IO流
一、IO流的分类
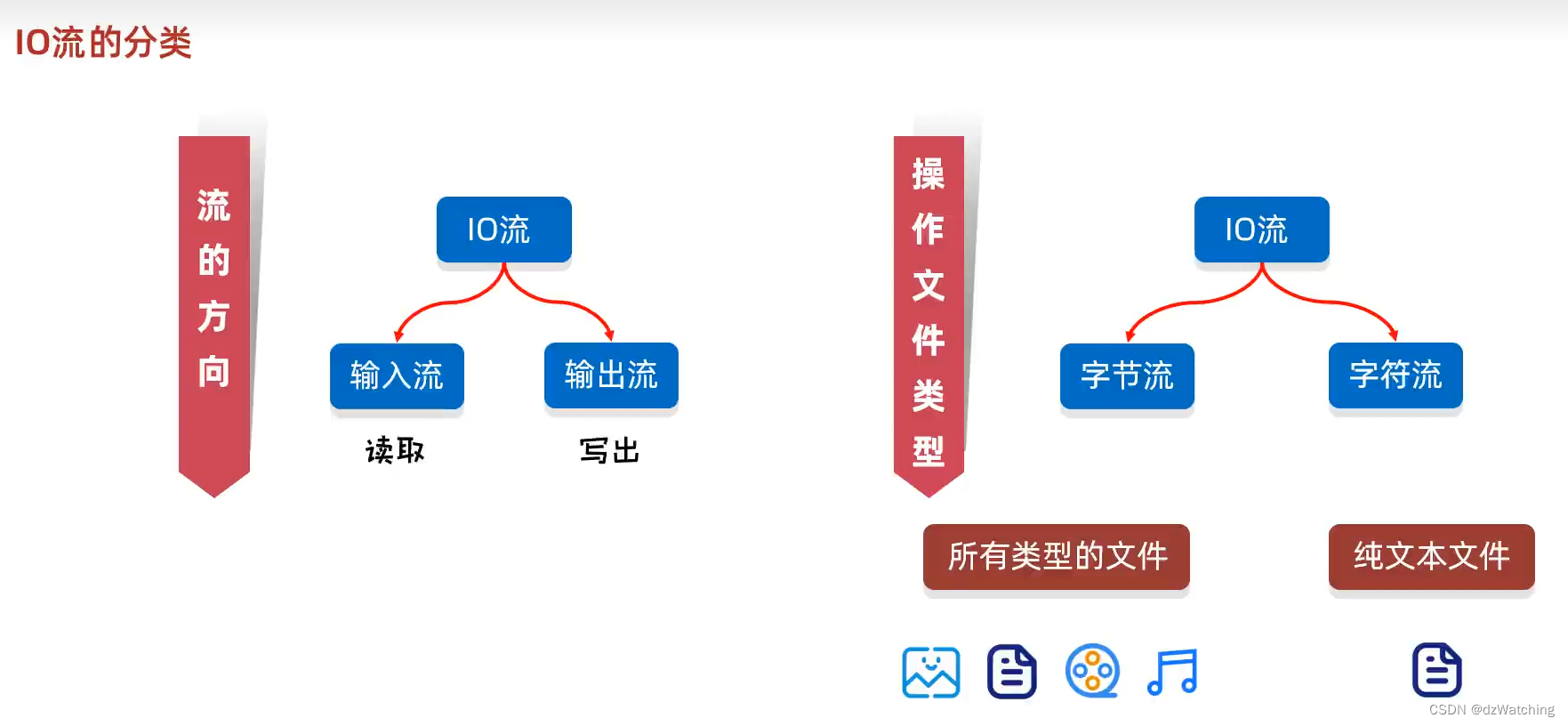
字节流
字节流可以操作任意类型的文件
字符流
字符流只能操作纯文本文件
总结

二、字节 输入输出流
输出流,使用FileOutputStream举例


FileOutputStream是一个字节输出流(一般情况下,output代表输出,stream代表字节流。FileWriter就是字符输出流。
写出
下面的代码就是简单的写出操作
/**
* @author Watching
* * @date 2023/5/19
* * Describe:
* 演示: 字节输出流 FileOutputStream
* 实现需求:写出一段文字到本地
* 1.创建输出流对象
* 细节1:参数是字符串表示的路径或者是File对象都是可以的
* 细节2:如果文件不存在会创建一个新的文件,但是要保证父级路径是存在的。.
* 细节3:如果文件已经存在,则会清空文件
* 2.写数据
* 细节: write方法的参数是整数,但是实际上写到本地文件中的是整数在ASCII上对应的字符
* 3.释放资源
* 每次使用完流,都需要关闭流对象,防止资源占用
*/
public class ByteStreamDemo1 {
public static void main(String[] args) throws IOException {
FileOutputStream fileOutputStream = new FileOutputStream("a.txt");
fileOutputStream.write(97);
fileOutputStream.close();
}
}
换行写出,续写
有时我们不止要写出一行,可能有换行的需求,还有不覆盖原文件内容,在原文件内容上面追加。
/**
* @author Watching
* * @date 2023/5/19
* * Describe:
* 文件输出流实现换行写,续写
* 换行写:
* 只需要在两行数据之间添加一个换行符
* windows: \r\n
* linux: \n
* mac: \r
* java底层对windows操作系统的换行做了补全,只写\n或者\r都可以实现换行,但是建议还是要写全
* 续写
*/
public class ByteSteamDemo3 {
public static void main(String[] args) throws IOException {
FileOutputStream fileOutputStream = new FileOutputStream("a.txt",true);
String str = "helloworld";
byte[] bytes = str.getBytes();
fileOutputStream.write(bytes);
String wrap = "\r\n";
byte[] bytes1 = wrap.getBytes();
fileOutputStream.write(bytes1);
String str2 = "666";
byte[] bytes2 = str2.getBytes();
fileOutputStream.write(bytes2);
fileOutputStream.close();
}
}
想要续写,在创建文件输出对象时只需要选择带有append形参的构造器就行下·
输入流,使用FileInputStream举例
读入
read()方法每次只能读取一个字节,当读到文件末尾时,read()方法会返回 -1
/**
* @author Watching
* * @date 2023/5/19
* * Describe:
* 文件输入流FileInputStream
*
* 字节输入流的细节:
* 1.创建字节输入流对象
* 细节1:如果文件不存在,就直接报错。
* 2.写数据
* 细节1:一次读-一个字节,读出来的是数据在ASCII上对应的数字
* 细节2:读到文件末尾了,read方法返回-1。
* 3.释放资源
* 细节:每次使用完流之后都要释放资源
*/
public class ByteStreamDemo {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream("a.txt");
int read1 = fileInputStream.read();
System.out.println((char) read1);//可以使用强转讲数字转为原本的内容
int read2 = fileInputStream.read();
System.out.println(read2);
int read3 = fileInputStream.read();
System.out.println(read3);
int read4 = fileInputStream.read();
System.out.println(read4);
int read5 = fileInputStream.read();//读到文件末尾read()方法会返回-1
System.out.println(read5);
fileInputStream.close();
}
}
循环读入
根据read()方法读到末尾会返回-1,使用while循环进行循环读取
/**
* @author Watching
* * @date 2023/5/19
* * Describe:循环读取
*/
public class ByteStreamDemo3 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("a.txt");
int b =0;
while((b = fis.read()) != -1){
System.out.println((char)b);
}
fis.close();
}
}
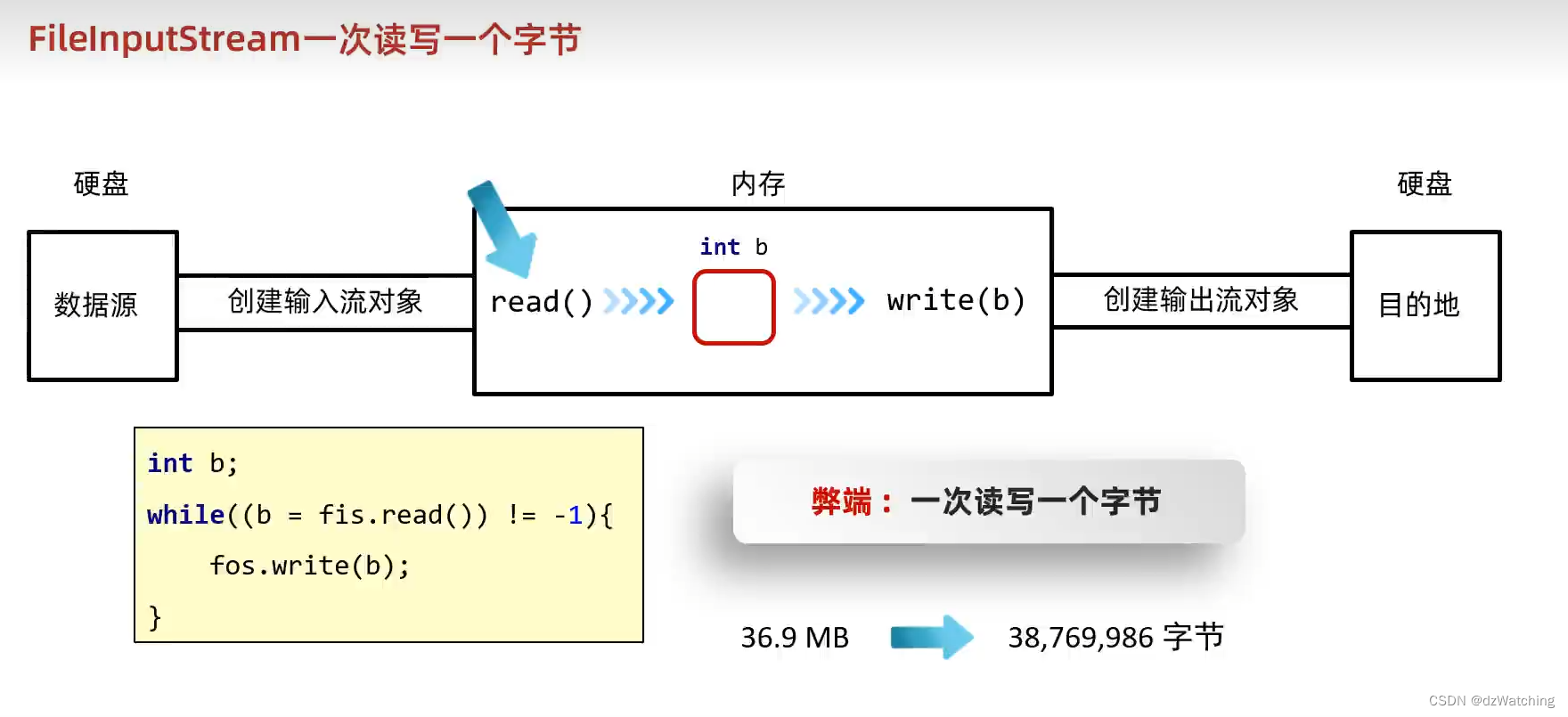
使用循环读入完成拷贝文件
/**
* @author Watching
* * @date 2023/5/19
* * Describe:、
* 这种方式只适合拷贝小文件,因为read()方法一次只能读取一个文件
*/
public class ByteStreamDemo4 {
public static void main(String[] args) throws IOException {
long start = System.currentTimeMillis();
FileInputStream fis = new FileInputStream("a.txt");
FileOutputStream fos = new FileOutputStream("b.txt");
int b = 0;
while((b = fis.read()) != -1){//读一个字节
fos.write(b);//写一个字节
}
//先开启的流后关闭
fos.close();
fis.close();
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}
这样进行文件拷贝会有一个问题,因为我们每次都读入的是一个字节,如果一个文件的大小有几百万字节,那么我们就需要循环几百万次,这样的效率是很低的。
使用循环读入完成拷贝文件,一次读入多个字节
下面的代码和上面的代码的区别就是:这段代码可以一次性读入
1024
个字节,使用的是
read(byte[] bytes)
方法,该方法也会在读到末尾时返回-1,在读到末尾之前每次返回读到的字节数
/**
* @author Watching
* * @date 2023/5/19
* * Describe:
* 使用read(Byte[] byte)可以一次性读取多个字节
*/
public class ByteStreamDemo5 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("a.txt");
FileOutputStream fos = new FileOutputStream("b.txt");
byte[] bytes = new byte[1024];
int len;
while((len = fis.read(bytes)) != -1){
fos.write(bytes,0,len);
}
fos.close();
fis.close();
}
}
思考题:
/**
* @author Watching
* * @date 2023/5/19
* * Describe:观察read(byte[] bytes)是如何读取文件中的字节的
*/
public class ByteStreamDemo6 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("a.txt");
byte[] bytes = new byte[2];//一次性可以读入两个字节
int len1 = fis.read(bytes);
String str1 = new String(bytes);
System.out.println(str1);//ab
int len2 = fis.read(bytes);
String str2 = new String(bytes);
System.out.println(str2);//cd
int len3 = fis.read(bytes);
String str3 = new String(bytes);
System.out.println(str3);//ed
//这里只读取了一个字节e,但是bytes数组中还有上一次读取的数据cd,所以e将c覆盖了
//输出bytes中的内容,为ed
}
}
请想一想,这段代码的执行结果是什么?

答案:
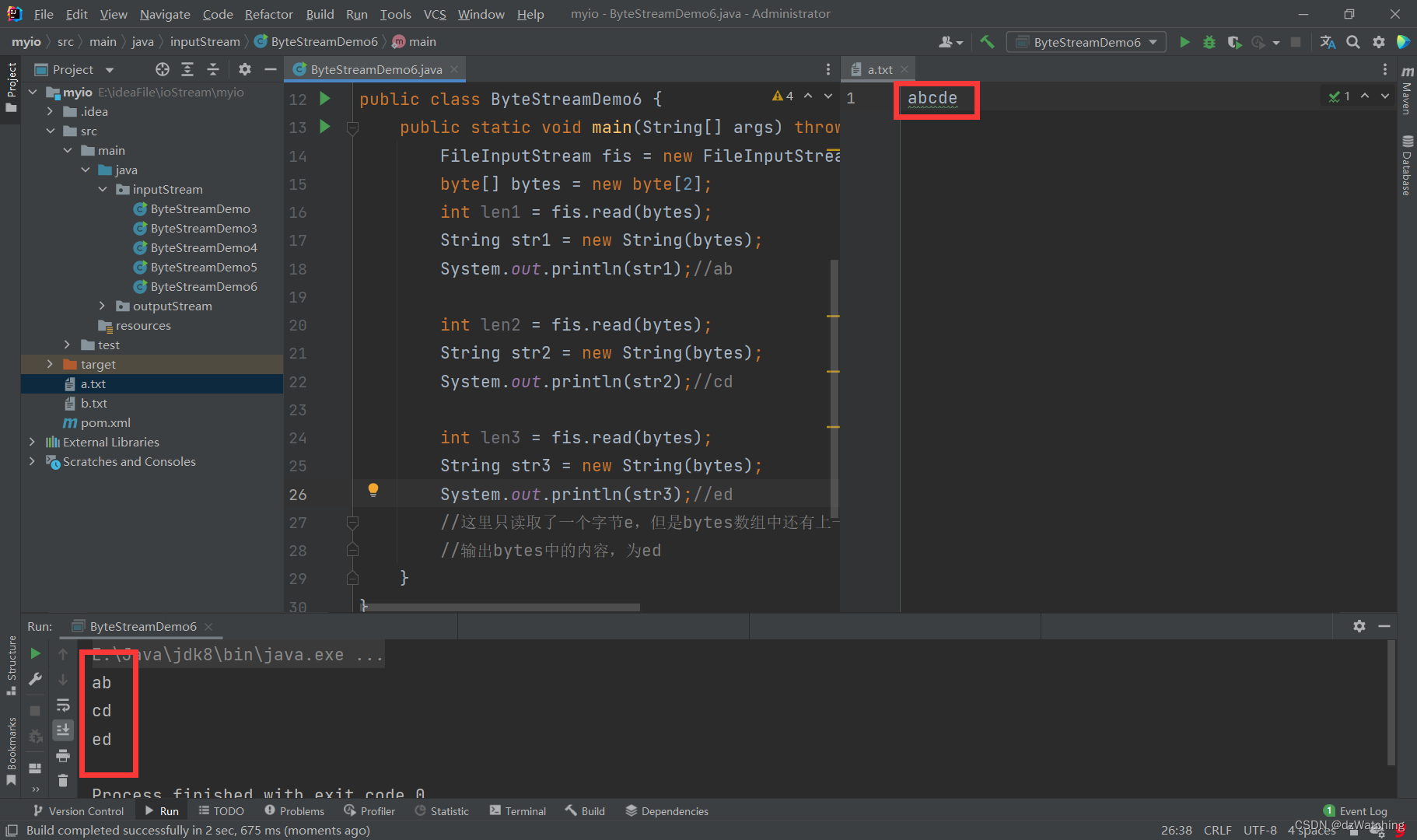
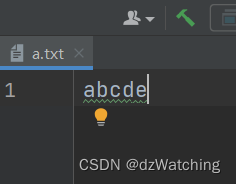
可以看到当我们使用大小为2的字节数组去读取内容为abcde的文件时,第一次读取到的内容为ab,第二次为cd,第三次为ed。
这是因为第三次读取时,字节数组中还保存了第二次读取的数据cd,第三次读取程序发现,内容只剩下e了,它就拿着e去覆盖了字节数组中的第一个字节c,于是我们输出字节数组的内容时,就出现了ed。
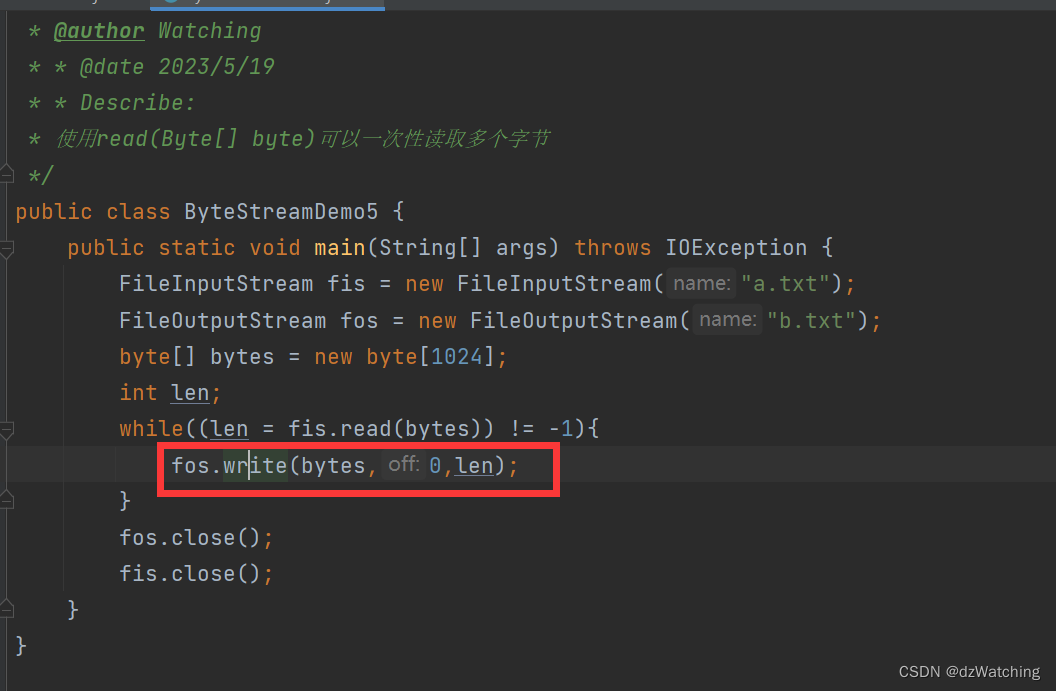
为了防止这种情况,我们可以利用read(byte[] bytes)方法每次读取返回的读取到的字节数量len。例如:
/**
* @author Watching
* * @date 2023/5/19
* * Describe:观察read(byte[] bytes)是如何读取文件中的字节的
*/
public class ByteStreamDemo6 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("a.txt");
byte[] bytes = new byte[2];
int len1 = fis.read(bytes);
String str1 = new String(bytes,0,len1);
System.out.println(str1);//ab
int len2 = fis.read(bytes);
String str2 = new String(bytes,0,len2);
System.out.println(str2);//cd
int len3 = fis.read(bytes);
String str3 = new String(bytes,0,len3);
System.out.println(str3);//ed
//这里只读取了一个字节e,但是bytes数组中还有上一次读取的数据cd,所以e将c覆盖了
//输出bytes中的内容,为ed
}
}
三、try-resource
释放流的资源时,我们通常需要将close方法写在finally中。
jdk7和jdk9为我们提供了新的写法:

try-catch-finally写法
/**
* @author Watching
* * @date 2023/5/19
* * Describe:
*/
public class ByteStreamDemo7 {
public static void main(String[] args) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("a.txt");
fos = new FileOutputStream("b.txt");
byte[] bytes = new byte[1024];
int len;
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//如果在new流对象的时候出现了fileNotFound异常,则fis或者fos不会被初始化,那么fos.close fis.close就会报空指针异常
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
try-resource写法
/**
* @author Watching
* * @date 2023/5/19
* * Describe:jdk7 try-resource
*/
public class ByteStreamDemo8 {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("a.txt"); FileOutputStream fos = new FileOutputStream("b.txt")) {
byte[] bytes = new byte[1024];
int len;
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes,0,len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
需要注意的是,能使用try-resource结构的类必须实现AutoCloseable接口(如果你没看见这个接口被实现,有可能是他的父类实现了)
四、字符集与编码方式
Ascll字符集与编码方式
一个Ascll字符集中的字符占1byte(8个bit)。
在编码时
,在字符集中查出要存储的字符的十进制编码,转成二进制,不足8bit的在最高位补0,再存入计算机。
在解码时
,将二进制数字转为十进制,在字符集中查询对应的字符。

GBK字符集与编码方式
GBK字符集是完全兼容Ascll码的,GBK在
存储英文字符
时也是使用的1个byte,不足8bit的在高位补0。

GBK编码在存储汉字时会使用2个byte,不需要进行补0。
解码时只需要将高位为1开头的8bit和后面连着的8bit一共16bit转换为一个汉字就行。

GBK在进行解码时只需要将2byte二进制数转换为一个十进制数就好。

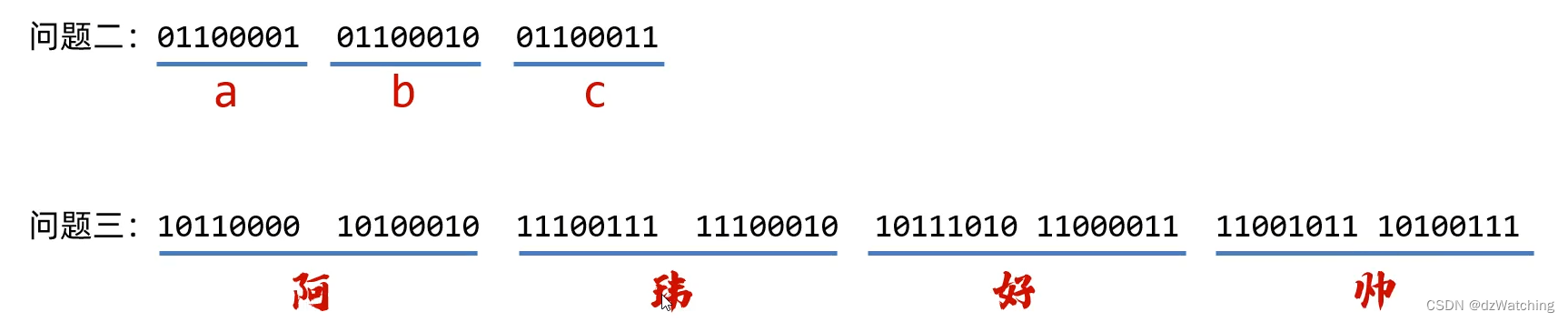
思考题

根据GBK字符集的规则,汉字高位二进制一定以1开头,汉字由两个byte存储,兼容的ascll码是以0开头,所以这段二进制数是一个汉字,一个英文字符。

可以用下面两个问题对比一下。
总结

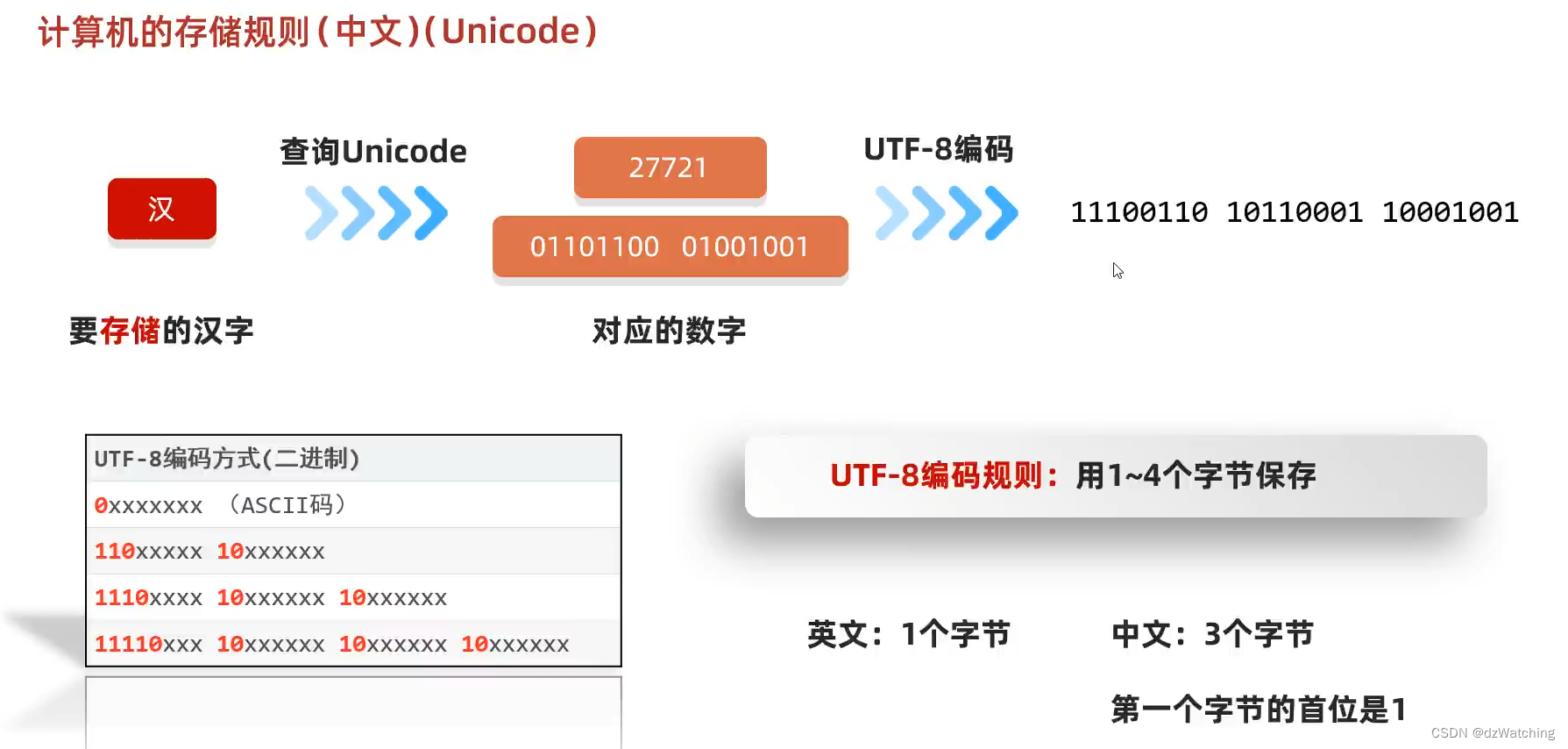
五、UTF-8编码
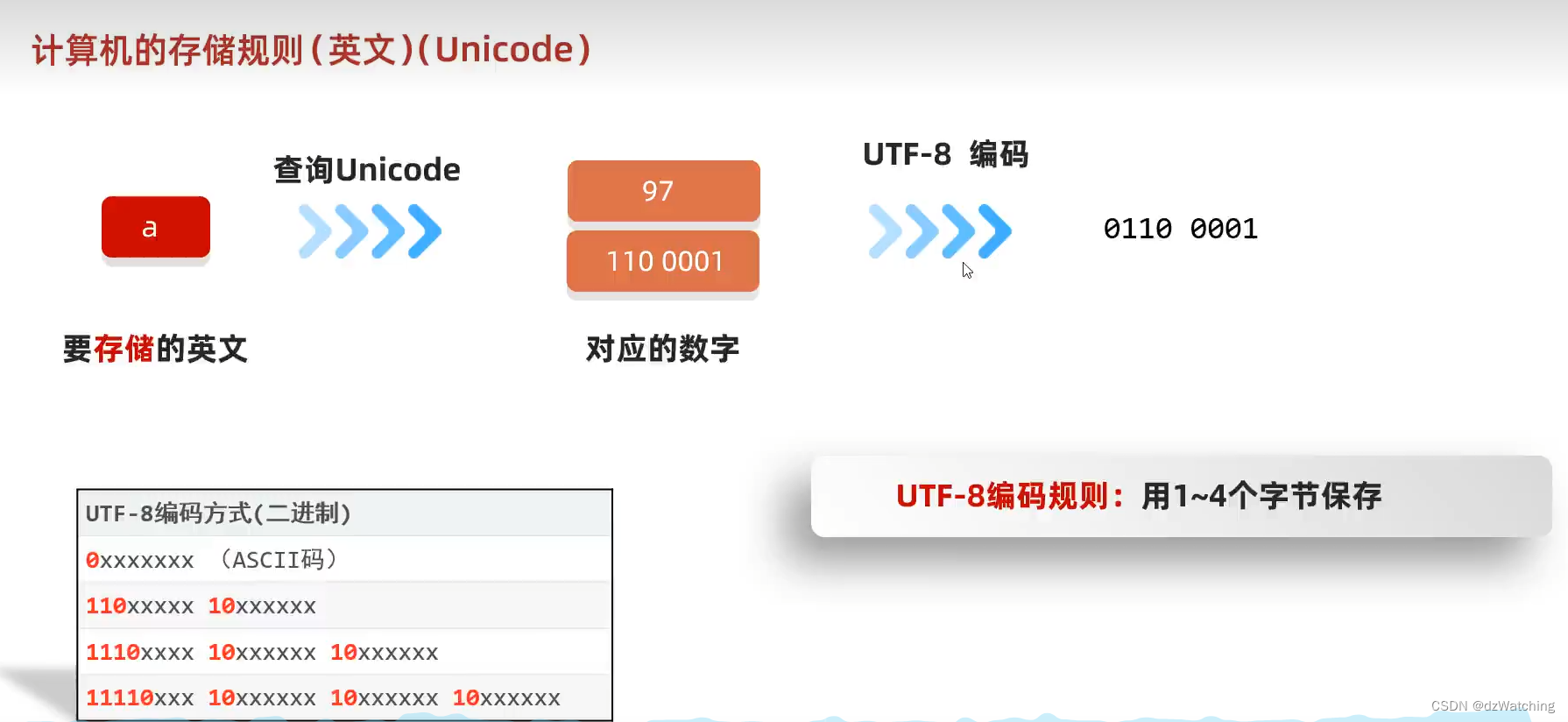
UTF-8是指unicode字符集的一种编码风格,它是一种
可变长度
的编码方式

例如英文编码:
中文编码:
思考题


总结

六、为什么会产生乱码?
原因一:读取字节不完整
例如:11100100 10111101 10100000 这3个字节表示一个汉字 “你”。但是在读取的时候,只读取了前两个字节,11100100 10111101。这样的话在字符集中就找不到对应的汉字字符,就会出现乱码。
原因二:解码的方式和编码的方式不统一
正常的情况:utf-8编码,utf-8解码

乱码情况:utf-8编码,gbk解码
utf-8是保存的三个字节为一个汉字,而GBK在获取到第一个字节11100110后,发现最高位是1,所以会连着10110001一起将这两个字节解释为汉字。11100110 10110001在GBK中表示姹,而10001001没有对应的字符,所以用问号表示,所以乱码了。

七、java中的编码和解码方法
/**
* @author Watching
* * @date 2023/5/21
* * Describe:
* java中的编码与解码
*/
public class CharsetDemo {
public static void main(String[] args) throws UnsupportedEncodingException {
/**
* 编码
*/
String str = "ai你哟";
byte[] bytes = str.getBytes();
System.out.println("ai你哟 utf-8编码:"+Arrays.toString(bytes));//[97, 105, -28, -67, -96, -27, -109, -97]
//idea默认的是utf-8编码所以ai你哟被编码成了8个字节(英文一个字节,汉字三个字节)
byte[] bytes1 = str.getBytes("GBK");//可以手动指定编码方式,但是需要抛出一个异常(UnsupportedEncodingException,不支持的编码方式)
System.out.println("ai你哟 GBK编码:"+Arrays.toString(bytes1));//[97, 105, -60, -29, -45, -76]
//GBK编码方式,英文占一个字节,汉字占两个字节,所以得到了6个字节
/**
* 解码
*/
//idea默认的解码方式是utf-8
String s = new String(bytes);
System.out.println(s);//ai你哟
//指定为GBK解码,使用GBK的解码方式解UTF-8编码的字符,会出现乱码
String s1 = new String(bytes,"GBK");
System.out.println(s1);//ai浣犲摕
}
}
八、字符流
================疑问
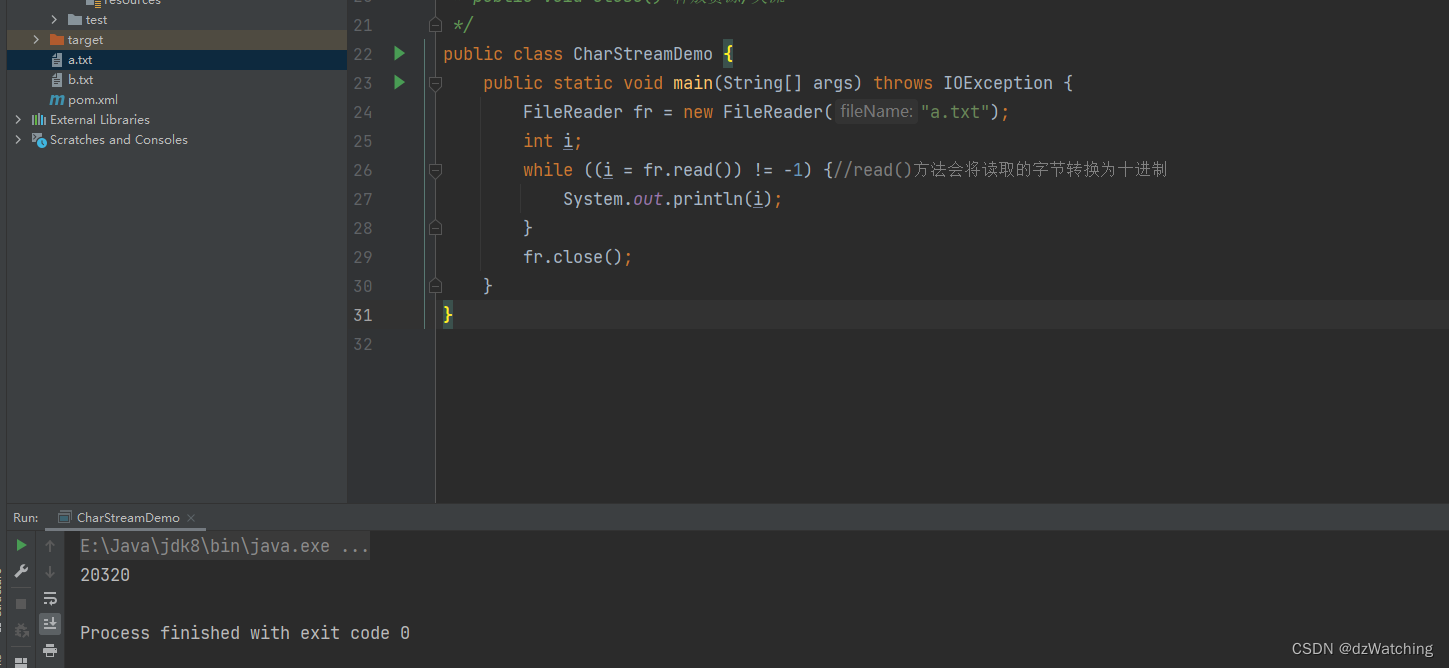
这个20320是怎么得到的?
解答:
使用图中的代码将 你 转为二进制数 100111101100000
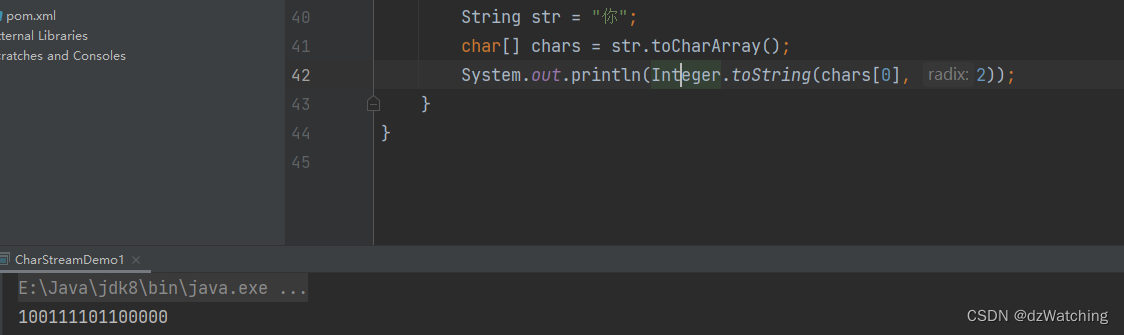

将这个二进制数转换,就得到了20320。
将这段二进制数代入utf-8的编码中
汉字3字节:1110xxxx 10xxxxxx 10xxxxxx
得到:11101001 10111011 10000000
自行了解utf-8编码吧
FileReader
无参的read()方法
/**
* @author Watching
* * @date 2023/5/21
* * Describe:
* 第一步:创建对象
* public FileReader(File file)
* 创建字符输入流关联本地文件
* public FileReader(String pathname)创建 字符输入流关联本地文件
* 第二步:读取数据
* public int read()
* 读取数据,读到末尾返回-1
* public int read( char[] buffer) 读取多个数据,读到末尾返回-1
* 第三步:释放资源
* public void close() 释放资源/关流
*/
public class CharStreamDemo {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("a.txt");
int i;
while ((i = fr.read()) != -1) {//read()方法会将读取的字节转换为十进制
System.out.println((char) i);
}
fr.close();
}
}
带参的read(char[] c)方法
/**
* @author Watching
* * @date 2023/5/21
* * Describe:
* 第一步:创建对象
* public FileReader(File file)
* 创建字符输入流关联本地文件
* public FileReader(String pathname)创建 字符输入流关联本地文件
* 第二步:读取数据
* public int read()
* 读取数据,读到末尾返回-1
* public int read( char[] buffer) 读取多个数据,读到末尾返回-1
* 第三步:释放资源
* public void close() 释放资源/关流
*/
public class CharStreamDemo1 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("a.txt");
char[] chars = new char[2];
int len;
while ((len = fr.read(chars)) != -1) {
System.out.print(new String(chars,0,len));
}
}
}
FileWriter
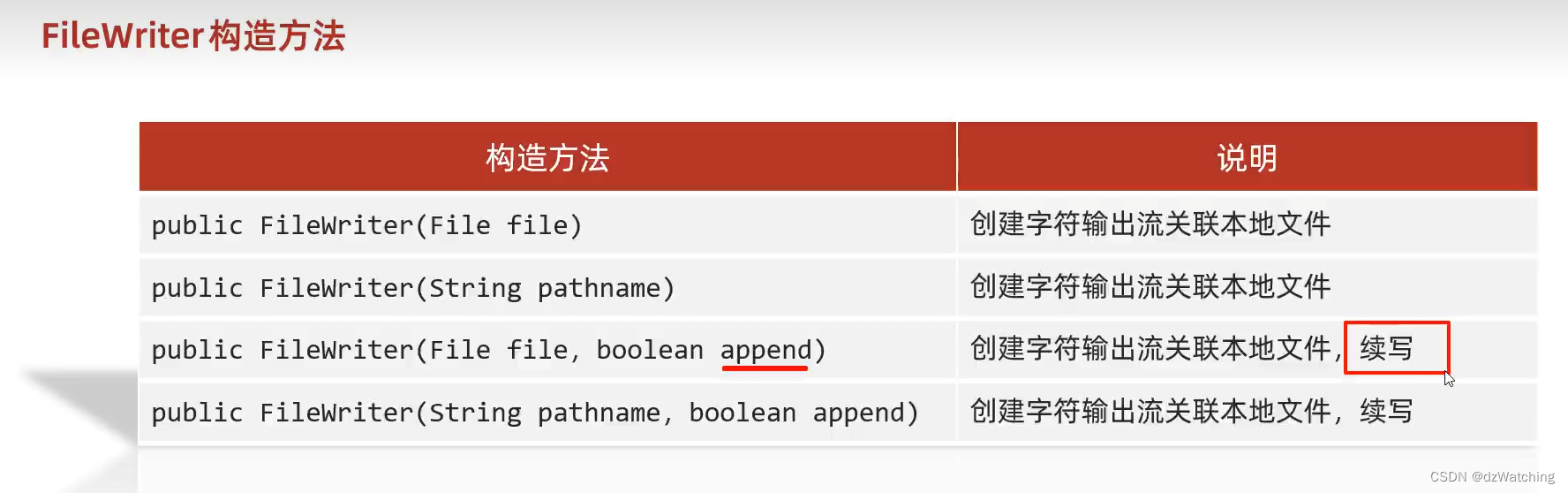
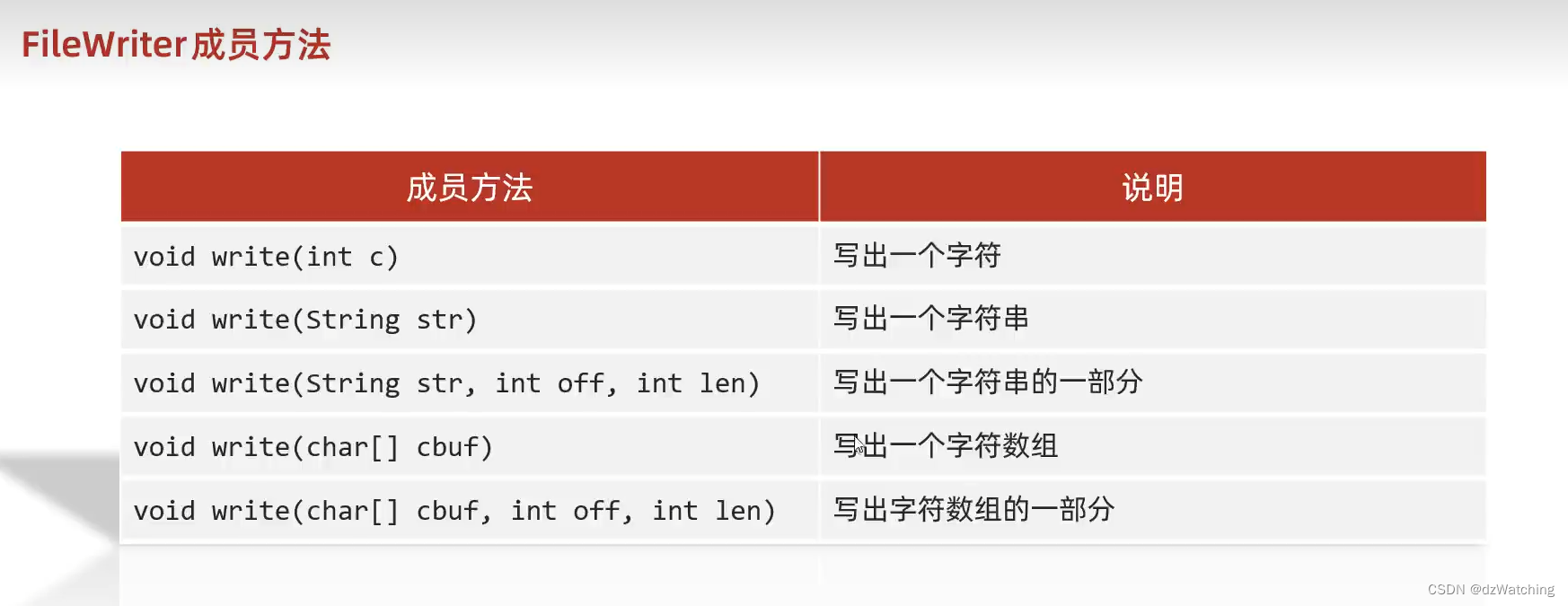

代码演示,还有其它的成员方法不做展示
/**
* @author Watching
* * @date 2023/5/21
* * Describe:
* 第一步:创建对象
* public FileReader(File file)
* 创建字符输入流关联本地文件
* public FileReader(String pathname)创建 字符输入流关联本地文件
* 第二步:读取数据
* public int read()
* 读取数据,读到末尾返回-1
* public int read( char[] buffer) 读取多个数据,读到末尾返回-1
* 第三步:释放资源
* public void close() 释放资源/关流
*/
public class CharStreamDemo1 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("a.txt");
FileWriter fw = new FileWriter("b.txt");
char[] chars = new char[2];
int len;
//read() 读取数据,解码,转为十进制
//read(chars) 读取数据,解码,转为十进制,强转三步合并,把强转之后的字符放到数组中
while ((len = fr.read(chars)) != -1) {
System.out.print(new String(chars,0,len));
fw.write(chars,0,len);
// fw.flush();//每次循环都将缓冲数组中的数据写出
fw.write(97+"");//如果写出的是一个int型的数字,它会被转成字符集中对应的字符,如果就是要原样输出数字,可以加一个空字符串。
}
fw.close();
fr.close();
}
}
字符流的底层原理
字符流的底层存在一个缓冲数组,大小为8192(字节流没有缓冲数组)
字符输入流详解
字符输出流详解
练习题:

关键点:
①目的地文件夹
②源文件存在目录需要递归
/**
* @author Watching
* * @date 2023/5/22
* * Describe:
*/
public class test1 {
public static void main(String[] args) throws IOException {
copyDir(new File("D:\\test\\source"),new File("D:\\test\\dest"));
}
/**
*
* @param source 源文件/目录
* @param dest 目的地
* @throws IOException
*/
private static void copyDir(File source, File dest) throws IOException {
dest.mkdirs();//防止出现FileNotFoundException
DirectoryStream<Path> paths = Files.newDirectoryStream(Paths.get(source.getPath()));
for (Path path : paths) {
File file = new File(String.valueOf(path));
if(file.isFile()){//如果是文件,则直接拷贝
FileInputStream fis = new FileInputStream(file);
FileOutputStream fos = new FileOutputStream(new File(dest,file.getName()));
byte[] b = new byte[1024];
int len;
while((len = fis.read(b)) != -1){
fos.write(b,0,len);
}
fos.close();
fis.close();
}else {
//递归子目录
copyDir(file,new File(dest,file.getName()));
}
}
}
}

提示:使用异或,100 ^ 10 = 110; 110 ^ 10 = 100;
(是换算成二进制做的)
九、缓冲流
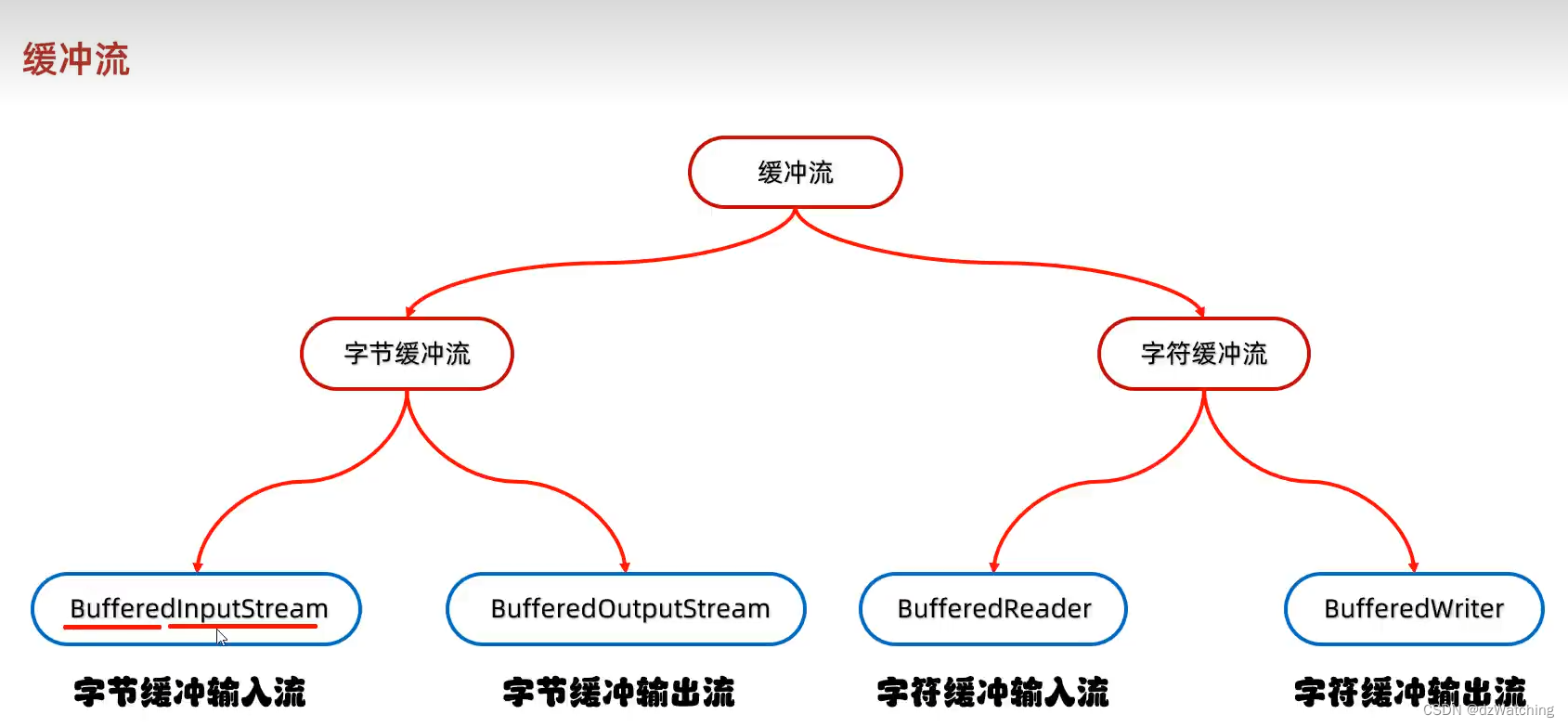
字节缓冲流

练习:

/**
* @author Watching
* * @date 2023/5/22
* * Describe:
* 需求:
* 利用字节缓冲流拷贝文件
*
*/
public class BufferedStreamDemo {
public static void main(String[] args) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("a.txt"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("b.txt"));
int len;
while ((len = bis.read())!= -1){
bos.write(len);
}
bos.close();
bis.close();
}
}
/**
* @author Watching
* * @date 2023/5/22
* * Describe:
* 需求:
* 利用字节缓冲流拷贝文件,使用字节数组一次性读取多个字节
*/
public class BufferedStreamDemo2 {
public static void main(String[] args) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("a.txt"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("b.txt"));
int len;
byte[] bytes = new byte[1024];
while ((len = bis.read(bytes))!= -1){
bos.write(bytes,0,len);
}
bos.close();
bis.close();
}
}
字节缓冲流提高效率的原理:
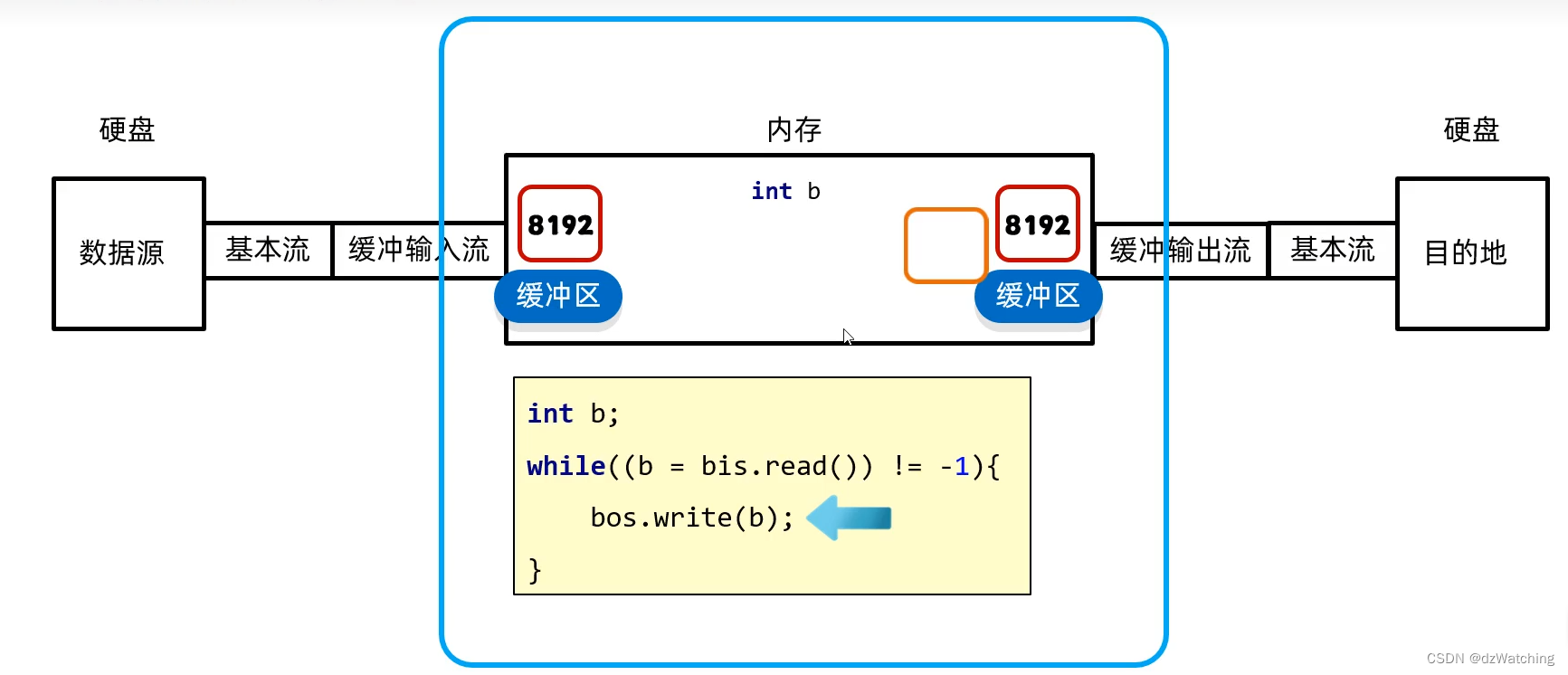
字节缓冲流是对基本流做了包装。
以输入流为例:在硬盘读取数据的时候,还是基本流在读取,不过与只用基本流相比,加了缓冲流的基本流可以一次性读8192个字节,因为缓冲流的底层维护了以一个大小为8192的缓冲数组,所以提高了速度。当缓冲区填满之后,它就会与缓冲输出流的缓冲区进行交换,因为是在内存中,所以会快很多,然后缓冲输出流的缓冲区填满之后,再一次性写出,这样就减少了写出的io操作。
(减少了操作系统cpu从用户态到核心态的切换)
=================疑问
我使用了一个大小为3个g的视频作为源文件,分别用普通流和缓冲流进行拷贝,下面是代码:
普通流:
/**
* @author Watching
* * @date 2023/5/19
* * Describe:
* 使用read(Byte[] byte)可以一次性读取多个字节
*/
public class ByteStreamDemo5 {
public static void main(String[] args) throws IOException {
long l = System.currentTimeMillis();
FileInputStream fis = new FileInputStream("a.mp4");
FileOutputStream fos = new FileOutputStream("b.mp4");
byte[] bytes = new byte[8192];
int len;
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
fos.close();
fis.close();
long l1 = System.currentTimeMillis();
System.out.println(l1 - l);
}
}
缓冲流:
/**
* @author Watching
* * @date 2023/5/22
* * Describe:
* 需求:
* 利用字节缓冲流拷贝文件,使用字节数组一次性读取多个字节
*/
public class BufferedStreamDemo2 {
public static void main(String[] args) throws IOException {
long l = System.currentTimeMillis();
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("a.mp4"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("b.mp4"));
int len;
byte[] bytes = new byte[8192];
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
}
bos.close();
bis.close();
long l1 = System.currentTimeMillis();
System.out.println(l1 - l);
}
}
分别对这两端代码进行测试,结果为:
普通流:17222ms、16455ms、15842ms
缓冲流:17533ms、14822ms、17523ms
可以看到差别不大,所以我暂时认为,缓冲流提升速度的原因是因为底层维护了一个数组,但是普通流的
read(byte[] b)
方法和
write(byte[] b)
方法也可以达到同样的目的,所以缓冲流的存在可能是还包装了其它方法,提供了便利。
字符缓冲流

字符流本身底层就维护了一个8192大小的数组,所以字符缓冲流的提升并不大,但是这并不意味着我们就可以不用学习这个高级流了。
字符缓冲流还为我们包装了两个重要的方法:
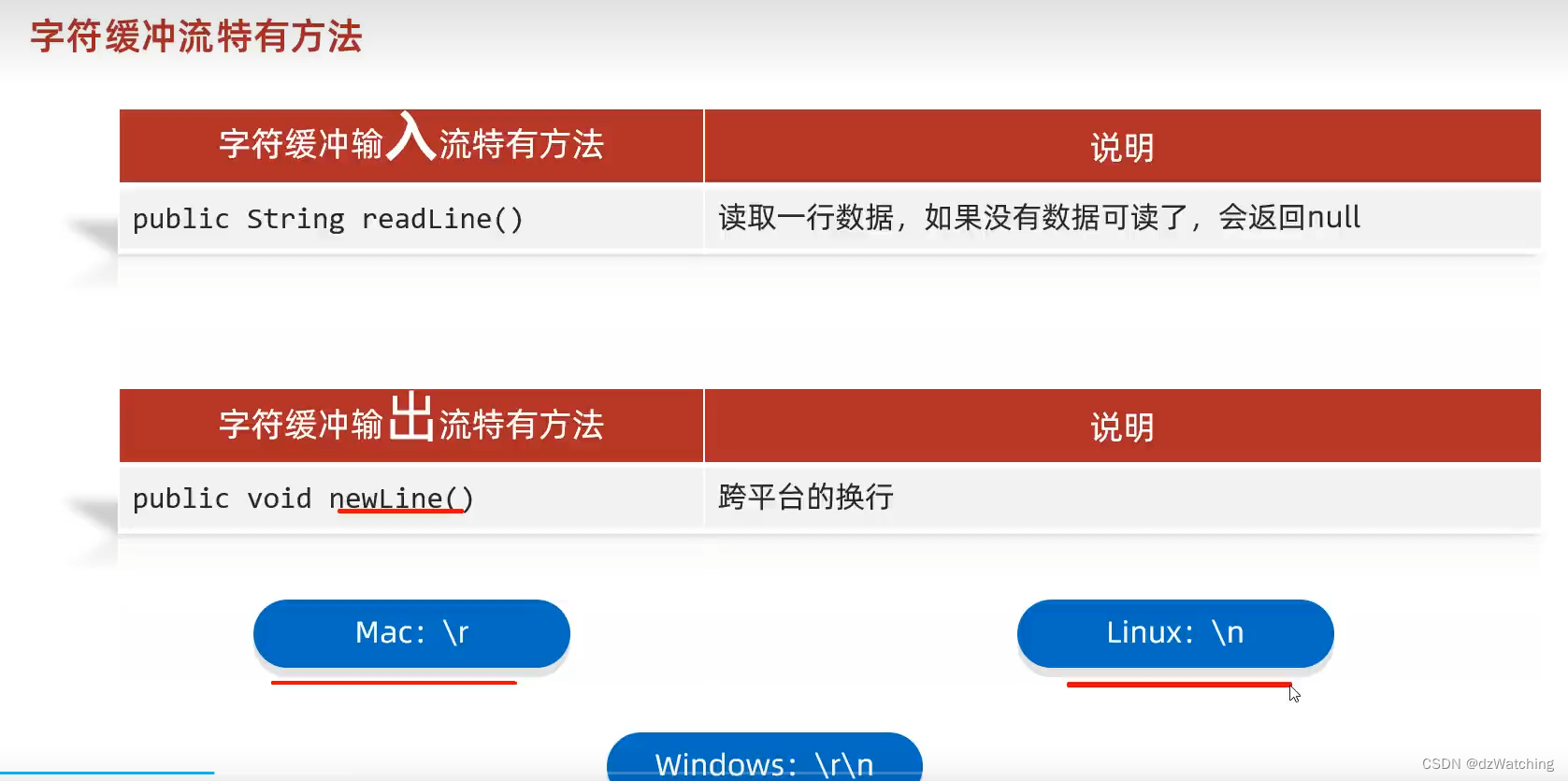
这个newLine()方法底层会先判断操作系统的类别,输出时根据操作系统对换行符做处理,就不用我们修改代码适配每个操作系统的换行符了。
字符缓冲流读入
/**
* @author Watching
* * @date 2023/5/23
* * Describe:
* 字符缓冲输入流
*/
public class BufferedStreamDemo4 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("a.txt"));
/*
readLine()方法每次读取都会读取一整行的数据,直到遇见回车换行符,但是它并不会将回车换行符读入。
所以需要我们手动换行。
*/
// String line1 = br.readLine();
// System.out.println(line1);
// String line2 = br.readLine();
// System.out.println(line2);
// String line3 = br.readLine();
// System.out.println(line3);
//循环读入的方法
String s;
while((s = br.readLine()) != null){
System.out.println(s);
}
br.close();
}
}
字符缓冲流输出
/**
* @author Watching
* * @date 2023/5/23
* * Describe:字符缓冲输出流
*/
public class BufferedStreamDemo5 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bw = new BufferedWriter(new FileWriter("b.txt", true));
String line1 = br.readLine();
bw.write(line1);
bw.newLine();//字符缓冲输出流的newLine()方法会帮我们对文件内容换行,所以搭配readLine()使用就可以完成基本拷贝功能
String line2 = br.readLine();
bw.write(line2);
bw.newLine();
String line3 = br.readLine();
bw.write(line3);
bw.newLine();
bw.close();
br.close();
}
}
总结

===============前面忘记的细节
如果使用了任意输出流读取了一个文件,那么这个文件是无法被输入流读取到数据的,除非输出流的append参数为true
以下面的代码举例:
/**
* @author Watching
* * @date 2023/5/23
* * Describe:
*/
public class test {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream("c.txt");
FileOutputStream fileOutputStream = new FileOutputStream("c.txt");
int read = fileInputStream.read();//这里的read是读不到文件内容的,因为文件内容在创建输出流的时候被清空了
System.out.println(read);
fileOutputStream.close();
fileInputStream.close();
}
}
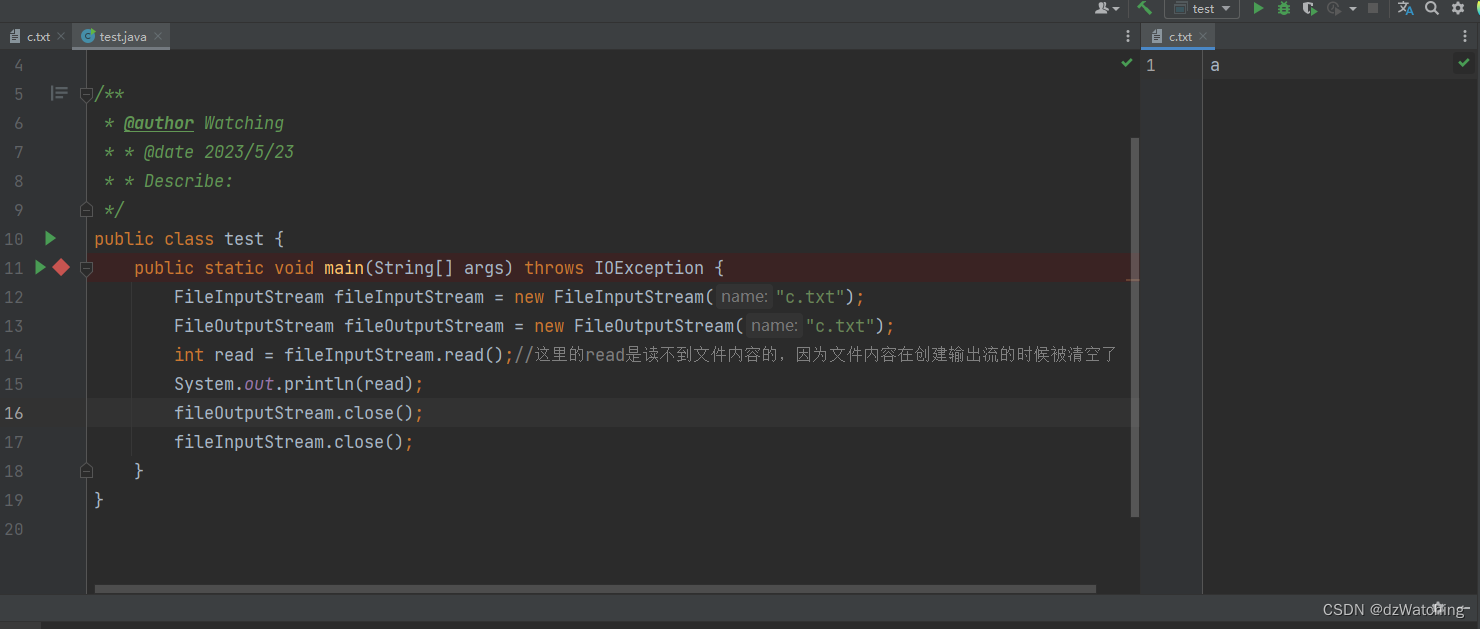
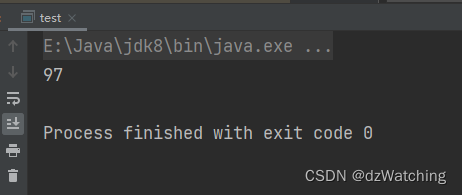
输出结果为:
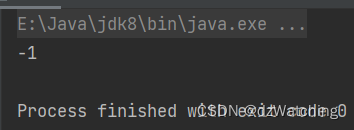
设置输出流的append参数为true
/**
* @author Watching
* * @date 2023/5/23
* * Describe:
*/
public class test {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream("c.txt");
FileOutputStream fileOutputStream = new FileOutputStream("c.txt",true);
int read = fileInputStream.read();//这里的read是读不到文件内容的,因为文件内容在创建输出流的时候被清空了
System.out.println(read);
fileOutputStream.close();
fileInputStream.close();
}
}
输出结果为:
将输出流的位置放在输入流读取之后
/**
* @author Watching
* * @date 2023/5/23
* * Describe:
*/
public class test {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream("c.txt");
int read = fileInputStream.read();//这里的read是读不到文件内容的,因为文件内容在创建输出流的时候被清空了
FileOutputStream fileOutputStream = new FileOutputStream("c.txt");
System.out.println(read);
fileOutputStream.close();
fileInputStream.close();
}
}
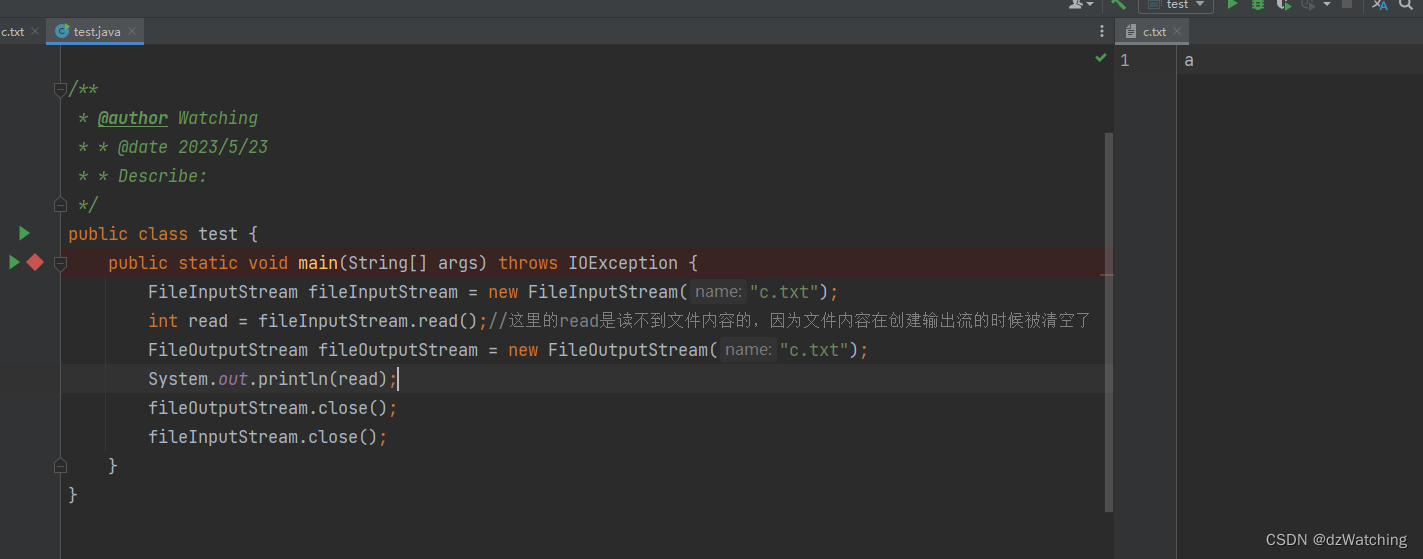
输出结果为:
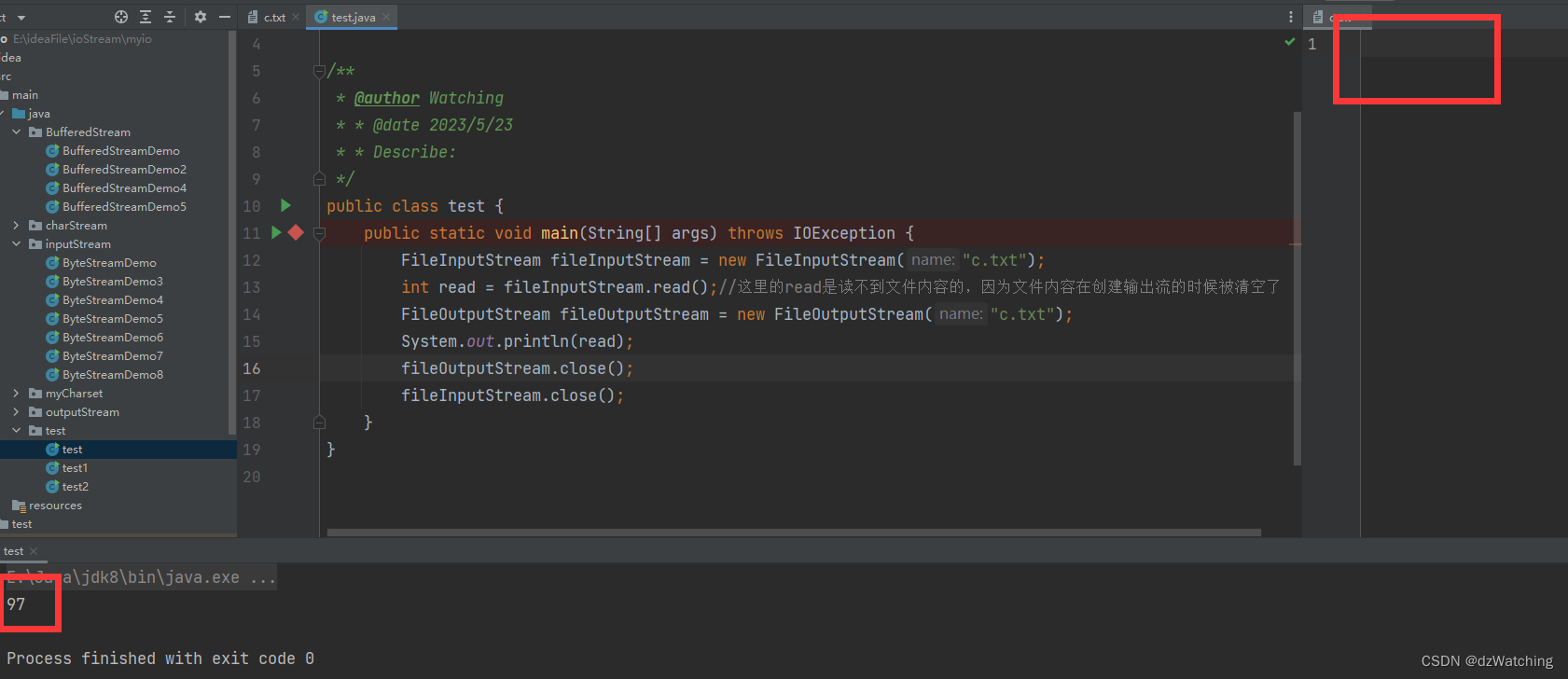
发现这样就能读取到内容,但是因为我们创建输出流,但是没有输出内容,而且没有将append参数设置为true,所以文件内容被清除了。
所以,输出流创建的位置很重要,创建在不合适的位置可能会导致输入流读取不到数据而出错。