第3.1课 原子操作
和许多多线程并行问题一-样,CUDA也存在互斥访问的问题,即当一个线程改变变量X,而另外一个线程在读取变量X的值,就会存在问题。而执行原子操作类似于有一个自旋锁,只有等X的变量在改变完成之后,才能执行读操作,这样可以保证每一次读取的都是最新的值.
原子操作很明显的会影响程序性能,所以可以的话,尽可能避免原子操作.
常用原子操作:

在涉及多block间进行统计操作时,由于不同block间无法进行通讯,因此进行统计操作时需要依赖于原子操作。
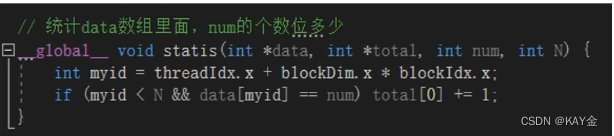
实例:
错误的
统计方式
实例:
正确的
统计方式

第一种统计方式会出现结果错误,因为total[0]的取值和写值在不同线程之间会出现冲突。
代码:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "curand.h"
#include "curand_kernel.h"
#include <stdio.h>
#include <iostream>
using namespace std;
// 统计data数组里面,num的个数位多少
__global__ void statis(int *data, int *total, int num, int N) {
int myid = threadIdx.x + blockDim.x * blockIdx.x;
if (myid < N && data[myid] == num) total[0] += 1;
}
__global__ void atomic_statis(int *data, int *total, int num, int N) {
int myid = threadIdx.x + blockDim.x * blockIdx.x;
if (myid < N && data[myid] == num) atomicAdd(&total[0], 1);
}
int main() {
int N = 1 << 10;
int threadNum = 32;
int blocks = N / 32 + 1;
int *data = (int*)malloc(N * sizeof(int));
int total_h[1];
memset(data, 0, N);
int *total_d, *data_d;
cudaMalloc((void **)&data_d, N * sizeof(int)); //GPU侧声明随机数存储缓冲器的内存空间
cudaMalloc((void **)&total_d, sizeof(int));
cudaMemset(total_d, 0, 1);
for (int i = 0; i < 128; i++)
{
data[i] = 1;
}
cudaMemcpy(data_d, data, N * sizeof(int), cudaMemcpyHostToDevice);
statis << <blocks, threadNum >> > (data_d, total_d, 1, N);
cudaMemcpy(total_h, total_d, sizeof(int), cudaMemcpyDeviceToHost);
cout << "total:" << total_h[0] << endl;
cudaMemset(total_d, 0, 1);
cudaMemcpy(data_d, data, N * sizeof(int), cudaMemcpyHostToDevice);
atomic_statis << <blocks, threadNum >> > (data_d, total_d, 1, N);
cudaMemcpy(total_h, total_d, sizeof(int), cudaMemcpyDeviceToHost);
cout << "total:" << total_h[0] << endl;
free(data);
free(total_h);
cudaFree(data_d);
cudaFree(total_d);
return 0;
}
版权声明:本文为qq_45605440原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。