
max( Salary ) AS SecondHighestSalary
FROM
Employee
WHERE
Salary < ( SELECT max( Salary ) FROM Employee );
5,min函数
返回查询到的数据的最⼩值,不是数字没有意义
– 返回 > 60 分以上的数学最低分
SELECT MIN(math) FROM exam_result WHERE math > 60;
6,ifnull函数
ifnull 函数是 MySQL 控制流函数之⼀,它接受两个参数,如果不是 NULL,则返回第⼀个参数,否则 ifnull 函数返回第⼆个参数
ifnull函数的语法
?语法: IFNULL(expression_1,expression_2);
如果 expression_1 不为 NULL,则 IFNULL 函数返回 expression_1,否则返回 expression_2 的结果。
?示例:
ELECT IFNULL(NULL,‘Hello,Null’); – returns Hello,Null
因为第⼀个参数为NULL。接下来我们来看⼀下使⽤IFNULL函数的实例。
? 使用ifnull函数的实例
例如:解决总成绩为null的情况
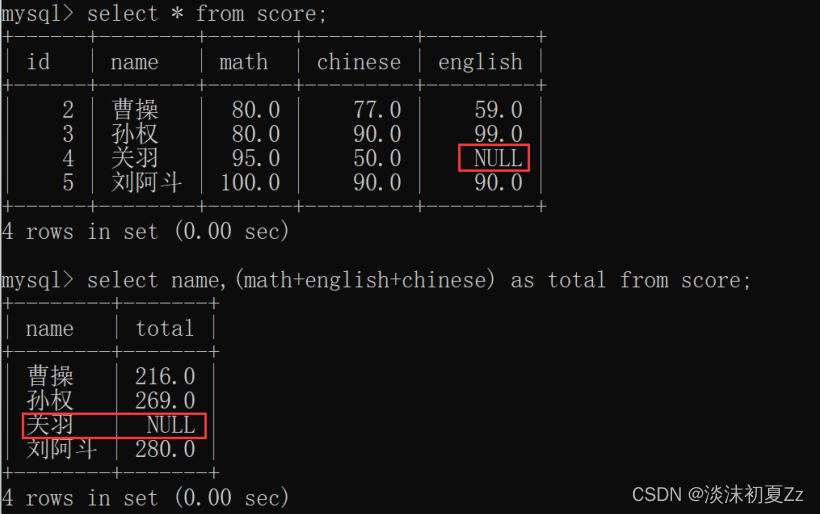
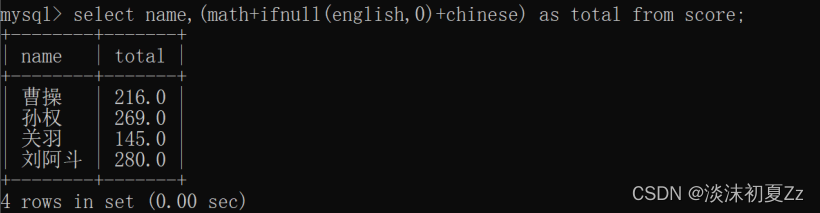
对于关于的总成绩为null,可以使用ifnull函数解决,使用ifnull(english,0),这样就可以解决这个问题,同时也可以使用非空约束或默认值为0
? 二,分组查询-group by
1,分组查询
select中使用group by 子句可以对指定列进⾏分组查询。需要满足:使用group by进行分组查询,select 指定的字段必须是“分组依据字段”,其他字段若想出现select 中则必须包含在聚合函数中
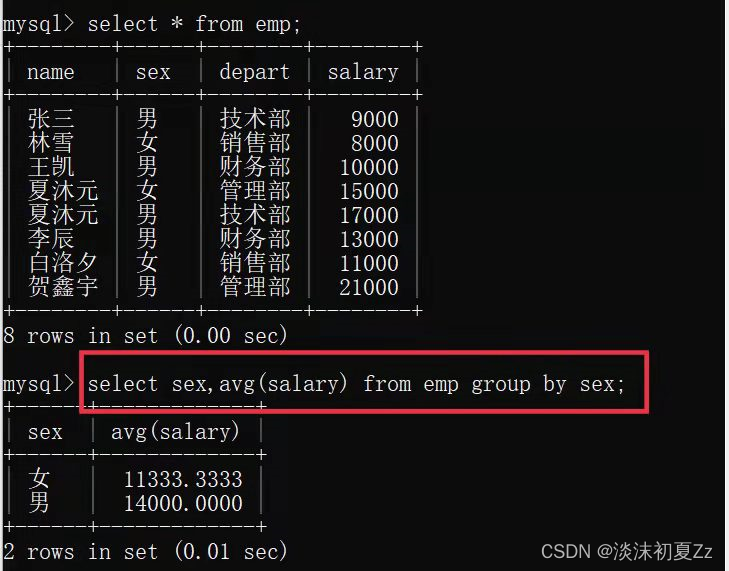
例如:有一张员工表emp,字段:姓名name,性别sex,部门depart,工资salary。查询以下数据
查询男女员工的平均工资
2,分组条件查询having
group by句进行分组以后,需要对分组结果再进行条件过滤时,不能使用where语句,需要用 having
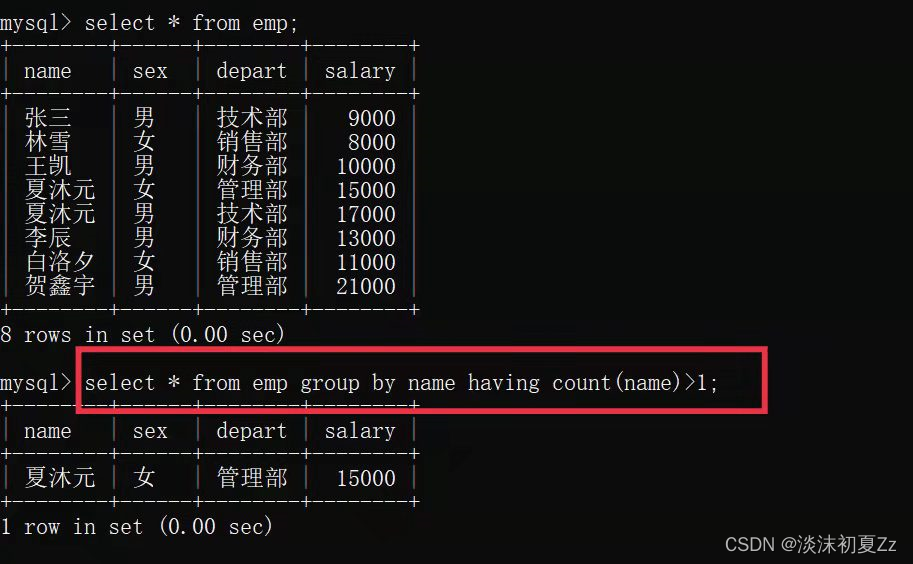
例如:有一张员工表emp,字段:姓名name,性别sex,部门depart,工资salary。查询以下数据:
查询姓名重复的员工信息
3,SQL查询关键字执行顺序
SQL查询关键字执行顺序
group by>having>order by>limit
?三,联合查询(多表查询)
1,前置知识-笛卡尔积
笛卡尔积是联合查询也就是多表查询的基础,那什么是笛卡尔积呢?
笛卡尔积称直积,表示为 X*Y,如 A 表中的数据为 m 行,B 表中的数据有 n 行,那么 A 和 B 做笛卡尔积,结果为 m *n 行。如以下表,它们的笛卡尔积就有 9 个:
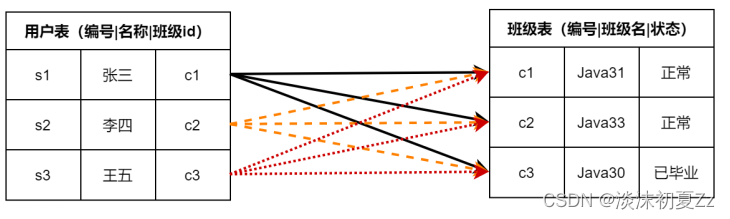
⼀个人只能在⼀个班级,张三在 Java31、李四在Java33、王五在 Java30,标出笛卡尔积和有效的数据信息
创建班级表,课程表,学生表,成绩表,添加测试数据
-- 班级表添加数据
insert into class(id,classname) values(1,'Java班级'),(2,'C++班级');
-- 课程表添加数据
insert into course(id,name) values(1,'计算机'),(2,'英语');
-- 学生表添加数据
insert into student(id,sn,username,mail,class_id) values(1,'CN001','张三','zhangsan@qq.com',1),(2,'CN002','李四','lisi@qq.com',2),(3,'CN003','王五','wangwu@qq.com',1);
-- 成绩表添加数据
insert into score_table(id,score,student_id,course_id) values(1,90,1,1),(2,59,1,2),(3,65,2,1),(4,NULL,2,2);
2,内连接
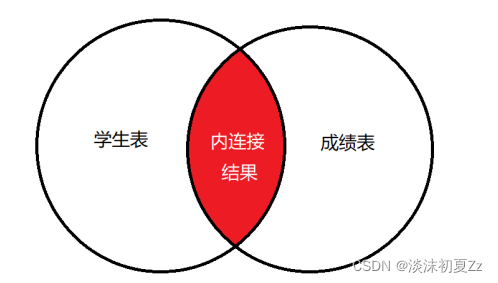
内连接侧重于两个表之间的共性,它的作用是使用联接,比较两个(或多个)表之间的共有数据,然后返回。
如我要查询学生的成绩,涉及到两张表:学⽣表和成绩表,使用内连接查询的数据是下图的红色部分:
2.1内连接语法
语法
select * from t1 join t2 [on 过滤条件] [where 过滤条件]
内连接的写法有以下 4 种:
1 select * from t1 join t2;
2 select * from t1 inner join t2;
3 select * from t1 cross join t2;
4 select * from t1,t2;
2.2示例分析
有班级表,课程表,成绩表,学生表
查询学生张三的成绩
select st , s from score_table st join student s on s.id=st.student_id where s.username=‘张三’;
(1)使用内连接查询(笛卡尔积)
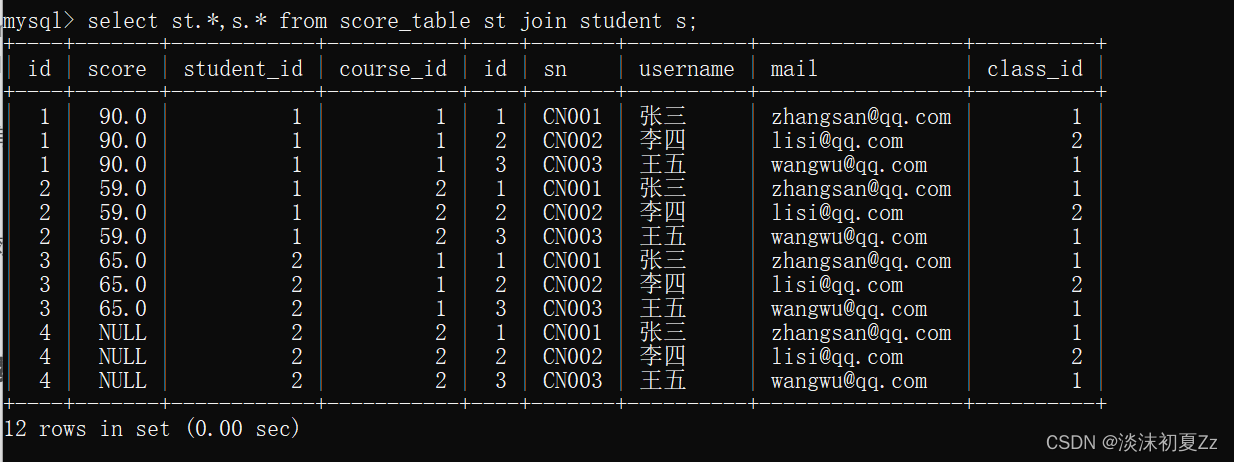
(2)使用on过滤无效条件,在使用where进行过滤得到张三的成绩

2.3内连接查询的问题
我们发现学生表有 3 个用户,然而使用内连接查询的时候,王五同学的数据⼀直没被查询到,王五同学可能是考完试转班过来的,所以只有学⽣表有数据,其他表没有数据。但即使这样,我们也不能漏⼀个⼈,如果其他表为空,成绩可以是 NULL 或者 0,但不能遗漏,这个时候就需要使用外连接了。
3,外连接
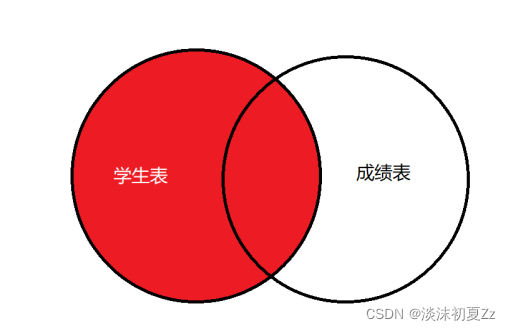
外连接包括内连接和其他至少⼀张表的所有满足条件的信息,外连接包括:
左(外)连接
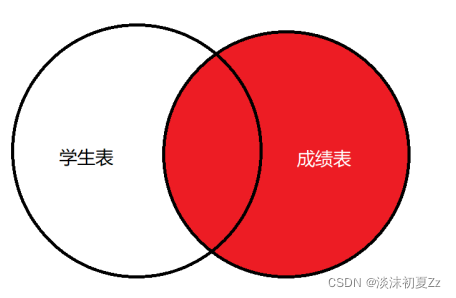
右(外)连接
其中
左连接查询
的内容如下图红色部分
右连接
如下图红色部分
3.1左连接和右连接语法
左连接语法
? select * from t1 left join t2 [on 连接条件];
左连接以左边的表为主查询数据
右连接语法
? select * from t1 right join t2 [on 连接条件];
右连接以右边的表为主查询数据
示例分析
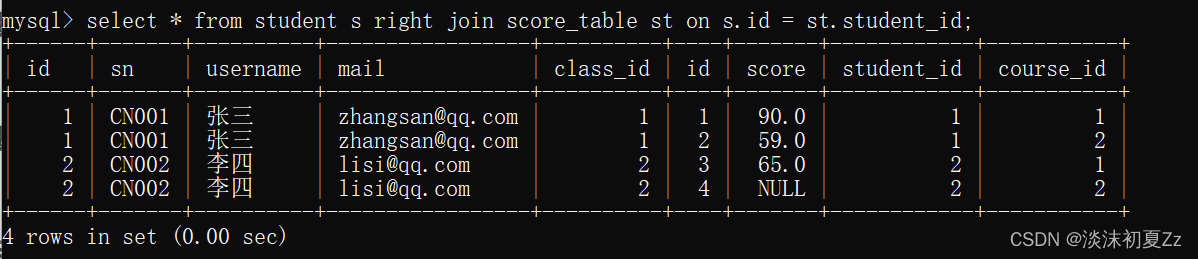
查询所有人的成绩
1,使用左连接查询,student表为主表
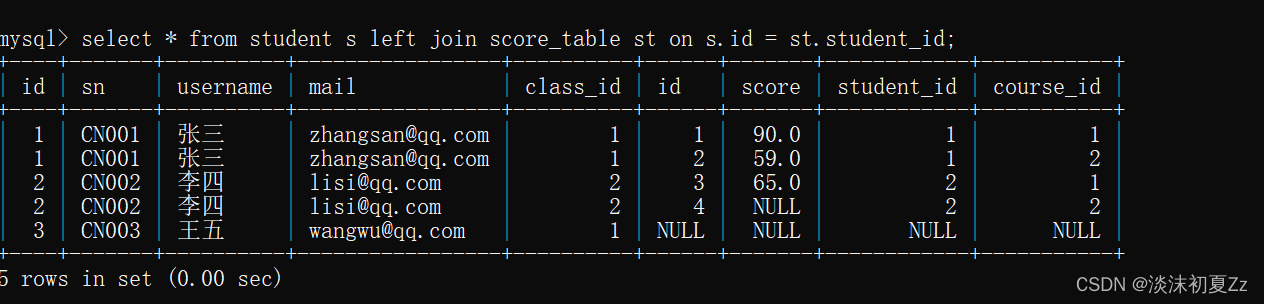
2,使用右连接查询,score_table表为主表
3.2左连接和右连接的区别
left join (左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
right join (右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
3.3on和where的区别
1,on和where
? on是连接两个表时的笛卡尔积形成中间表的约束条件
? where是在有on条件的select语句中过滤中间表的约束条件,在没有on的单表查询中,是限制物理表或中间表记录的约束条件
因此on只进行连接操作,where只过滤中间表的记录
(1)内连接的on可以省略,而外连接的不能省略
(2)on在内连接和外连接的执行效果不同
(3)在外连接中on和where不同
在外连接中若是有多个查询条件,应将查询条件写在where中,而不是写在on中,在on中一般情况下只需要写一个笛卡尔积无效数据的过滤条件即可
4,自连接
⾃连接是指在同⼀张表连接自身进行查询。
示例
查询英语成绩>计算机成绩的数据
select st1.score 英语,st2.score 计算机 from score_table st1,score_table st2 where st1.student_id=st2.student_id and st1.score>st2.score;

从上⾯的语法“select * from t1,t2”我们可以看出,⾃连接就是查询同⼀张表的内查询,因为这个语句就
是内连接的查询语句
5,子查询
⼦查询是指嵌⼊在其他 sql 语句中的 select 语句,也叫嵌套查询
示例
查询计算机或英语的成绩
select * from score_table where course_id in(select id from course where name=‘计算机’ or name=‘英语’);

6,合并查询
合并查询⽤于合并结果集相同的两张(多张)表,它有两个关键字:
union
union all
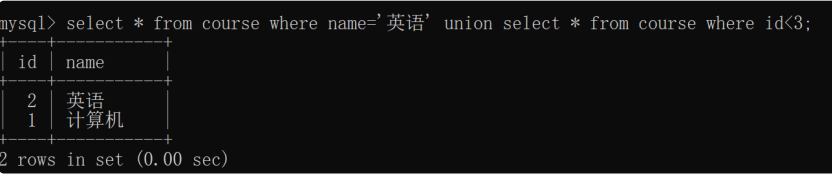
(1)union的使用
查询 id 小于 3 和名字为“英语”的课程:
select * from course where id<3
union
select * from course where name=‘英语’;
– 或者使⽤ or 来实现
select * from course where id<3 or name=‘英语’;
(2)union all 的使用
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行
查询 id 小于 3,或者名字为“英语”的课程
– 可以看到结果集中出现重复数据Java
select * from course where id<3
union all
select * from course where name=‘英语’;

?(3)union和union all的区别
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序
union在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。
实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表union
Union All:对两个结果集进行并集操作,包括重复行,不进行排序
如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。