文章目录
全文约 12566 字,预计阅读时长: 36分钟
一 版权声明
上海贝尔网络应用-林锐


二 做题打分
三 博士的前言总结
- 知错就改;
- 经常温故而知新;
- 坚持学习,天天向上。
第一二章:
防止头文件被重复包含。
# ifndef famer_h
# define famer_h
//..
# endif
- <>头文件,编译器将引用标准库的头文件,从标准目录开始搜索、
-
“”头文件,将从用户的工作目录开始搜索,用户自己创建的头文件
- 头文件只存放声明,不存放定义
- 不建议使用全局变量

目录结构
-
如果一个软件的头文件数目比较多(如超过十个),通常应将头文件和定义文件分
- 别保存于不同的目录,以便于维护。
- 例如可将头文件保存于 include 目录,将定义文件保存于 source 目录(可以是多级
- 目录)。
- 如果某些头文件是私有的,它不会被用户的程序直接引用,则没有必要公开其“声明”。为了加强信息隐藏,这些私有的头文件可以和定义文件存放于同一个目录
程序的版式风格
清晰、美观,是程序风格的重要构成因素
-
空行起着分隔程序段落的作用。
- 空行不会浪费内存
- 【规则 2-1-1】在每个类声明之后、每个函数定义结束之后都要加空行。
-
【规则 2-1-2】在一个函数体内,逻揖上密切相关的语句之间不加空行,其它地方应加空行分隔。

代码行
一行代码只做一件事情,如只定义一个变量,或只写一条语句。这样的代码容易阅读,并且方便于写注释。
- if、for、while、do 等语句自占一行,执行语句不得紧跟其后。
- 不论执行语句有多少都要加{}。这样可以防止书写失误。
- 关键字之后要留空格。象 const、virtual、inline、case 等关键字之后至少要留一个空格,否则无法辨析关键字。象 if、for、while 等关键字之后应留一个空格再跟左括号‘(’,以突出关键字。
- 【规则 2-3-4】‘,’之后要留空格,如 Function(x, y, z)。如果‘;’不是一行的结束符号,其后要留空格,如 for(initialization; condition; update)。
-
【规则 2-3-5】赋值操作符、比较操作符、算术操作符、逻辑操作符、位域操作符,如“=”、“+=” “>=”、“<=”、“+”、“
”、“%”、“&&”、“||”、“<<”,“^”等二元操作符的前后应当加空格。

对齐
-
z 【规则 2-4-1】程序的分界符‘{’和‘}’应独占一行并且位于同一列,同时与引用它们的语句左对齐。
- 【规则 2-4-2】{ }之内的代码块在‘{’右边数格处左对齐
-

长行拆分
- 【规则 2-5-1】代码行最大长度宜控制在 70 至 80 个字符以内。代码行不要过长,否则眼睛看不过来,也不便于打印。
- 【规则 2-5-2】长表达式要在低优先级操作符处拆分成新行,操作符放在新行之首(以便突出操作符)。拆分出的新行要进行适当的缩进,使排版整齐,语句可读。
- 【规则 2-6-1】应当将修饰符 * 和 & 紧靠变量名 *
-
【规则 2-7-2】如果代码本来就是清楚的,则不必加注释。否则多此一举,令人厌烦。注释的花样要少

类的版式
- 类可以将数据和函数封装在一起,其中函数表示了类的行为(或称服务)。
-
类提供关键字 public、protected 和 private,分别用于声明哪些数据和函数是公有的、受保护的或者是私有的。
- 这样可以达到信息隐藏的目的,即让类仅仅公开必须要让外界知道的内容,而隐藏其它一切内容。我们不可以滥用类的封装功能,不要把它当成火锅,什么东西都往里扔。
- 将 private 类型的数据写在前面,而将 public 类型的函数写在后面,“以数据为中心”,重点关注类的内部结构。
- 将 public 类型的函数写在前面,而将 private 类型的数据写在后面,“以行为为中心”,重点关注的是类应该提供什么样的接口(或服务)。
-
建议“以行为为中心”的书写方式.

第三章:命名规则
- 【规则 3-1-1】标识符应当直观且可以拼读,可望文知意,不必进行“解码”。标识符最好采用英文单词或其组合,便于记忆和阅读。
- 【规则 3-1-2】标识符的长度应当符合“min-length && max-information”原则。
- 【规则 3-1-3】命名规则尽量与所采用的操作系统或开发工具的风格保持一致
Windows 简单的命名规则
-
Windows 应用程序的标识符通常采用“大小写”混排的方式,如 AddChild。而 Unix 应用程序的标识符通常采用“小写加下划线”的方式,如 add_child。
-
【规则 3-1-6】变量的名字应当使用“名词”或者“形容词+名词”。
-
【规则 3-1-7】全局函数的名字应当使用“动词”或者“动词+名词”(动宾词组)。
-
【规则 3-1-8】用正确的反义词组命名具有互斥意义的变量或相反动作的函数等.
//例如:
int minValue;
int maxValue;
int SetValue(…);
int GetValue(…)
-
【规则 3-2-1】类名和函数名用大写字母开头的单词组合而成。

-
【规则 3-2-3】常量全用大写的字母,用下划线分割单词。
-
【规则 3-2-4】静态变量加前缀 s_(表示 static)。
-
【规则 3-2-5】如果不得已需要全局变量,则使全局变量加前缀 g_(表示 global)。

-
【规则 3-2-6】类的数据成员加前缀 m_(表示 member),这样可以避免数据成员与_成员函数的参数同名。

-
【规则 3-2-7】为了防止某一软件库中的一些标识符和其它软件库中的冲突,可以为各种标识符加上能反映软件性质的前缀。例如三维图形标准 OpenGL 的所有库函数均以 gl 开头,所有常量(或宏定义)均以 GL 开头。
简单的 Unix 应用程序命名规则
- 这是个迷
第 4 章 表达式和基本语句
运算符的优先级
-
C++/C 语言的运算符有数十个,运算符的优先级与结合律如表 4-1 所示。注意一元运算符 + – * 的优先级高于对应的二元运算符。
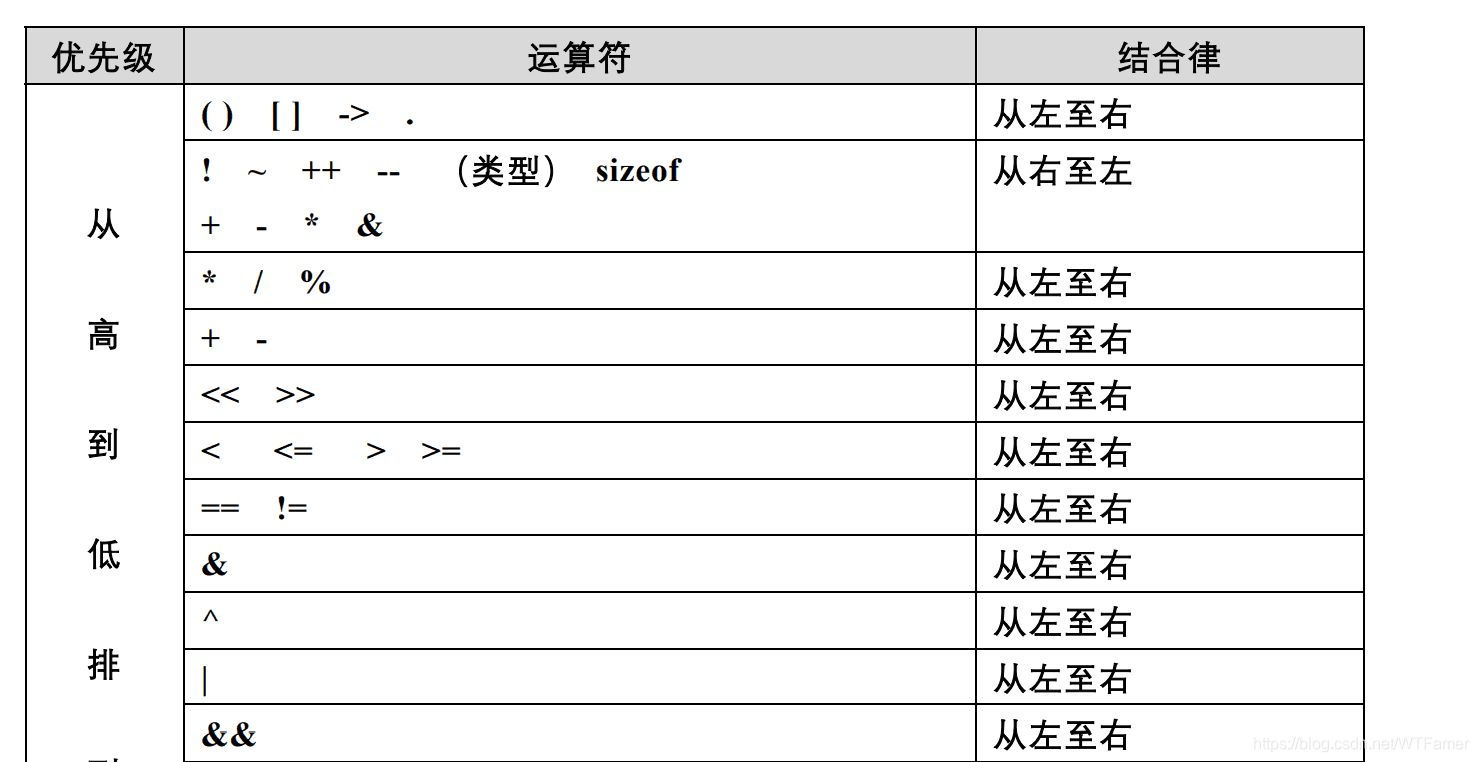

-
【规则 4-1-1】如果代码行中的运算符比较多,用括号确定表达式的操作顺序,避免使用默认的优先级。
//例如:
word = (high << 8) | low
if ((a | b) && (a & c))
复合表达式
-
如 a = b = c = 0 这样的表达式称为复合表达式。允许复合表达式存在的理由是:(1)书写简洁;(2)可以提高编译效率。但要防止滥用复合表达式。
-
z 【规则 4-2-1】不要编写太复杂的复合表达式。
例如: i = a >= b && c < d && c + f <= g + h ; // 复合表达式过于复杂 -
z 【规则 4-2-2】不要有多用途的复合表达式。例如:
d = (a = b + c) + r ;
该表达式既求 a 值又求 d 值。应该拆分为两个独立的语句:
a = b + c;
d = a + r;
-
【规则 4-2-3】不要把程序中的复合表达式与“真正的数学表达式”混淆。 例如: if (a < b < c) // a < b < c 是数学表达式而不是程序表达式
并不表示 if ((a<b) && (b<c)) ;而是成了令人费解的 if ( (a<b)<c )。
if语句
_本节以“与零值比较”为例,展开讨论。
布尔变量与零值比较
-
【规则 4-3-1】不可将布尔变量直接与 TRUE、FALSE 或者 1、0 进行比较。
- 根据布尔类型的语义,零值为“假”(记为 FALSE),任何非零值都是“真”(记为TRUE)。
- TRUE 的值究竟是什么并没有统一的标准。例如 Visual C++ 将 TRUE 定义为1,而 Visual Basic 则将 TRUE 定义为-1。
- 假设布尔变量名字为 flag,它与零值比较的标准 if 语句如下:
- if (flag) 表示 flag 为真
- if (!flag) 表示 flag 为假
整型变量与零值比较
- 【规则 4-3-2】应当将整型变量用“==”或“!=”直接与 0 比较。假设整型变量的名字为 value,它与零值比较的标准 if 语句如下:
if (value == 0)
if (value != 0)
浮点变量与零值比较
-
【规则 4-3-3】不可将浮点变量用“==”或“!=”与任何数字比较。
- 千万要留意,无论是 float 还是 double 类型的变量,都有精度限制。
- 所以一定要避免将浮点变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“<=”形式。
- 假设浮点变量的名字为 x,应当将 if (x == 0.0) 隐含错误的比较
//转化为
if ((x>=-EPSINON) && (x<=EPSINON))
//其中 EPSINON 是允许的误差(即精度)。
指针变量与零值比较
-
【规则 4-3-4】应当将指针变量用“==”或“!=”与 NULL 比较。指针变量的零值是“空”(记为 NULL
- 尽管 NULL 的值与 0 相同但是两者意义不同。假设指针变量的名字为 p,它与零值比较的标准 if 语句如下:
if (p == NULL) // p 与 NULL 显式比较,强调 p 是指针变量 if (p != NULL)
4.4 循环语句的效率
本节重点论述循环体的效率。提高循环体效率的基本办法是降低循环体的复杂性。
- C++/C 循环语句中,for 语句使用频率最高,while 语句其次,do 语句很少用。
- 【建议 4-4-1】在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少 CPU 跨切循环层的次数。
for (col=0; col<5; col++ )
{
for (row=0; row<100; row++)
{
sum = sum + a[row][col];
}
}
- 【建议 4-4-2】如果循环体内存在逻辑判断,并且循环次数很大,宜将逻辑判断移到循环体的外面。
- 示例 C 的程序比示例 D 多执行了 N-1 次逻辑判断。并且由于前者老要进行逻辑判断,打断了循环“流水线”作业,使得编译器不能对循环进行优化处理,降低了效率。
for (i=0; i<N; i++) //C
{
if (condition)
DoSomething();
else
DoOtherthing();
}
----//
if (condition) //D
{
for (i=0; i<N; i++)
DoSomething();
}
else
{
for (i=0; i<N; i++)
DoOtherthing();
}
4.5 for 语句的循环控制变量
- 【规则 4-5-1】不可在 for 循环体内修改循环变量,防止 for 循环失去控制。
4.6 switch 语句
- switch 是多分支选择语句,而 if 语句只有两个分支可供选择。
- 虽然可以用嵌套的if 语句来实现多分支选择,但那样的程序冗长难读。这是 switch 语句存在的理由。
switch (variable)
{
case value1:
break;
case value2:
break;
default:
break;
}
- 【规则 4-6-1】每个 case 语句的结尾不要忘了加 break,否则将导致多个分支重叠(除非有意使多个分支重叠)。
- 【规则 4-6-2】不要忘记最后那个 default 分支。即使程序真的不需要 default 处理,也应该保留语句 default : break; 这样做并非多此一举,而是为了防止别人误以为你忘了 default 处理。
第五章 常量
5.1 为什么需要常量
-
如果不使用常量,直接在程序中填写数字或字符串,将会有什么麻烦?
- 程序的可读性(可理解性)变差。程序员自己会忘记那些数字或字符什么意思,用户则更加不知它们从何处来、表示什么。
- 在程序的很多地方输入同样的数字或字符串,难保不发生书写错误。
-
如果要修改数字或字符串,则会在很多地方改动,既麻烦又容易出错。

5.2 const 与 #define 的比较
- const 常量有数据类型,而宏常量没有数据类型。编译器可以对前者进行类型安全检查。而对后者只进行字符替换,没有类型安全检查,并且在字符替换可能会产生意料不到的错误(边际效应)。
- 有些集成化的调试工具可以对 const 常量进行调试,但是不能对宏常量进行调试。
- 【规则 5-2-1】在 C++ 程序中只使用 const 常量而不使用宏常量,即 const 常量完全取代宏常量。
5.3 常量定义规则
- 【规则 5-3-1】需要对外公开的常量放在头文件中,不需要对外公开的常量在定义文件的头部。为便于管理,可以把不同模块的常量集中存放在一个公共的头文件中。
- 【规则 5-3-2】如果某一常量与其它常量密切相关,应在定义中包含这种关系,而不应给出一些孤立的值。例如:
const float RADIUS = 100;
const float DIAMETER = RADIUS * 2;
5.4 类中的常量
-
枚举常量不会占用对象的存储空间,它们在编译时被全部求值。枚举常量的缺点是:它的隐含数据类型是整数,其最大值有限,且不能表示浮点数(如 PI=3.14159)。

第六章 函数设计
-
这里有一个很细的讲解:
【C语言从青铜到王者】第二篇·详解函数
-
C 语言中,函数的参数和返回值的传递方式有两种
- 值传递(pass by value)
- 指针传递(pass by pointer)。
- C++ 语言中多了引用传递(pass by reference)。由于引用传递的性质象指针传递,而使用方式却象值传递。
参数的规则
- 【规则 6-1-1】参数的书写要完整,不要贪图省事只写参数的类型而省略参数名字。如果函数没有参数,则用 void 填充
-
【规则 6-1-2】参数命名要恰当,顺序要合理。
- void StringCopy( char *strDestination,char *strSource);
- 【规则 6-1-3】如果参数是指针,且仅作输入用,则应在类型前加 const,以防止该指针在函数体内被意外修改。
void StringCopy(char *strDestination,const char *strSource);
- 【规则 6-1-4】如果输入参数以值传递的方式传递对象,则宜改用“const &”方式来传递,这样可以省去临时对象的构造和析构过程,从而提高效率。
6.2 返回值的规则
-
【规则 6-2-1】不要省略返回值的类型
- C 语言中,凡不加类型说明的函数,一律自动按整型处理。这样做不会有什么好处,却容易被误解为 void 类型
- C++语言有很严格的类型安全检查,不允许上述情况发生。由于C++程序可以调用C 函数,为了避免混乱,规定任何 C++/ C 函数都必须有类型。
- 如果函数没有返回值,那么应声明为 void 类型
-
如果 getchar 碰到文件结束标志或发生读错误,它必须返回一个标志 EOF。为了区别于正常的字符,只好将 EOF 定义为负数(通常为负 1)。因此函数 getchar 就成了 int 类型。

6.3 函数内部实现的规则
-
函数的出口入口处对参数的有效性进行检查

-
编译器直接把临时对象创建并初始化在外部存储单元中,省去了拷贝和析构的化费,提高了效率。

6.4 其他建议
- 【建议 6-4-1】函数的功能要单一,不要设计多用途的函数。
- 【建议 6-4-2】函数体的规模要小,尽量控制在 50 行代码之内。
- 建议 6-4-3】尽量避免函数带有“记忆”功能。如:static
6.5 使用断言
- 程序一般分为 Debug 版本和 Release 版本,Debug 版本用于内部调试,Release 版本发行给用户使用。
- 断言 assert 是仅在 Debug 版本起作用的宏,它用于检查“不应该”发生的情况。
-
而是宏。程序员可以把assert 看成一个在任何系统状态下都可以安全使用的无害测试手段。

第 7 章 内存管理
-
640K ought to be enough for everybody — Bill Gates 1981 内存分配方式有三种:
- 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static 变量。
- 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
- 从堆上分配,亦称动态内存分配。程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用 free 或 delete 释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多
-
要对堆区开辟的内存判断是否为NULL
- 开辟的内存要进行初始化
- 注意初始化成功时不要越界
- 动态内存的申请与释放必须配对,程序中 malloc 与 free 的使用次数一定要相同,
- 注意不要返回指向“栈内存”的“指针”
- 将指针设置为 NULL
7.3 指针与数组的对比
-
数组要么在静态存储区被创建(如全局数组),要么在栈上被创建。数组名对应着(而不是指向)一块内存,其地址与容量在生命期内保持不变,只有数组的内容可以改变。
-
指针可以随时指向任意类型的内存块,它的特征是“可变”,所以我们常用指针来高质量 C++/C 编程指南,操作动态内存。指针远比数组灵活,但也更危险
-
指针 p 指向常量字符串“world”(位于静态存储区,内容为 world\0),
常量字符串的内容是不可以被修改的。从语法上看,编译器并不觉得语句 p[0]= ‘X’有什么不妥,但是该语句企图修改常量字符串的内容而导致运行错误

-
数组之间比较用 strcmp ,赋值用strcpy。

-
sizeof(字符串) ,’\0’也算字符串大小。
7.4 指针参数是如何传递内存的?
-
用“指向指针的指针”

-
用函数返回值来传递动态内存。这种方法更加简单
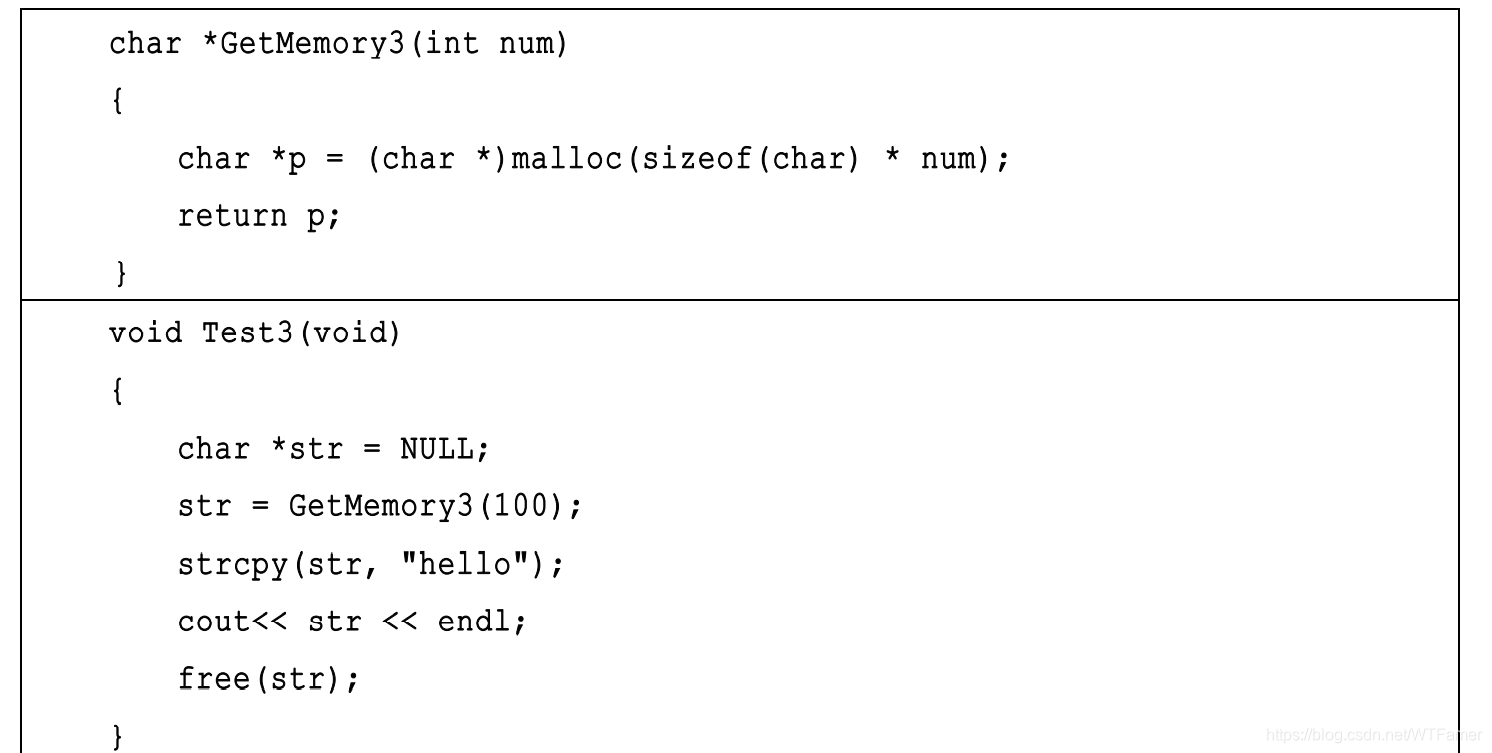
-
函数 Test5 运行虽然不会出错,但是函数 GetString2 的设计概念却是错误的。 因为 GetString2 内的“hello world”是常量字符串,位于静态存储区,它在程序生命期内恒定不变。无论什么时候调用 GetString2,它返回的始终是同一个“只读”的内存块。

-
“栈指针”

7.5 free 和 delete 把指针怎么啦
-
别看 free 和 delete 的名字恶狠狠的(尤其是 delete),它们只是把指针所指的内存给释放掉,但并没有把指针本身干掉

7.6 切记要初始化指针,释放指针后要置成空指针。
- 要么将指针设置为 NULL,要么让它指向合法的内存。例如
char *p = NULL; *
char *str = (char *) malloc(100);
- 不要越界访问
7.8 有了 malloc/free 为什么还要 new/delete
- 待定
7.9 内存耗尽怎么办?
-
如果在申请动态内存时找不到足够大的内存块,malloc 和 new 将返回 NULL 指针,宣告内存申请失败。通常有三种方式处理“内存耗尽”问题。
(1)判断指针是否为 NULL,如果是则马上用 return 语句终止本函数。例如:
void Func(void)
{
A *a = new A;
if(a == NULL)
{
return;
}
//…
}
(2)判断指针是否为 NULL,如果是则马上用 exit(1)终止整个程序的运行。例如:
void Func(void)
{
A *a = new A; *
if(a == NULL)
{
cout << “Memory Exhausted” << endl;
exit(1);
}
// …
}
(3)为 new 和 malloc 设置异常处理函数。例如 Visual C++可以用_set_new_hander 函_数为 new 设置用户自己定义的异常处理函数,也可以让 malloc 享用与 new 相同的异常处理函数。详细内容请参考 C++使用手册
-
上述(1)(2)方式使用最普遍。如果一个函数内有多处需要申请动态内存,那么方式(1)就显得力不从心(释放内存很麻烦),应该用方式(2)来处理。很多人不忍心用 exit(1),问:“不编写出错处理程序,让操作系统自己解决行不行?”
- 不行。如果发生“内存耗尽”这样的事情,一般说来应用程序已经无药可救。
- 如果不用 exit(1) 把坏程序杀死,它可能会害死操作系统。道理如同:如果不把歹徒击毙,歹徒在老死之前会犯下更多的罪.
有一个很重要的现象要告诉大家。对于 32 位以上的应用程序而言,无论怎样使用malloc 与 new,几乎不可能导致“内存耗尽”。
我在 Windows 98 下用 Visual C++编写了测试程序,见示例 7-9。这个程序会无休止地运行下去,根本不会终止。因为 32 位操作系统支持“虚存”,内存用完了,自动用硬盘空间顶替。我只听到硬盘嘎吱嘎吱地响,Window 98 已经累得对键盘、鼠标毫无反应。
---//试图耗尽操作系统的内存
void main(void)
{
float *p = NULL;
while(TRUE)
{
p = new float[1000000];
cout << “eat memory” << endl;
if(p==NULL)
exit(1);
}
}
7.10 malloc/free 的使用要点
-
函数 malloc 的原型如下:
void * malloc(size_t size);
用 malloc 申请一块长度为 length 的整数类型的内存,程序如下:
int *p = (int *) malloc(sizeof(int) * length);


7.11 new/delete 的使用要点
待定
7.12 一些心得体会
- (1)越是怕指针,就越要使用指针。不会正确使用指针,肯定算不上是合格的程序员。
- (2)必须养成“使用调试器逐步跟踪程序”的习惯,只有这样才能发现问题的本质
第 8 章 C++函数的高级特性
- 对比于 C 语言的函数,C++增加了重载(overloaded)、内联(inline)、const 和 virtual四种新机制。
- 其中重载和内联机制既可用于全局函数也可用于类的成员函数,const 与virtual 机制仅用于类的成员函数
8.1 函数重载的概念
-
重载的起源:自然语言中,一个词可以有许多不同的含义,即该词被重载了。
- 人们可以通过上下文来判断该词到底是哪种含义。
- “词的重载”可以使语言更加简练。
- 例如“吃饭”的含义十分广泛,人们没有必要每次非得说清楚具体吃什么不可。别迂腐得象孔已己,说茴香豆的茴字有四种写法。
-
在 C++程序中,可以将语义、功能相似的几个函数用同一个名字表示,即函数重载。
- 这样便于记忆,提高了函数的易用性,这是 C++语言采用重载机制的一个理由。
- 例如示例 8-1-1 中的函数 EatBeef,EatFish,EatChicken 可以用同一个函数名 Eat 表示,用不同类型的参数加以区别。
void EatBeef(…); 可以改为: void Eat(Beef …);
void EatFish(…); 可以改为: void Eat(Fish …);
void EatChicken(…); 可以改为: void Eat(Chicken …);
-
重载是如何实现的?
- 几个同名的重载函数仍然是不同的函数,它们是如何区分的呢?我们自然想到函数
- 接口的两个要素:参数与返回值。
-
如果同名函数的参数不同(包括类型、顺序不同),那么容易区别出它们是不同的函数。

-
所以只能靠参数而不能靠返回值类型的不同来区分重载函数。
- 编译器根据参数为每个重载函数产生不同的内部标识符。
- 例如编译器为示例 8-1-1 中的三个 Eat 函数产生象_eat_beef、_eat_fish、_eat_chicken 之类的内部标识符(不同的编译器可能产生不同风格的内部标识符)。
如果 C++程序要调用已经被编译后的 C 函数,该怎么办?
- 假设某个 C 函数的声明如下:void foo(int x, int y);
- 该函数被 C 编译器编译后在库中的名字为_foo,而 C++编译器则会产生像_foo_int_int之类的名字用来支持函数重载和类型安全连接。由于编译后的名字不同,C++程序不能直接调用 C 函数。
- C++提供了一个 C 连接交换指定符号 extern“C”来解决这个问题。例如:
extern “C”
{
void foo(int x, int y);
//… 其它函数
}
//或者写成
extern “C”
{
#include “myheader.h”
//… 其它 C 头文件
}
-
这就告诉 C++编译译器,函数 foo 是个 C 连接,应该到库中找名字_foo 而不是找_foo_int_int。C++编译器开发商已经对 C 标准库的头文件作了 extern“C”处理,所以我们可以用#include 直接引用这些头文件。
-
注意并不是两个函数的名字相同就能构成重载。全局函数和类的成员函数同名不算重载,因为函数的作用域不同。例如:
void Print(…); 全局函数
class A
{//…
void Print(…); // 成员函数
}
-
不论两个 Print 函数的参数是否不同,如果类的某个成员函数要调用全局函数 Print,为了与成员函数 Print 区别,全局函数被调用时应加‘::’标志。如
::Print(…);
// 表示 Print 是全局函数而非成员函数 - 当心隐式类型转换导致重载函数产生二义性
-
示例 8-1-3 中,第一个 output 函数的参数是 int 类型,第二个 output 函数的参数是 float 类型。由于数字本身没有类型,将数字当作参数时将自动进行类型转换(称为隐式类型转换)。
- 语句 output(0.5)将产生编译错误,因为编译器不知道该将 0.5 转换成int 还是 float 类型的参数。隐式类型转换在很多地方可以简化程序的书写,但是也可能留下隐患。
- 示例 8-1-3 隐式类型转换导致重载函数产生二义性 :
#include <iostream.h>
void output( int x); // 函数声明
void output( float x); // 函数声明
void output( int x)
{
cout << " output int " << x << endl ;
}
void output( float x)
{
cout << " output float " << x << endl ;
}
void main(void)
{
int x = 1;
float y = 1.0;
output(x); output int 1
output(y); output float 1
output(1); output int 1
output(0.5); error! ambiguous call, 因为自动类型转换
output(int(0.5)); output int 0
output(float(0.5)); output float 0.5
}
8.2 成员函数的重载、覆盖与隐藏、
-
重载与覆盖 成员函数被重载的特征:
(1)相同的范围(在同一个类中);
(2)函数名字相同;
(3)参数不同;
(4)virtual 关键字可有可无。 -
覆盖是指派生类函数覆盖基类函数,特征是:
(1)不同的范围(分别位于派生类与基类);
(2)函数名字相同;
(3)参数相同;
(4)基类函数必须有 virtual 关键字。
其余待定
8.3 参数的缺省值
待定
8.4 运算符重载
待定
8.5 函数内联
待定
8.6 一些心得体会
- C++ 语言中的重载、内联、缺省参数、隐式转换等机制展现了很多优点,但是这些优点的背后都隐藏着一些隐患。正如人们的饮食,少食和暴食都不可取,应当恰到好处。
- 我们要辨证地看待 C++的新机制,应该恰如其分地使用它们。虽然这会使我们编程时多费一些心思,少了一些痛快,但这才是编程的艺术。
第 9 章 类的构造函数、析构函数与赋值函数
待定
第 10 章 类的继承与组合
待定
第 11 章 其它编程经验
使用 const 提高函数的健壮性
- const 更大的魅力是它可以修饰函数的参数、返回值,甚至函数的定义体。const 是 constant 的缩写,“恒定不变”的意思。
- 被 const 修饰的东西都受到强制保护,可以预防意外的变动,能提高程序的健壮性。所以很多 C++程序设计书籍建议:“Use const whenever you need”。
-
用 const 修饰函数的参数;输出参数不能用 const

- const 只能修饰输入参数。
- 如果输入参数采用“指针传递”,那么加 const 修饰可以防止意外地改动该指针,起到保护作用。
-
如果输入参数采用“值传递”,由于函数将自动产生临时变量用于复制该参数,该输入参数本来就无需保护,所以不要加 const 修饰。

-
总结:

用 const 修饰函数的返回值
- 如果给以“指针传递”方式的函数返回值加 const 修饰,那么函数返回值(即指针)的内容不能被修改,该返回值只能被赋给加 const 修饰的同类型指针。
- 例如函数
const char * GetString(void); *
//如下语句将出现编译错误:
char *str = GetString(); *
//正确的用法是
const char *str = GetString();*
- 如果函数返回值采用“值传递方式”,由于函数会把返回值复制到外部临时的存储单元中,加 const 修饰没有任何价值。 例如不要把函数 int GetInt(void) 写成 const int GetInt(void)。
提高程序的效率
程序的时间效率是指运行速度,空间效率是指程序占用内存或者外存的状况。
全局效率是指站在整个系统的角度上考虑的效率,局部效率是指站在模块或函数角度上考虑的效率。
- 【规则 11-2-1】不要一味地追求程序的效率,应当在满足正确性、可靠性、健壮性、可读性等质量因素的前提下,设法提高程序的效率。
- 【规则 11-2-2】以提高程序的全局效率为主,提高局部效率为辅。
- 【规则 11-2-3】在优化程序的效率时,应当先找出限制效率的“瓶颈”,不要在无关紧要之处优化。
- 【规则 11-2-4】先优化数据结构和算法,再优化执行代码。
- 【规则 11-2-5】有时候时间效率和空间效率可能对立,此时应当分析那个更重要,作出适当的折衷。例如多花费一些内存来提高性能。
- 【规则 11-2-6】不要追求紧凑的代码,因为紧凑的代码并不能产生高效的机器码。
一些有益的建议
-
当心那些视觉上不易分辨的操作符发生书写错误。我们经常会把“==”误写成“=”,象“||”、“&&”、“<=”、“>=”这类符号也很容易发生“丢 1”失误。然而编译器却不一定能自动指出这类错误。
-
变量(指针、数组)被创建之后应当及时把它们初始化,以防止把未被初始化的变量当成右值使用。
-
当心变量的初值、缺省值错误,或者精度不够
-
当心数据类型转换发生错误。尽量使用显式的数据类型转换(让人们知道发生了什么事),避免让编译器轻悄悄地进行隐式的数据类型转换。
-
当心变量发生上溢或下溢,数组的下标越界。
-
当心忘记编写错误处理程序,当心错误处理程序本身有误。
-
当心文件 I/O 有错误。
-
避免编写技巧性很高代码。
-
不要设计面面俱到、非常灵活的数据结构。
-
尽量使用标准库函数,不要“发明”已经存在的库函数。
-
尽量不要使用与具体硬件或软件环境关系密切的变量。
-
把编译器的选择项设置为最严格状态。
-
如果可能的话,使用 PC-Lint、LogiScope 等工具进行代码审查。
GG寄语
如有和原文较大差异的地方、或不完善的地方、或不明白的地方,可以百度、或者评论区柳岩。三联,三联,三联…!
