Transformer属于seq2seq模型,解决输入时序列,输出也是序列,并且输出长度由机器自己决定的问题。
一、seq2seq的应用
-
语音识别:输入声音讯号,输出对应的文字
-
机器翻译:输入一段英文,输出对应的一段中文

-
语音翻译:将听到的一段声英语,翻译成中文字

- 语音合成:输入一段文字,输出对应的语种声音翻译
- 聊天机器人
- 提取文章的摘要
对于不同的任务,应该客制化对应的seq2seq模型,这样效果更好。
二、transfomer的架构
input——encoder(编译)——decoder(解译)——output

(一)Encoder
【一般的seq2seq】
-
总的来看,Encoder要做的事情,就是给一排向量,输出另外一排长度相同的向量。可以采用self-attention、CNN、RNN。其中包含了很多个block,而每个block都包含了sa和fc。
- Encoder里面,会分成很多很多的block。每一个block都是输入一排向量,输出一排向量。每一个block裡面做的事情,是好几个layer在做的事情。
-
每个block中,包括了self-attention和FC。先做一个self-attention,input一排vector以后,做self-attention,考虑整个sequence的资讯,Output另外一排vector。接下来这一排vector,会再丢到fully connected的feed forward network裡面,再output另外一排vector,这一排vector就是block的输出。

【transformer】
1. block的框架补充
每个block中,都是self-attention+residual connection——layer normalization——FC——layer normalization
- 01-self-attention+residual connection:在self-attention的output的基础上加上input,得到新的vec。加上residual connection的目的是:
- 02-layer normalization比batch normalization更简单。batch normalization是对不同example,不同feature的同一个dimension,去计算mean跟standard deviation。layer normalization==,它是对同一个feature,同一个example裡面,不同的dimension,去计算mean跟standard deviation。将此作为FC的输入。
- 04-FC的输出还要再做一次layer normalization,才是一个block的输出结果。

2. input到block之间的细节补充
- 在input的地方,还有加上positional encoding
-
block中的self-attention要用Multi-Head Attention

(二)Decoder
-
输入形式
:依次输入从encoder输出的seq中的token,每一个 Token,都可以把它用一个 One-Hot 的 Vector来表示,One-Hot Vector 就其中一维是 1,其他都是 0。 -
输入与输出的衔接
:Decoder 会把自己的输出,当做接下来的输入。 -
decoder输入与输出的方法
:Autoregression / Non-Autoregression
1. Autoregressive(AT)
(1)输入与输出
把 Encoder 的输出先读进去,依次向decoder输入其中的向量。
01-输入start ,经过decoder,产生一个向量,经softmax输出评分最高的值。
02-把上一个向量的输出作为 Decoder 新的 Input。
…重复上述步骤

(2)decoder的内部结构
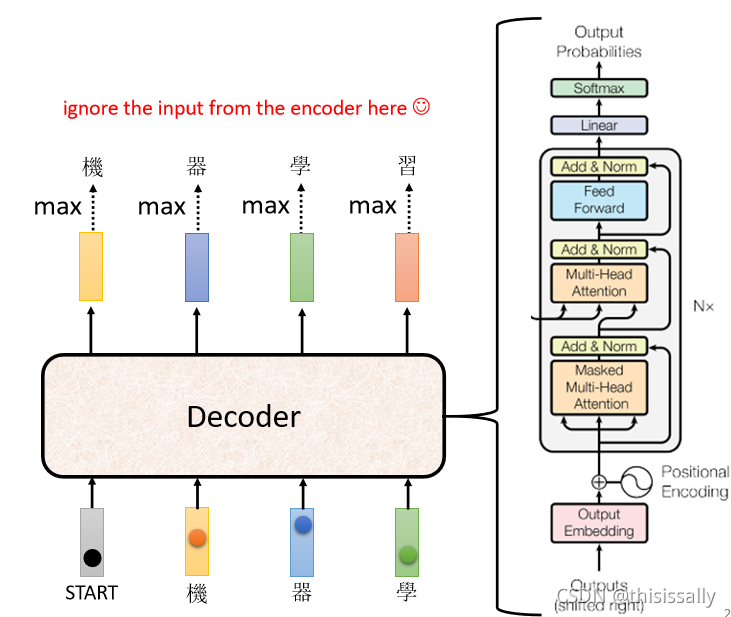
decoder vs. encoder

- 同: Encoder 这边,Multi-Head Attention,然后 Add & Norm,Feed Forward,Add & Norm,重复 N 次,Decoder 其实也是一样
-
异:01-输出的时候需要先做softmax。02-Multi-Head Attention 这一个 Block 上面,还加了一个masked 。它的作用是输出一个向量的时候,只考虑前面的a,不考虑在它后面的a。比如:
b1
b^1
b
1
的时候,我们只能考虑
a1
a^1
a
1
的资讯,你不能够再考虑
a2
a^2
a
2
a3
a^3
a
3
a4
a^4
a
4
。讲得更具体一点,你做的事情是,当我们要產生
b2
b^2
b
2
的时候,我们只拿第二个位置的 Query
b2
b^2
b
2
,去跟第一个位置的 Key,和第二个位置的 Key,去计算 Attention,第三个位置跟第四个位置,就不管它,不去计算 Attention。之所以这样做,和decoder的输入输出形式相关。因为对 Decoder 而言,先有
a1
a^1
a
1
才有
a2
a^2
a
2
,才有
a3
a^3
a
3
才有
a4
a^4
a
4
,所以实际上,当你有
a2
a^2
a
2
,你要计算
b2
b^2
b
2
的时候,你是没有
a3
a^3
a
3
跟
a4
a^4
a
4
的,所以你根本就没有办法把
a3
a^3
a
3
a4
a^4
a
4
考虑进来。

(3)stop token

2. Non-autoregressive(NAT)
-
特点
:NAT与AT最大的差异在于,NAT可以平行运算,NAT 的 Decoder可能吃的是一整排的 BEGIN 的 Token,你就把一堆一排
BEGIN 的 Token 都丢给它,让它一次產生一排 Token 就结束了。 -
输出长度的确定
:另外learn一个 Classifier,这个 Classifier ,它吃 Encoder 的 Input,然后输出是一个数字,这个数字代表 Decoder 应该要输出的长度,这是一种可能的做法

3. NAT vs. AT
(1)NAT支持平行化,速度快
(2)NAT的decoder可以控制输出的长度
(3)AT的效果往往比NAT好

(三)Encoder与Decoder之间的资讯传递——cross attention
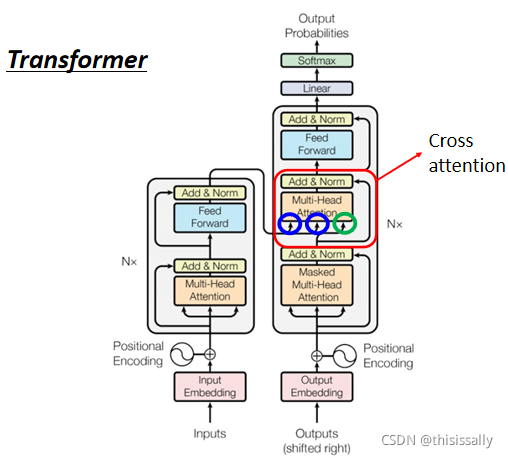
q 来自於 Decoder,k 跟 v 来自於 Encoder

三、transformer的训练——Teacher Forcing
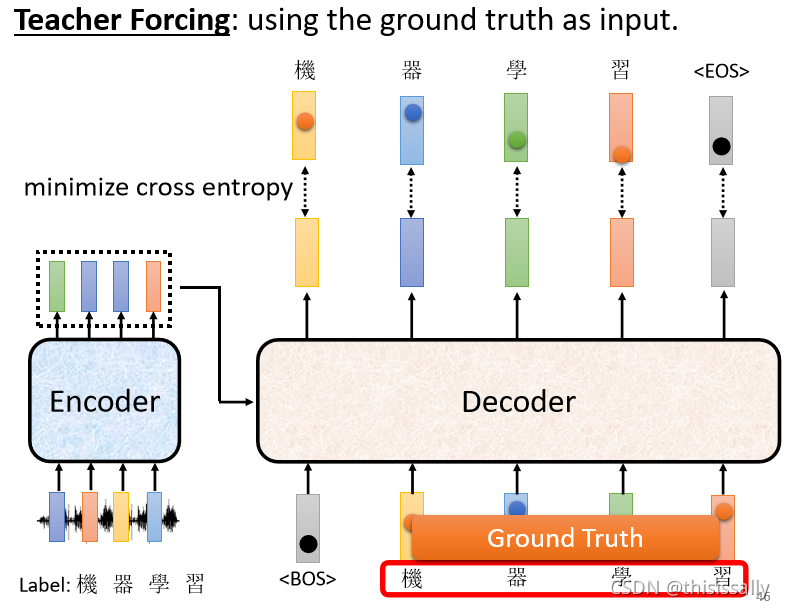
把正确答案给Decoder,希望 Decoder 的输出跟正确答案越接近越好。
四、Seq2seq的训练技巧
(一)Copy Mechanism:重复利用简化训练
Decoder 没有必要自己创造输出出来,它需要做的事情,也许是从输入的东西裡面复製一些东西出来。机器的训练显然会比较容易,它显然比较有可能得到正确的结果。
e.g.01-聊天机器人

02-摘要
从文章裡面直接复製一些资讯出来
(二)Guided Attention:固定模式防止缺漏
在训练资料裡面,非常短的句子很少,就容易输出错误结果。所以需要强迫它,一定要把输入的每一个东西通通看过。Guiding Attention 要做的事情就是,要求机器它在做 Attention 的时候,是有固定的方式的,举例来说,对语音合成或者是语音辨识来说,我们想像中的 Attention,应该就是由左向右。

(三)Beam Search——以退为进
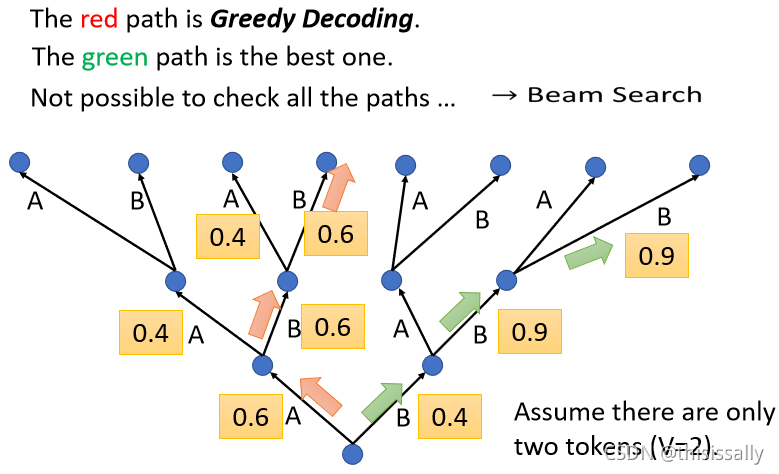
绿色的路,虽然一开始第一个步骤,你选了一个比较差的输出,但是接下来的结果是好的。答案非常明确的仍无,Beam Search 的作用显著;需要机器发挥一点创造力的时候,这时候 Beam Search 就比较没有帮助。
(四)Scheduled Sampling:早见noise就不至于一步错步步错
怎样应对decoder中一步错步步错的问题?——给 Decoder 的输入加一些错误的东西

五、seqseq的评级指标——BLEU
