原文地址:
https://adeshpande3.github.io/adeshpande3.github.io/Deep-Learning-Research-Review-Week-2-Reinforcement-Learning
每周都会分享一些关于深度学习的知识,这周主要分享的就是强化学习。
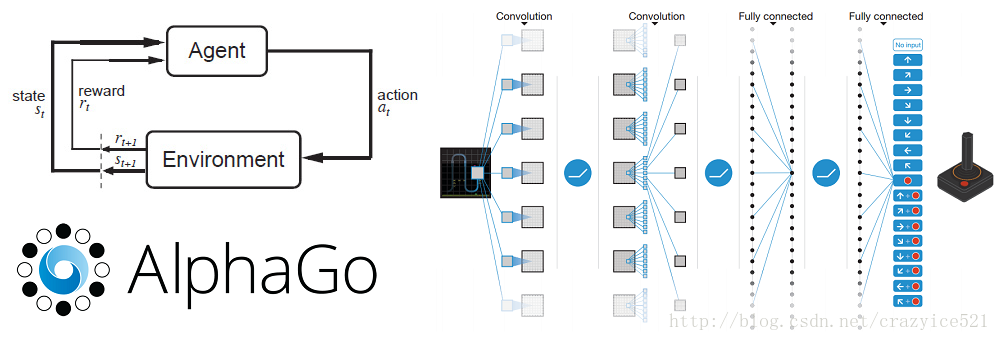
强化学习介绍
机器学习的三个分类
在深入了解这篇文章之前,我们先讨论一下什么是强化学习。机器学习领域大致可以分为三个主要的分类。
1、监督学习
2、无监督学习
3、强化学习
第一个分类,
监督学习
,肯定是你最熟悉的一个。他主要依赖于基于一些包含训练数据和标签的训练样本构建一个函数或者模型。卷积神经网络就是一个例子,输入的是图片,输出的是图片的分类信息(狗,猫等)。
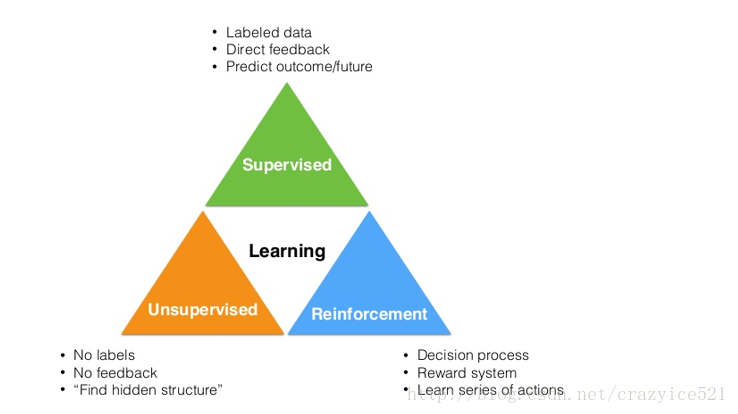
无监督学习
试图去找到数据的内在结构并进行分类。一个比较众所周知的机器学习聚类算法,K-means,是无监督学习的一个例子。
强化学习
的任务就是去学习在给定的环境
environment
做什么行为
action
,以使得奖励值最大。强化学习和监督学习最大的区别就是,强化学习不会告诉你怎么做,只能告诉你你做这个行为的好坏。也不能告诉你所做的哪个行为是最好的。和卷积神经网络也不一样,卷积神经网络主要是给图片一个定义。另外一个独特的成分就是Agent的行为将会影响他接下来接受到的数据。举个例子:Agent的行为向左移动而不是向右移意味着Agent会接收到不同的环境输入在接下来的时间里。我们以一个例子开始。
强化学习问题
首先,我们考虑一个强化学习的问题。我们想象一下在一个小的房间里面有一个小的机器人。我们没有对这个机器人进行任何的编程让他去做任何的行为。这个机器人就站在那里不动。这个机器人就是我们的Agent。
就像我们上面所说的那样,强化学习就是试着去理解做决定的最优路径使得我们的奖励函数R最大。这个奖励就是一个回馈信号,表示这我们的Agent在这个时间点做的时间的好坏的判断。一个Agent做了一个行为A在每一个时间就是一个关于
奖励(信号表明Agent做了这个行为的好坏)和状态S
的函数,描述了Agent所在的环境。从环境状态到行为的映射叫做策略P。这个策略定义了Agent在一个确定时间点的路,给定一个确定的状态。现在,我们有一个价值函数V,用来评价每一个位置的好坏。这个和奖励函数的不同之处在于奖励函数只是表明了在接下来一个场景的好坏,价值函数时表明在接下来长时间内这个行为的好坏。最后我们有一个模型M,就是Agent的环境代表。下面就是这个Agent的模型他去怎么考虑这个环境去做什么事情。


马尔科夫决策
现在,我们再回过头来考虑在小房间中的机器人。奖励函数就是决定我们希望Agent去完成的。或者那样说,我们想让他移动到房间的一个角落,当他到达角落的时候,他会得到一个奖励。这个机器人会得到一个+25当他到达我们制定的点,同时,在其他地点的每一步都会得到一个-1。我们就是想让这个机器人尽可能快的到达这个角落。Agent能做的行为就包括往东西南北四个方向移动。Agent的策略就是很简单的一个,就是使得所做的行为在到达目的地的时候所得到的价值函数最大。往右移动?价值函数高的位置=这个位置是可以到达的(关于长期奖励)
现在,整个强化学习环境能够被描述使用马尔科夫决策过程。对于那些以前没有听过这个名词的同学,MDP就是一个框架帮助Agent做决定。他包含一个有限的状态集(还有状态的价值函数),一个有限的行为集,策略,和奖励函数。我们的价值函数能够被分解为两个部分。
1、状态值函数V:
在给定的状态S和策略π的条件下得到的返回值。返回值通过着眼于未来每一步的奖励得到(伽马是一个固定的因子,表示在第十步的奖励权重比着第一步的小)
2.行为价值函数Q:
在给定的状态S和策略π的条件下,执行行为a的时候所给出的返回值。(等式和上面的一样除了有一个额外的条件At = a)
现在,我们有了所有的成分,我们怎么是使用MDP去做呢?我们想要接解出他,当然。通过解出MDP,你能够发现一个最优的策略是的Agent从环境中得到的奖励值最大。
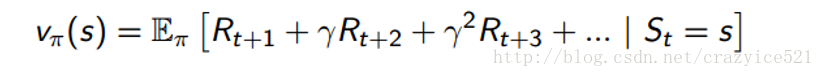
解MDP
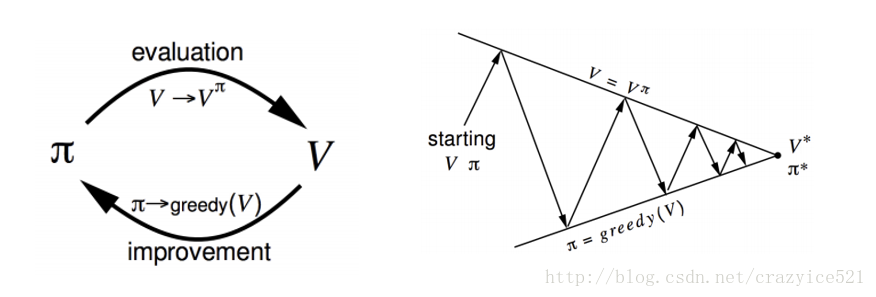
我们能够解MDP并且得到最优的策略通过动态规划和特别地使用策略迭代(另一种叫法叫做价值迭代,但是我们现在不深入去讲)。这个想法就是我们使用初始策略 π1并且计算当前策略下的状态值函数。我们做这个通过Bellman 期望等式。
这个等式基本的说明了我们的值函数,在给定状态π是,能够被分解为当前奖励Rt+1的期望和和成功状态St+1的价值函数。如果你想分开考虑这两个,这就等价于我们在前面章节定义的价值函数。使用这个等式是我们策略评价的一个成分。为了得到一个更好的策略,我们使用贪心策略算法提升。换句话说就是做得行为使得价值最大。
现在,为了得到最优的策略,我们重复这两步,一步接一步,知道达到我们的最优策略π*。
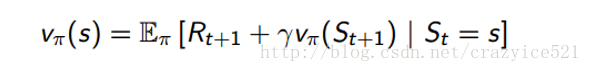
当你没有被给定一个MDP
决策迭代是好的也是全部的,但是他只是在给定MDP的时候起作用。MDP告诉你这个环境怎么起作用,但是在真是的场景当中并不会给出。当没有给定MDP的时候,我们使用函数和决策。当没有给定MDP的时候,我们将会继续做同样的步骤以便于策略的评价和策略的提升。
我们这样做替代提升我们的决策通过优化我们的行为价值函数Q而不是状态值函数。还记得我们是怎么拆分我们的状态值函数为瞬时奖励和未来成功奖励的值函数的和吗?好的,我们可以对Q用同样的方法。
现在,我们继续通过同样的步骤对策略评价和策略提升,除了我们是使用行为值函数Q替换掉状态值函数V。现在,我们将会跳过怎么改变提升的细节部分。为了理解MDP评价和提升的方法,像蒙特卡罗学习,时间差分学习和 SARSA 等这些,需要一整片的博客去讲解这些(如果你对这些感兴趣,你可以去听一下David Silver的课程4和课程5)。现在,然而,我们直接跳到值函数估计和在Alphago和Atari Papers中讨论的方法,同时期望能够尝到现在强化学习技术的滋味。主要的点是我们都想要找到最优的策略π*能够最大化我们的行为值函数Q。
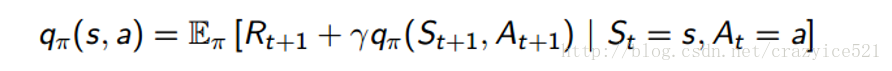
值函数预测
因此,如果你考虑我们提到过的每一件事情到現在,我们对待我们的问题以最简单的方式。现在看看上面的Q评价。我们使用特定的状态S和行为A,同时,计算一个数值告诉我们我们期望得到的是什么。现在,我们想象一下我们的Agent向右移动了1毫米。这就意味着我们有一个全新的状态S’,现在我们要去计算一个Q值。在真实世界的RL问题中,有数以万计的状态因此他是重要的我们的值函数能够理解一般化的不需要我们去保存每一个值函数对于每一个可能的状态。解决办法就是使用一个Q值函数估计能够一般化不知道的状态。
因此,我们需要的是一些函数,我们叫他为Q,能够给出Q值的预测在给定状态S和一些行为A之后。
这个函数继续在S,A,同时一个好的旧的价值权重向量W(一旦你看到W,你就应该明白我们使用了梯度下降)。之后计算x和W的点积(x是特征向量,代表S和A)。这个方法我们想要提升这个函数就是通过计算真正的Q值和函数的输出之间的差值。
在我们计算出loss之后,我们使用梯度下降找到最小值,就是哪一个点我们找到最优的W向量。当看到之后的论文之后这个价值函数预测的想法就是我们强化学习的核心内容。
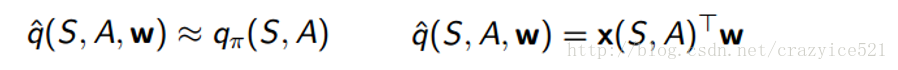
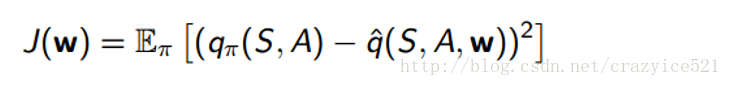
再多讲一点
在读这篇论文之前,在接触最后一个东西。一个有意思的讨论关于强化学习的话题就是探索对探索。探索就是Agent 的过程对所知道的事物的探索,之后能够做出行为知道产生最大的奖励。这听起来很好,对吗?Agent总会做出最好的行为基于他现在的知识。然而,有一个核心短语在那个状态。当前知识。如果Agent并没有足够探索状态空间,他就不能够知道是否做出的是最好的行为。这个做出决策的行为就是探索。
这个想法可以和真实世界样例联系起来。现在你有一个选择,今晚去哪个餐厅吃饭。你(作为Agent)知道你喜欢Mexican的食物,因此,在强化学习中,去一个Mexican餐厅吃饭肯定是最好的行为能够最大化你的奖励值,或者在这种情况你感觉到最舒适。然而,还有一个选择是Italian食物,你以前没有吃过的。有一个可能性就是他会比着Mexican食物好吃,或者更差。这个权衡在是否去探索Agent过去的知识和新的渴望探索一个更好的奖励是一个主要的挑战在强化学习当中。(在我们日常生活当中)
其他强化学习的资源
虽然大多数的信息都是没有意义的但是也是一个完整的回顾对整个领域。如果你想要一个更深层次的回顾对于强化学习,我会继续收集这些资源。
David Silver (from Deepmind) Reinforcement Learning
Video Lectures
Sutton and Barto’s
Reinforcement Learning Textbook
(This is really the holy grail if you are determined to learn the ins and outs of this subfield)
Andrej Karpathy’s
Blog Post
on RL (Start with this one if you want to ease into RL and want to see a really well done practical example)
UC Berkeley CS 188
Lectures 8-11
Open AI Gym
: When you feel comfortable with RL, try creating your own agents with this reinforcement learning toolkit that Open AI created