这一篇是MySQL中的重点也是相对于MySQL中比较难得地方,个人觉得要好好的去归类,并多去练一下题目。MySQL的查询也是在笔试中必有的题目。希望我的这篇博客能帮助到大家!
重感冒下的我,很难受!keep on going,never givp up.(小编高中最喜欢用的句子,因为只记得这一句)
对数据表数据进行查询操作,其中可能大家不熟悉的就对于INNER JOIN(内连接)、LEFT JOIN(左连接)、RIGHT JOIN(右连接)等一些复杂查询,还有多表查询与子查询都是应用十分广泛的。
一、SELECT查询概述
1.1、select查询语法的作用
1)提取数据(搜索)
2)提取的数据进行排序(排序)
3)执行计算汇总
注意:select语句永远不会改变数据库中原始记录,仅仅是对数据进行提取处理而已。
1.2、select查询语法格式

select语法格式简化为:

1.3、构建查询环境
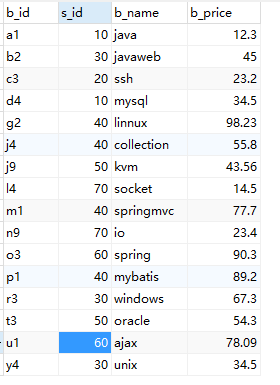
创建一个book表
create table book( b_id varchar(15), s_id int not null, b_name varchar(30) not null, b_price decimal(8,2) not null , primary key (b_id) ); 备注:b_id:主键 使用的是VARCHAR类型的字符来代表主键,s_id:书籍批发商编号,s_name书名,s_price书的价格.
插入数据
二、单表查询
单表查询的主要操作有:
查询所有字段
、查询指定字段、查询指定记录、带IN关键字的查询、带BETWEEN AND 的范围查询、带LIKE的字符匹配查询、查询空值
带AND的多条件查询、带OR的多条件查询、关键字DISTINCT(查询结果不重复)、对查询结果排序、分组查询(GROUP BY)、使用LIMIT限制查询结果的数量
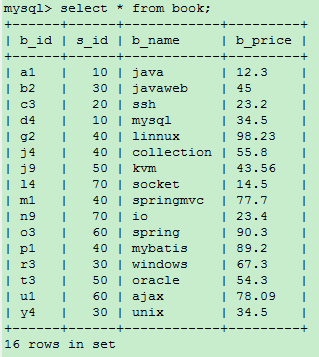
2.1、查询所有字段
select * from book;
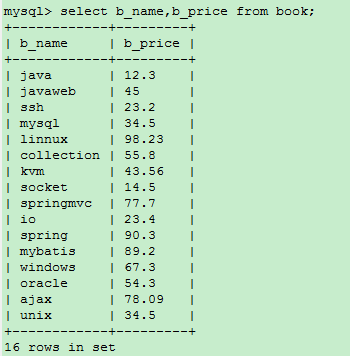
2.2、查询指定字段
select b_name,b_price from book;
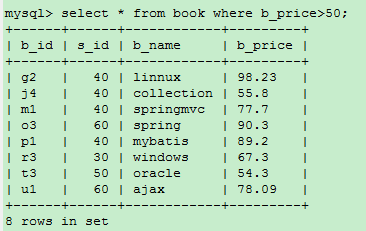
2.3、查询指定记录
指定记录:也就是按条件进行查询,将满足一定条件的记录给查询出来,使用WHERE关键字
。
select * from book where b_price>50;
2.4、带IN关键字的查询
IN关键字:IN(xx,yy,…) 满足条件范围内的一个值即为匹配项(IN前面可以加NOT)
select * from book where book.b_name in(‘ajax’,’io’);
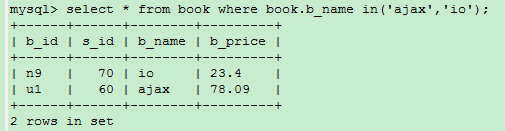
2.5、带BETWEEN AND 的范围查询
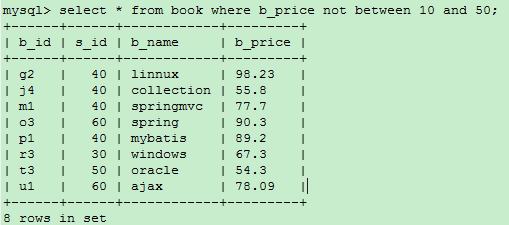
BETWEEN … AND … : 在…到…范围内的值即为匹配项(between前面可以加NOT)
select * from book where b_price not between 10 and 50;
2.6、带LIKE的字符匹配查询
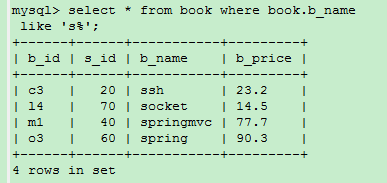
LIKE: 相当于模糊查询,和LIKE一起使用的通配符有 “%”、”_”
“%”:作用是能匹配任意长度的字符。
“_”:只能匹配任意一个字符
select * from book where book.b_name like ‘s%’; //查询以s开头的书名
select * from book where book.b_name like ‘__a_’;//查询前面任意两个字符后面为a,在后面为任意字符的四个字符的书名

总结:’%’和’_’可以在任意位置使用,只需要记住%能够表示任意个字符,_只能表示一个任意字符
2.7、查询空值
空值不是指为
空字符串””或者0,一般表示数据未知或者在以后在添加数据,也就是在添加数据时,其字段上默认为NULL,也就是说,如果该字段上不插入任何值,就为NULL
。此时就可以查询出来。
SELECT * FROM 表名 WHERE 字段名 IS NULL; //查询字段名是NULL的记录
SELECT * FROM 表名 WHERE 字段名 IS NOT NULL; //查询字段名不是NULL的记录
2.8、 带AND的多条件查询
AND: 相当于”逻辑与”,也就是说要同时满足条件才算匹配
select * from book where book.s_id=40 and book.b_price>60;//查询s_id为100,且价格大于60的书

2.9、带OR的多条件查询
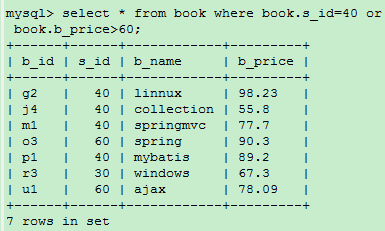
OR: 相当于”逻辑或”,也就是说只要满足其中一个条件,就算匹配上了,跟IN关键字效果差不多
select * from book where book.s_id=40 or book.b_price>60;//查询s_id为100或者价格大于60的书
2.10、关键字DISTINCT(查询结果不重复)
使用DISTINCT就能消除重复的值
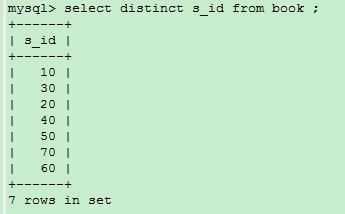
2.11、对查询结果排序
看上面输出的值没顺序,可以给他们进行排序。使用关键字 ORDER BY,有两个值供选择 DESC 降序 、 ASC 升序(默认值)
select distinct s_id from book order by s_id;

默认为升序
select distinct s_id from book order by s_id desc;

2.12、分组查询(GROUP BY)
分组查询就是
将相同的东西分到一个组里面去
,现实生活中举个例子,厕所分男女,这也是一个分组的应用,在还没有分男女厕所前,大家度共用厕所,后面通过分男女性别,男的跟男的分为一组,女的和女的分为一组,
就这样分为了男女厕所了。这就是分组的意思,
在上面对s_id进行查询的时候,发现很多重复的值,我们也就可以对它进行分组,将相同的值分为一组
。
1)select s_id from book group by s_id; //将s_id进行分组,有实际意义,按书批发商进行分组,从40批发商这里拿的书籍会放在40这个组中

解释:将s_id分组后,就没有重复的值了,因为重复的度被分到一个组中去了,现在在来看看每个组中有多少个值
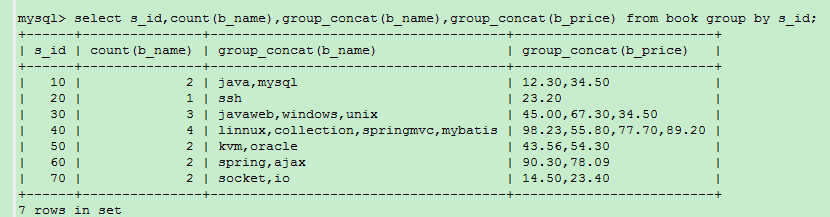
2)
COUNT()作用就是计算有多少条记录,
GROUP_CONCAT(): 将分组中的各个字段的值显示出来
select s_id,count(b_name),group_concat(b_name),group_concat(b_price) from book group by s_id;
分组之后还可以进行条件过滤,将不想要的分组丢弃,使用关键字 HAVING
select s_id,count(b_name),group_concat(b_name),group_concat(b_price) from book group by s_id having count(b_name)>2;

总结:
知道GROUP BY的意义,并且会使用HAVING对分组进行过滤,
HAVING和WHERE都是进行条件过滤的,区别就在于 WHERE 是在分组之前进行过滤,而HAVING是在分组之后进行条件过滤
。
2.13、使用LIMIT限制查询结果的数量
LIMIT[位置偏移量] 行数 通过LIMIT可以选择数据库表中的任意行数,也就是不用从第一条记录开始遍历,可以直接拿到 第5条到第10条的记录,也可以直接拿到第12到第15条的记录。、
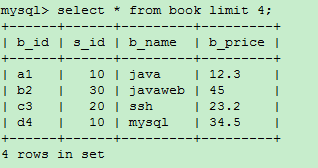
1)
select * from book limit 4; //没有写位置偏移量,默认就是0,也就是从第一条开始,往后取4条数据,也就是取了第一条数据到第4条的数据。
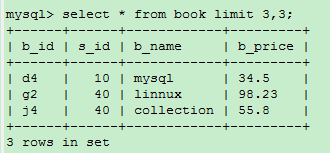
2)select * from book limit 3,3;
//从第4条数据开始,往后取3条数据,也就是从第4条到第7条
三、组函数(集合函数)查询
MySQL中组函数有
COUNT()函数
、SUM()函数、AVG()函数、MAX()函数、MIN()函数
3.1、COUNT()
COUNT(*):计算
表中的总的行数,不管某列有数值或者为空值,因为*就是代表查询表中所有的数据行
COUNT(字段名):计算
该字段名下总的行数,计算时会忽略空值的行,也就是NULL值的行
。
例如:查看一下book表中的总记录数
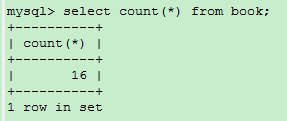
没有空值,所以计算出来的行数和总的记录行数是一样的。
3.2、SUM()
SUM()是一个求总和的函数,返回指定列值的总和
例如:计算一下所有书的总价
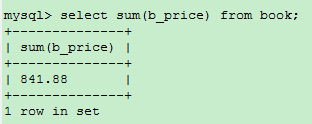
3.3、AVG()
AVG()函数通过计算返回的行数和每一行数据的和,求的
指定列数据的平均值
(列数据指的就是字段名下的数据,不要搞不清楚列和行,搞不清就对着一张表搞清楚哪个是列哪个是行),通俗点讲,就是将计算得来的总之除以总的记录数,得出一个平均值。
例如:求所有书的平均价格
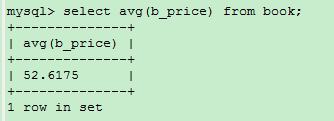
3.4、MAX()
MAX()返回指定列中的最大值
例如:求所有书中最贵的一本
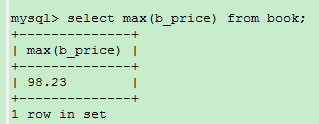
3.5、MIN()
MIN()返回查询列中的最小值
例如:求所有书中最便宜的一本

觉得不错的老哥,点个“”推荐“”!
转载于:https://www.cnblogs.com/zhangyinhua/p/7505643.html