卡塔尔世界杯
世界杯都已经开始好几天了,虽然主队(显而易见,这里并不是指中国队)没有入围最后的决赛圈,绝代双骄也已过了巅峰,自己也老了,对这项赛事的关注度已降到了冰点,不过瘦死的骆驼比马大,对这届赛事的还是有些期待的。所以已经错过了开幕式,也错过了好几场比赛了,赶紧看看接下来的赛程。什么?马上梅老⑦就要出场了,接下来稍微关注一下吧。赛程呢,去网站上找找吧。
爬虫
接下来看看爬虫技术,先从最基本的开始,通过访问网页获取数据。这里先用到request库。近年来,直播8很火啊,反正我是以前经常逛这个网站,所以这次就访问直播8。
使用requests库访问后可以获得近期各类比赛的赛程,所以好像也没用到爬虫技术,仅仅只访问一次而已,不管了,先看看这个吧。
访问网站
使用requests发送get请求得到数据:
import requests
url = 'http://www.zhibo8.cc'
res = requests.get(url)
print(type(res))
# res.encoding = 'gbk'
res.encoding = 'utf-8'
resTxt = res.text
print(type(resTxt))
print(resTxt)
将数据转换成了字符串,接下来直接对字符串处理
结构还是很清晰的,接下来使用字符串函数来处理
数据处理
循环处理
idx = resTxt.find('<li label="世界杯,')
while idx != -1:
resTxt = resTxt[idx:]
idx = resTxt.find('</li>')
match = resTxt[:idx]
# print(match)
if match.find('鏖战世界波') == -1:
m_idx = match.find('data-time="')
matchTime = match[m_idx + len('data-time="'): match.find('">')]
m_idx = match.find('<b>')
phase_home = match[m_idx + len('<b>') : match.find('<img src=')]
m_idx = match.find('</b>')
tmp = match[:m_idx]
m_idx = tmp.rfind('>')
# print(m_idx)
visiting = tmp[m_idx+1:]
m_idx = match.find('"_blank">')
media = match[m_idx + len('"_blank">'): match.find('</a>')]
space = ' '
matchInfo = matchTime + space + phase_home + 'VS'+ visiting + space + media
# print(matchInfo)
resTxt = resTxt[idx:]
idx = resTxt.find('<li label="世界杯,')
结果
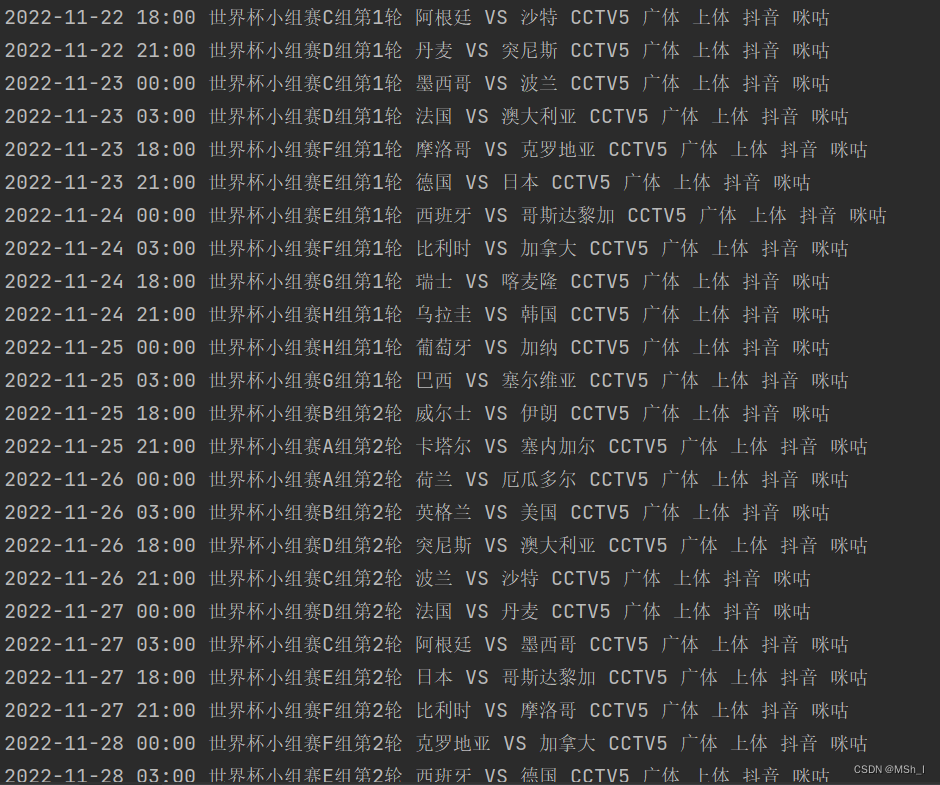
近期的赛程就出来了,一直到所有的1/8决赛。什么?怎么还有的比赛只有抖音才播,这么怪异吗 ̄□ ̄||
梅老板要出场了,赶紧回家吃饭,打开咪咕,其他的以后再说。。。。
版权声明:本文为shouqw原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。