随着计算机的周边外设越来越丰富,设备管理已经成为现代操作系统的一项重要任务,这对于Linux来说也是同样的情况。每次Linux内核新版本的发布,都会伴随着一批设备驱动进入内核。在Linux内核里,驱动程序的代码量占有了相当大的比重。下图是我在网络上搜索到的一幅Linux内核代码量的统计图,对应的内核版本是2.6.29。
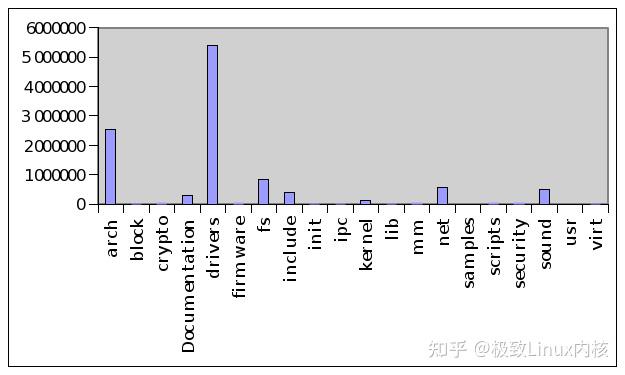
我们可以很明显的看到,在Linux内核中驱动程序的比例已经非常高了。
Linux 2.6内核最初为了应付电源管理的需要,提出了一个设备模型来管理所有的设备。在物理上,外设之间是有一种层次关系的,比如把一个U盘插到笔记本上,实际上这个U盘是接在一个USB Hub上,USB Hub又是接在USB 2.0 Host Controller (EHCI)上,最终EHCI又是一个挂在PCI Bus上的设备。这里的一个层次关系是:PCI->EHCI->USB Hub->USB Disk。如果操作系统要进入休眠状态,首先要逐层通知所有的外设进入休眠模式,然后整个系统才可以休眠。因此,需要有一个树状的结构可以把所有的外设组织起来。这就是最初建立Linux设备模型的目的。
当然,Linux设备模型给我们带来的便利远不止如此。既然已经建立了一个组织所有设备和驱动的树状结构,用户就可以通过这棵树去遍历所有的设备,建立设备和驱动程序之间的联系,根据类型不同也可以对设备进行归类,这样就可以更清晰的去“看”这颗枝繁叶茂的大树。另外,Linux驱动模型把很多设备共有的一些操作抽象出来,大大减少了重复造轮子的可能。同时Linux设备模型提供了一些辅助的机制,比如引用计数,让开发者可以安全高效的开发驱动程序。达成了以上这些好处之后,我们还得到了一个非常方便的副产品,这就是sysfs—-一个虚拟的文件系统。sysfs给用户提供了一个从用户空间去访问内核设备的方法,它在Linux里的路径是/sys。这个目录并不是存储在硬盘上的真实的文件系统,只有在系统启动之后才会建起来。
下面这个命令可以用来显示sysfs的大致结构:
tree /sys
这个命令的信息量非常大,我就不贴出来了,如果有兴趣的话可以自己动手实验一下。
我们来看看第一层目录结构:
/sys
|– block
|– bus
|– class
|– dev
|– devices
|– firmware
|– fs
|– kernel
|– module
`– power
这里有10个子目录,但并不是说这10个目录代表了10种完全不同的设备类型,实际上这些目录只是给我们提供了如何去看整个设备模型的不同的视角。其实从不同的目录出发都有可能找到同一个设备的。那真正的设备信息到底放在哪里呢?看看目录的名称就应该能猜到,对,就是devices子目录,Linux的所有设备都可以在这个目录里找到。这里是一个大杂烩,虽然五脏俱全但我们却无从下手。这里还是以U盘为例,插上U盘之后,在devices目录里如何找到这支U盘呢?真得很难办到。但是如果知道这个U盘在系统里的设备文件名(暂且假设为sdb),那就可以从block目录着手。
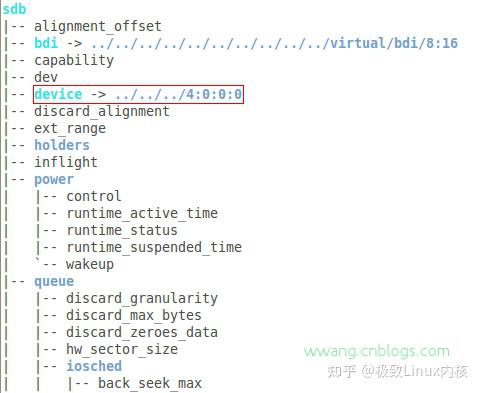
透过block目录,我们很容易就可以找到这个U盘设备,符号链接device正是指向devices目录下的位置。
到这里,我们总结一下/sys目录下各个子目录的作用。block目录是从块设备的角度来组织设备;bus目录是从系统总线这个角度来组织设备,比如PCI总线或者USB总线;class目录把看问题的视角提高到了类别的高度,比如PCI设备或者USB设备等;dev目录的视角是设备节点;devices目录在前面提到了,这里是所有设备的大本营;firmware目录包含了一些比较低阶的子系统,比如ACPI、EFI等;fs目录里看到的是系统支持的所有文件系统;kernel目录下包含的是一些内核的配置选项;modules目录下包含的是所有内核模块的信息,内核模块实际上和设备之间是有对应关系的,通过这个目录顺藤摸瓜找到devices或者反过来都是可以做到的;power目录存放的是系统电源管理的数据,用户可以通过它来查询目前的电源状态,甚至可以直接“命令”系统进入休眠等省电模式。
sysfs正是用户和内核设备模型之间的一座桥梁,通过这个桥梁我们可以从内核中读取信息,也可以向内核里写入信息。
在Linux里也可以找到一些图形化的工具来查询设备信息。比如GNOME下基于HAL的Device Manager:

或者KDE下基于Solid的KInfoCenter:

这些图形化的工具提供了更加直观的方式来访问设备,但是它们的提供的信息还不够全面,而且没有向内核设备写数据的功能。
如果具体到某一类型的设备,Linux下还有一些专用的工具可以使用。比如面向PCI设备的pciutils,面向USB设备的usbutils,以及面向SCSI设备的lsscsi等。对于Linux开发者来说,有时使用这些专用的工具更加方便。
我们如果要写程序来访问sysfs,可以像读写普通文件一样来操作/sys目录下的文件,或者,也可以使用libsysfs。不过需要注意的是,Linux内核社区并不推荐用libsysfs,因为这个API的更新不够快,赶不上内核的变化。libsysfs已经逐渐背离最初创建它的目标,这个lib带来的问题似乎比它解决的还要多。当然,如果只是要访问设备,一般很少会直接操作sysfs,它太细节太底层了,大部分情况下可以使用更加方便的DeviceKit或者libudev。
总结一下,主要简单介绍了Linux设备模型的基本概念和虚拟文件系统sysfs。接下来将和大家继续探讨设备模型在内核空间的一些细节。
上面主要介绍了Linux设备模型在用户空间的接口sysfs,用户通过这个接口可以一览内核设备的全貌。接下来将从Linux内核的角度来看一看这个设备模型是如何构建的。
在Linux内核里,kobject是组成Linux设备模型的基础,一个kobject对应sysfs里的一个目录。从面向对象的角度来说,kobject可以看作是所有设备对象的基类,因为C语言并没有面向对象的语法,所以一般是把kobject内嵌到其他结构体里来实现类似的作用,这里的其他结构体可以看作是kobject的派生类。Kobject为Linux设备模型提供了很多有用的功能,比如引用计数,接口抽象,父子关系等等。引用计数本质上就是利用kref实现的。
另外,Linux设备模型还有一个重要的数据结构kset。Kset本身也是一个kobject,所以它在sysfs里同样表现为一个目录,但它和kobject的不同之处在于kset可以看作是一个容器,如果你把它类比为C++里的容器类如list也无不可。Kset之所以能作为容器来使用,其内部正是内嵌了一个双向链表结构struct list_head。
下面这幅图可以用来表示kobject和kset在内核里关系。
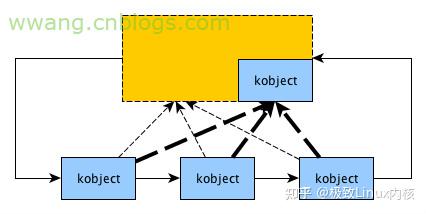
在接下来的篇幅里我们会逐步看到这个关系图在内核里是如何建立的。本文的示例代码可以从
这里
下载,下文中的两个实作都在这个示例代码里。
【文章福利】
小编推荐自己的Linux内核技术交流群:
【977878001】
整理一些个人觉得比较好得学习书籍、视频资料!进群私聊管理领取
内核资料包
(含视频教程、电子书、实战项目及代码)
内核资料直通车:
Linux内核源码技术学习路线+视频教程代码资料
学习直通车:
Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
Kobject
Kobject在Linux内核里的定义如下:
struct kobject {
const char *name;
struct list_head entry;
struct kobject *parent;
struct kset *kset;
struct kobj_type *ktype;
struct sysfs_dirent *sd;
struct kref kref;
unsigned int state_initialized:1;
unsigned int state_in_sysfs:1;
unsigned int state_add_uevent_sent:1;
unsigned int state_remove_uevent_sent:1;
unsigned int uevent_suppress:1;
};在上面我们介绍到内核里的设备之间是以树状形式组织的,在这种组织架构里比较靠上层的节点可以看作是下层节点的父节点,反映到sysfs里就是上级目录和下级目录之间的关系,在内核里,正是kobject帮助我们实现这种父子关系。在kobject的定义里,name表示的是kobject在sysfs中的名字;指针parent用来指向kobject的父对象;Kref大家应该比较熟悉了,kobject通过它来实现引用计数;Kset指针用来指向这个kobject所属的kset,接下来会再详细描述kset的用法;对于ktype,如果只是望文生义的话,应该是用来描述kobject的类型信息。Ktype的定义如下:
struct kobj_type {
void (*release)(struct kobject *kobj);
const struct sysfs_ops *sysfs_ops;
struct attribute **default_attrs;
};函数指针release是给kref使用的,当引用计数为0这个指针指向的函数会被调用来释放内存。sysfs_ops和attribute是做什么用的呢?前文里提到,一个kobject对应sysfs里的一个目录,而目录下的文件就是由sysfs_ops和attribute来实现的,其中,attribute定义了kobject的属性,在sysfs里对应一个文件,sysfs_ops用来定义读写这个文件的方法。Ktype里的attribute是默认的属性,另外也可以使用更加灵活的手段,讲解的重点还是放在default attribute。
下面看一个实作。在这个实作里,我们定义一个内嵌kobject的结构。
struct my_kobj {
int val;
struct kobject kobj;
};最终我们的目的是在内核里构建这样的架构。
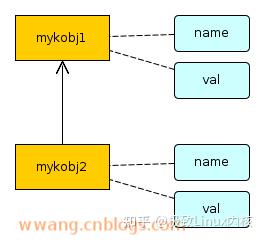
对应sysfs里的目录关系是:
mykobj1/
|– mykobj2
| |– name
| — val |– name — val
这是module_init代码。
static int __init mykobj_init(void)
{
printk(KERN_INFO "mykobj_init\n");
obj1 = kzalloc(sizeof(struct my_kobj), GFP_KERNEL);
if (!obj1) {
return -ENOMEM;
}
obj1->val = 1;
obj2 = kzalloc(sizeof(struct my_kobj), GFP_KERNEL);
if (!obj2) {
kfree(obj1);
return -ENOMEM;
}
obj2->val = 2;
my_type.release = obj_release;
my_type.default_attrs = my_attrs;
my_type.sysfs_ops = &my_sysfsops;
kobject_init_and_add(&obj1->kobj, &my_type, NULL, "mykobj1");
kobject_init_and_add(&obj2->kobj, &my_type, &obj1->kobj, "mykobj2");
return 0;
}这段代码可以分作三个部分。第一部分是分配obj1和obj2并赋值;第二部分是初始化kobj_type变量my_type;第三部分是调用kobject_init_and_add函数来初始化kobject并把它加入到设备模型的体系架构(也就是上文中提到的内核中的那棵树)中。kobject_init_and_add是简化的写法,这个函数也可以分两步完成:kobject_init和kobject_add。
int kobject_init_and_add(struct kobject *kobj, struct kobj_type *ktype,
struct kobject *parent, const char *fmt, ...);
void kobject_init(struct kobject *kobj, struct kobj_type *ktype);
int kobject_add(struct kobject *kobj, struct kobject *parent,
const char *fmt, ...);kobject_init用来初始化kobject结构,kobject_add用来把kobj加入到设备模型之中。在实作中,我们先对obj1进行初始化和添加的动作,调用参数里,parent被赋为NULL,表示obj1没有父对象,反映到sysfs里,my_kobj1的目录会出现在/sys下,obj2的父对象设定为obj1,那么my_kobj2的目录会出现在/sys/my_kobj1下面。
前面提到,kobject也提供了引用计数的功能,虽然本质上是利用kref,但也提供了另外的接口供用户使用。
struct kobject *kobject_get(struct kobject *kobj);
void kobject_put(struct kobject *kobj);kobject_init_and_add和kobject_init这两个函数被调用后,kobj的引用计数会初始化为1,所以在module_exit时要记得用kobject_put来释放引用计数。
我们再回到实作中,看看如何使用ktype。代码里,my_attrs是这样定义的:
struct attribute name_attr = {
.name = "name",
.mode = 0444,
};
struct attribute val_attr = {
.name = "val",
.mode = 0666,
};
struct attribute *my_attrs[] = {
&name_attr,
&val_attr,
NULL,
};
结构体struct attribute里的name变量用来指定文件名,mode变量用来指定文件的访问权限。这里需要着重指出的是,
数组my_attrs的最后一项一定要赋为NULL
,否则会造成内核oops。
sysfs_ops的代码如下:
ssize_t my_show(struct kobject *kobj, struct attribute *attr, char *buffer)
{
struct my_kobj *obj = container_of(kobj, struct my_kobj, kobj);
ssize_t count = 0;
if (strcmp(attr->name, "name") == 0) {
count = sprintf(buffer, "%s\n", kobject_name(kobj));
} else if (strcmp(attr->name, "val") == 0) {
count = sprintf(buffer, "%d\n", obj->val);
}
return count;
}
ssize_t my_store(struct kobject *kobj, struct attribute *attr, const char *buffer, size_t size)
{
struct my_kobj *obj = container_of(kobj, struct my_kobj, kobj);
if (strcmp(attr->name, "val") == 0) {
sscanf(buffer, "%d", &obj->val);
}
return size;
}
struct sysfs_ops my_sysfsops = {
.show = my_show,
.store = my_store,
};读文件会调用my_show,写文件会调用my_store。
最后是module_exit:
static void __exit mykobj_exit(void)
{
printk(KERN_INFO "mykobj_exit\n");
kobject_del(&obj2->kobj);
kobject_put(&obj2->kobj);
kobject_del(&obj1->kobj);
kobject_put(&obj1->kobj);
return;
}
kobject_del的作用是把kobject从设备模型的那棵树里摘掉,同时sysfs里相应的目录也会删除。这里需要指出的是,
释放的顺序应该是先子对象,后父对象
。因为kobject_init_and_add和kobject_add这两个函数会调用kobject_get来增加父对象的引用计数,所以kobject_del需要调用kobject_put来减少父对象的引用计数。在本例中,如果先通过kobject_put来释放obj1,那kobject_del(&obj2->kobj)就会出现内存错误。
在这个实作中,我们建立了两个对象obj1和obj2,obj1是obj2的父对象,如果推广开来,obj1可以有更多的子对象。在Linux内核中,这种架构方式其实并无太大的实际价值,有限的用处之一是在sysfs里创建子目录(Linux内核里有这种用法,这种情况下,直接调用内核提供的kobject_create来实现,不需要自定义数据结构并内嵌kobject),而且,创建子目录也是有其他的办法的。我们知道,Linux设备模型最初的目的是为了方便电源管理,这就需要从上到下的遍历,在这种架构里,通过obj1并无法访问其所有的子对象。这个实作最大的意义在于可以让我们比较清晰的理解kobject如何使用。通常情况下,kobject只需要在叶节点里使用,上层的节点要使用kset。
Kset
Kset的定义如下:
struct kset {
struct list_head list;
spinlock_t list_lock;
struct kobject kobj;
const struct kset_uevent_ops *uevent_ops;
};Kset结构里的kobj表明它也是一个kobject,list变量用来组织它所有的子对象。
我们直接看一个实作。在这个实作里,我们将构建如下的架构。
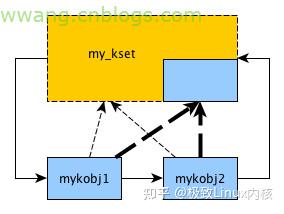
对应sysfs里的目录关系是:
my_kset/
|– mykobj1
| |– name
| — val — mykobj2
|– name
`– val
这个实作和前一个差别很小,下面只简略的引用一些代码。
static int __init mykset_init(void)
{
printk(KERN_INFO "mykset_init\n");
my_kset = kset_create_and_add("my_kset", NULL, NULL);
if (!my_kset) {
return -ENOMEM;
}
// Allocate obj1 and obj2
// ...
obj1->kobj.kset = my_kset;
obj2->kobj.kset = my_kset;
// Init my_type
// ...
kobject_init_and_add(&obj1->kobj, &my_type, NULL, "mykobj1");
kobject_init_and_add(&obj2->kobj, &my_type, NULL, "mykobj2");
return 0;
}
static void __exit mykset_exit(void)
{
printk(KERN_INFO "mykset_exit\n");
// Release obj1 and obj2
// ...
kset_unregister(my_kset);
return;
}在module_init里,我们首先调用kset_create_and_add创建my_kset,接下来把my_kset赋给obj1和obj2,最后调用kobject_init_and_add来添加obj1和obj2。这里需要注意的是,kobject_init_and_add参数里的parent都是NULL,在这种情况下,obj1和obj2的父对象由kobject结构里的kset指针决定,在这个实作里就是my_kset。在module_exit里,我们还需要额外调用kset_unregister来释放之前创建的my_kset。
注:我在这里注明一下,从2.6.23开始Linux内核就抛弃了subsystem,subsystem其实只是kset的一个马甲,所以抛弃它对Linux设备模型并没什么影响。
在文中,我们介绍到如何使用default attribute。Default attribute使用很方便,但不够灵活。比如上面在Kobject一节中提到的那个例子,name和val这两个attribute使用同一个show/store函数来访问,如果attribute非常多,show/store函数里的分支就会很凌乱。
为了解决这个问题,我们可以参考内核提供的kobj_attribute。在内核里,kobj_attibute是这样定义的:
struct kobj_attribute {
struct attribute attr;
ssize_t (*show)(struct kobject *kobj, struct kobj_attribute *attr,
char *buf);
ssize_t (*store)(struct kobject *kobj, struct kobj_attribute *attr,
const char *buf, size_t count);
};每一个attribute会对应自己的show/store函数,这样就极大的提高了灵活性。可是,在上一篇文章中我们的认知是,sysfs是通过kobject里的kobj_type->sysfs_ops来读写attribute的,那如果要利用kobj_attribute中的show/store来读写attribute的话,就必须在kobj_type->sysfs_ops里指定。Linux内核提供了一个默认的kobj_type类型dynamic_kobj_ktype来实现上述的操作。
/* default kobject attribute operations */
static ssize_t kobj_attr_show(struct kobject *kobj, struct attribute *attr,
char *buf)
{
struct kobj_attribute *kattr;
ssize_t ret = -EIO;
kattr = container_of(attr, struct kobj_attribute, attr);
if (kattr->show)
ret = kattr->show(kobj, kattr, buf);
return ret;
}
static ssize_t kobj_attr_store(struct kobject *kobj, struct attribute *attr,
const char *buf, size_t count)
{
struct kobj_attribute *kattr;
ssize_t ret = -EIO;
kattr = container_of(attr, struct kobj_attribute, attr);
if (kattr->store)
ret = kattr->store(kobj, kattr, buf, count);
return ret;
}
const struct sysfs_ops kobj_sysfs_ops = {
.show = kobj_attr_show,
.store = kobj_attr_store,
};
static void dynamic_kobj_release(struct kobject *kobj)
{
pr_debug("kobject: (%p): %s\n", kobj, __func__);
kfree(kobj);
}
static struct kobj_type dynamic_kobj_ktype = {
.release = dynamic_kobj_release,
.sysfs_ops = &kobj_sysfs_ops,
};kobj_attribute是内核提供给我们的一种更加灵活的处理attribute的方式,但是它还不够。只有当我们使用kobject_create来创建kobject时,使用kobj_attribute才比较方便,但大部分情况下,我们是把kobject内嵌到自己的结构里,此时就无法直接使用内核提供的dynamic_kobj_ktype,因此,我们需要创建自己的kobj_attribute。
本文接下来将围绕一个实作来看看如何创建自己的kobj_attribute,sample code可以从
这里
下载。这个sample code是基于上篇文章kobject中的例子修改而来的,看过那个例子的读者应该会比较轻松。
首先,我们需要定义自己的attribute:
struct my_attribute {
struct attribute attr;
ssize_t (*show)(struct my_kobj *obj, struct my_attribute *attr,
char *buf);
ssize_t (*store)(struct my_kobj *obj, struct my_attribute *attr,
const char *buf, size_t count);
};在my_attribute里,我们的show/store直接操作my_kobj,这样更加方便。
参考Linux内核,kobj_type里的sysfs_ops这样定义:
static ssize_t my_attr_show(struct kobject *kobj, struct attribute *attr,
char *buf)
{
struct my_attribute *my_attr;
ssize_t ret = -EIO;
my_attr = container_of(attr, struct my_attribute, attr);
if (my_attr->show)
ret = my_attr->show(container_of(kobj, struct my_kobj, kobj),
my_attr, buf);
return ret;
}
static ssize_t my_attr_store(struct kobject *kobj, struct attribute *attr,
const char *buf, size_t count)
{
struct my_attribute *my_attr;
ssize_t ret = -EIO;
my_attr = container_of(attr, struct my_attribute, attr);
if (my_attr->store)
ret = my_attr->store(container_of(kobj, struct my_kobj, kobj),
my_attr, buf, count);
return ret;
}下面就可以分别对name和val两个attribute定义自己的show/store。name这个attribute是只读的,只要为它定义show即可。
ssize_t name_show(struct my_kobj *obj, struct my_attribute *attr, char *buffer)
{
return sprintf(buffer, "%s\n", kobject_name(&obj->kobj));
}
ssize_t val_show(struct my_kobj *obj, struct my_attribute *attr, char *buffer)
{
return sprintf(buffer, "%d\n", obj->val);
}
ssize_t val_store(struct my_kobj *obj, struct my_attribute *attr,
const char *buffer, size_t size)
{
sscanf(buffer, "%d", &obj->val);
return size;
}接下来,利用内核提供的宏__ATTR来初始化my_attribute,并建立attribute数组。
struct my_attribute name_attribute = __ATTR(name, 0444, name_show, NULL);
struct my_attribute val_attribute = __ATTR(val, 0666, val_show, val_store);
struct attribute *my_attrs[] = {
&name_attribute.attr,
&val_attribute.attr,
NULL,
};其中,宏__ATTR的定义如下:
#define __ATTR(_name,_mode,_show,_store) { \
.attr = {.name = __stringify(_name), .mode = _mode }, \
.show = _show, \
.store = _store, \
}在module_init里,我们调用sysfs_create_files来把attribute增加到sysfs中。
retval = sysfs_create_files(&obj->kobj,
(const struct attribute **)my_attrs);
if (retval) {
// ...
}在kobject对应的目录里,还可以创建子目录,Linux内核里是用attribute_group来实现。在本例中,我们可以这么做:
struct attribute_group my_group = {
.name = "mygroup",
.attrs = my_attrs,
};然后在module_init里调用sysfs_create_group来添加。
retval = sysfs_create_group(&obj->kobj, &my_group);
if (retval) {
// ...
}本例创建的attribute_group中包含的attribute也是my_attrs,所以在子目录mygroup下的文件和mykobj目录下的文件完全一致。
最后我们得到的目录结构是这样的。
mykobj/
|– mygroup
| |– name
| — val |– name — val
完成这个实作之后,你可以用命令echo 2 > /sys/mykobj/val来修改mykobj下的val文件,可以观察到/sys/mykobj/mygroup/val的内容也会变成2,反之亦然。
上面主要通过一些简单的实作介绍了kobject、kset、kobj_type、attribute等数据结构的用法,但这些实作并没有涉及到实际环境下的设备模型和sysfs。接下来将以/sys下的module子目录为例,看看内核是如何构建sysfs这棵大树的。
(注:本文的分析基于2.6.36内核)
module的创建
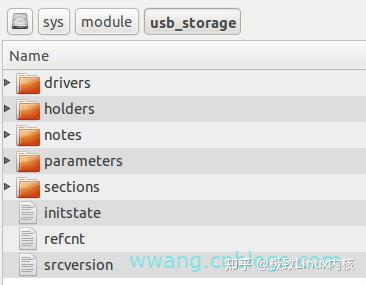
当module被insmod到内核空间时,/sys/module目录下会相应创建一个和模块同名的目录。我们以usb_storage为例,在执行完sudo modprobe usb_storage之后,sysfs里会产生一个名为usb_storage的目录,其目录结构是:
在Linux 2.6内核里,module的插入是由用户程序insmod(modprobe最终也是调用insmod)发起的,但大部分工作还是由内核完成。我们可以用
strace
来观察一下insmod的流程。
stat64(“/sys/module/usb_storage”, 0xbfb9a654) = -1 ENOENT (No such file or directory)
open(“/lib/modules/2.6.35-24-generic/kernel/drivers/usb/storage/usb-storage.ko”, O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=94776, …}) = 0
mmap2(NULL, 94776, PROT_READ|PROT_WRITE, MAP_PRIVATE, 3, 0) = 0xb776f000
close(3) = 0
init_module(0xb776f000, 94776, “”) = 0
munmap(0xb776f000, 94776) = 0
exit_group(0) = ?
从这个流程我们可以看到,insmod在执行时,首先会把module的内容映射到内存里,然后呼叫系统调用init_module来实现真正的工作。

如上图所示,这是系统调用init_module的执行路径。因为本文只是讨论设备模型和sysfs,流程图里只涉及到相关的内容。
1、mod_sysfs_init首先会查询当前模块(本例中是usb_storage)在sysfs中是否已经存在,如果没有,则调用kobject_init_and_add创建之;
2、调用kobject_create_and_add创建holders目录。holders目录用于存放指向其他module的链接,这里的其他module都是依赖于当前module的。以usb_storage为例,如果我们需要使用ums_XX模块(比如ums_karma或者ums_freecom等),可以调用sudo modprobe ums_XX来完成加载,因为ums_XX依赖于usb_storage,所以在usb_storage/holders目录下就会创建指向ums_XX的链接,同时refcnt也会加1;
3、module_param_sysfs_setup用来创建parameters目录,这个目录里的文件对应着当前module的所有参数。在Linux内核里,module的二进制ko文件中的__param section用来存储当前module的参数,load_module会把这些参数读取到内存结构里,module_param_sysfs_setup再根据相应的结构来创建paramters目录及其参数文件;
4、module_add_modinfo_attrs用来创建当前module目录下的4个文件:version、srcversion、refcnt和initstate,其中version和srcversion的信息存储在二进制ko文件的.modinfo section里。对于usb_storage模块来说,并没有指定version,所以不存在version这个文件。顺便罗嗦一句,在Linux内核里,可以用宏MODULE_VERSION定义版本号,比如MODULE_VERSION(“v1.00”)定义版本号为v1.00,这里的版本信息完全是字符串,并无特定格式。srcversion可以由MODULE_INFO(srcversion, xxx)来定义,但一般情况下由modpost默认生成就可以了。refcnt反映当前module的引用计数。initstate反映module的三种状态:live、coming和going;
5、add_usage_links和holders是密切相关的,但这个函数并不是操作当前module的holders目录。以ums_XX为例,在ums_XX的加载过程中,其add_usage_links会把自己作为链接加到usb_storage的holders目录下;
6、sections目录对应当前module的二进制ko文件里的section信息,这是通过add_sect_attrs实现的。需要提醒一下的是,section的命名通常以“.”开头,而以“.”开头的文件在Linux里被认为是隐藏文件,所以如果要察看的话要在ls命令后加”-a”参数,下面谈到的notes同样需要这样处理;
7、add_notes_attrs用来创建notes目录。ELF文件格式定义了一种名为note的元素,主要用于给二进制文件添加一些标示信息。通常,我们可以用readelf来察看ELF文件是否包含note section。比如usb_storage,我们可以使用命令“readelf usb-storage.ko -n”察看,其输出如下:
Notes at offset 0x00000034 with length 0x00000024:
Owner Data size Description
GNU 0x00000014 NT_GNU_BUILD_ID (unique build ID bitstring)
相应的,在/sys/module/usb_storage/notes目录下建立的notes文件就是.note.gnu.build-id。
上面的7条流程里,并无创建drivers的地方,那/sys/module/usb_storage下的drivers目录是如何建立的呢?答案在下图:
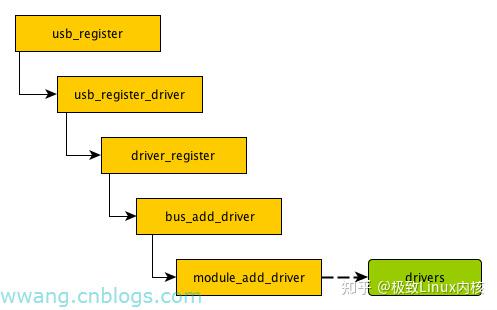
在usb_storage的module_init中,会调用usb_register来注册usb_driver结构,如图中所示,最终会调用module_add_driver来创建drivers目录。
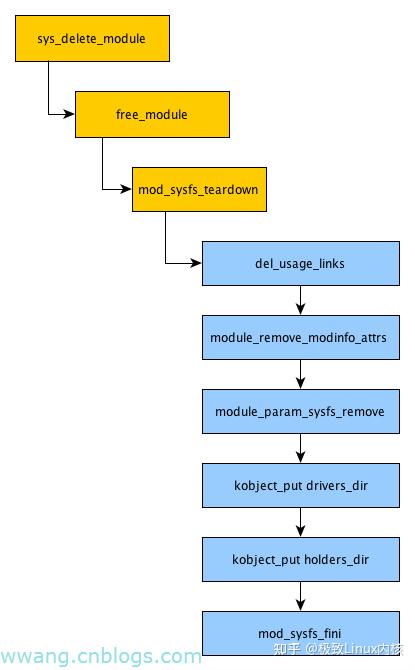
module的撤销
module的撤销过程和前文中的创建过程一一对应,在这里就不详细叙述了,请看下图。
关于sysfs中的其他子目录的创建和撤销,大家也可以很容易的在Linux内核中找到对应的代码,本文不再一一赘述。