
1.构建YOLOv3网络的cfg文件
该文件表示的是你的检测网络的结构,类似caffe的prototxt文件。
YOLOv3的cfg文件
上篇介绍YOLOv3网络中提到的去掉上采样操作的YOLOv3cfg文件
2.准备hs.data文件
如下文件中规定了当前目标检测网络中的类别数量为4。训练数据的路径train.txt的位置,hs.names的路径的位置,以及最终训练得到的网络模型保存的位置。
classes = 4
train = /home/yuanlei/darknet_yolov3/backup/yolov3_initial/4_cls/train.txt
names = /home/yuanlei/darknet_yolov3/backup/yolov3_initial/4_cls/hs.names
backup = /home/yuanlei/darknet_yolov3/backup/yolov3_initial/4_cls- train.txt文件 train.txt文件中的内容如下图所示,保存的是训练数据集图片的保存路径。
/home/yuanlei/traindata_4cls/0.jpg
/home/yuanlei/traindata_4cls/1.jpg
/home/yuanlei/traindata_4cls/2.jpg
/home/yuanlei/traindata_4cls/3.jpg
...
...
/home/yuanlei/traindata_4cls/1000.jpg
/home/yuanlei/traindata_4cls/1001.jpg
...- hs.names文件 hs.names中的内容如下图所示,保存的是当前检测网络中需要检测的类别名称,用于后续显示。
people
car
bicycle
truck
3.训练数据准备
训练数据的保存位置要和步骤2中的train.txt文件中的路径对应起来,当然除了train.txt中的图片数据,我们还需要准备基于对应图片的目标位置和类别数据,也就是图片对应的标签文件,具体存放方式如下。
而上图中的
txt
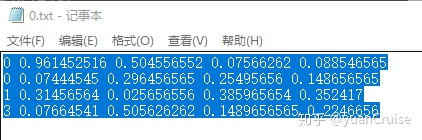
文件中的格式如下: 每一行代表了当前图片中的一个目标,每一行数据由5个字段组成,第一个字段表示了当前目标的类别,
0:people, 1:car, 2:bicycly, 3.truck
和上述的hs.names文件相对应。而第二,三字段表示了在全图中当前目标的中心点位置,第四,五字段表示了在全图中当前目标的宽,高。我们可以看到这四个字段都是小于1的,因为都是以全图的宽高的百分比来表示的(回归网络训练时会更加容易收敛)。
如下所示的代码可以用来解析
jpg,txt
文件,从大图中根据标签数据把小图抠出来,这段代码对YOLOv3网络的训练没有用处,把这段代码放在这里就是让大家对
txt
文件中的字段有更清晰的理解。
from PIL import Image
img = Image.open("0.jpg")
width = img.size[0]
height = img.size[1]
with open("0.txt") as f:
lines = f.readlines()
for line in lines:
center_width = int(width * float(line.split(" ")[1]))
center_height = int(height * float(line.split(" ")[2]))
patch_width = int(width * float(line.split(" ")[3]))
patch_height = int(height * float(line.split(" ")[4]))
left_top_width = center_width - patch_width/2
left_top_height = center_height - patch_width/2
right_down_width = center_width + patch_width/2
right_down_height = center_height + patch_width/2
pic = img.crop(box=(left_top_width,left_top_height,right_down_width,right_down_height))
pic.show()
4.若有预训练权重,准备预训练权重
如果需要预训练权重,就重网上下载和cfg文件相对应的权重文件,并保存到
/home/yuanlei/darknet_yolov3/backup/yolov3_initial/pretrain/yolov3.weights
路径下边即可。
5.构建train.sh批处理脚本
批处理脚本如下所示,要训练检测网络,主要使用的两个字段为
detetor,train
,以及一些必须的路径,如cfg,weights等路径。darknet中的主函数会解析给定的字段,进行训练,本文不展开讲,后续会专门这对这个过程写一篇文章。
cfg_dir = /home/yuanlei/darknet_yolov3
root_dir = /home/yuanlei/darknet_yolov3
$root_dir/darknet
detector
train
$cfg_dir/backup/yolov3_initial/4_cls/hs.data
$cfg_dir/backup/yolov3_initial/4_cls/yolov3_initial.cfg
$cfg_dir/backup/yolov3_initial/pretrain/yolov3.weights
8.在命令行运行sh train.sh开始训练YOLOv3网络
在命令行输入
sh train.sh
,就可以开始训练了,至此利用YOLOv3训练自己的数据集全部完成~
9.训练过程中打印出的log的含义
如下的代码所示,网络训练过程中,每一个batch都会打印如下所示的信息。需要注意的是原始的基于darknet框架的YOLOv3网络并不会打印出
l.batch 16, l.h 11, l.w 20, l.n 3
此类信息,这是我为了便于理解,在源码中添加后让其打印出来的。
Loaded: 0.000045 seconds
l.batch 16, l.h 11, l.w 20, l.n 3
Region 71 Avg IOU: 0.1578377, Class:0.329731, Obj: 0.614276, No Obj: 0.497656, .5R: 0.090909, .75R: 0.000000, count: 11
l.batch 16, l.h 22, l.w 40, l.n 3
Region 79 Avg IOU: 0.172776, Class:0.443888, Obj: 0.514122, No Obj: 0.489635, .5R: 0.052632, .75R: 0.000000, count: 19
l.batch 16, l.h 44, l.w 80, l.n 3
Region 87 Avg IOU: 0.169250, Class:0.485123, Obj: 0.664770, No Obj: 0.4577785, .5R: 0.102564, .75R: 0.000000, count: 39
l.batch 16, l.h 11, l.w 20, l.n 3
Region 71 Avg IOU: 0.159549, Class:0.464980, Obj: 0.487730, No Obj: 0.496075, .5R: 0.000000, .75R: 0.000000, count: 10
l.batch 16, l.h 22, l.w 40, l.n 3
Region 79 Avg IOU: 0.210336, Class:0.425438, Obj: 0.47328, No Obj: 0.489249, .5R: 0.095238, .75R: 0.000000, count: 21
l.batch 16, l.h 44, l.w 80, l.n 3
Region 87 Avg IOU: 0.144593, Class:0.413408, Obj: 0.617854, No Obj: 0.4457386, .5R: 0.000000, .75R: 0.000000, count: 53
8666434: 1440.400757, 1468.966187 avg, 0.000050 rate, 3.923887 seconds, 27725888 images
输出log中,分为两部分,这主要基于cfg文件中的
batch=32,subdivisions=2
,所以第一部分用到了16张图,第二部分用到了另外16张图。而任意部分中输出了三块,其中每一块代表了一种特征图上的detection结果,利用我打印出来的
l.batch 16, l.h 11, l.w 20, l.n 3
语句能更好的区分每一小块代表的是哪种尺度的detection。


10.cfg参数介绍
简单介绍下cfg文件中的一些参数: – 实际batchsize为16
batch=32
subdivisions=2- 相关增强操作
angle=0
saturation = 1.5
exposure = 1.5
hue=.1- 优化策略 利用step策略,分为三个阶段下降,用steps参数控制何时下降,由scales参数控制每次学习率变化时相乘的系数。
policy=steps
steps=866633,876633,896633
scales=10,.5,.2-
特殊参数burn_in 当update_num小于burn_in时,不是使用配置的学习速率更新策略,而是按照公式
lr = base_lr * power(batch_num/burn_in,pwr)
更新。其背后的假设是:全局最优点就在网络初始位置附近,所以训练开始后的burn_in次更新,学习速率从小到大变化。update次数超过burn_in后,采用配置的学习速率更新策略从大到小变化,显然在finetune时可以尝试使用该参数。
burn_in=200- yolo层中的参数
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=4
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0- mask 该参数用于确定当前尺度的detection使用哪三个anchor,6,7,8表示使用最后三组尺度大的anchor,其余类推。
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
mask = 6,7,8
mask = 4,5,6
mask = 1,2,3- random
random为1时会启用Multi-Scale Training,随机使用不同尺寸的图片进行训练,如果为0,每次训练大小与输入大小一致; – jitter 通过抖动增加噪声来抑制过拟合