基于Python的英语错词查询记录本 v0.1(改进中)
写在前面——前因后果
经过了这次的经历我真的相信:“
懒人的需求推动全世界发展。
”
因为特殊原因,我的右手掌骨骨折了,作为一名普通人,生活的各个方面尚且受了巨大的影响,更无需说作为一名正在准备考研、专业是计算机的学生来说了。
养病期间,做英语查单词成了大难题,单手打字确实是一个艰难的过程,为了少打字,我就想:是否可以利用
python
、
网络爬虫
技术编写一个自用的简单错词查询、记录的小脚本,
辅助查词
?似乎可行!开干!
设计思路
网址规律
因为平时查词喜欢使用有道云词典,所以本次使用的网站就暂定为有道云,首先,需要明确有道云网址的规律。
首先我们查询“start”这个单词,单词页面网址如下:
https://dict.youdao.com/w/eng/start/#keyfrom=dict2.top
再查询“special”这个单词,单词页面网址如下:
https://dict.youdao.com/w/special/#keyfrom=dict2.top
可以大体看出我们有道云的
网址规律
为:
https://dict.youdao.com/w/{你需要查询的单词}/#keyfrom=dict2.top
获取网页内容并保存
利用requests获取网页内容并通过open语句保存,为后面的分析做准备。
分析网页结构
用chrome浏览器打开之前“start”的那个网页,右击空白处,选择检查,即可查看网页结构。
我们需要的只是简单释义,所以只需要确定中间那几个意思的内容特性即可。
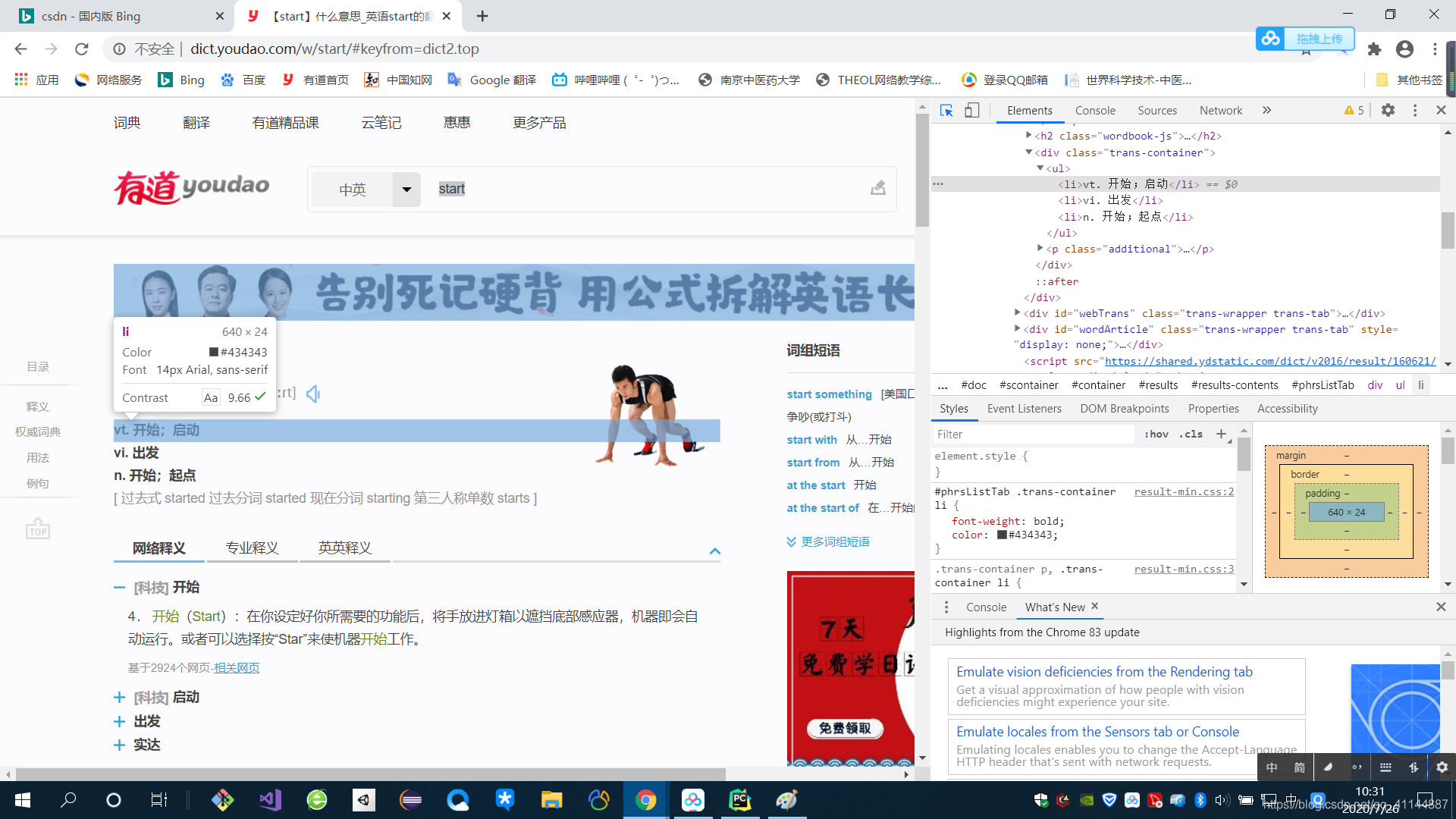
通过查看网页内容我们定位了这几个“li”的位置:
div(class=“trans-wrapper clearfix”) > div(class=“trans-container”) > ul > li
我们需要获取这个标签内的文字,所以我们利用tree库内的xpath函数获取,xpath()输入参数为:
div[contains(@class,“trans-wrapper clearfix”)]/div[contains(@class,“trans-container”)]/ul/li/text()
保存查询结果,生成当日错词本
最后利用open保存查询结果。保存时需要获取当日日期,以区分其他天的文件。
源码与注意事项
使用注意事项
使用时,需要在py文件下建立“html”、“txt”两个文件夹。当然也可以在源码中修改成自己的文件夹位置。
源码
import requests
from lxml import etree
import datetime
def main():
# 网址
url = 'https://dict.youdao.com/w/{}/#keyfrom=dict2.top'
# 查询目标输入
word = input()
# 时间
year = datetime.datetime.now().year
month = datetime.datetime.now().month
day = datetime.datetime.now().day
# 循环查询,直到输入-1
while word != '-1':
# 请求网页内容
response = requests.get(url.format(word))
# 保存网页内容
with open(f'./html/{word}.html', 'w', encoding='utf-8') as fp:
fp.write(response.text)
# 利用xpath分析提取特殊网页内容
parser = etree.HTMLParser(encoding="utf-8")
tree = etree.parse(f'./html/{word}.html', parser=parser)
result = tree.xpath(
'//div[contains(@class,"trans-wrapper clearfix")]/div[contains(@class,"trans-container")]/ul/li/text()')
print(result)
# 添加结果
with open(f'./txt/{year}.{month}.{day} words.txt', 'a', encoding='utf-8') as fp:
fp.write(word + ' ')
for each in result:
fp.write(each)
fp.write('\n')
word = input()
if __name__ == '__main__':
main()
To Be Continue……