目录
摘要
通过估计源和目标服装区域之间的密集流,ClothFlow有效地模拟几何变化,并自然地将外观转换为合成的新图像。
三阶段模型:
- 首先,根据目标姿势估计人的语义布局。
- 然后,基于两个特征金字塔网络,级联流估计网络准确地估计相应服装区域之间的外观匹配。生成的密集流扭曲源图像以灵活地表达变形。
- 最后,生成网络将扭曲的服装区域作为输入并渲染目标视图。
为了解决服装形状匹配的问题,目前有两种方法:
-
deformation-based methods 基于变形的方法→
自由度有限,在发生大的几何变化时不准确和不自然的变换估计
-
DensePose-based methods 基于密集姿势的方法→DensePose能够将2D图像的人像素映射到3D人体表面,从而允许其传递身体的3D几何信息。使得即使在大空间变形的情况下,也更容易获得源图像和目标图像之间的纹理对应关系。但
进一步引入了伪影
,如在源图像中不可见的位置产生孔洞。
估计DensePose极具挑战性,与变形相比,传递的结果不够真实
。
为了解决现有方法的问题,提出了基于流的生成模型。与大多数基于变形的方法相比,ClothFlow估计了密集的流场(eg.2×256×256),在捕捉空间变形时具有较高的灵活性和准确性。
方法

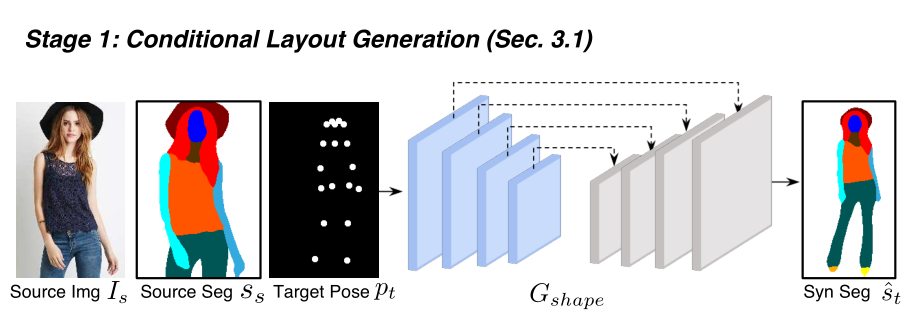
1.条件布局生成
使用现成的姿态估计器OPENPOSE和人体解析器PGN。姿势估计器预测人关键点的一组2D坐标,然后将其转换为热图。将布局信息编码为多通道二进制映射,使得每个通道指示特定人类部分的语义分割。目标布局生成网络Glyout具有编码器-解码器架构,使用像素交叉熵损失来约束。
2.级联服装流估计
预测的目标布局为理解目标域中服装的变换提供了线索,探索该信息以估计源图像和目标图像中服装区域之间的密集外观流。
受最近采用金字塔结构来逐步细化视频光流估计的方法的启发,提出了一种级联扭曲网络。此处只关注服装流,皮肤区域由香草生成模型生成。
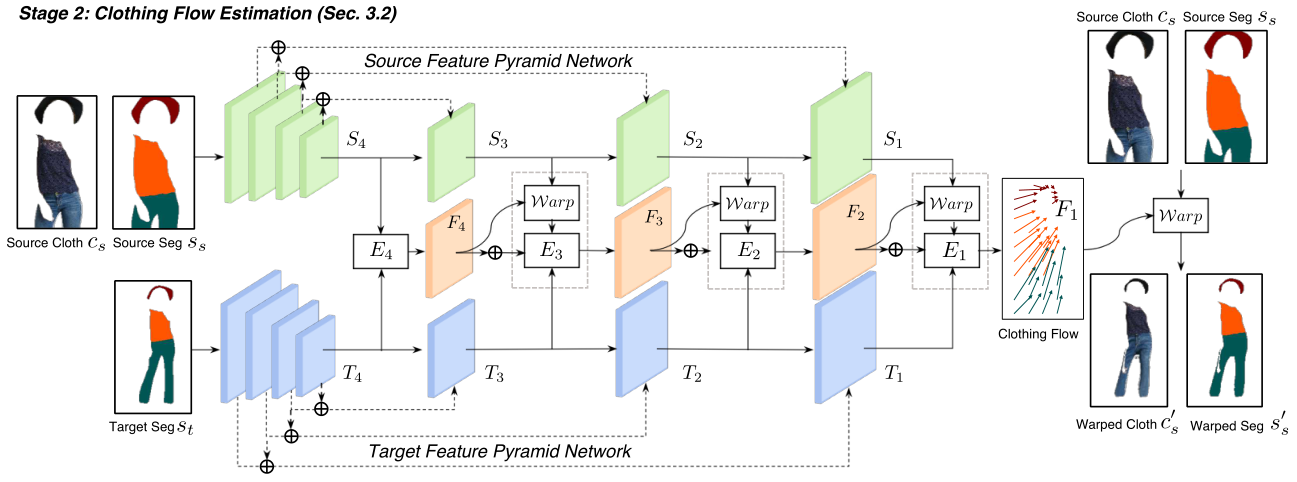
Dual Feature Pyramid Networks 双特征金字塔网络
1.源FPN
将源服装区域Cs和源服装分割图Ss作为输入,由N个编码层组成,步幅为2的下采样层和残差块。源特征金字塔,产生一组特征{S1,S2,…,SN}。
2.目标FPN
目标FPN与源FPN有类似的结构,输入为目标语义布局St,产生特征T1,T2,…,TN}。
得到的金字塔特征用于以级联方式估计从源服装Cs到目标服装Ct的服装流。
Clothing Flow Estimation 服装流估计
将级联的S和T馈送到卷积层En,以产生初始的服装流Fn,对于更高层金字塔中的特征,扭曲基于Fn的源特征,并通过后续的卷积层En-1预测残差流来细化Fn。
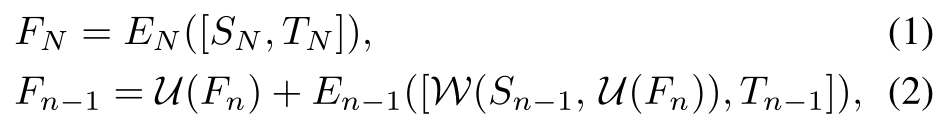
W(S,F)表示根据使用双线性插值的流F的扭曲特征图S,使得能够在训练期间通过反向传播进行优化。
感知
损失
:
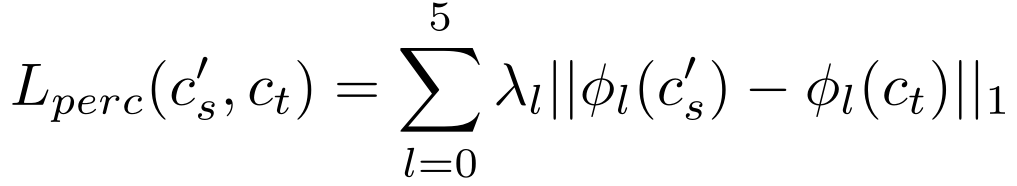
设计了结构损失:
![]()
修改了感知损失,以了解服装感兴趣区域,指导模型专注于扭曲每个ROI的纹理

使用密集流通常会在没有适当正则化的情况下呈现出不吸引人的伪影,因此我们进一步引入了总变化损失,该总变化损失正则化了估计的流场以增强平滑度:
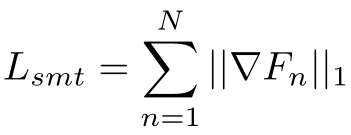
3.服装保存渲染
使用编码器-解码器生成网络生成最终结果
条件布局生成器和渲染生成器是具有跳过连接的
U-Net
型网络。两个
FPN的主干具有与U-Net的编码器
相似的结构。
结果
