零、基础
1、系统架构
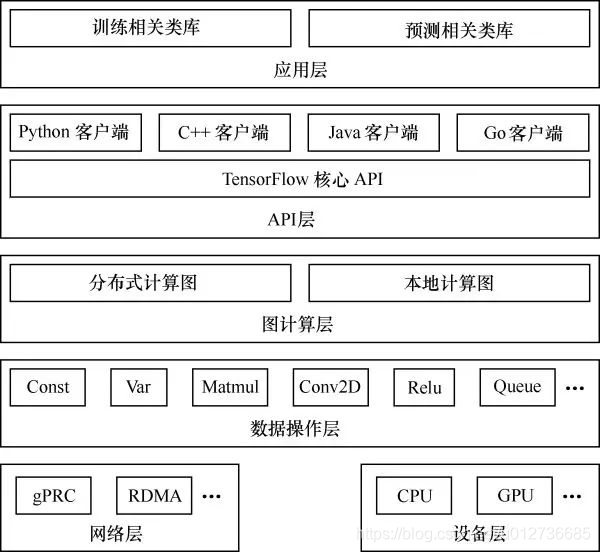
TF的系统架构,从底向上分为设备管理和通信层、数据操作层、图计算层、API接口层、应用层。
其中设备管理和通信层、数据操作层、图计算层是TF的核心层。
-
底层设备通信层负责网络通信和设备管理。
设备管理可以实现TF设备异构的特性,支持CPU、GPU、Mobile等不同设备。网络通信依赖gRPC通信协议实现不同设备间的数据传输和更新。 -
第二层是数据操作层
。主要包括卷积函数、激活函数等操作。 -
第三层是图计算层(Graph)
,包含本地计算流图和分布式计算流图的实现。Graph模块包含Graph的创建、编译、优化和执行等部分。 -
第四层是API接口层
。Tensor C API是对TF功能模块的接口封装,便于其他语言平台调用。 -
第四层以上是应用层
。不同编程语言在应用层通过API接口层调用TF核心功能实现相关实验和应用。
2、设计理念
-
将图的定义和图的运行完全分开。
TF是符号式编程(运行速度快些),符号式计算一般先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量之间的计算关系,最后需要对数据流图进行编译,注意:此时的数据流图中没有任何实质的数据,只有把需要运行的输入放进去,才能在整个模型中形成数据流,从而形成输出值。 -
TF中涉及的运算都放在图中,而图的运行只发生在会话(session)中。
会话启动后,就可以用数据填充节点,进行计算;关闭会话后,不能再计算。
3、常用概念
(1)边
边有两种连接关系:数据依赖和控制依赖。
- 实线表示数据依赖,代表数据(tensor)。
- 虚线表示控制依赖,用于控制操作的运行,用于确保happens-before关系,这类边上没有数据流过,但源节点必须在目的节点开始执行前完成执行。常用以下代码:
tf.Graph.control_dependencies(control_inputs)
(2)节点
节点:代表一个操作,一般表示施加的数学运算,也可以表示数据输入(feed in)的起点以及输出(push out)的终点,或是读取/写入持久变量的终点。
(3)图
将各个节点构建成一个有向无环图。
(4)会话
启动图的第一步就是创建一个Session对象。会话提供在图中执行操作的一些方法。一般的模式是,建立会话,此时会生成一张空图,在会话中添加节点和边,形成一张图,然后执行。
import tensorflow as tf
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([2.], [2.])
product = tf.matmul(matrix1, matrix2)
with tf.Session() as sess:
result = sess.run([product])
print(result)
主要有两个API接口:
- extend:在Graph中注入数据进行计算。
- run:输入计算的节点和填充(传入tensor)必要的数据后,进行运算,并输出运算结果。
(5)设备
设备(device): 一块可以用于运算并拥有自己的地址空间的硬件,eg: GPU和CPU。
设备的设置:
with tf.device("/gpu:1"):
(6)变量——tf.Variable()
变量(variable)在图中有固定的位置,在创建时需要一个初始值,初始值的形状和类型决定该变量的形状来类型。
state = tf.Variable(0, name = "counter") # 定义一个变量,初始化为标量0
input1 = tf.constant(3.0) # 定义一个常量张量
填充机制:tf.placeholder() 临时代替任意操作的张量,在调用Session对象的run()方法执行图时,使用填充数据(feed_dict)作为调用参数,在结束调用后参数消失。
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.mul(input1, input2)
with tf.Session() as sess:
print(sess.run([output], feed_dict={input1:[7.], input2:[2.]}))
(7)内核
内核(kernel):能够运行在特定设备(eg: CPU GPU)上的一种对操作的实现。
关键词:计算模型、数据模型 和 运行模型;神经网络的主要计算流程。
一、计算模型——计算图
计算图是 TF 中最基本的一个概念,TF 中所有计算都会被转化为计算图上的节点。
1、计算图
TensorFlow
- Tensor(张量): 一种数据结构,简单理解为多维数组,数据流图的边。
- Flow(流): 表示张量之间通过计算相互转化的过程,数据流图中节点所做的操作。
2、计算图使用
TF 程序一般可以分为两个阶段:
- 第一阶段:定义计算图中所有计算;
- 第二阶段:执行计算阶段;
(1)计算阶段
计算定义阶段:
import tensorflow as tf
a = tf.constant([1.0, 2.0], name="a")
b = tf.constant([2.0, 3.0], name="b")
result = a + b
# a.graph可以查看张量所属的计算图,若没特指,则为默认的计算图
print(a.graph is tf.get_default_graph())
# True
在此过程中,TF 会自动将定义的计算转化为计算图上的节点。在 TF 程序中,系统会自动维护一个默认的计算图,通过
tf.get_default_graph
函数可以获得当前默认的计算图。
通过
tf.Graph
生成新的计算图,不同计算图上的张量和运算不会共享,这样可以隔离张量和计算。
import tensorflow as tf
## tf.Graph 生成新的计算图
g1 = tf.Graph()
with g1.as_default():
# 在计算图 g1 中定义变量“v”,并初始化为 0.
v = tf.get_variable("v", initializer=tf.zeros_initializer()(shape=[1]))
g2 = tf.Graph()
with g2.as_default():
# 在计算图 g2 中定义变量“v”,并初始化为 1.
v = tf.get_variable("v", initializer=tf.ones_initializer()(shape=[1]))
# 在计算图 g1 中读取变量 “v” 的取值。
with tf.Session(graph=g1) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
# 在计算图 g2 中读取变量 “v” 的取值。
with tf.Session(graph=g2) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
输出
2019-03-08 16:51:32.897748: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-03-08 16:51:33.012464: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:897] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-03-08 16:51:33.013465: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1405] Found device 0 with properties:
name: GeForce GTX 1060 major: 6 minor: 1 memoryClockRate(GHz): 1.6705
pciBusID: 0000:01:00.0
totalMemory: 5.94GiB freeMemory: 5.57GiB
2019-03-08 16:51:33.013487: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1484] Adding visible gpu devices: 0
2019-03-08 16:51:33.239035: I tensorflow/core/common_runtime/gpu/gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-03-08 16:51:33.239077: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 0
2019-03-08 16:51:33.239084: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] 0: N
2019-03-08 16:51:33.239567: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 5338 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1060, pci bus id: 0000:01:00.0, compute capability: 6.1)
[0.]
2019-03-08 16:51:33.305269: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1484] Adding visible gpu devices: 0
2019-03-08 16:51:33.305352: I tensorflow/core/common_runtime/gpu/gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-03-08 16:51:33.305360: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 0
2019-03-08 16:51:33.305365: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] 0: N
2019-03-08 16:51:33.305609: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 5338 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1060, pci bus id: 0000:01:00.0, compute capability: 6.1)
[1.]
(2)相关设置
通过
tf.Graph.device
函数可以指定运行计算的设备(GPU)。
g = tf.Graph()
with g.device('/gpu:0'):
result = a + b
在一个计算图中,可以通过集合(collection)来管理不同类别的资源。eg:
tf.add_to_collection
函数可将资源加入一个或多个集合中,然后通过
tf.get_collection
函数获取一个集合里面所有的资源。资源包括:张量、变量或运行 tf 程序所需的队列资源等等。
(3)TF 中维护的集合列表
| 集合名称 | 集合内容 | 使用场景 |
|---|---|---|
|
所有变量 | 持久化TF 模型 |
|
可学习的变量(NN中参数) | 模型训练、生成模型可视化等内容 |
|
日志生成相关的张量 | TF 计算可视化 |
|
处理输入的 QueueRunner | 处理输入 |
|
所有计算了滑动平均值的变量 | 计算变量的滑动平均值 |
二、数据模型——张量
1、张量的概念
在 Tensorflow 中所有的数据都是通过张量的形式表示,简单理解为 多维数组。
但张量在 Tensorflow 中的实现不是直接采用数组的形式,张量只是对 TF 中运算结果的引用。
在张量中没有真正保存数字,而是何如得到这些数字的计算过程。
import tensorflow as tf
# tf.constant 是一个计算,这个计算的结果是一个张量,保存在变量 a 中。
a = tf.constant([1.0, 2.0], name="a")
b = tf.constant([2.0, 3.0], name="b")
result = tf.add(a, b, name="add")
print(result)
输出
Tensor("add_2:0", shape=(2,), dtype=float32)
分析:
一个张量中主要保存三个属性:名字(name)、维度(shape)和类型(type)。
-
name:一个张量的唯一标识符,同时给出这个张量是如何计算出来的。命名格式:
node:src_output
,其中
node
为节点名称,
src_output
表示当前张量来自节点的第几个输出。
add:0
表示result这个张量是计算节点
add
输出的第一个结果。 -
shape:张量的维度。
shape=(2,)
表示张量 result 是一个长度为 2 的一维数组。 - type:张量的唯一类型。TF 对参与运算的张量进行类型检查,若不匹配则会报错。例如:
import tensorflow as tf
a = tf.constant([1, 2], name="a")
# 修改如下:
# a = tf.constant([1, 2], name="a", dtype=tf.float32)
b = tf.constant([2.0, 3.0], name="b")
result = tf.add(a, b, name="add")
输出
ValueError: Tensor conversion requested dtype int32 for Tensor with dtype float32: 'Tensor("b_1:0", shape=(2,), dtype=float32)'
通过指定
dtype
来明确指出变量或常量的类型。
TF 支持14种不同的类型,主要包括:实数( tf.float32、tf.float64 )、整数( tf.int8、tf.int16、tf.int32、tf.int64、tf.uint8 )、布尔型( tf.bool ) 和复数(tf.complex64、tf.complex128)
2、张量的使用
(1)对中间计算结果的引用
当一个计算包含很多中间结果时,使用张量可以大大提高代码的可读性。同时,可以方便获取中间结果。
# 使用张量记录中间结果
a = tf.constant([1.0, 2.0], name="a")
b = tf.constant([2.0, 3.0], name="b")
result = a + b
# 直接计算向量的和
result = tf.constant([1.0, 2.0], name="a") + tf.constant([2.0, 3.0], name="b")
(2)获取计算结果
当计算图构造完成之后,张量可以用来获取计算结果。
tf.Session().run(result)
获取计算结果。
三、运行模型——会话(session)
使用会话(session)执行定义好的运算。
会话拥有并管理 TF 程序运行是所有的资源,在所有计算完成之后需要关闭会话来帮助系统回收资源,否则会出现资源泄露的问题。
1、两种模式
- 需要明确调用会话生成函数和关闭会话函数。该模式代码流程如下:
# 创建会话
sess = tf.Session()
# 例如获取张量 result 的取值
sess.run(result)
# 关闭会话使得本次运行中使用的资源可以被释放
sess.close()
在这种模式下,在所有计算完成之后,需要明确调用
Session.close()
函数来关闭会话并释放资源。
但是,若程序异常退出则不会执行该函数。
==》
- 通过 Python 的上下文管理器来使用会话。
# 创建一个会话,并通过 Python 的上下文管理器来使用会话
with tf.Session() as sess:
sess.run(...)
# 不再需要调用'Session.close()'函数关闭会话
# 当上下文退出时,会话关闭和资源释放也自动完成
2、默认会话设置
TF 不会自动生成默认的会话,而是需要手动指定。当默认的会话被指定之后,可通过
tf.Tensor.eval
函数计算一个张量的值。
sess = tf.Session()
with sess.as_default():
print(result.eval())
# 两部分等价
sess = tf.Session()
print(sess.run(result))
print(result.eval(session=sess))
tf.InteractiveSession()
函数可以自动将生成的会话注册为默认会话。
sess = tf.InteractiveSession()
print(result.eval())
sess.close()
3、配置会话
配置会话:通过
tf.ConfigProto
函数配置需要生成的会话。通过
tf.ConfigProto
可以配置类似并行的线程数、GPU分配策略、运算超时时间等参数。
最常用的参数:
-
allow_soft_placement:布尔型的参数,当它为
True
时,以下任意一个条件成立时,GPU上的运算可以放到CPU上进行:- 运算无法在 GPU 上执行;
- 没有GPU资源;
- 运算输入包含对CPU计算结果的引用。
- log_device_placement:当它为 True 时,日志中将会记录每个节点被安排在哪个设可备上以方便调试;实际中,设置为 False 可减少日志量
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
sess1 = tf.InteractiveSession(config=config)
sess2 = tf.Session(config=config)
四、实现神经网络
1、过程
使用神经网络解决分类问题可分为以下步骤:
(1) 提取问题中实体的特征向量作为神经网络的输入;
(2) 定义网络结构;
(3) 神经网络的训练(调整参数)
(4) 预测未知数据。
2、前向传播算法
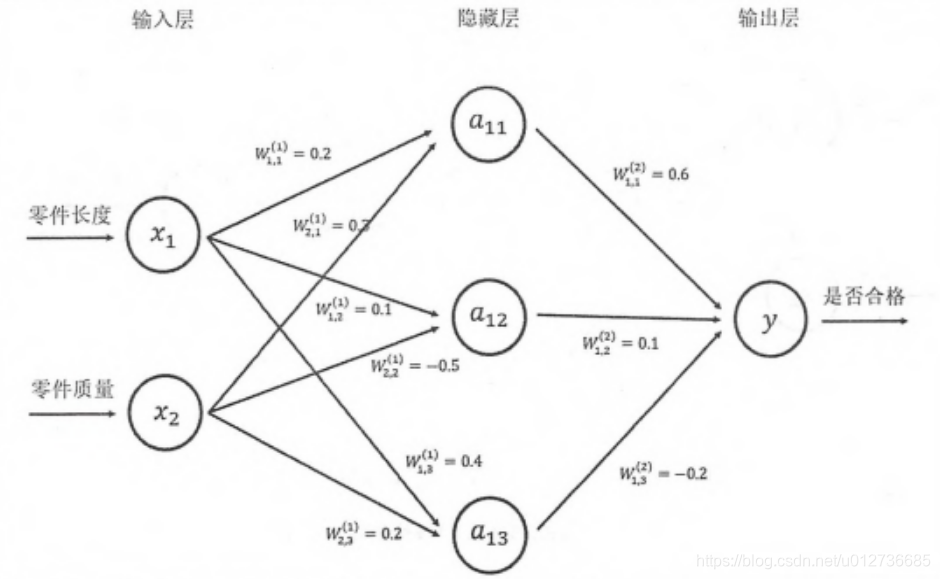
TF 程序
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
3、神经网络参数 与 TensorFlow变量
侧重点: Tensorflow 是如何组织、保存及使用神经网络中的参数。
(1)tf.Variable(变量)
作用
:保存和更新神经网络中的参数,需要进行初始化,还可设置为常数或通过其他变量的初始值计算得到。
神经网络中,常见的初始化:随机初始化。
## 声明均值为0,标准差为2的2*3随机数矩阵。mean参数可以设置平均值,默认为0
weights = tf.Variable(tf.random_normal([2, 3], stddev=2))
随机数生成函数
| 函数名称 | 随机数分布 | 主要参数| |
|---|---|---|
|
正态分布 | 均值、标准差、取值类型 |
|
正态分布,若随机生成的值偏离均值超过2个标准差,则重新生成 | 均值、标准差、取值类型 |
|
均匀分布 | 最大取值、最小取值、取值类型 |
|
Gamma分布 | 形状参数alpha、尺度参数beta、取值类型 |
(2)常数初始化
| 函数名称 | 功能 | 样例| |
|---|---|---|
|
生成全0数组 |
-> |
|
生成全1数组 |
-> |
|
生成一个全部为给定数字的数组 |
-> |
|
生成一个给定值的常量 |
-> |
(3)偏置项(bias)设置
bias 通常使用常数来设置。
## 设置初值全为0且长度为3的变量
biases = tf.Variable(tf.zeros([3]))
(4)其他变量的初始值进行初始化
w2 = tf.Variable(weights.initialized_value())
w3 = tf.Variable(weights.initialized_value() * 2.0)
(5)样例
import tensorflow as tf
# 声明w1、w2两个变量。seed参数设置随机种子,保证每次结果一致
w1 = tf.Variable(tf.random_normal((2, 3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), stddev=1, seed=1))
# 定义为一个1*2矩阵
x = tf.constant([[0.7, 0.9]])
# 前向传播
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
sess.run(w1.initializer) # 初始化 w1
sess.run(w2.initializer) # 初始化 w2
print(sess.run(y))
sess.close()
输出
[[3.957578]]
通过
tf.global_variables_initalizer
函数实现初始化所有变量。
init_op = tf.global_variable_initalizer()
sess.run(init_op)
4、通过Tensorflow训练神经网络模型
使用反向传播算法训练神经网络的流程图。
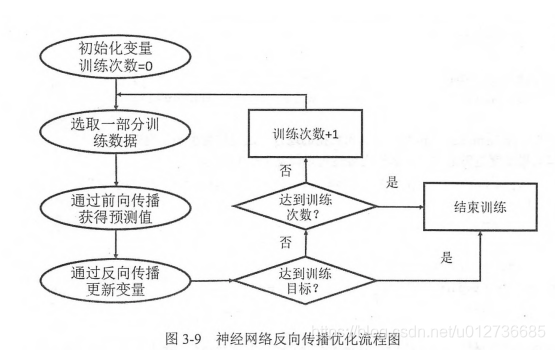
反向传播算法实现了一个迭代过程。在每次迭代的开始,首先需要选取一小部分训练数据(batch)。然后,这个 batch 的样例会通过前向传播算法得到神经网络模型的预测结果,并计算与 ground truth 之间的差距。最后,反向传播算法通过这个差距,更新神经网络的参数,使得预测结果与 ground truth 更加接近。
5、完整代码
import tensorflow as tf
from numpy.random import RandomState
# 设置训练数据 batch 大小
batch_size = 8
# 定义神经网络参数
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 训练数据
x = tf.placeholder(tf.float32, shape=(None, 2), name='x-input')
y_ = tf.placeholder(tf.float32, shape=(None, 1), name='y-input')
# 前向传播
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 损失函数和反向传播过程
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
# 通过随机数生成一个模拟数据集
rdm = RandomState(1)
dataset_size = 120
X = rdm.rand(dataset_size, 2)
Y = [[int(x1 + x2) < 1] for (x1, x2) in X]
# 创建会话来运行 TF 程序
with tf.Session() as sess:
init_op = tf.initialize_all_variables()
# 初始化变量
sess.run(init_op)
print(sess.run(w1))
print(sess.run(w2))
# 设置训练的轮数
STEPS = 5000
for i in range(STEPS):
# 每次选取batch_size个样本进行训练
start = (i * batch_size) % dataset_size
end = min(start + batch_size, dataset_size)
# 通过选取的样本训练神经网络并更新参数
sess.run(train_step, feed_dict={x: X[start: end], y_:Y[start: end]})
if i % 1000 == 0:
# 每隔一段时间计算所有数据上的交叉熵损失函数。
total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y})
print("After %d training step(s), cross entropy on all data is %g" %
(i, total_cross_entropy))
print(sess.run(w1))
print(sess.run(w2))
输出
2019-03-09 12:22:31.932975: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-03-09 12:22:32.053557: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:897] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-03-09 12:22:32.054556: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1405] Found device 0 with properties:
name: GeForce GTX 1060 major: 6 minor: 1 memoryClockRate(GHz): 1.6705
pciBusID: 0000:01:00.0
totalMemory: 5.94GiB freeMemory: 5.49GiB
2019-03-09 12:22:32.054595: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1484] Adding visible gpu devices: 0
2019-03-09 12:22:32.284779: I tensorflow/core/common_runtime/gpu/gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-03-09 12:22:32.284804: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 0
2019-03-09 12:22:32.284810: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] 0: N
2019-03-09 12:22:32.285118: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 5257 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1060, pci bus id: 0000:01:00.0, compute capability: 6.1)
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/util/tf_should_use.py:118: initialize_all_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02.
Instructions for updating:
Use `tf.global_variables_initializer` instead.
[[-0.8113182 1.4845988 0.06532937]
[-2.4427042 0.0992484 0.5912243 ]]
[[-0.8113182 ]
[ 1.4845988 ]
[ 0.06532937]]
After 0 training step(s), cross entropy on all data is 0.071992
After 1000 training step(s), cross entropy on all data is 0.0167723
After 2000 training step(s), cross entropy on all data is 0.00941592
After 3000 training step(s), cross entropy on all data is 0.00749986
After 4000 training step(s), cross entropy on all data is 0.00600073
[[-1.984426 2.6028152 1.7178398]
[-3.4925323 1.0919542 2.1556146]]
[[-1.8463261]
[ 2.7097478]
[ 1.4506569]]
关键点
:
tf提供了
placeholder
机制用于提供输入数据。
placeholder
相当于定义了一个位置,这个位置中的数据在程序运行时再指定。定义
placeholder
时,需要指定类型,但是不一定需要维度,因为可以根据提供的数据推导出来。