//根据 字符数组 首字母 拼音排序
pySegSort(arr, empty) {
// 根据传入的数组 arr,对其按照首字母拼音分类,参考地址https://www.cnblogs.com/goloving/p/7662676.html
if (!String.prototype.localeCompare) return null;
var letters = "#abcdefghjklmnopqrstwxyz".split("");
var en = "abcdefghjklmnopqrstwxyz".split("");
var zh = "阿八嚓哒妸发旮哈讥咔垃痳拏噢妑七呥扨它穵夕丫帀".split("");
// 先将其中的 字母找出来排序
let segs2 = [];
let curr2;
letters.filter((i, v) => {
curr2 = { letters: i, dat: [] };
arr.filter((i2, v2) => {
if (
(!en[v - 1] || en[v - 1].localeCompare(i2) <= 0) &&
i2.localeCompare(en[v]) == -1
) {
curr2.dat.push(i2);
}
if (empty || curr2.dat.length) {
segs2.push(curr2);
curr2.dat.sort(function (a, b) {
return a.localeCompare(b);
});
}
});
});
// 将其中的相同项合并 将中文以及其他字符拿出来 cnChar
let arry2 = [];
let cnChar = [];
for (let i in segs2) {
i = parseInt(i);
if (
segs2[i] &&
segs2[i + 1] &&
segs2[i].letters == segs2[i + 1].letters
) {
} else {
if (segs2[i].letters == "#") {
cnChar = cnChar.concat(segs2[i].dat);
} else {
arry2.push(segs2[i]);
}
}
}
// 对中文 进行排序
let segs = [];
let curr;
letters.filter((item, index) => {
curr = { letters: item, dat: [] };
cnChar.filter((item2, index2) => {
if (
(!zh[index - 1] || zh[index - 1].localeCompare(item2) <= 0) &&
item2.localeCompare(zh[index]) == -1
) {
curr.dat.push(item2);
}
if (empty || curr.dat.length) {
segs.push(curr);
curr.dat.sort(function (a, b) {
return a.localeCompare(b);
});
}
});
});
// 对相同项进行合并
let arry = [];
for (let i in segs) {
i = parseInt(i);
if (segs[i] && segs[i + 1] && segs[i].letters == segs[i + 1].letters) {
} else {
if (segs[i]) {
arry.push(segs[i]);
}
}
}
// 将中文排序 数组 英文排序数组 进行合并
let sel = arry.concat(arry2);
for (let i = 0, l = sel.length; i < l; i++) {
i = parseInt(i);
for (let j = i + 1, l = sel.length; j < l; j++) {
if (sel[i].letters == sel[j].letters) {
sel[i].dat = sel[i].dat.concat(sel[j].dat);
sel.splice(j, 1);
l--;
j--;
}
}
}
//排序 js 里面 字符 '#'<'a' 'a'<''b 以此类推
let len = sel.length;
for (let i = 0; i < len - 1; i++) {
for (let j = 0; j < len - 1 - i; j++) {
// 相邻元素两两对比,元素交换,大的元素交换到后面
if (sel[j].letters > sel[j + 1].letters) {
let temp = sel[j];
sel[j] = sel[j + 1];
sel[j + 1] = temp;
}
}
}
// 返回 排好序的 集合
return sel;
}
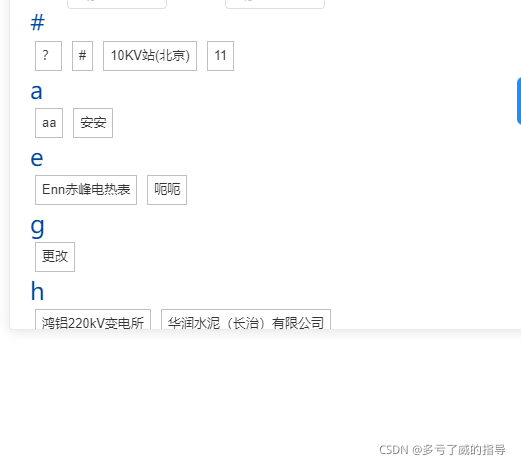
使用
pySegSort([ ‘aa’ , ‘报表’ , ‘是’ , ‘啊’ , ‘
KaTeX parse error: Expected ‘}’, got ‘#’ at position 17: … ]) 返回 结果 [ {‘#̲’,dat:[‘
’]} , {‘a’,dat:[‘aa’,‘啊’]} , {‘b’,dat:[‘报表’]} , {‘s’,dat:[‘是’]} ]
版权声明:本文为qq_41299637原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。