
WGAN & WGAN-GP:
1.资料参考:
互怼的艺术:从零直达WGAN-GP – 科学空间|Scientific Spaceskexue.fm

郑华滨:令人拍案叫绝的Wasserstein GANzhuanlan.zhihu.com
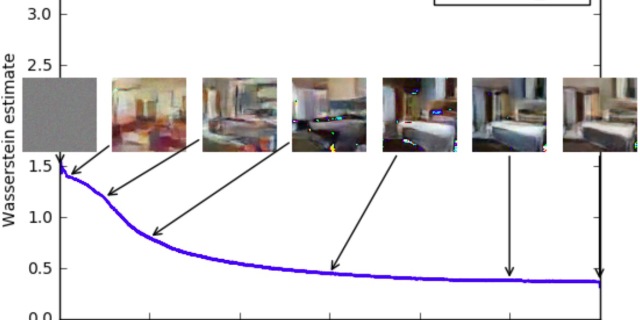
2.code参考:
https://github.com/bojone/gan/blob/master/mnist_gangp.pygithub.com
3.感悟:
原始GAN的问题:
判别器越好,生成器梯度消失越严重。
根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布
与生成分布
之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化
和
之间的JS散度。
根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布
与生成分布
之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化
和
之间的JS散度。
回过头来看第一句话,“当
版权声明:本文为weixin_36084095原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。