antlr4 代码 语法树
DSL是很酷的东西,但我不清楚它们有什么用。
然后我意识到它们对以下方面有好处:
- 摆脱复杂的UI
意思是
- 更快的做事方式
而已。 当我阅读此
博客
时,我得出了这个结论。
如果您的用户是技术人员,并且不惧怕类似SQL的语法处理方式,则DSL特别适合
- 你有语法高亮
- 你有代码补全
否则,DSL有点烂。
因此,我不得不向客户提出一些概念证明。 他有模糊的要求,要准确提取团队的需求并不容易(他们需要很多东西,而且他很忙),因此DSL可以在此过程中提供很多帮助,因为人们被迫在他们需要时才想清楚他们的需求面对一种语法(甚至很小的一种)。
因此,我采用了以下技术:
-
用于代码镜像的JSF库Primefaces扩展
-
ANTLR4
(与ANTLR3相比有很大的改进,而且本书很棒)
不幸的是,我无法在两个工具中重复使用语法。 实际上,我找不到任何可以做到这一点的解决方案。 至少对于基于Web的JSF解决方案。 而且没有时间学习。 所以我不得不稍微改一下。
首先,我们需要语法。 ANTLR4比ANTLR3更好,因为现在接线代码是通过访问者和侦听器完成的。 语法内没有更多的Java代码。 那很棒,而且更容易使用。
所以你可以有一个这样的语法
grammar Grammar;
options
{
language = Java;
}
@lexer::header {
package parsers;
}
@parser::header {
package parsers;
}
eval : expr EOF;
expr : 'JOB' (jobName)? type 'TARGET' targetList ('START' startExpr)?
startExpr
: 'AT' cronTerm
| 'AFTER' timeAmount timeUnits;
timeAmount: INT;
jobName: STRING;
targetList: STRING (',' STRING)*;
type : deleteUser
| createUser;
deleteUser: opDelete userName;
createUser: opCreate userName;
opDelete: 'DELETE';
opCreate: 'CREATE';
userName: STRING;
cronTerm: '!'? (INT | '-' | '/' | '*' | '>' | '<')+;
timeUnits
: 'MINUTES'
| 'HOURS'
| 'DAYS'
| 'WEEKS'
| 'MONTHS';
WS : [ \t\r\n]+ -> skip;
STRING
: '"' ( ESC_SEQ | ~('\\'|'"') )* '"'
;
fragment
HEX_DIGIT : ('0'..'9'|'a'..'f'|'A'..'F') ;
fragment
ESC_SEQ
: '\\' ('b'|'t'|'n'|'f'|'r'|'\"'|'\''|'\\')
| UNICODE_ESC
| OCTAL_ESC
;
fragment
OCTAL_ESC
: '\\' ('0'..'3') ('0'..'7') ('0'..'7')
| '\\' ('0'..'7') ('0'..'7')
| '\\' ('0'..'7')
;
fragment
UNICODE_ESC
: '\\' 'u' HEX_DIGIT HEX_DIGIT HEX_DIGIT HEX_DIGIT
;
ID : ('a'..'z'|'A'..'Z'|'_') ('a'..'z'|'A'..'Z'|'0'..'9'|'_')*
;
INT : '0'..'9'+
;要编译语法,请尝试
public static void main(String[] args) {
String[] arg0 = {"-visitor","/pathto/Grammar.g4"};
org.antlr.v4.Tool.main(arg0);
}然后,ANTLR将为您生成类。
在我们的例子中,我们想访问解析树并检索我们想要的值。 我们这样做扩展了生成的抽象类。
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.StringTokenizer;
import org.antlr.v4.runtime.tree.ErrorNode;
import bsh.EvalError;
import bsh.Interpreter;
public class MyLoader2 extends GrammarBaseVisitor<Void> {
private String jobName,cronTerm,timeUnits,userName,jobType;
private List<String> targetList;
private boolean now,errorFound;
private int timeAmount;
private Interpreter bsh = new Interpreter();
private String eval(String s) throws EvaluationException{
try {
if (!s.startsWith("\"")){
return s;
}
bsh.eval("String s="+s);
return (String)bsh.eval("s");
} catch (EvalError e) {
throw new EvaluationException(s);
}
}
@Override
public Void visitTimeAmount(TimeAmountContext ctx) {
try{
this.timeAmount = Integer.parseInt(ctx.getText());
}catch(java.lang.NumberFormatException nfe){
throw new InvalidTimeAmountException(ctx.getText());
}
return super.visitTimeAmount(ctx);
}
@Override
public Void visitUserName(UserNameContext ctx) {
this.userName = eval(ctx.getText());
return super.visitUserName(ctx);
}
@Override
public Void visitCronTerm(CronTermContext ctx) {
this.cronTerm = eval(ctx.getText());
return super.visitCronTerm(ctx);
}
@Override
public Void visitTimeUnits(TimeUnitsContext ctx) {
this.timeUnits = ctx.getText();
return super.visitTimeUnits(ctx);
}
@Override
public Void visitTargetList(TargetListContext ctx) {
this.targetList = toStringList(ctx.getText());
return super.visitTargetList(ctx);
}
@Override
public Void visitJobName(JobNameContext ctx) {
this.jobName = eval(ctx.getText());
return super.visitJobName(ctx);
}
@Override
public Void visitOpCreate(OpCreateContext ctx) {
this.jobType = ctx.getText();
return super.visitOpCreate(ctx);
}
@Override
public Void visitOpDelete(OpDeleteContext ctx) {
this.jobType = ctx.getText();
return super.visitOpDelete(ctx);
}
private List<String> toStringList(String text) {
List<String> l = new ArrayList<String>();
StringTokenizer st = new StringTokenizer(text," ,");
while(st.hasMoreElements()){
l.add(eval(st.nextToken()));
}
return l;
}
private Map<String, String> toMapList(String text) throws InvalidItemsException, InvalidKeyvalException {
Map<String, String> m = new HashMap<String, String>();
if (text == null || text.trim().length() == 0){
return m;
}
String[] items = text.split(",");
if (items.length == 0){
throw new InvalidItemsException();
}
for(String item:items){
String[] keyval = item.split("=");
if (keyval.length == 2){
m.put(keyval[0], keyval[1]);
}else{
throw new InvalidKeyvalException(keyval.length);
}
}
return m;
}
public String getJobName() {
return jobName;
}
public String getCronTerm() {
return cronTerm;
}
public String getTimeUnits() {
return timeUnits;
}
public String getUserName() {
return userName;
}
public String getJobType() {
return jobType;
}
public List<String> getTargetList() {
return targetList;
}
public boolean isNow() {
return now;
}
public int getTimeAmount() {
return timeAmount;
}
@Override
public Void visitOpNow(OpNowContext ctx) {
this.now = ctx.getText().equals("NOW");
return super.visitOpNow(ctx);
}
public boolean isErrorFound() {
return errorFound;
}
@Override
public Void visitErrorNode(ErrorNode node) {
this.errorFound = true;
return super.visitErrorNode(node);
}
}
请注意,
beanshell
解释器用于将“ xyz”之类的字符串评估为xyz。 这对于其中包含转义引号和字符的字符串特别有用。
因此,您有了语法和visiter / loader bean,然后我们可以对其进行测试:
private static MyLoader getLoader(String str){
ANTLRInputStream input = new ANTLRInputStream(str);
GrammarLexer lexer = new GrammarLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
GrammarParser parser = new GrammarParser(tokens);
ParseTree tree = parser.eval();
MyLoader loader = new MyLoader();
loader.visit(tree);
return loader;
}
public static void main(String[] args){
MyLoader loader = getLoader("JOB \"jobName\" CREATE \"myuser\" TARGET \"site1\",\"site2\" START AFTER 1 DAY");
System.out.println(loader.getJobName());
System.out.println(loader.getJobType());
}
大。 现在是黑客。 Code Mirror支持自定义语法,但
JSF Primefaces扩展中不存在
。 因此,我打开了resources-codemirror-1.2.0.jar,打开了/META-INF/resources/primefaces-extensions/codemirror/mode/modes.js文件,对其进行了
格式化
(以便我可以阅读),然后我刚刚选择了最简单的语言作为我的新自定义sintax荧光笔!
我改名了
(...)
}, "xml"), CodeMirror.defineMIME("text/x-markdown", "markdown"), CodeMirror.defineMode("mylanguage", function (e) {
(...)
var t = e.indentUnit,
n, i = r(["site", "type", "targetList"]),
s = r(["AT","AFTER","CREATE","MINUTES","HOURS","TARGET","MONTHS","JOB","DAYS","DELETE","START","WEEKS" ]),
(...)
}), CodeMirror.defineMIME("text/x-mylanguage", "mylanguage"), CodeMirror.defineMode("ntriples", function () {(...)那些在“ s = r”中用大写字母表示的标记是将被突出显示的标记,而在“ i = r”中的那些标记则是将被突出显示的标记。 为什么我们都想要? 因为第二种类型是“占位符”,我的意思是,我们将它们用于自动填充内容。
好,那么您的JSF xhtml页面将如下所示
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:p="http://primefaces.org/ui"
xmlns:pe="http://primefaces.org/ui/extensions">
<h:body>
<h:form id="form">
<pe:codeMirror
id="codeMirror"
style="width:600px;"
mode="myLanguage"
widgetVar="myCodeMirror"
theme="eclipse"
value="#{myMB.script}"
lineNumbers="true"
completeMethod="#{myMB.complete}"
extraKeys="{ 'Ctrl-Space': function(cm) { PF('myCodeMirror').complete(); }}"/>
<p:commandButton value="Verify" action="#{myMB.verify}" />
(...)现在,我们需要自动完成功能。 这是无聊的部分。 您必须手动完成大部分的完成工作,因为没有上下文信息(请记住,我没有时间学习……),所以快速而肮脏的方式是这样的
in myMB
public List<String> complete(final CompleteEvent event) {
try {
return this.myEJB.complete(event.getToken());
} catch (Exception e) {
jsfUtilEJB.addErrorMessage(e,"Could not complete");
return null;
}
}
in myEJB
private static final String SITE = "site_";
public List<String> complete(String token) throws Exception {
if (token == null || token.trim().length() == 0){
return null;
}else{
List<String> suggestions = new ArrayList<String>();
switch(token){
//first search variables
case "targetlist":
for(String v:TARGETS){
suggestions.add(v);
}
break;
case "site":
List<Site> allSites = this.baseService.getSiteDAO().getAll();
for(Site s:allSites){
suggestions.add("\""+SITE+s.getName()+"\"");
}
break;
case "type":
suggestions.add("DELETE \"userName\"");
suggestions.add("CREATE \"userName\"");
break;
case "AT":
suggestions.add("AT \"cronExpression\"");
suggestions.add("AT \"0 * * * * * * *\"");
break;
case "AFTER":
for(int a:AMOUNTS){
for(String u:UNITS){
if (a == 1){
suggestions.add("AFTER"+" "+a+" "+u);
}else{
suggestions.add("AFTER"+" "+a+" "+u+"S");
}
}
}
break;
case "TARGET":
for(String v:TARGETS){
suggestions.add("TARGET "+v+"");
}
break;
case "JOB":
suggestions.add("JOB \"jobName\" \ntype \nTARGET targetlist \nSTART");
break;
case "START":
suggestions.add("START AT \"cronExpression\"");
suggestions.add("START AT \"0 * * * * * * *\"");
for(int a:AMOUNTS){
for(String u:UNITS){
if (a == 1){
suggestions.add("START AFTER"+" "+a+" "+u);
}else{
suggestions.add("START AFTER"+" "+a+" "+u+"S");
}
}
}
suggestions.add("START NOW");
break;
case "DELETE":
suggestions.add("DELETE \"userName\"");
break;
case "CREATE":
suggestions.add("CREATE \"userName\"");
break;
default:
if (token.startsWith(SITE)){
List<Site> matchedSites = this.baseService.getSiteDAO().getByPattern(token.substring(SITE.length())+"*");
for(Site s:matchedSites){
suggestions.add("\""+SITE+s.getName()+"\"");
}
}else{
//then search substrings
for(String kw:KEYWORDS){
if (kw.toLowerCase().startsWith(token.toLowerCase())){
suggestions.add(kw);
}
}
}
}//end switch
//remove dups and sort
Set<String> ts = new TreeSet<String>(suggestions);
return new ArrayList<String>(ts);
}
}
private static final int[] AMOUNTS = {1,5,10};
private static final String[] UNITS = {"MINUTE","HOUR","DAY","WEEK","MONTH"};
private static final String[] TARGETS = {"site"};
/*
* KEYWORDS are basic suggestions
*/
private static final String[] KEYWORDS = {"AT","AFTER","CREATE","MINUTES","HOURS","TARGET","MONTHS","JOB","DAYS","DELETE","START","WEEKS"};因此,关键字的自动填充内容将仅向您显示字段和更多关键字,而“占位符”(还记得jar中的codemirror javascript中的小写关键字吗?)是从数据库中检索到的动态值(用于实际值)完成的。 另外,您可以使用部分字符串来检索以子字符串开头的那些字符串,如下所示:
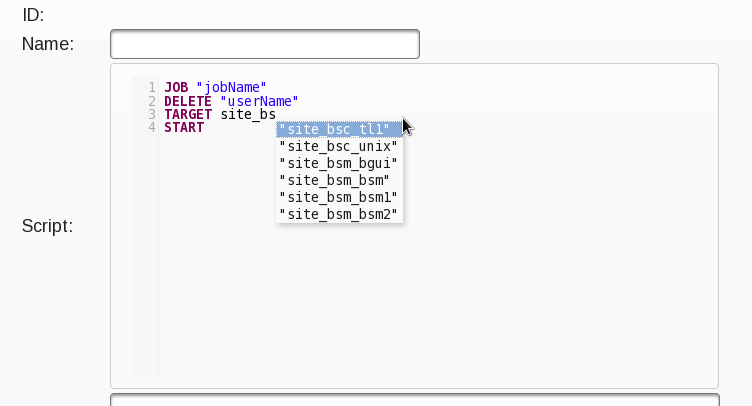
当然,在JPA中类似模式的搜索可以这样执行:
public abstract class GenericDAO<E> {
protected EntityManager entityManager;
private Class<E> clazz;
private EntityType<E> pClass;
@SuppressWarnings("unchecked")
public GenericDAO(EntityManager entityManager) {
this.entityManager = entityManager;
ParameterizedType genericSuperclass = (ParameterizedType) getClass().getGenericSuperclass();
this.clazz = (Class<E>) genericSuperclass.getActualTypeArguments()[0];
EntityManagerFactory emf = this.entityManager.getEntityManagerFactory();
Metamodel metamodel = emf.getMetamodel();
this.pClass = metamodel.entity(clazz);
}
public List<E> getByPattern(String pattern) {
pattern = pattern.replace("?", "_").replace("*", "%");
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<E> q = cb.createQuery(clazz);
Root<E> entity = q.from(clazz);
SingularAttribute<E, String> singularAttribute = (SingularAttribute<E, String>) pClass.getDeclaredSingularAttribute(getNameableField(clazz));
Path<String> path = entity.get(singularAttribute);
q.where(cb.like(path, pattern));
q.select(entity);
TypedQuery<E> tq = entityManager.createQuery(q);
List<E> all = tq.getResultList();
return all;
}
private String getNameableField(Class<E> clazz) {
for(Field f : clazz.getDeclaredFields()) {
for(Annotation a : f.getAnnotations()) {
if(a.annotationType() == Nameable.class) {
return f.getName();
}
}
}
return null;
}
(...)其中Nameable是您的实体类的注释:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD})
public @interface Nameable {
}用它来注释实体类中的单个列,即String。 像这样:
@Entity
@Table(uniqueConstraints=@UniqueConstraint(columnNames={"name"}))
public class Site implements Serializable {
/**
*
*/
private static final long serialVersionUID = 8008732613898597654L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Nameable
@Column(nullable=false)
private String name;
(...)
当然,“验证”按钮只是获取您的脚本并将其推入加载器。
antlr4 代码 语法树