关于Spring Cloud + Dubbo的链路追踪及traceId方案及思考(1)
背景
在大型的微服务中,一个请求可能会经过多个服务,而且服务分布在成百上千的服务器中。一旦出问题或者需要做请求响应时间的优化,我们到底如何快速定位和分析问题出现在哪个服务呢?
单个请求到响应都会形成一条服务调用链路。
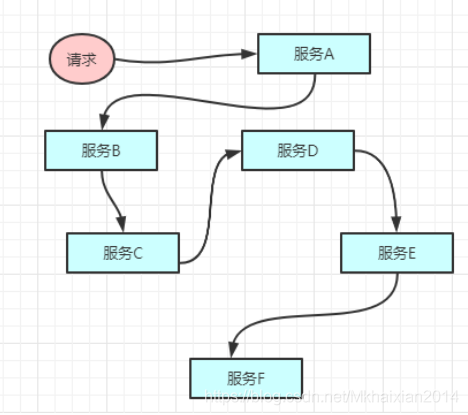
随着服务的越来越多,对调用链的分析会越来越复杂。它们之间的调用关系也许如下:

我们需要一些工具帮我们分析链路的行为和性能问题,这些工具就是APM(应用性能管理)工具。目前主流的微服务APM工具有Zipkin、Pinpoint、SkyWalking。
-
Zipkin是Twitter开源的调用链分析工具,目前基于Spring Cloud Sleuth得到了广泛的使用,特点是轻量,使用部署简单。缺点是对代码有侵入性。
-
Pinpoint是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能强大,接入端无代码侵入。
-
SkyWalking是国内开源的基于字节码注入的调用链分析以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前使用厂商最多,版本更新较快,已成为 Apache 基金会顶级项目。
优缺点及性能分析请参考:
分布式服务监控zipkin、Pinpoint、SkyWalking分析
实现方案
1. SkyWalking作为项目中的APM工具
参考
分布式服务监控zipkin、Pinpoint、SkyWalking分析
的分析,从性能、功能、界面、活跃度来看,我选择SkyWalking作为我项目中的APM工具。
1.1 SkyWalking服务端搭建
-
首先需要本地有ElasticSearch环境,因为SkyWalking官方推荐使用ES作为存储方案。具体ES搭建我使用docker搭建,大家可以根据自己的需要,参考网上资料搭建。
docker-compose.yml
version: '3.3' services: elasticsearch: image: wutang/elasticsearch-shanghai-zone:6.3.2 container_name: elasticsearch restart: always ports: - 9200:9200 - 9300:9300 environment: cluster.name: elasticsearch -
运行SkyWalking服务端两种方式
(1)Linux直接安装SkyWalking服务端-
在Linux安装SkyWalking需要jdk的运行环境,官方下载地址http://skywalking.apache.org/downloads/,因为我们的ES版本是6的,所以选择SkyWalking的6.6.0版本的linux版本下载
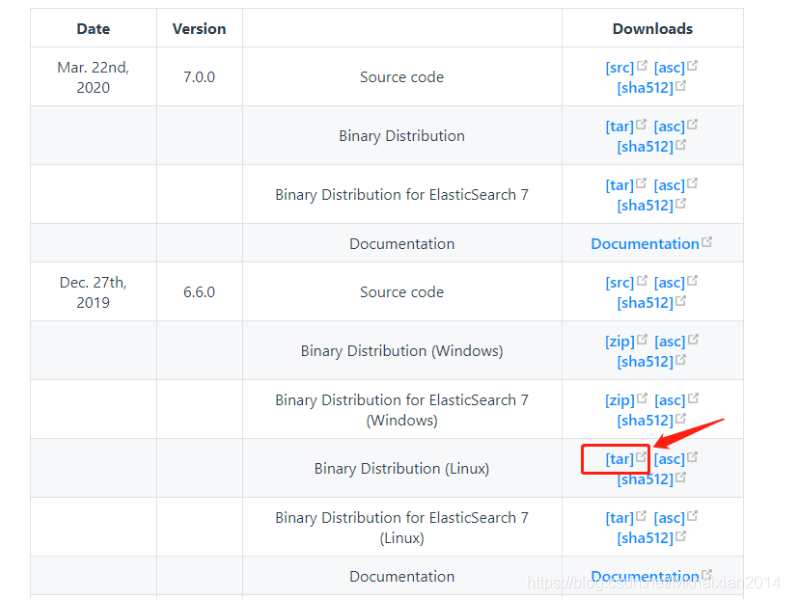
- 修改配置及启动
- 下载完成后解压缩,进入 apache-skywalking-apm-bin/config 目录并修改 application.yml 配置文件
-
在Linux安装SkyWalking需要jdk的运行环境,官方下载地址http://skywalking.apache.org/downloads/,因为我们的ES版本是6的,所以选择SkyWalking的6.6.0版本的linux版本下载
storage:
elasticsearch:
nameSpace: ${SW_NAMESPACE:""}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:192.168.160.105:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
# trustStorePath: ${SW_SW_STORAGE_ES_SSL_JKS_PATH:"../es_keystore.jks"}
# trustStorePass: ${SW_SW_STORAGE_ES_SSL_JKS_PASS:""}
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:2}
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:0}
# # Those data TTL settings will override the same settings in core module.
recordDataTTL: ${SW_STORAGE_ES_RECORD_DATA_TTL:7} # Unit is day
otherMetricsDataTTL: ${SW_STORAGE_ES_OTHER_METRIC_DATA_TTL:45} # Unit is day
monthMetricsDataTTL: ${SW_STORAGE_ES_MONTH_METRIC_DATA_TTL:18} # Unit is month
# # Batch process setting, refer to https://www.elastic.co/guide/en/elasticsearch/client/java-api/5.5/java-docs-bulk-processor.html
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:1000} # Execute the bulk every 1000 requests
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10} # flush the bulk every 10 seconds whatever the number of requests
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
# elasticsearch7:
# nameSpace: ${SW_NAMESPACE:""}
# clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
# protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
# trustStorePath: ${SW_SW_STORAGE_ES_SSL_JKS_PATH:"../es_keystore.jks"}
# trustStorePass: ${SW_SW_STORAGE_ES_SSL_JKS_PASS:""}
# user: ${SW_ES_USER:""}
# password: ${SW_ES_PASSWORD:""}
# indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:2}
# indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:0}
# # Those data TTL settings will override the same settings in core module.
# recordDataTTL: ${SW_STORAGE_ES_RECORD_DATA_TTL:7} # Unit is day
# otherMetricsDataTTL: ${SW_STORAGE_ES_OTHER_METRIC_DATA_TTL:45} # Unit is day
# monthMetricsDataTTL: ${SW_STORAGE_ES_MONTH_METRIC_DATA_TTL:18} # Unit is month
# # Batch process setting, refer to https://www.elastic.co/guide/en/elasticsearch/client/java-api/5.5/java-docs-bulk-processor.html
# bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:1000} # Execute the bulk every 1000 requests
# flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10} # flush the bulk every 10 seconds whatever the number of requests
# concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
# resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
# metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
# segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
# h2:
# driver: ${SW_STORAGE_H2_DRIVER:org.h2.jdbcx.JdbcDataSource}
# url: ${SW_STORAGE_H2_URL:jdbc:h2:mem:skywalking-oap-db}
# user: ${SW_STORAGE_H2_USER:sa}
# metadataQueryMaxSize: ${SW_STORAGE_H2_QUERY_MAX_SIZE:5000}
# mysql:
# properties:
# jdbcUrl: ${SW_JDBC_URL:"jdbc:mysql://localhost:3306/swtest"}
# dataSource.user: ${SW_DATA_SOURCE_USER:root}
# dataSource.password: ${SW_DATA_SOURCE_PASSWORD:root@1234}
# dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}
# dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}
# dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}
# dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}
- 启动/apache-skywalking-apm-bin/bin/startup.sh
(2)docker安装SkyWalking服务端(比较方便,推荐)
docker-compose.yml如下
version: '3.3'
services:
oap:
image: apache/skywalking-oap-server:6.6.0-es6
container_name: skywalking-oap
restart: always
ports:
- 11800:11800
- 12800:12800
environment:
- SW_STORAGE=elasticsearch #Es的存储
- SW_STORAGE_ES_CLUSTER_NODES=192.168.160.105:9200 # Es的节点地址,配置es的地址
- TZ=Asia/Shanghai #设定东八区的城市,防止Oap记录数据时用0时区
ui:
image: apache/skywalking-ui:6.6.0
container_name: skywalking-ui
depends_on:
- oap
links:
- oap
restart: always
ports:
- 8080:8080 #默认8080端口,这里设置18080映射到宿主机,可修改
environment:
collector.ribbon.listOfServers: oap:12800
1.2项目中Skywalking客户端使用
-
Java Agent 探针,参考官网
Setup java agent
- (1)解压之前下载的SkyWalking包apache-skywalking-apm-bin,在agent目录下找到skywalking-agent.jar。复制全路径,我本地为E:\apache-skywalking-apm-bin\agent\skywalking-agent.jar
- (2)在idea中配置VM options:
-javaagent:E:\apache-skywalking-apm-bin\agent\skywalking-agent.jar
-Dskywalking.agent.service_name=light-demo-center
-Dskywalking.collector.backend_service=192.168.160.105:11800
- (3)启动项目后,多次发出项目请求,到SkyWalking服务端UI可以看到如下效果:
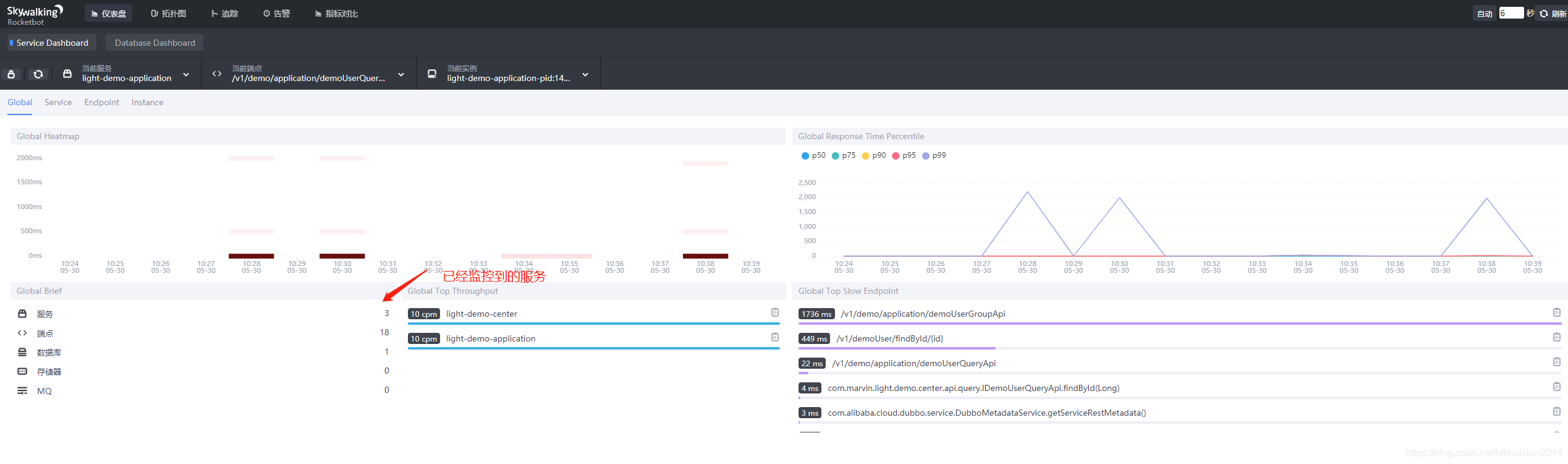
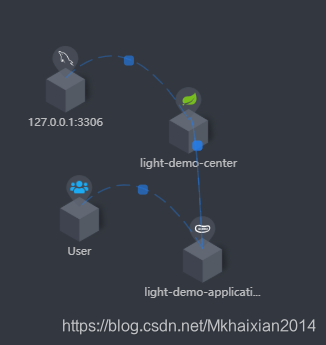
具体的SkyWalking使用可以参考
SkyWalking官网
下一篇,我们讲解如何在日志中查找同一条链路的日志吧,敬请期待。