heatmap
如果网络要输出N种分类的关键点,就输出N维的特征图,同时我们根据关键点的位置在N维label的特征图上造高斯核,如果每一个像素点对应的只有一种分类,此时我们可以采用softmax Loss(Softmax loss是由softmax和交叉熵(cross-entropy loss)loss组合而成,所以全称是softmax with cross-entropy loss),也可以使用MSE Loss.
heatmap+focal loss
我们假设一张特征图的大小是800
600,上面有一个关键点,其高斯核的大小是9
9,那么正负样本的比例就是81:480000,
这正负样本的比例相差惊人,为了平衡正负样本,我们可以引入focal loss。
我们以简单的二分类为例,二分类的loss定义如下:
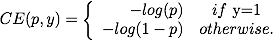
上式中p代表样本属于1的概率。y代表标签。为了表示方便,我们定义pt如下:
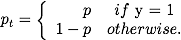
一方面,当正负样本不均衡的时候,我们本能的希望能在 平衡正负样本的loss,比如,当正样本很多的时候,我们希望提升负样本loss的占比,可以直接在前面乘以一个固定的数值:
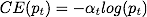
at这个调控的参数是一个二维的数组,分别乘在正样本和负样本的前面。(一定要注意其不是一个单独的数)!
CE loss 如下图中的蓝色曲线所示,这个loss的一个显著特征是,即使是分类接近正确的情况下,也会产生较大的loss。
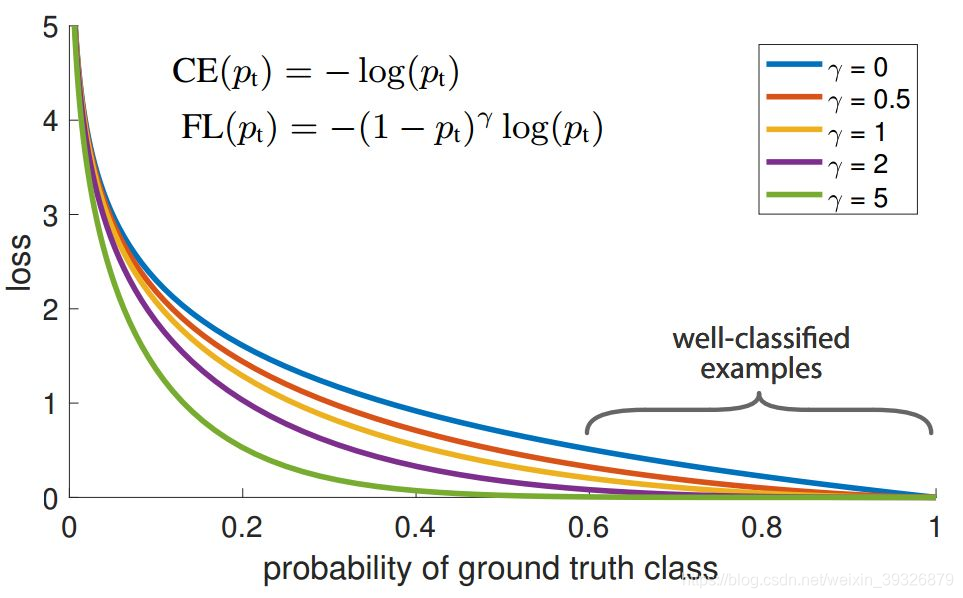
我们希望loss着重于难分类或者说分类结果错误很大的样本上,于是我们将公式改成如下:
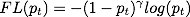
由上图我们可以看出y越大,对分类太错误会比分类结果接近正确有更重的惩罚。
当一个样本被错分类,pt值很小的时候,调节因子,(1-pt)的值很大,因此loss很大。当pt值很大,趋近于1的时候,调节因子的值趋近于0,因此对于正确分类的样本的loss值被缩小了。
我们将样本不均衡以及加大对错误分类的惩罚结合起来:
关于focal loss的例子,我们可以看如下代码区更好地了解:
# version 1: use torch.autograd
class FocalLossV1(nn.Module):
def __init__(self,
alpha=0.25,
gamma=2,
reduction='mean', ):
super(FocalLossV1, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
self.crit = nn.BCEWithLogitsLoss(reduction='none')
def forward(self, logits, label):
'''
logits and label have same shape, and label data type is long
args:
logits: tensor of shape (N, ...)
label: tensor of shape(N, ...)
'''
# compute loss
logits = logits.float() # use fp32 if logits is fp16
#表明以下两步不用求梯度
#可以看出alpha不是一个值,在正样本的情况下(1)其系数为alpha
with torch.no_grad():
alpha = torch.empty_like(logits).fill_(1 - self.alpha)
alpha[label == 1] = self.alpha
#将输出结果归一化
probs = torch.sigmoid(logits)
#label==1的地方用probs代替,不等于1的地方用1 - probs代替
pt = torch.where(label == 1, probs, 1 - probs)
#Crit是BCEloss
ce_loss = self.crit(logits, label.float())
loss = (alpha * torch.pow(1 - pt, self.gamma) * ce_loss)
if self.reduction == 'mean':
loss = loss.mean()
if self.reduction == 'sum':
loss = loss.sum()
return loss
heatmap+offsets
对于Heatmap + Offsets的Ground Truth构建思路主要是Google在CVPR 2017上提出的,与单纯的Heatmap不同的是,Google的Heatmap指的是在距离目标关键点一定范围内的所有点的概率值都为1,在Heatmap之外,使用Offsets,即偏移量来表示距离目标关键点一定范围内的像素位置与目标关键点之间的关系。目前还没有在公开的论文看到有人比较过这两种Ground Truth构建思路的效果差异,但是个人认为Heatmap + Offsets不仅构建了与目标关键点之间的位置关系,同时Offsets也表示了对应像素位置与目标关键点之间的方向信息,应该要优于单纯的Heatmap构建思路。
heatmap 是作者提出的二值热图,指的是距离目标关节点一定范围内的所有点的概率值都为1,其余为0。
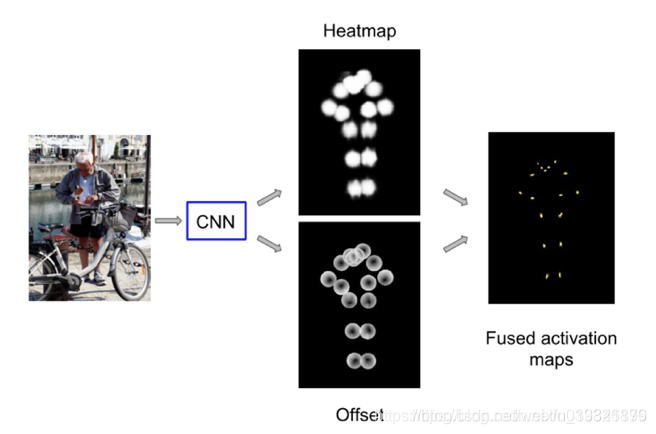
offsets 用来表示所有概率为1的点与目标关节点之间的指向关系。
输入是heatmap(K channel,每一个关键点一个channel)和offset(2
K channel,每一个关键点两个channel,分别是x和y坐标),输出是3
K个channel。
关于融合,对于每一个关节点和每一个空间位置,计算该位置是关节点的概率,这样生成K个关键点,之后将这个问题转换为一个二分类问题。另一方面,预测每一个位置与标准位置的距离,将其转换为一个2D回归问题。这样就将融合分成了二分类和2D回归两个问题。
Wing loss
Wing loss个人觉得不靠谱,说的是网络最后经过全连接输出关键点的位置2L(L代表关键点个数),对于这种回归的方式个人局的很不靠谱。