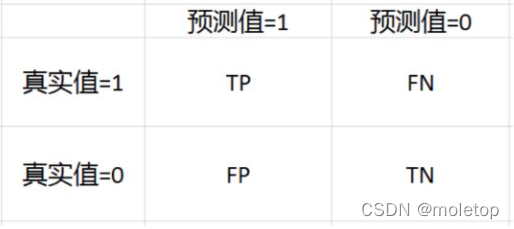
.评价指标
常用指标
(分类和回归):
-
准确率:Accuracy=(TP+TN)/(TP+FP+TN+FN)
-
精确率(查准)Precision=TP/(TP+FP),召回率(查全)Recall=TP/(TP+FN)
-
F1 score(Fx 分数,x为召回率和精确率的比值)
F1 score=2·Precision·Recall/(Precision+Recall)
综合考量,召回率Recall和精确率Precision的调和平均,只有在召回率Recall和精确率Precision都高的情况下,F1 score才会很高。
-
ROC和PR曲线
-
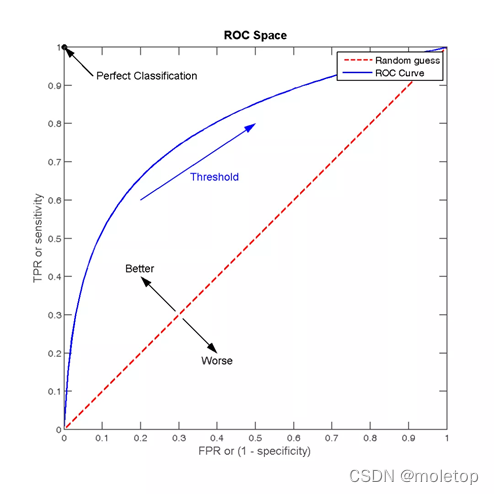
ROC曲线可以用于评价一个分类器在不同阈值下的表现情况。在ROC曲线中,每个点的横坐标是(FPR),纵坐标是TPR,描绘了分类器在True Positive和False Positive间的平衡。
-
TPR=TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。
FPR=FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例,FPR越大,预测正类中实际负类越多
-
AUC(Area Under Curve)为ROC曲线下的面积,它表示的就是一个概率,这个面积的数值不会大于1。随机挑选一个正样本以及一个负样本,AUC表征的就是有多大的概率,分类器会对正样本给出的预测值高于负样本。面积越大越好,大于0.5才有意义,1是完美预测,小于0.5表示连随机预测都算不上。
-
ROC的绘制:
- 假设已经得出一系列样本被划分为正类的概率Score值,按照大小排序。
- 从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于某个样本,其“Score”值为0.6,那么“Score”值大于等于0.6的样本都被认为是正样本,而其他样本则都认为是负样本。
- 每次选取一个不同的threshold,得到一组FPR和TPR,以FPR值为横坐标和TPR值为纵坐标,即ROC曲线上的一点。
-
4个关键的点:
点(0,0):FPR=TPR=0,预测所有的样本都为负样本;
点(1,1):FPR=TPR=1,预测所有的样本都为正样本;
点(0,1):FPR=0, TPR=1,此时FN=0且FP=0,所有的样本都正确分类;
点(1,0):FPR=1,TPR=0,此时TP=0且TN=0,最差分类器,避开了所有正确答案
-
当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变
比如负样本的数量增加到原来的10倍,TPR不受影响,FPR的各项也是成比例的增加,并不会有太大的变化。所以不均衡样本问题通常选用ROC作为评价标准。

-
-
PR曲线:
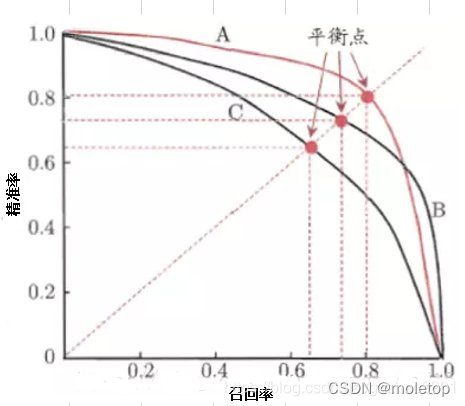
- 画法和ROC一样,取不同的阈值,计算所有样本下的p和r.
- F1 = 2 * P * R /( P + R )。平衡点(BEP)是P=R时的取值(斜率为1)
-
-
MAE(平均绝对误差)和MSE(均方误差)
- MSE收敛快,对异常值敏感。因为它的惩罚是平方的,所以异常值的loss会非常大
- MAE相较于MSE,没有平方项的作用,对所有训练数据惩罚力度相同。可能由于梯度值小,使模型陷入局部最优
检索和推荐指标:
-
IOU(在目标检测,图像分割领域中,定义为两个矩形框面积的交集和并集的比值,IoU=A∩B/A∪B).如果完全重叠,则IoU等于1,是最理想的情况。一般在检测任务中,IoU大于等于0.5就认为召回,如果设置更高的IoU阈值,则召回率下降,同时定位框也越更加精确。
-
AP和mAP
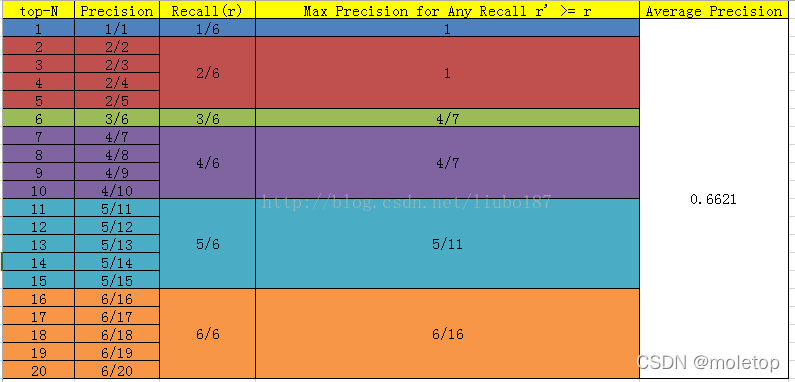
AP:average precision,对分数排好序之后,从rank1到rankn。对应每个召回节点 最大的精确率,然后取平均得到AP。
注意:AP之前的计算发明方法:令N是所有id,如果从top-1到top-N都统计一遍,得到了对应的precision和recall,以recall为横坐标,precision为纵坐标,则得到了检测中使用的precision-recall曲线,虽然整体趋势和意义与分类任务中的precision-recall曲线相同,计算方法却有很大差别。分类里的pr是设置不同的阈值来确定所有样本的下p和r,这里的AP是确定阈值后,从top1到topN都统计一遍,获取当前topx的p和r。
MAP:进行N次检索的结果平均,一般会把所有类别都检索一遍来算,就像多标签的图像分类计算方式一样。
AP衡量的是学出来的模型在一个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏。
-
MRR(mean reciprocal rank)平均倒数排名
- RR,倒数排名,指检索结果中第一个相关文档的排名的倒数。
-
MRR多个查询的倒数排名的均值,公式如下:rank
i
表示第 i 个查询的第一个相关文档的排名。
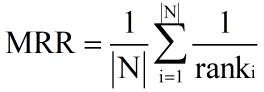
-
NDCG(推荐也用)
-
CG,Cumulative Gain)累计效益, k 表示 k 个文档组成的集合,rel 表示第 i 个文档的相关度

-
DCG(Discounted Cumulative Gain)在 CG 的计算中没有考虑到位置信息,例如检索到三个文档的相关度依次为(3,-1,1)和(-1,1,3),根据 CG 的计算公式得出的排名是相同的,但是显然前者的排序好一些。所以需要在 CG 计算的基础上加入位置信息的计算,引入折扣因子。根据位置的递增,对应的价值递减。
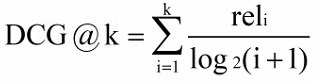
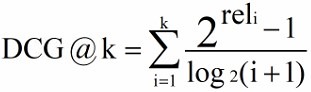
-
IDCG(ideal DCG)理想情况下,按照相关度从大到小排序,然后计算 DCG 可以取得最大值情况。其中 |REL| 表示文档按照相关度从大到小排序,取前 k 个文档组成的集合。
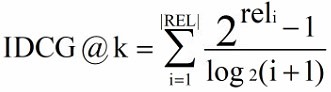
-
NDCG(Normalized DCG)
由于每个查询所能检索到的结果文档集合长度不一致,k 值的不同会影响 DCG 的计算结果。所以不能简单的对不同查询的 DCG 结果进行平均,需要先归一化处理。NDCG 就是利用 IDCG 进行归一化处理,表示当前的 DCG 与理想情况下的 IDCG 相差多大。
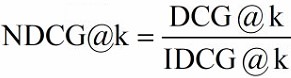
- Hit ratio分母是所有的测试集合,分子是每个用户前K个中属于测试集合的个数的总和,该指标衡量是召回率,该指标越大越好。
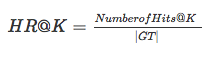
-