先来一个疲惫却快乐的笑容 ?
期末的archlab…神一般的存在
上上周开开心心写完Part A,Part B已经在作业里做过了
感觉这个lab真是友好呀!!
然而今天死磕了一天Part C(手动狗头
anyway,终于做完了还是好开心滴!!
最后一个lab和期末都要好好加油呀?
Part A
这一部分还是考验编写汇编的能力
要把examples.c的三个函数编写成Y86的汇编语言
一开始我还先把他们转化成x86的汇编再进行改写
后来发现真是太复杂了,因为函数的功能都相当简单,直接写就可以了
& 需要学习一下模式化的开栈和调用等操作(写多了就熟悉啦,这里参考了网络~)
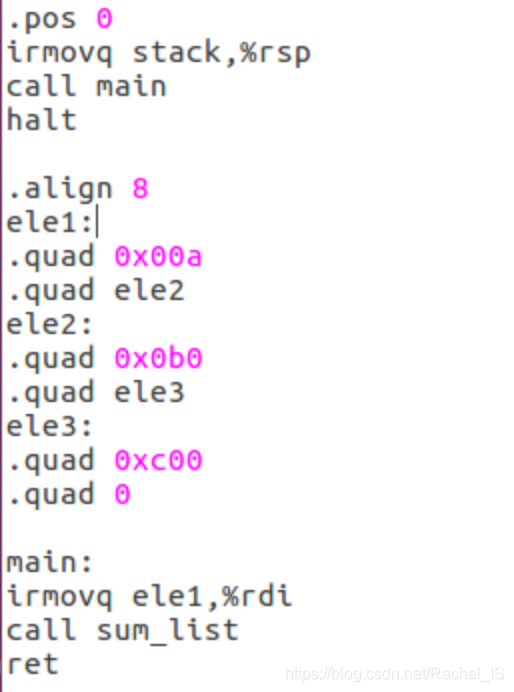
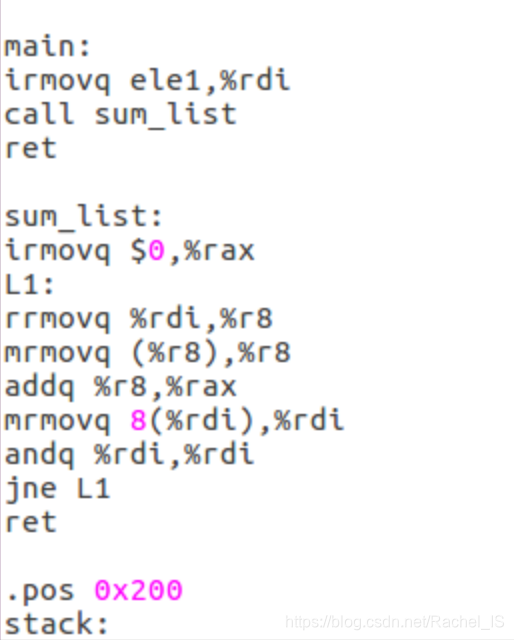
sum_list.ys
根据上上周遗留下来的上古遗迹来看,就大致是这样的
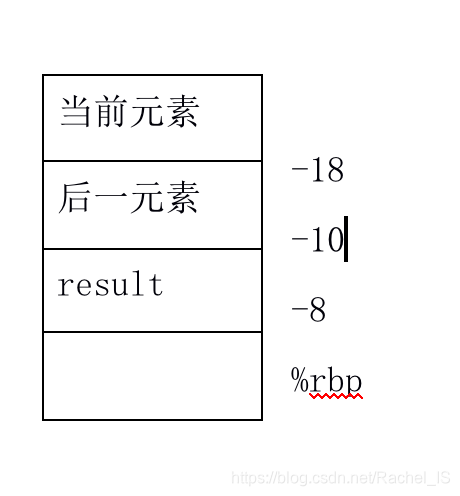
在栈中以这样的形式进行依次相加
测试:
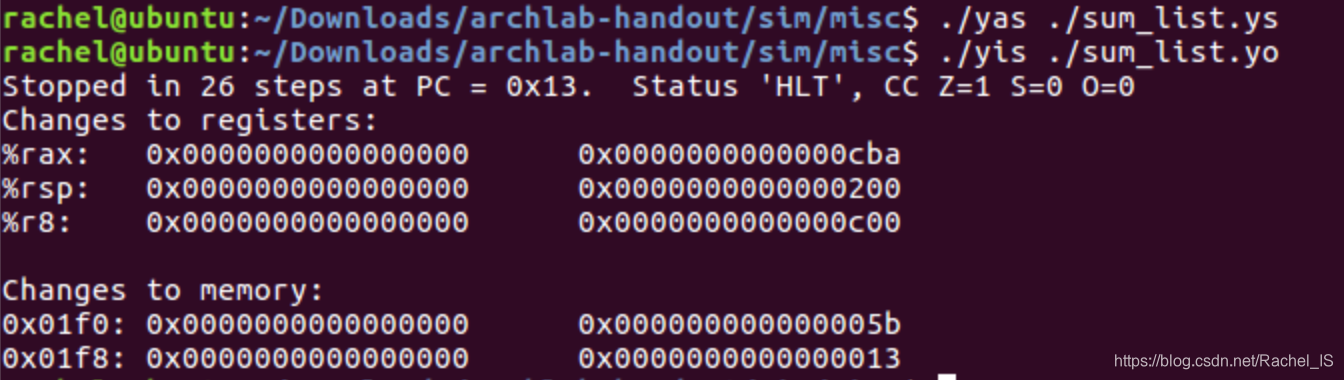
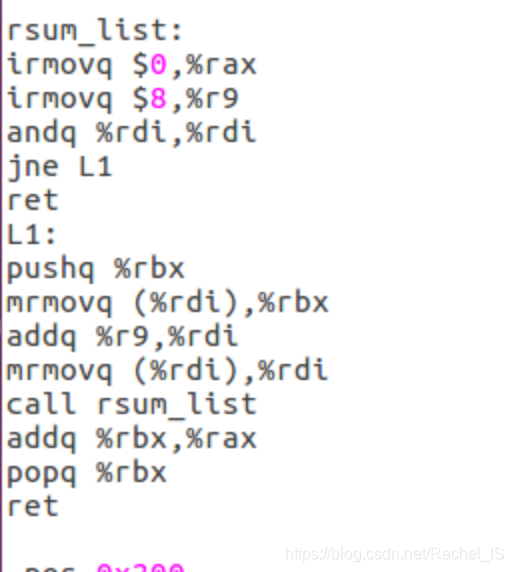
rsum_list.ys
功能与第一个相同,只是需要使用递归
要注意递归时的栈推入写法
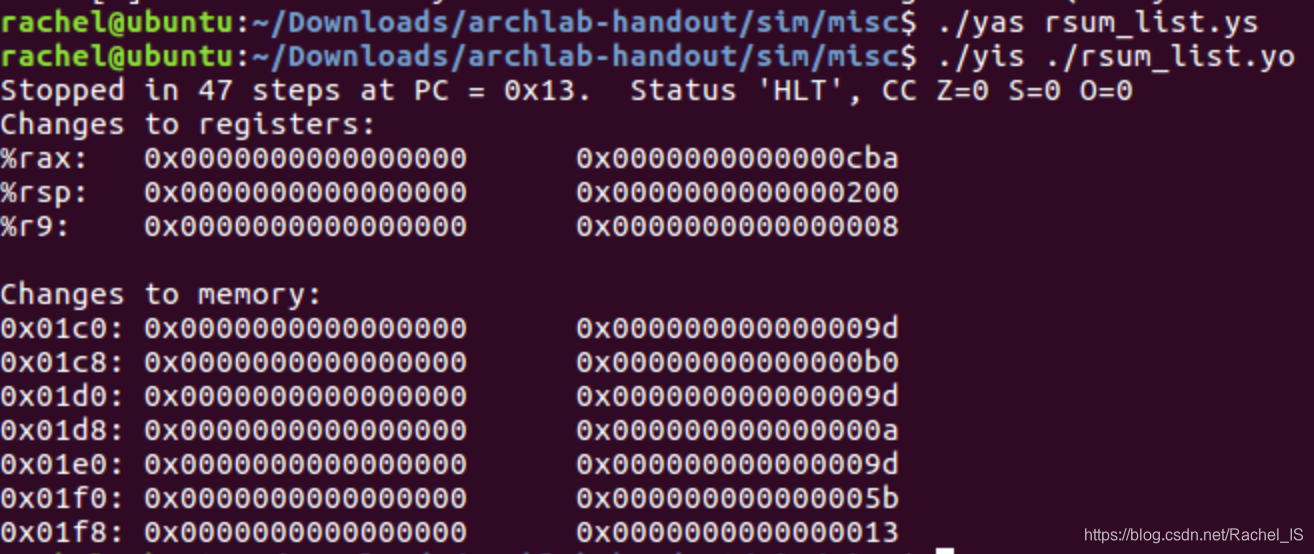
测试:
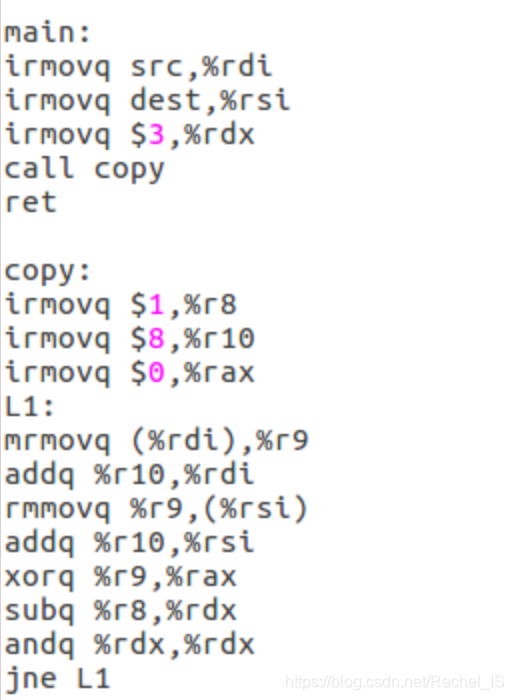
copy.ys
复制并计算链表
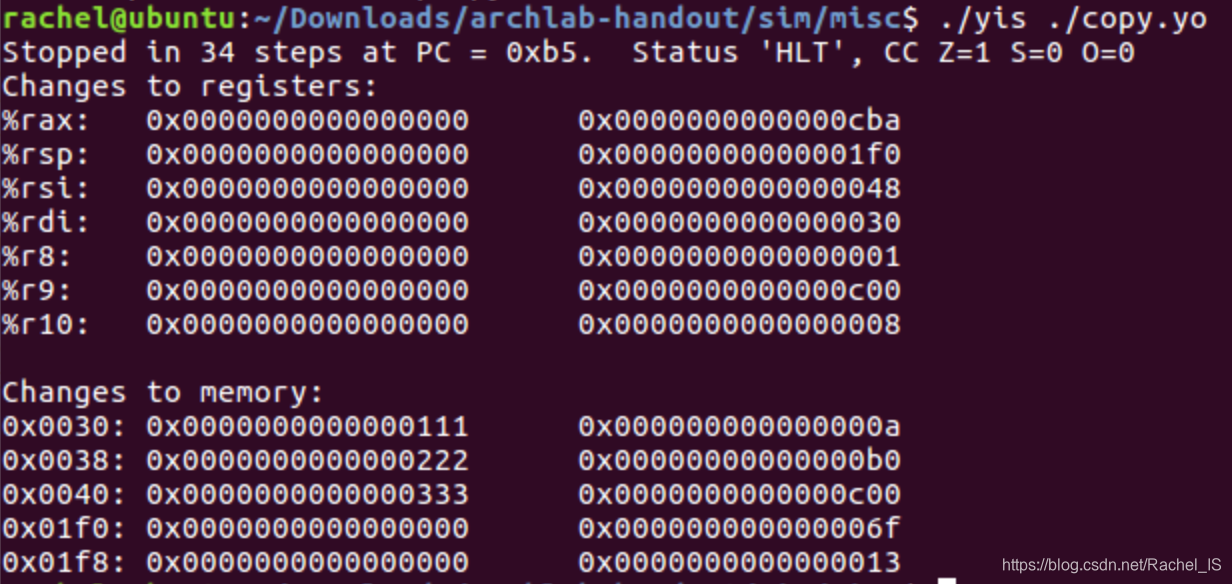
测试:
Part B
这个我们之前做过作业啦~感觉也不是很难,只要明白指令过程就OK
直接贴作业了hh

seq-full.hcl 修改处
################ Fetch Stage ###################################
bool instr_valid = icode in
{ IIADDQ, INOP, IHALT, IRRMOVQ, IIRMOVQ, IRMMOVQ, IMRMOVQ,
IOPQ, IJXX, ICALL, IRET, IPUSHQ, IPOPQ };
# Does fetched instruction require a regid byte?
bool need_regids =
icode in { IIADDQ, IRRMOVQ, IOPQ, IPUSHQ, IPOPQ,
IIRMOVQ, IRMMOVQ, IMRMOVQ };
# Does fetched instruction require a constant word?
bool need_valC =
icode in { IIRMOVQ, IIADDQ, IRMMOVQ, IMRMOVQ, IJXX, ICALL };
################ Decode Stage ###################################
## What register should be used as the B source?
word srcB = [
icode in { IOPQ, IRMMOVQ, IMRMOVQ, IIADDQ } : rB;
icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP;
1 : RNONE; # Don't need register
];
## What register should be used as the E destination?
word dstE = [
icode in { IRRMOVQ } && Cnd : rB;
icode in { IIRMOVQ, IOPQ, IIADDQ } : rB;
icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP;
1 : RNONE; # Don't write any register
];
################ Execute Stage ###################################
## Select input A to ALU
word aluA = [
icode in { IRRMOVQ, IOPQ } : valA;
icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ } : valC;
icode in { ICALL, IPUSHQ } : -8;
icode in { IRET, IPOPQ } : 8;
# Other instructions don't need ALU
];
## Select input B to ALU
word aluB = [
icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL,
IPUSHQ, IRET, IPOPQ, IIADDQ } : valB;
icode in { IRRMOVQ, IIRMOVQ } : 0;
# Other instructions don't need ALU
];
## Should the condition codes be updated?
bool set_cc = icode in { IOPQ, IIADDQ };
测试:
Part C
来了,PartC终于来了
这题就是让你尽可能快的优化ncopy.ys
初看它的代码,确实有很多不好的地方,但是你把它改掉之后…
就是0分…
所以真的没那么简单,需要自学第五章的优化方法(真实)
所以这里采用了如下的方法:
1.为pipe-full.hcl增加IAAQ指令,可以优化加法的速度,方法与Part B相同
2.使用第五章的split循环的方法,依次循环操作
8个
数字,减少循环的次数
3.在取数字时一次取出两个,既防止了bubble的发生(似乎这里是数据冒险??),也获得了下一步操作的数据
4.修改了原来的判断jg/jle,使得效率提升
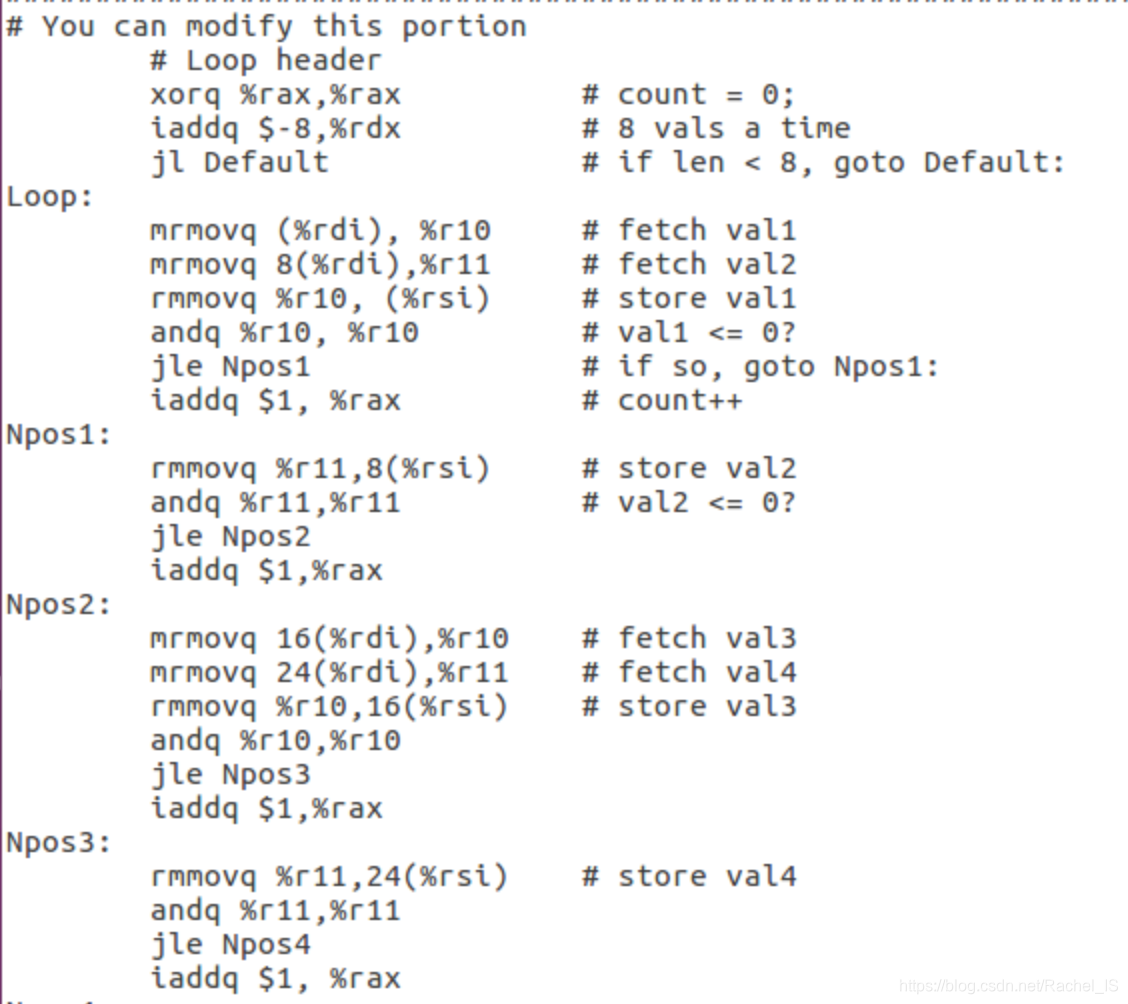
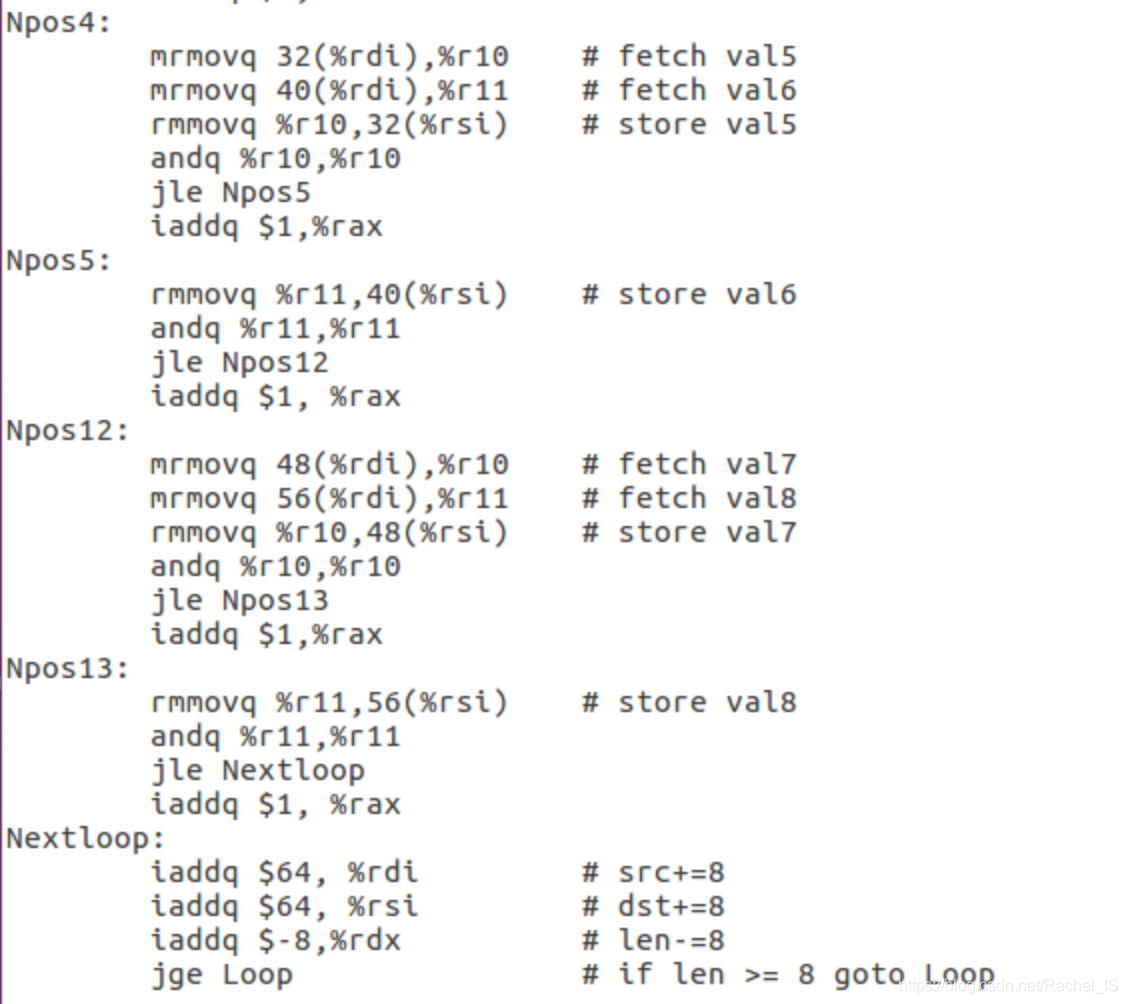
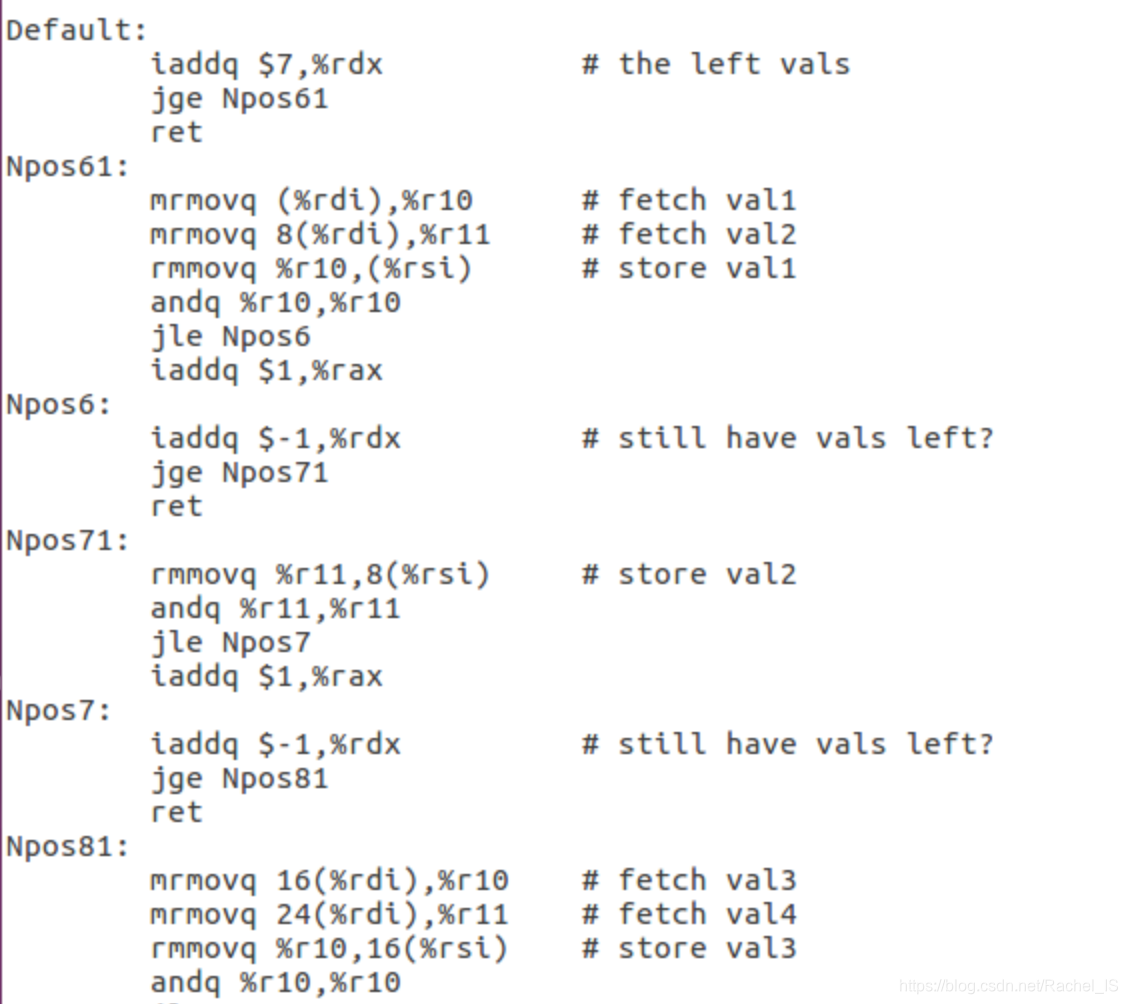
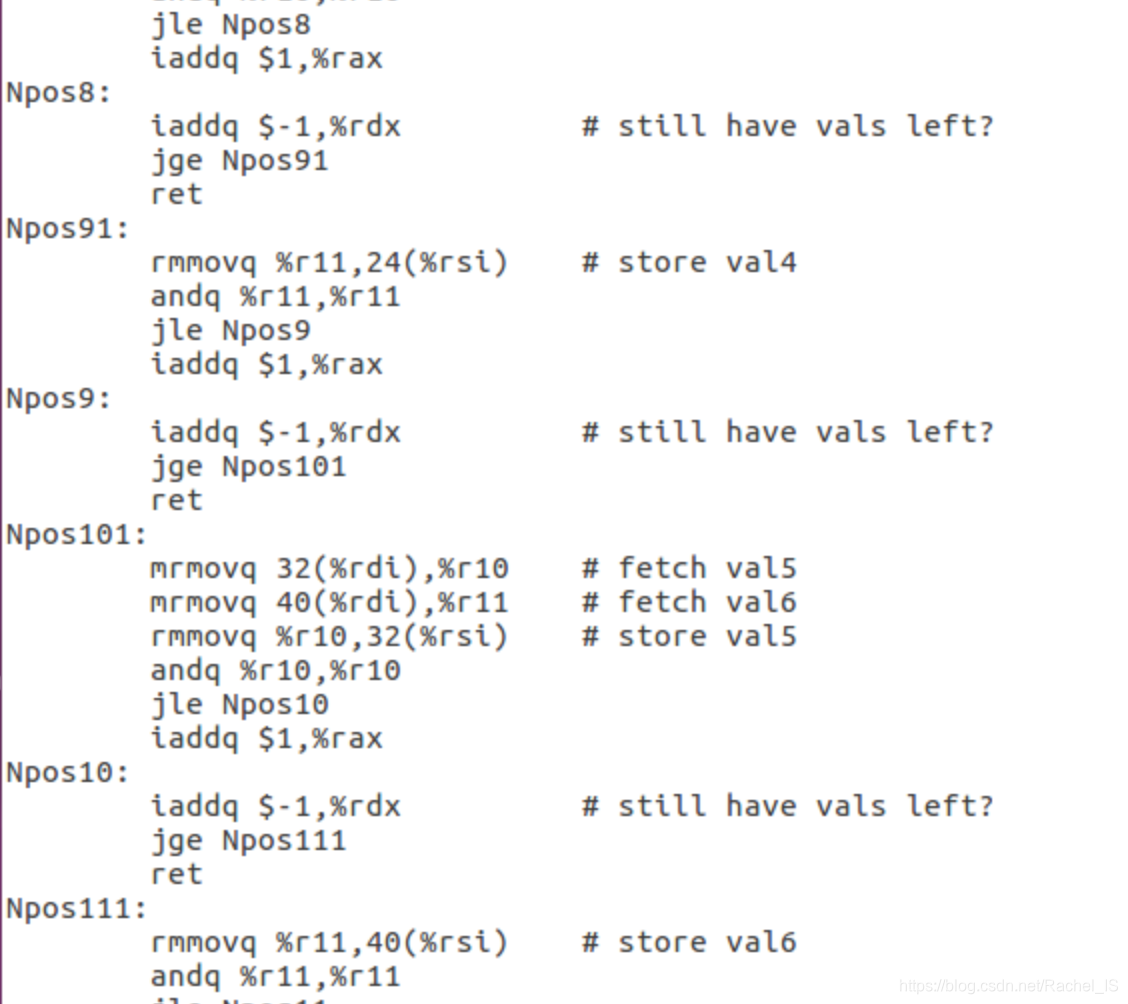
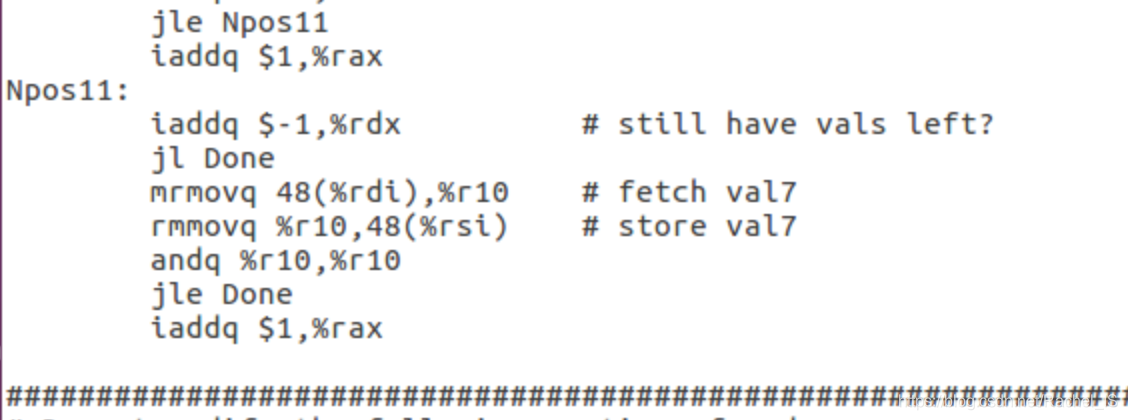
个人觉得最重要的是拆分循环+去bubble的想法~
参考了大佬的思路,万分感谢!!
各种测试:
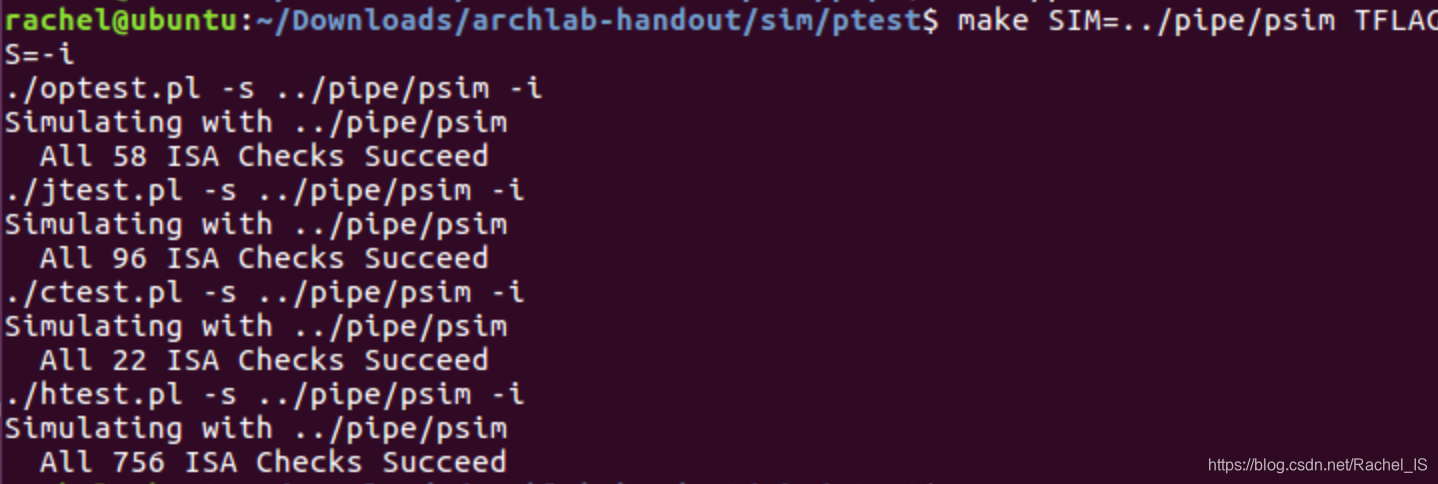
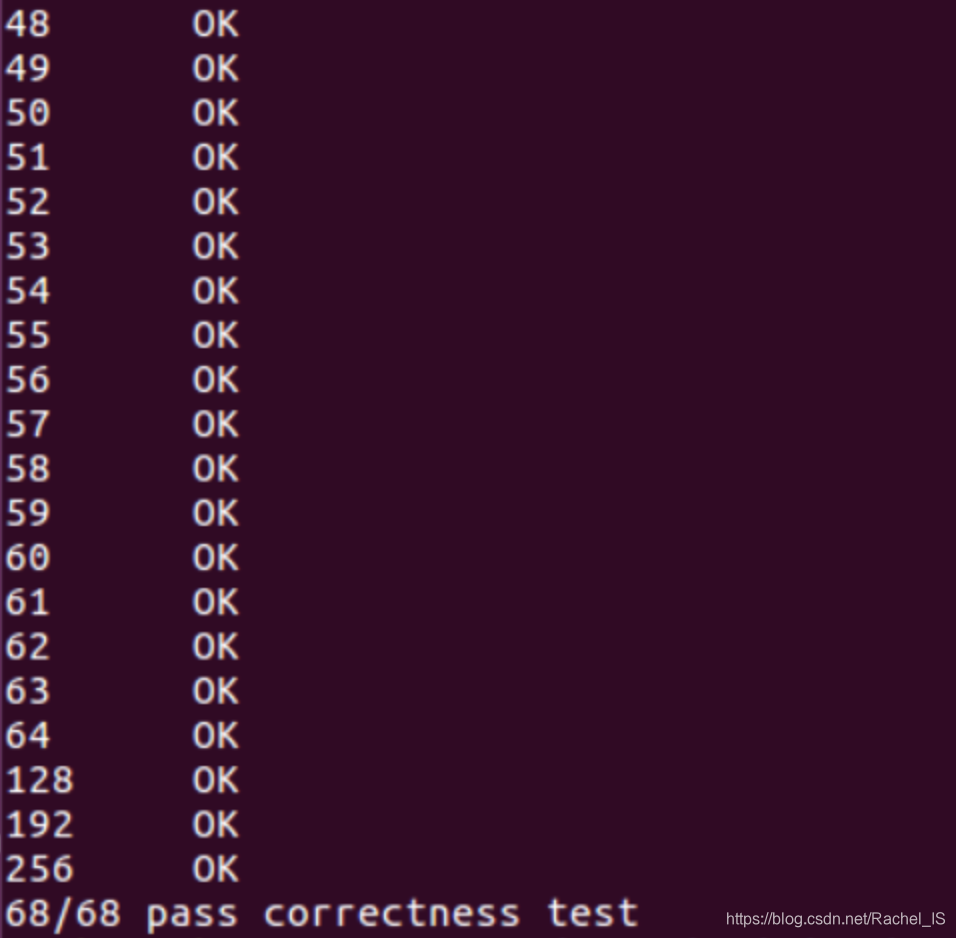
在完成了1、2、3的优化后,进行的benchmark:
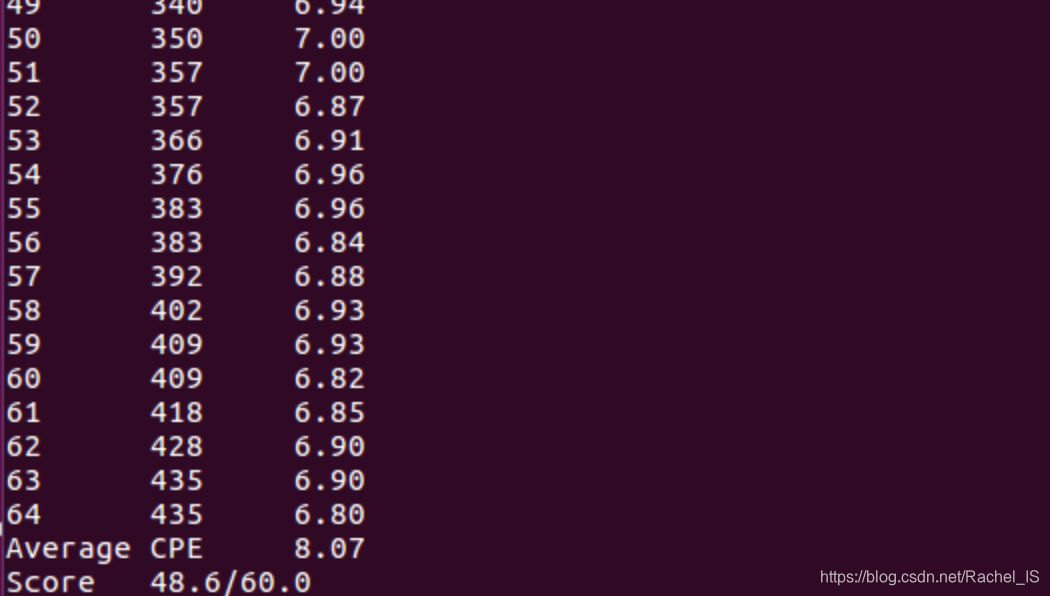
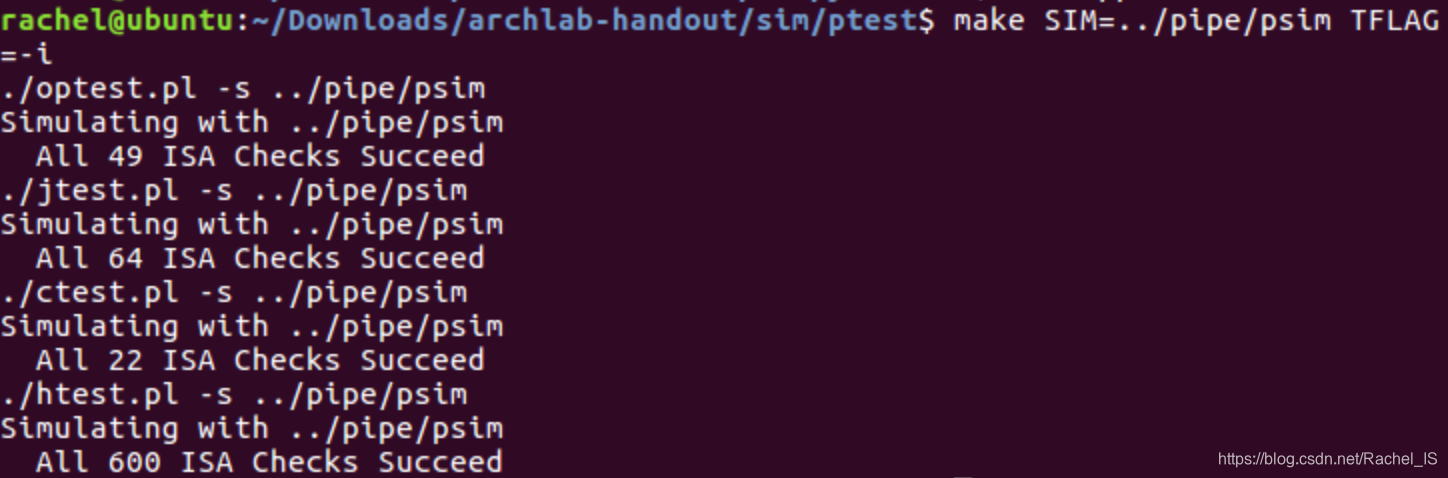
在优化了jle/jg判断后的benchmark:(也太不容易了555)
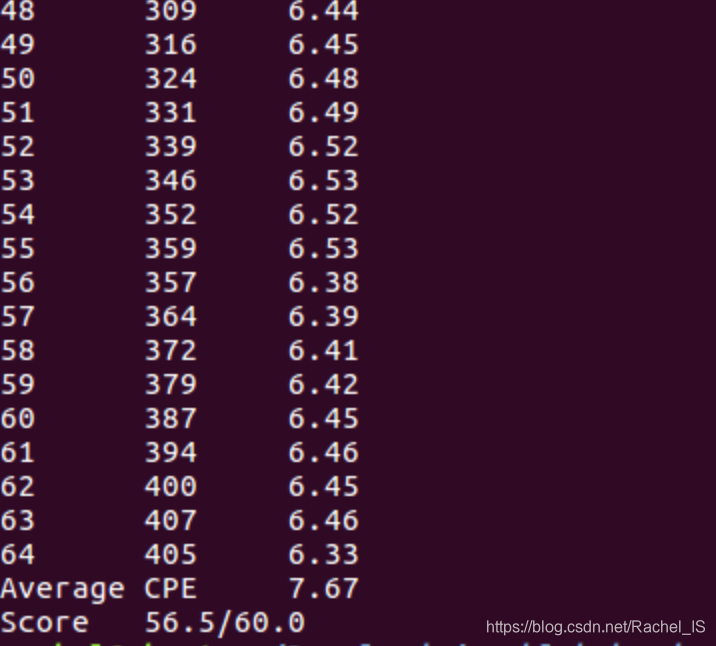
还有个卡了一下午的bug!!
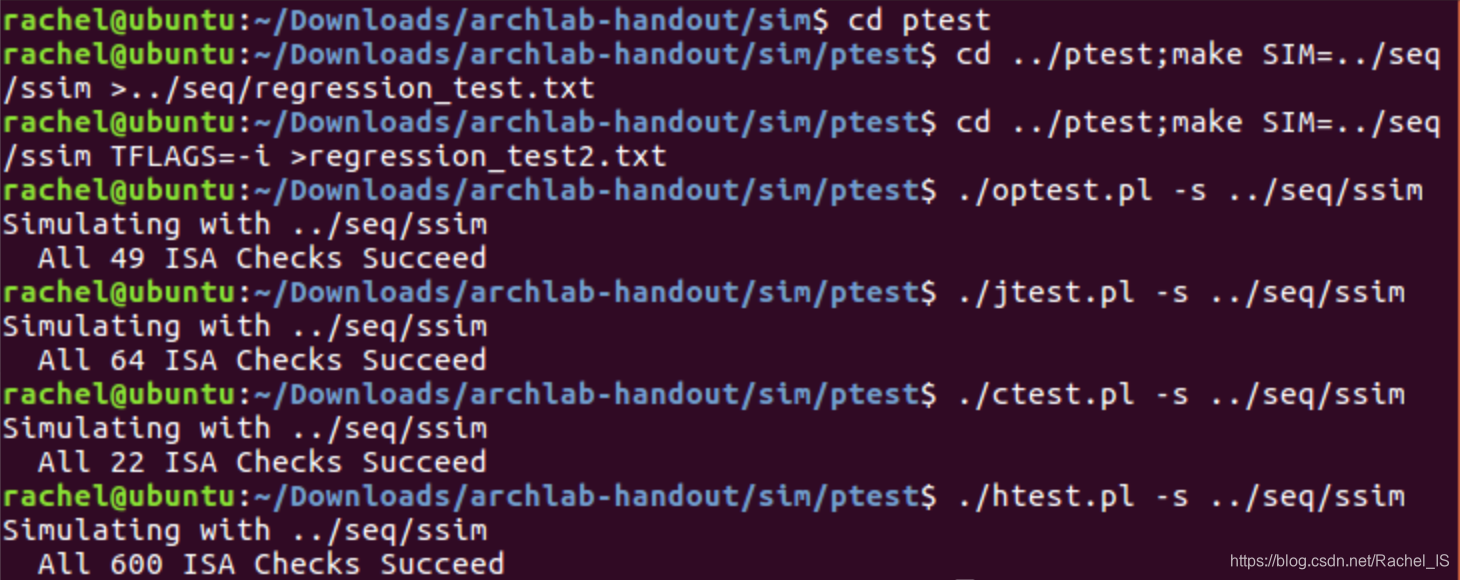
不知道为什么…benchmark会全是7,而且regression测试都是错的……?
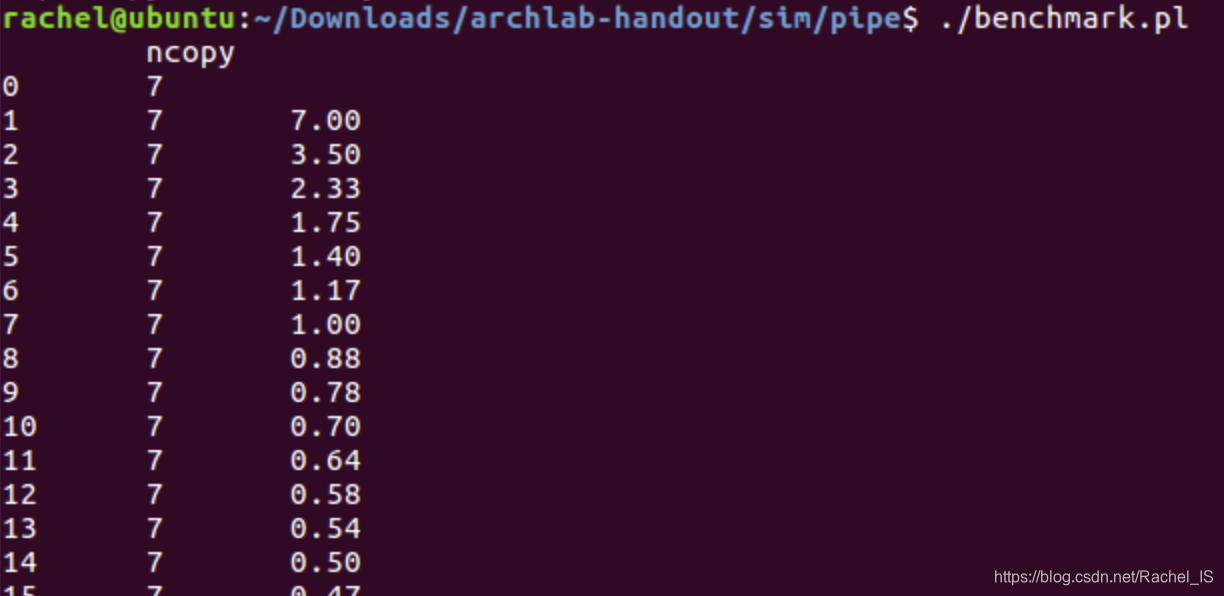
真的很有趣…这个bug最后给你的成绩是60(手动微笑
无论怎么make drivers都无效啊…一度崩溃
最后似乎是莫名其妙的进行了下
make passim VERSION=full
然后出现了这堆东西,就OK了
这个lab的时间很短,做的也有些拖沓和匆忙
但是从Part C真的可以看出CMU老师的牛?了
没拿到满分,但已经学到很多啦,特别是优化程序的思路,下学期也是要学习的
最后一个lab冲冲冲!!