字典

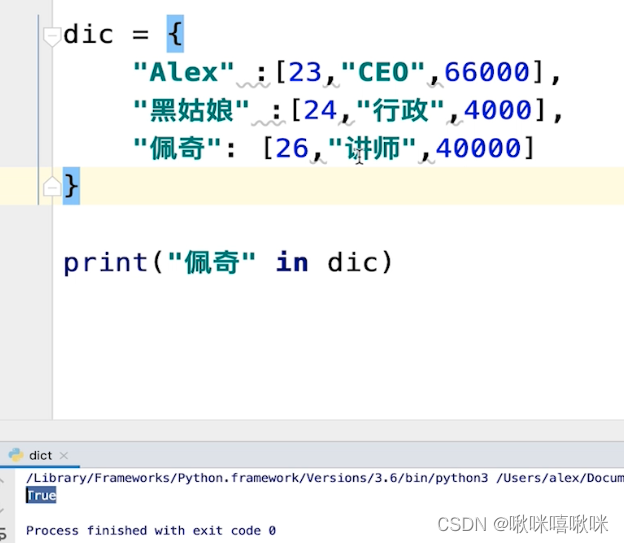
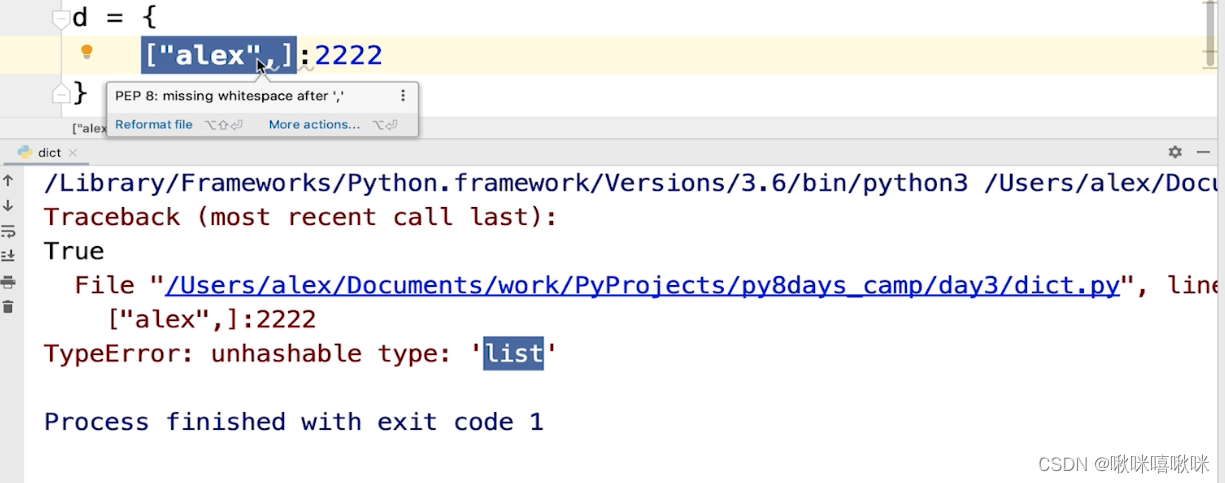
因为key不能为变量 只能为不可变的值
字典的key必须是唯一的 不然后面的值会吧前面的值覆盖
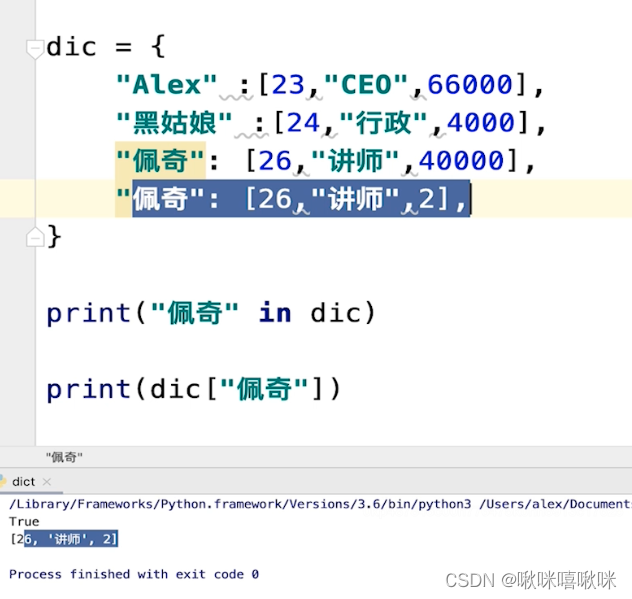



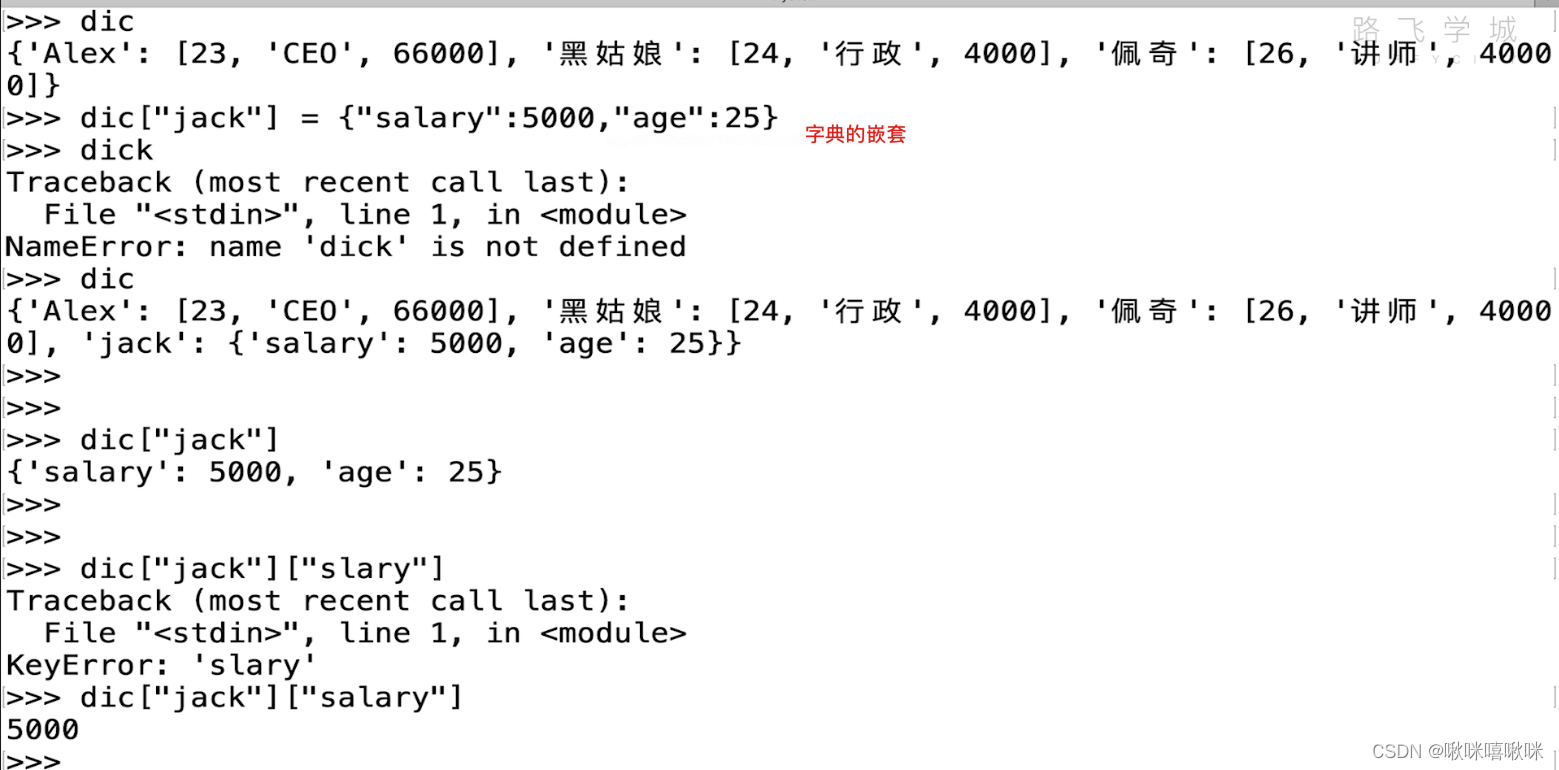
字典取值只能一个一个取 且只能通过key查询value 不能反过来

d.items就是变成了列表里 元祖的形式



这种取值是最推荐的。第三种比第二种推荐的方式 是因为第2种取值会先转换为大列表。然后取值,有一个转化的过程,所以效率低。
第三种就是直接拿key去取value的值 取1亿条和取1条一样的快


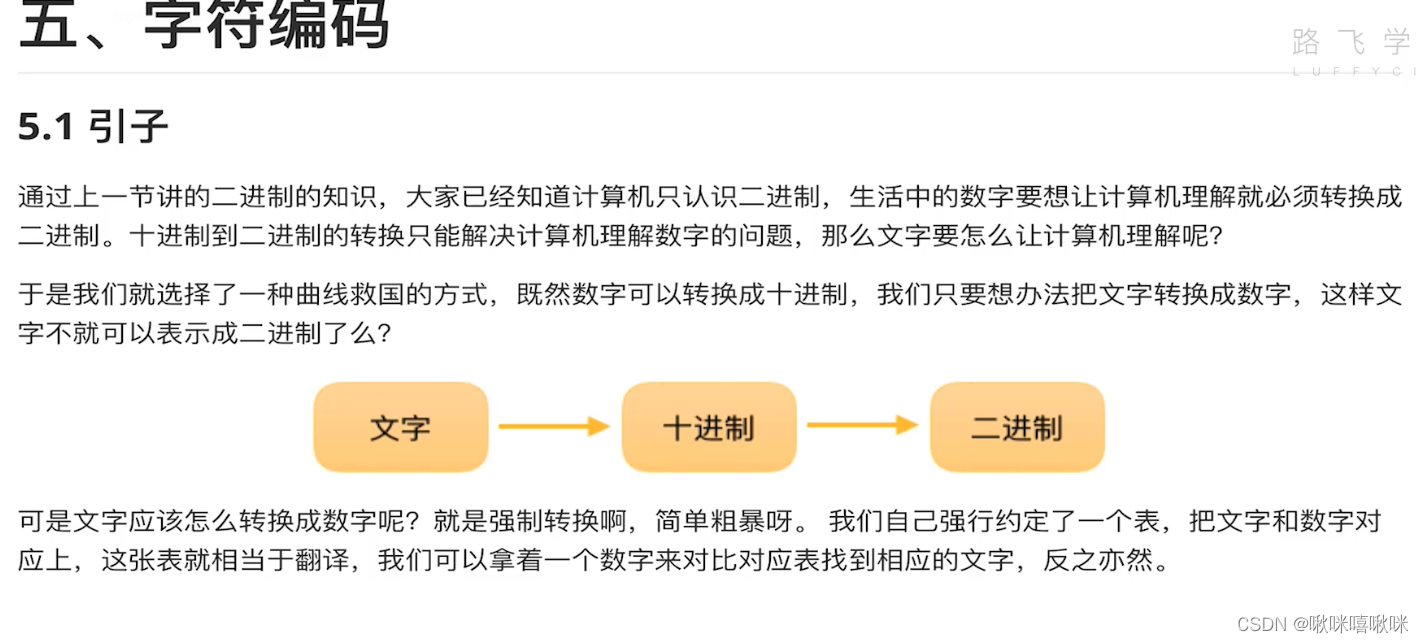
解释器自带函数
二进制计算

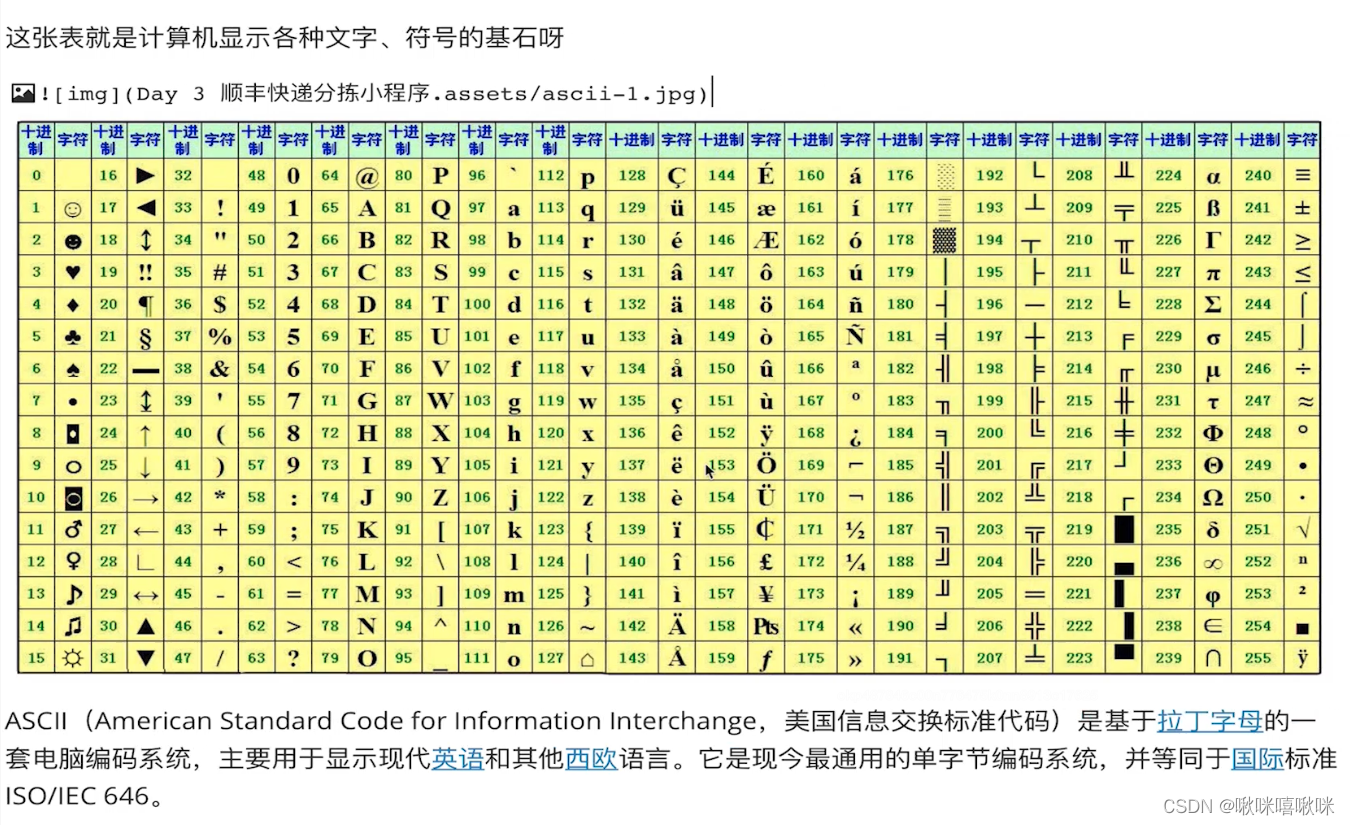


问题:如何去打印两个空格1个对号呢??
因为空格的ascii码对应的数字就是0

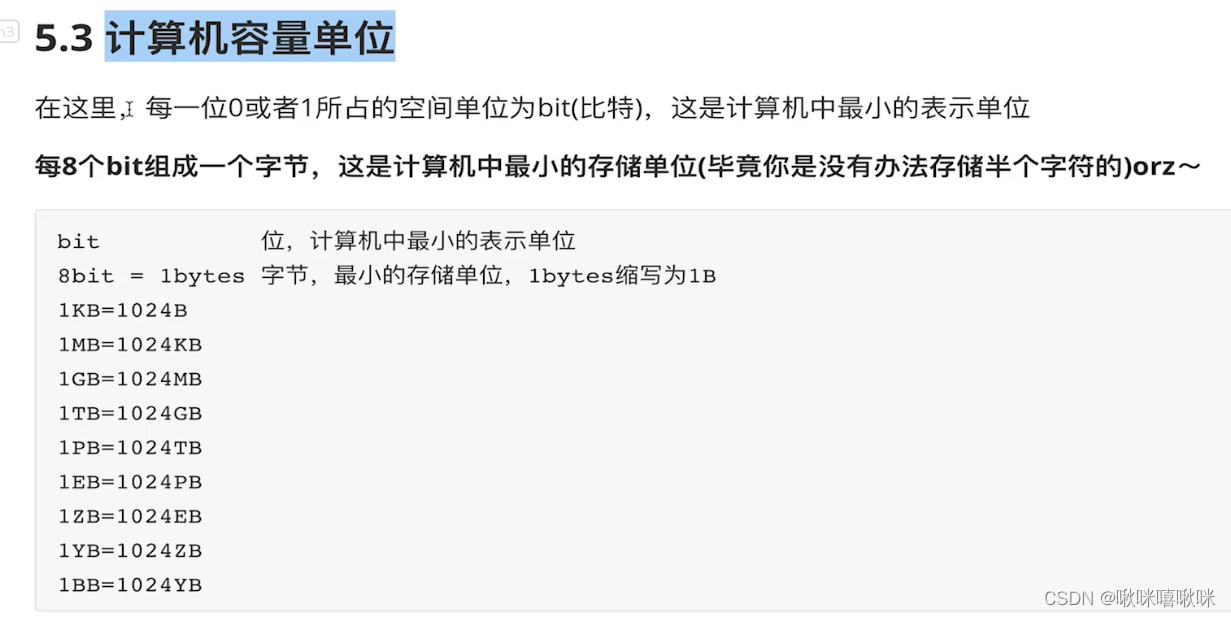
1个二进制位就是1bit
8bit就是一个字符就是 1bytes
如何识别中文的呢
2个字节 2^16 =65535 所以2个字节代表一个中文汉字。


2个字节的首位都是1 代表就是汉字
因为ascii码128以后的都是乱七八糟的字符 –扩展表 基本只用0-128 基本字节
代表英文数字都在0-128内
所以2个高字节一起出现 就认定是中文。

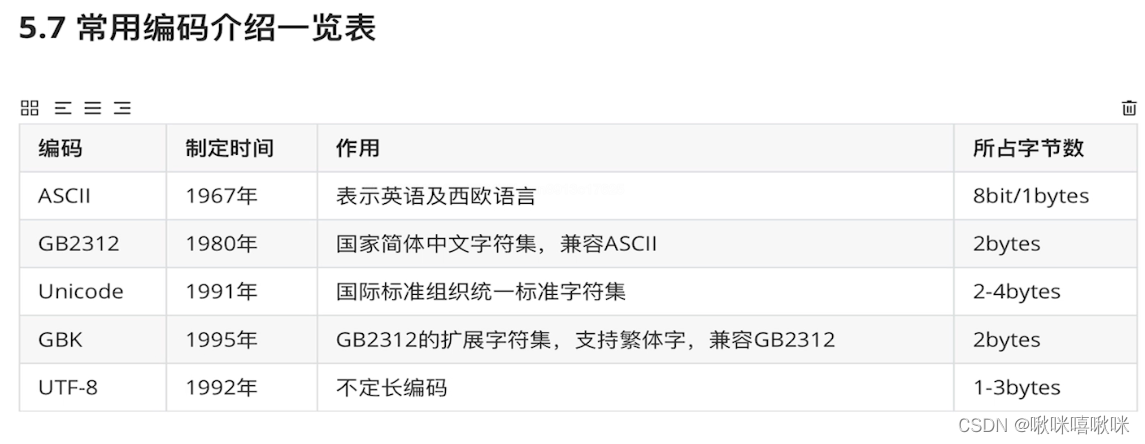
编码的战国时代
后来囊括了 中文 日文 少数民族的所有语言 编码为gbk

比如 中文用 2个字节代表 其他的xx用3个代表
万国码可以转的表

比如路字在万国码里的位置是8DEF 在gbk是4237 这样子就很好转换了 都有转换的关系;
这样子不至于中文编译的软件 转换为万国码也很方便了
但是万国码使得转换为硬盘上就会变大了 传输时间也长了

UTF32 相当于不管是啥都转为4个字节离谱
UTF-8 就是传输到文件最通用的方式 在内存就还是unicode
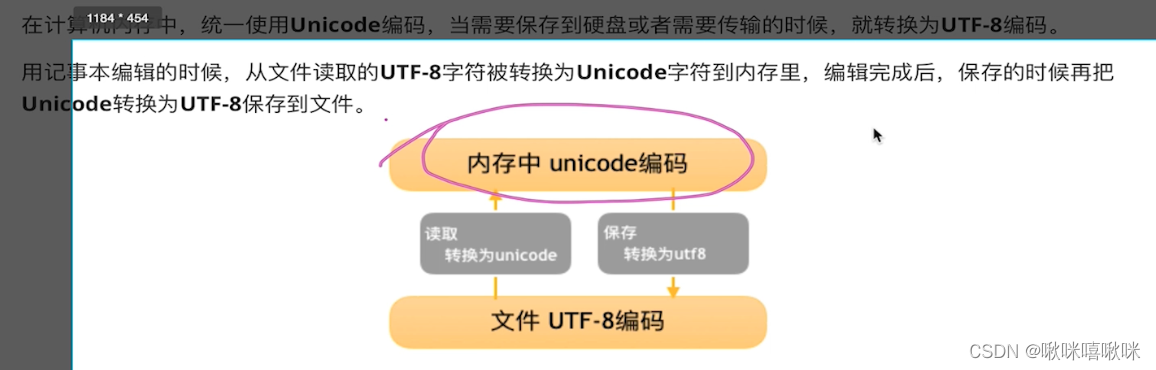
16进制

参考:本文链接:https://blog.csdn.net/weixin_43857827/article/details/126304561
Day4

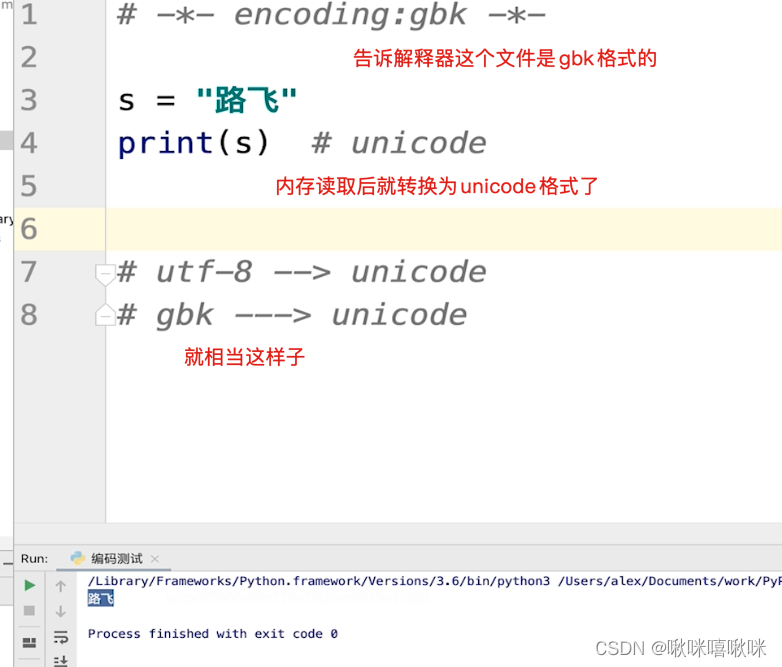
gbk的文字如何转换


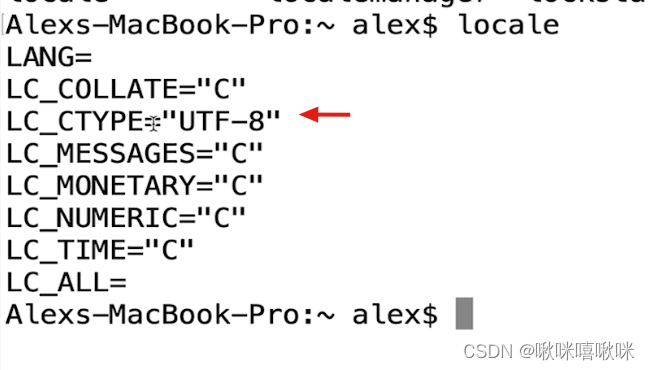
问题:文字在windos上产生的 gbk编码
发送到mac 要求mac正常显示怎么办?
演示:
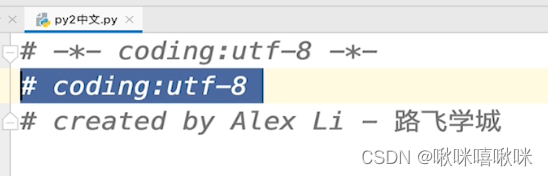
pycharm默认就是utf8
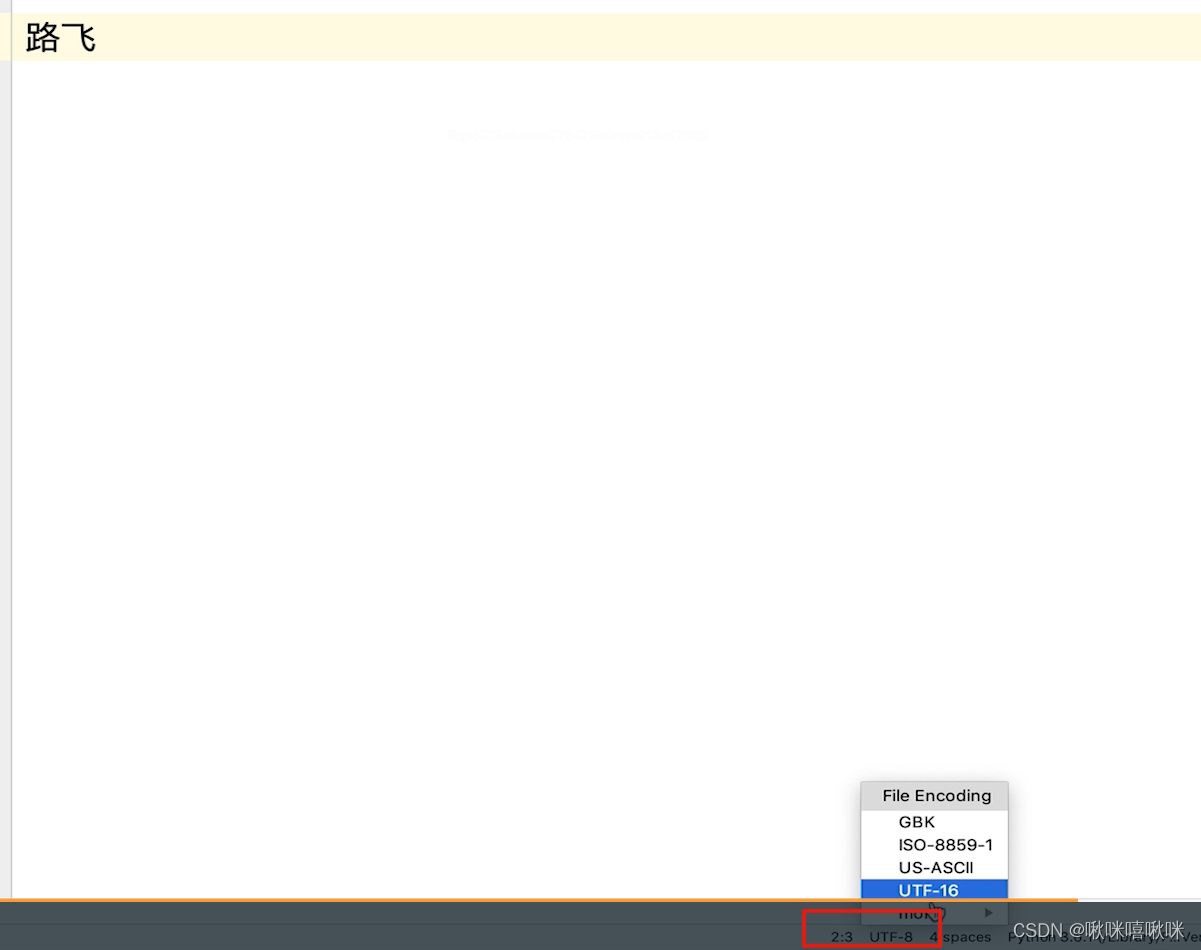
改成gbk
把这个文本发送给mac,发现乱码了

如何显示?


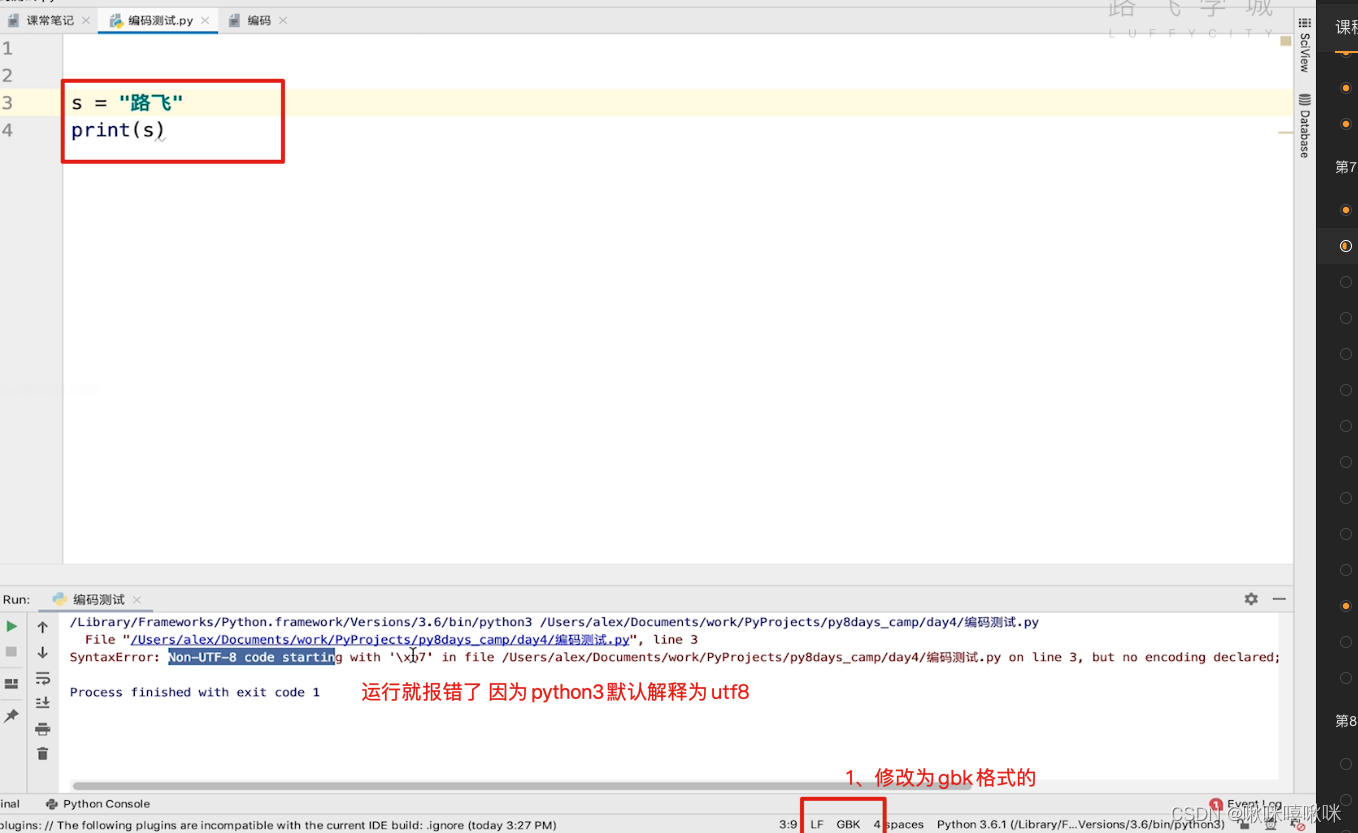
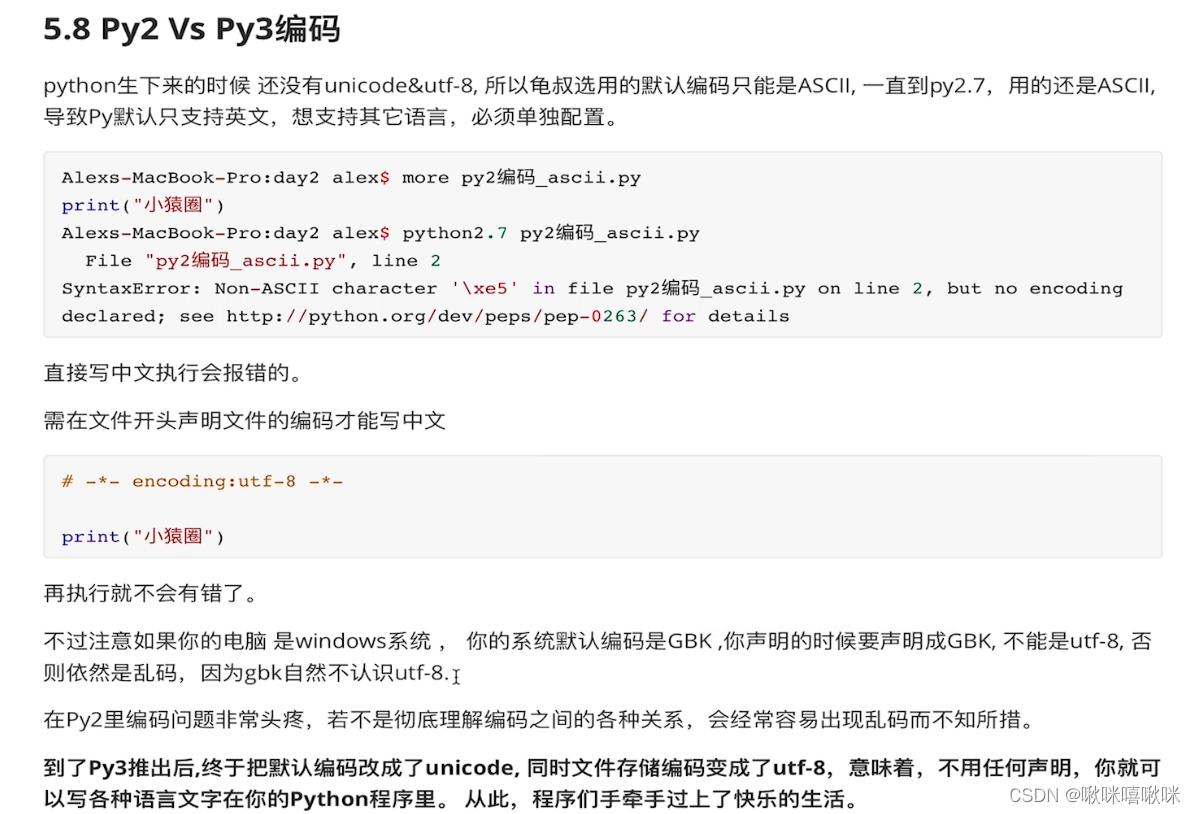
python2默认使用的是ascii码

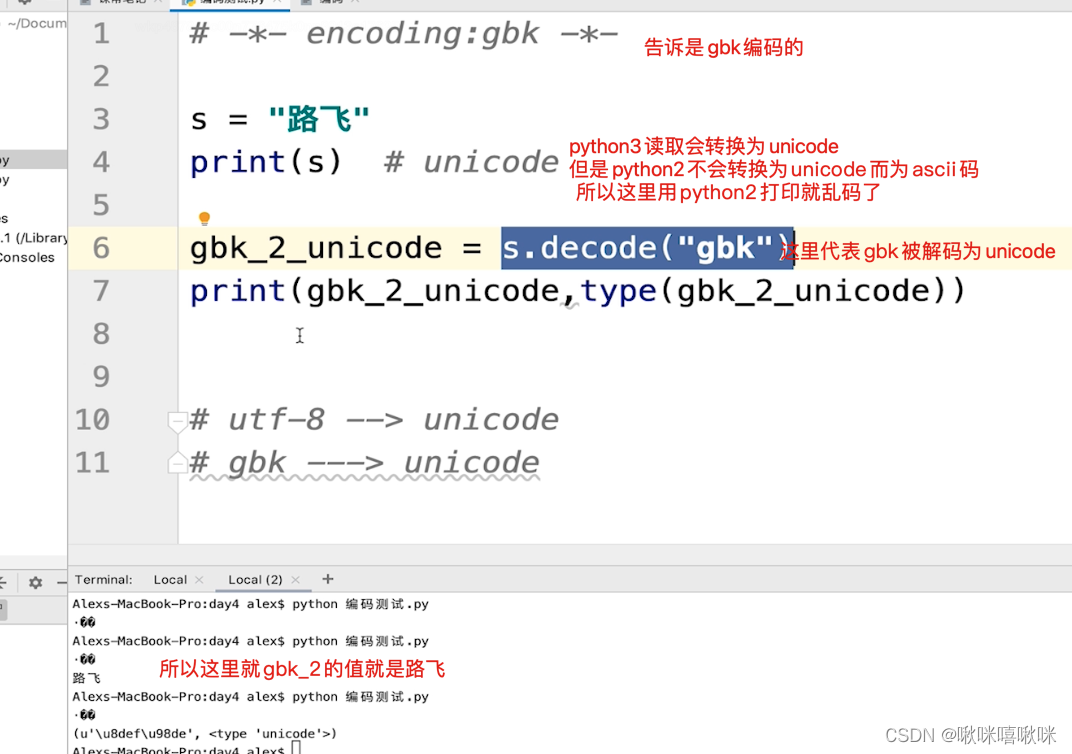
mac默认是utf8