广州大学软件方向综合课程设计目录
序章
-
本报告为广州大学大三上软件方向综合课程设计报告,仅供各位同学参考使用,
不得作商业用途
。 -
开源代码链接如下,不要吝啬你的小星星噢~:
Github链接?
-
概念设计、物理设计参考在线制作网站:
https://drawerd.com
第一章 系统需求简介
1.1 需求分析
实现一个具体的课程管理系统。按照软件工程思路设计简化的专业课数据库,尽量模拟现有专业课程一个学期的选课排课原型实际情况。
(注:本系统由本人单独设计、开发完成)
1.2 数据结构需求分析
课程管理系统需要完成功能主要有:
(1) 学生基本信息的查询,学生可以对本人的系统登陆密码进行修改。
(2) 学生定制专属课表,可以查看整个学期本人的课程安排,包括课程名称、上课时间、上课地点、任课老师、学分等等。
(3) 学生可以进行选课,专业必修课程系统会提前帮助学生们选上。
(4) 学生可以进行退课,专业必修课程不允许退课。
(5) 学生可以查看自己选上的课的成绩,以及各个课程的得分、绩点,并给出其平均绩点,但不允许查看年级其他人的成绩。
(6) 任课教师基本信息的查询,老师可以对本人的系统登陆密码进行修改。
(7) 任课教师可以查看本人所任教课程信息,包括课程名称、上课时间、上课地点、上课班级等等。
(8) 任课教师可以对其任教课程进行调课,调课在全部课程时间无冲突下可以成功调课。
(9) 任课教师可以查看其教的每一个课程的学生名单。
(10) 任课教师可以对其教的课程的学生进行登分以及修改分数。
(11) 任课教师可以对其任教的班级成绩进行排序。
(12) 系主任拥有包括以上所有任课教师所拥有权限,以及以下的额外权限。
(13) 系主任可以查看整个系的全部学生以及他们的平均绩点,可以对每个班进行排名,或者也可以对整个系进行排名。
(14) 系主任可以查看整个系的任教教师名单,以及他们所负责的课程数目。
(15) 系主任可以查看整个学期所开设的所有课程,包括这些课程的全部详细信息。
(16) 系主任可以查看每个班的课程安排表。
1.3系统功能设计
课程管理系统主要分为三个客户端登陆,分别是学生、任课教师和系主任,每个客户端的功能是不同的。这三个客户端的登陆拥有自己的功能实现。下面三个图分别是三个客户端的功能模块图。
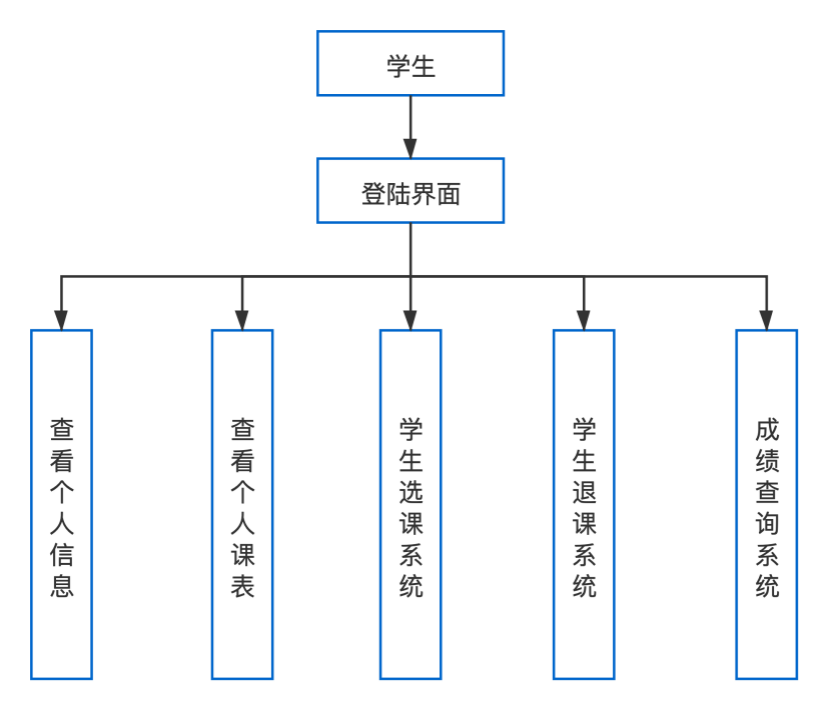
图1.1 学生的客户端功能
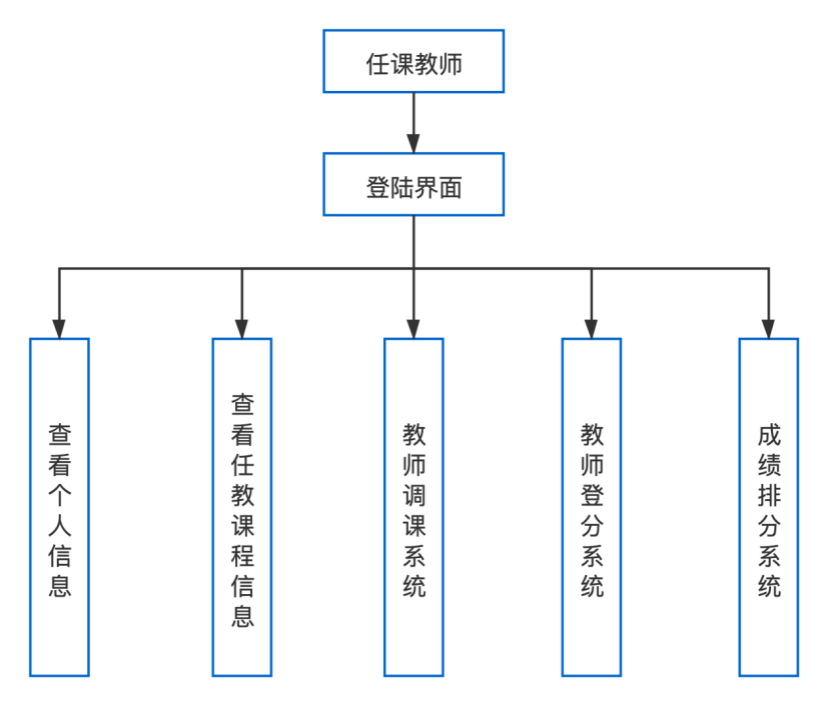
图1.2 任课教师的客户端功能
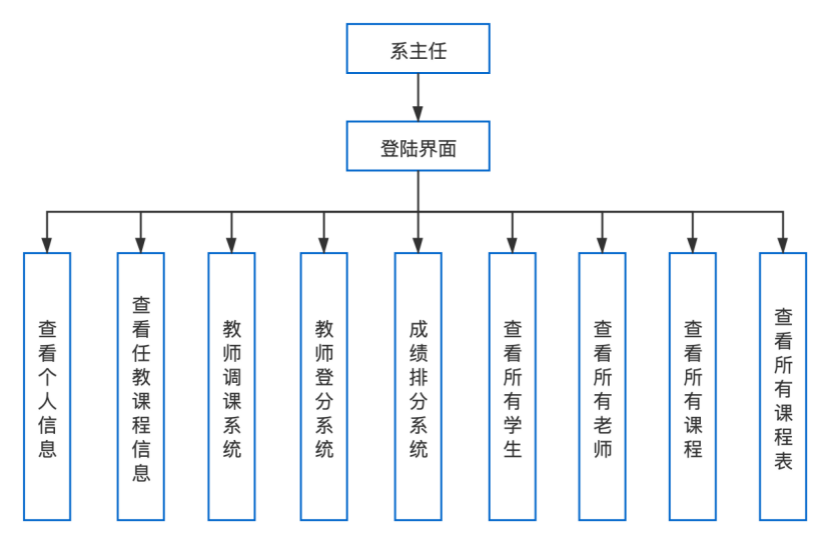
图1.3 系主任的客户端功能
第二章 需求描述
2.1 数据流图
系统的全局数据流图
系统的全局数据流图,在具体的设计工具中往往也称为第0层或顶层数据流图,主要是从整体上描述系统的数据流,反映系统中数据的整体流向,是设计者针对用户和开发者表达出来的一个总体描述。
经过对课程管理的调查、数据的收集和信息流程分析处理,明确了该系统的主要功能,分别为:
(1)学生
查看、修改个人信息;
查看个人课表;
选课、退课;
查看个人成绩、绩点;
(2)任课教师
查看、修改个人信息;
查看任教课程信息;
调整任教课程上课时间;
登记、修改所教课程的学生成绩;
对班级学生成绩进行排序;
(3)系主任
查看、修改个人信息;
查看任教课程信息;
调整任教课程上课时间;
登记、修改所教课程的学生成绩;
对班级学生成绩进行排序;
查看所有学生信息;
查看所有任课教师信息;
查看所有课程信息;
查看所有班级课程表;

图2.1 顶层数据流图
2.2 数据字典
数据流图清楚的表达了数据和处理数据的关系,但是没有清楚的描述出个数据处理的细节。通过数据字典来说明数据流图中出现的元素的详细定义和描述。包括数据流、加工处理、数据存储、数据的起点和终点或外部实体等。下面是数据存储的描述。
数据存储
表2-2-1 课程组信息模块存储的描述
| 序号 | 数据文件 | 文件组成 | 关键标识 | 组织 |
|---|---|---|---|---|
| 1 | 课程组信息 | 课程代码+课程名称+课程性质+考察方式+课时+学分 | 全部 | 按课程代码排序 |
表2-2-2 班级模块存储的描述
| 序号 | 数据文件 | 文件组成 | 关键标识 | 组织 |
|---|---|---|---|---|
| 1 | 班级信息 | 班级号+班别名称+班主任 | 全部 | 按班级号编号排序 |
表2-2-3 个人信息模块存储的描述
| 序号 | 数据文件 | 文件组成 | 关键标识 | 组织 |
|---|---|---|---|---|
| 1 | 学生信息 | 学号+姓名+性别+专业+班别号+入学日期+登陆密码 | 全部 | 按学号编号排序 |
| 2 | 教师信息 | 教师编号+姓名+性别+登陆密码 | 全部 | 按教师号编号排序 |
表2-2-4 课程信息模块存储的描述
| 序号 | 数据文件 | 文件组成 | 关键标识 | 组织 |
|---|---|---|---|---|
| 1 | 课程信息 | 课程号+课程代码+教师编号+课程名称+上课地点+上课时间+任教班级 | 全部 | 按课程号排序 |
| 2 | 学生选课信息 | 课程号+学号+分数 | 全部 | 按课程号、学号编号排序 |
| 3 | 班级课程信息 | 班级号+课程号 | 全部 | 按班级号、课程号编号排序 |
第三章 概念设计
3.1 实体
由前面分析得到的数据流图和数据字典,可以抽象得到实体主要有8个:课程组、班级、学生、教师、课程、班级课程、课程组教师、分数。
- 课程组实体属性有:课程代码、课程名称、课程性质、考察方式、课时、学分。
- 班级类型实体属性有:班级编号、班级名称、班主任教师号。
- 教师实体属性有:教师编号、姓名、性别、登陆密码。
- 学生实体属性有:学号、姓名、性别、专业、班级编号、入学日期、登陆密码。
- 课程实体属性有:课程号、教师编号、课程代码、课程名称、上课时间、上课地点、上课班级。
- 班级课程实体属性有:班级号、课程号、班主任。
- 课程组教师属性有:课程代码、教师号、课题组组长标记。
- 分数实体属性有:学号、课程号、分数。
3.2 系统全局E-R图
- 课程组实体和课程组教师实体存在归属的联系,一个课程组可以包含多个教师,且有一个课程组组长,所以它们之间是一对多的联系(1:n)。
- 教师实体和课程组教师实体存在归属的联系,一个教师可以任教多门不同课程,可以在不同课程组内,所以它们之间是一对多的联系(1:n)。
- 课程组实体和课程实体存在单对多的关系,一个课程组可以开设多个该课程,所以它们之间是一对多的联系(1:n)。
- 教师实体和课程实体存在单对多的关系,每个教师可以任教多门课程,所以它们之间是一对多的联系(1:n)。
- 班级实体和班级课程实体存在单对多的关系,一个班级可以选择多门课程,所以它们之间是一对多的联系(1:n)。
- 课程实体和班级课程实体存在单对多的关系,一个课程可以被多个班级同时选择,所以他们之间是一对多的联系(1:n)。
- 班级实体和学生实体存在单对单的关系,一个班级内有多个学生,所以它们之间是一对多的联系(1:n)。
- 学生实体和分数实体存在单对多的关系,一位学生可以选择多门课程,每一门课程都有相应的分数,所以它们之间是一对多的联系(1:n)。

图3.2.1 系统全局E-R图
3.3 概念数据模型设计
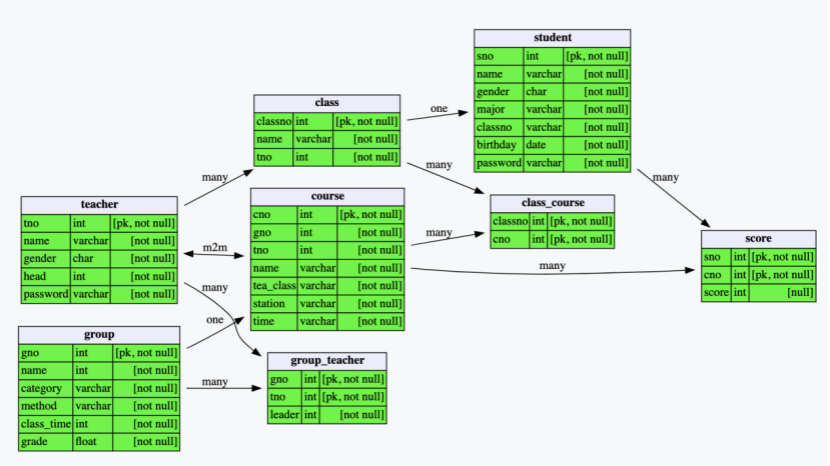
图3.3.1 课程管理系统的概念数据模型图
第四章 逻辑设计
4.1 ER图到关系模式的转换
课程管理系统功能大,实体多,这里列举重要的关系模式的转换过程:
(1)课程组实体和课程组教师实体存在归属的联系,一个课程组可以包含多个教师,且有一个课程组组长,所以它们之间是一对多的联系(1:n)。课程组教师实体和教师实体存在联系,一个教师可以同时在多个课程组。设计成如下的关系模式:
- 课程组(课程代码,课程组名称,课程性质,考察方式,总课时,学分)
- 课程组教师(课程代码,教师编号,组长标记)
-
教师(教师编号,名字,性别,主任标记,登陆密码)
(2)班级实体和学生实体存在单对单的关系,一个班级内有多个学生,所以它们之间是一对多的联系(1:n)。 - 班级(班级号,班级名称,班主任)
-
学生(学号,姓名,性别,专业,班级,入学时间,登陆密码)
(3)课程实体和班级课程实体存在单对多的关系,一个课程可以被多个班级同时选择,所以他们之间是一对多的联系(1:n)。设计成如下的关系模式: - 课程(课程号,课程代码,教师号,课程名,上课时间,上课地点,上课班别)
-
班级课程(班级号,课程号)
(4)一位学生可以选择多门课程,每一门课程都有相应的分数,分数实体由学号与课程号确定分数。 - 分数(学号,课程号,分数)
4.2 各个数据表的表结构设计
表4-1 数据库表清单
| 数据库表名 | 关系模式名称 | 备注 |
|---|---|---|
| group | 课程组 | 课程组表 |
| group_teacher | 课程组教师 | 课程组教师表 |
| teacher | 教师 | 教师表 |
| class | 班级 | 班级表 |
| student | 学生 | 学生表 |
| course | 课程 | 课程表 |
| class_course | 班级课程 | 班级课程表 |
| score | 分数 | 分数表 |
表4-2 课程组表

表4-3 课程组教师表

表4-4 教师表

表4-5 班级表

表4-6 学生表
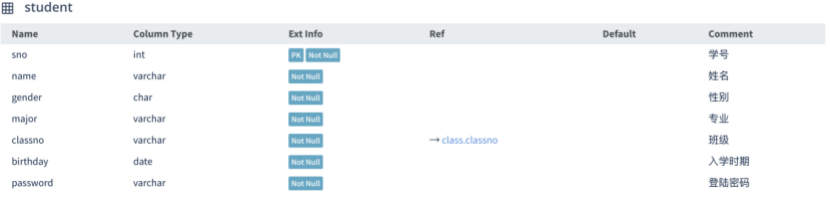
表4-7 课程表

表4-8 班级课程表

表4-9 分数表

第五章 物理设计
5.1 数据库软件
SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如 Tcl、C#、PHP、Java等,还有ODBC接口,同样比起Mysql、PostgreSQL这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快。
官网下载sqlite3即可,打开方式为-》终端-》输入sqlite3,即可进入操作。
5.2 创建数据表

图5.2.1 创建教师表

图5.2.2 创建课程组表

图5.2.3 创建课程组教师表

图5.3.4 创建课程表

图5.3.5 创建班级表

图5.3.6 创建班级课程表

图5.3.7 创建学生表

图5.3.8 创建得分表
第六章 处理数据
6.1 数据需求
由前面分析以及课程设计提供的数据,我们可以直接获得的数据主要为课程组信息、教师信息、学生信息。
课程组信息:通过整理我们专业六个班级的课程表可以获得;
教师信息:通过整理我们专业的老师信息表可以获得;
学生信息:通过整理六个班级的信息可以获得。
不可以直接获得的信息主要为开设课程的信息,这个进一步分析获得,通过教师的数目,班级的数目,确定每个课程组应当开设的课程数目,整理获得。
6.2 读取数据
(一)读取课程组信息
import os
list1 = os.listdir('./20-21(1)班级课表(正式版)2020-8-27')
for i in list1:
data = pd.read_excel('./20-21(1)班级课表(正式版)2020-8-27/'+i)
(二)读取教师信息
import pandas as pd
teacher = pd.read_csv('./teacher.csv')
(三)读取学生信息
import pandas as pd
name181 = pd.read_excel('./2018级各班花名册.xlsx',header=None,sheet_name = '计科181(36)')
name182 = pd.read_excel('./2018级各班花名册.xlsx',header=None,sheet_name = '计科182(41)')
name183 = pd.read_excel('./2018级各班花名册.xlsx',header=None,sheet_name = '计科183(41)')
name184 = pd.read_excel('./2018级各班花名册.xlsx',header=None,sheet_name = '计科184(40)')
name185 = pd.read_excel('./2018级各班花名册.xlsx',header=None,sheet_name = '计科185(40)')
name186 = pd.read_excel('./2018级各班花名册.xlsx',header=None,sheet_name = '计科186(40)')
6.3 处理数据
通过导入前面的表格,经过简单预处理,可以得到以下表格数据。
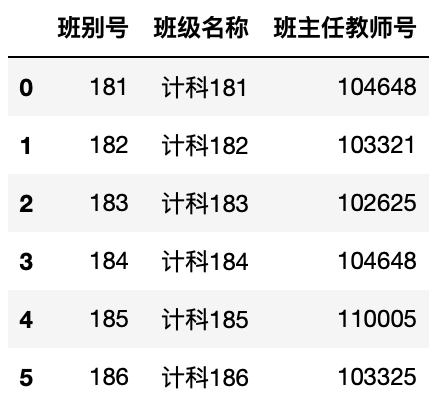
表6-3-1 课程组表(显示全部)
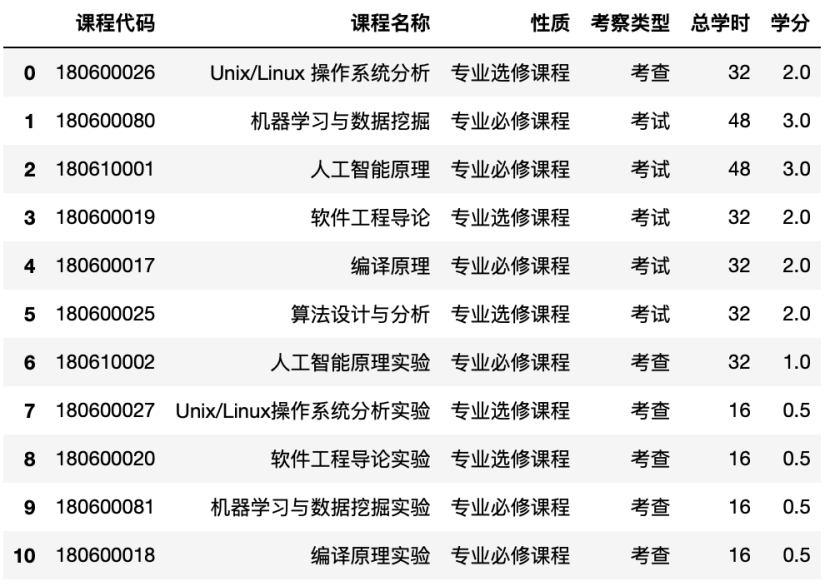
表6-3-2 教师表(仅显示部分)
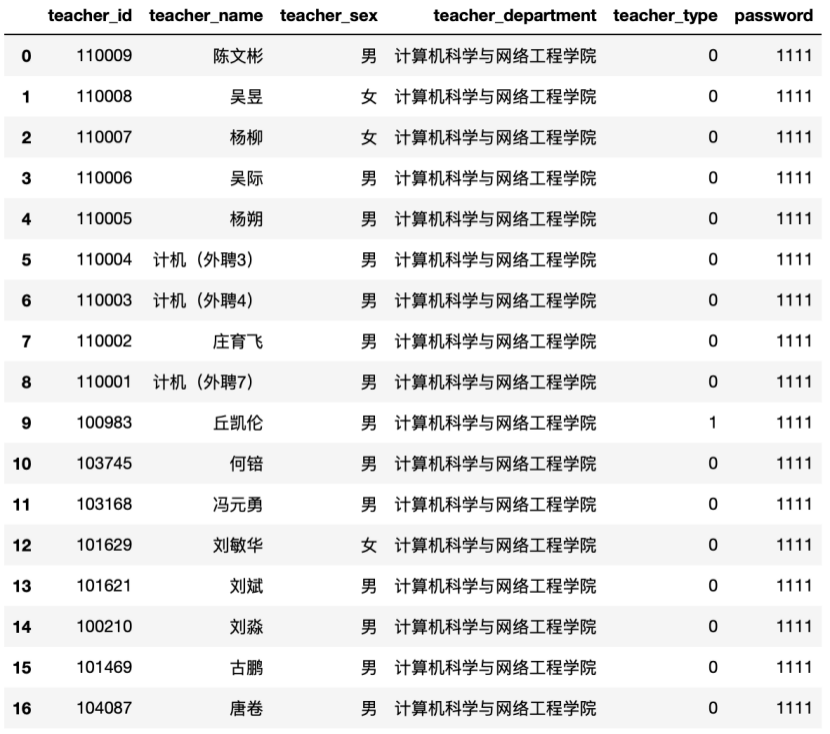
表6-3-3 课程组教师表(显示全部)

表6-3-4 学生表(仅显示部分)
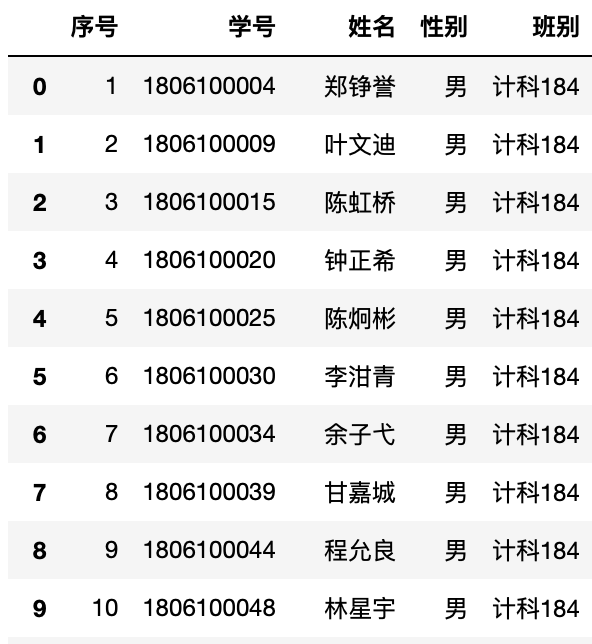
表6-3-5 班级表(显示全部)
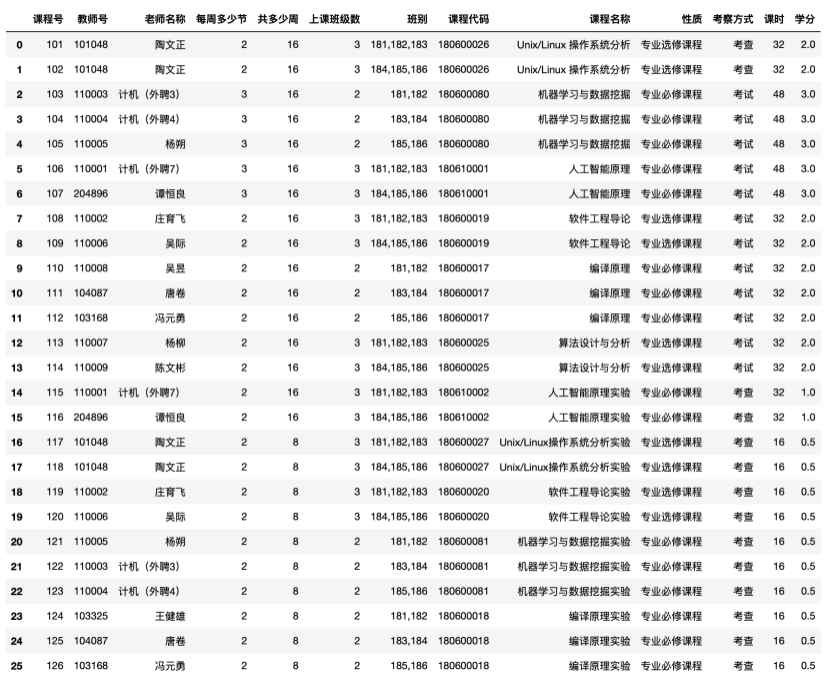
前面5个表格的数据可以通过简单的数据预处理即可获得,重点阐述表6-3-6是如何处理获得的。分析课程组一共有11个,与每个课程组所拥有的老师数量,以及所任教的班级数量。当只有1个老师,该老师需开设两个课程,分别教3个班;当有2个老师,一人开一个课程,分别教3个班;当有3个老师,则一人开一个课程,分别教2个班。分析完毕,处理数据可得,需开设课程为26个,课程设置如表6-3-6所示。
表6-3-6 课程表(显示全部)
6.4 制作Sql语句
由前面分析得到的表格,可以生成导入数据库的sql语句,为了避免繁琐的操作,可使用python生成大量的导入语句。注:我们有八个表格,其中课程表格需要智能排课后获得上课时间,班级课程表格、分数表格需要课程号作为外码,但我提前给出sql语句,排课算法将会介绍上课时间如何得来。
处理程序如下:
for index,row in name181[5:].iterrows():
print(f"INSERT INTO student VALUES({row[1]},'{row[2]}','{row[3]}',date('2018-09-01'),'计算机科学与技术','{row[1][5:]}',{row[4][2:]});")
for index,row in name182[5:].iterrows():
print(f"INSERT INTO student VALUES({row[1]},'{row[2]}','{row[3]}',date('2018-09-01'),'计算机科学与技术','{row[1][5:]}',{row[4][2:]});")
for index,row in name183[5:].iterrows():
print(f"INSERT INTO student VALUES({row[1]},'{row[2]}','{row[3]}',date('2018-09-01'),'计算机科学与技术','{row[1][5:]}',{row[4][2:]});")
for index,row in name184[5:].iterrows():
print(f"INSERT INTO student VALUES({row[1]},'{row[2]}','{row[3]}',date('2018-09-01'),'计算机科学与技术','{row[1][5:]}',{row[4][2:]});")
for index,row in name185[5:].iterrows():
print(f"INSERT INTO student VALUES({row[1]},'{row[2]}','{row[3]}',date('2018-09-01'),'计算机科学与技术','{row[1][5:]}',{row[4][2:]});")
for index,row in name186[5:].iterrows():
print(f"INSERT INTO student VALUES({row[1]},'{row[2]}','{row[3]}',date('2018-09-01'),'计算机科学与技术','{row[1][5:]}',{row[4][2:]});")

图6.4.1 插入学生表语句(部分)
处理程序如下:
for row in course['name'].value_counts().keys():
k+=1
name = row
linshi = course[course['name']==row]['bixiu'].value_counts().keys()[0]
ddd = course[course['name']==row]['duoshaojieke'].value_counts().keys()[0]
jilu = courses_courses[courses_courses['course_name']==row]
print(f"INSERT INTO groups VALUES({list(jilu['course_id'])[0]},'{name}','{linshi}','{list(jilu['exam_method'])[0]}',{list(jilu['class_hour'])[0]},{list(jilu['credit'])[0]});")

图6.4.2 插入课程组语句
处理程序如下:
import numpy as np
for row in course['name'].value_counts().keys():
pp = 0
k+=1
name = row
linshi = course[course['name']==row]['teacher_name'].value_counts().keys()
jilu = courses_courses[courses_courses['course_name']==row]
for j in linshi:
ids = np.array(course[course['teacher_name']==j]['teacher_id'])[0]
if pp==0:
print(f"INSERT INTO group_teacher VALUES({list(jilu['course_id'])[0]},'{ids}',1);")
else:
print(f"INSERT INTO group_teacher VALUES({list(jilu['course_id'])[0]},'{ids}',0);")
pp+=1
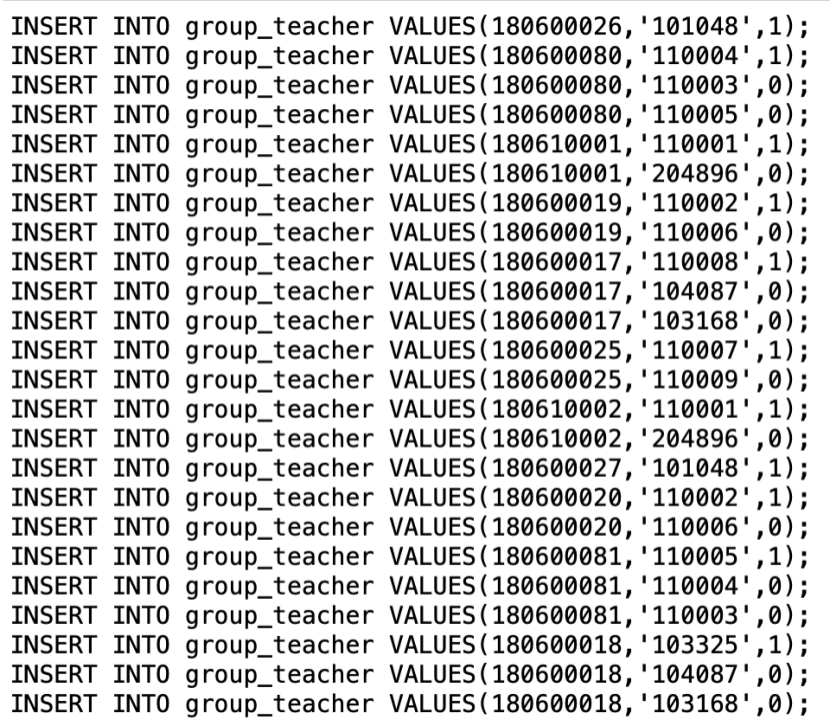
图6.4.3 插入课程组教师语句

图6.4.4 插入课程语句
处理程序如下:
for index,row in teacher.iterrows():
print(f"INSERT INTO teacher VALUES({row[0]},'{row[1]}','{1111}','{row[2]}',{row[4]});")

图6.4.5 插入教师语句(部分)
处理程序如下:
for index,row in all_course.iterrows():
print(f"INSERT INTO course VALUES({row[0]},'{row[8]}',{row[1]},{row[7]},'{row[13]}','{row[6]}','{row[14]}');")

图6.4.6 插入课程语句(部分)
处理程序如下:
for index,row in all_course.iterrows():
for i in row[6].split(','):
print(f"INSERT INTO class_course VALUES({row[0]},{i});")
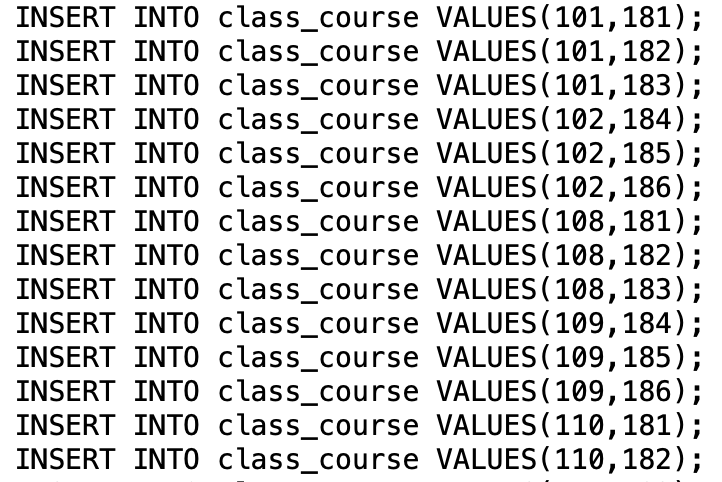
图6.4.7 插入班级课程语句(部分)
处理程序如下:
for index,row in all_course.iterrows():
if row[9] =='专业必修课程' and '181' in row[6]:
for index,rowst in name181[5:].iterrows():
num = np.random.randint(50, 100)
print(f"INSERT INTO score VALUES({rowst[1]},{row[0]},{num});")
for index,row in all_course.iterrows():
if row[9] =='专业必修课程' and '182' in row[6]:
for index,rowst in name182[5:].iterrows():
num = np.random.randint(50, 100)
print(f"INSERT INTO score VALUES({rowst[1]},{row[0]},{num});")
for index,row in all_course.iterrows():
if row[9] =='专业必修课程' and '183' in row[6]:
for index,rowst in name183[5:].iterrows():
num = np.random.randint(50, 100)
print(f"INSERT INTO score VALUES({rowst[1]},{row[0]},{num});")
for index,row in all_course.iterrows():
if row[9] =='专业必修课程' and '184' in row[6]:
for index,rowst in name184[5:].iterrows():
num = np.random.randint(50, 100)
print(f"INSERT INTO score VALUES({rowst[1]},{row[0]},{num});")
for index,row in all_course.iterrows():
if row[9] =='专业必修课程' and '185' in row[6]:
for index,rowst in name185[5:].iterrows():
num = np.random.randint(50, 100)
print(f"INSERT INTO score VALUES({rowst[1]},{row[0]},{num});")
for index,row in all_course.iterrows():
if row[9] =='专业必修课程' and '186' in row[6]:
for index,rowst in name186[5:].iterrows():
num = np.random.randint(50, 100)
print(f"INSERT INTO score VALUES({rowst[1]},{row[0]},{num});")

图6.4.8 插入分数语句(部分)
第七章 智能排课算法
7.1 排课要求
(一)1-16周,周一到周五,1-9节; 课程安排的时间长度必须和课程学分一致;
(二)同个班同个小节不能上多门课,不同班同门课可能一起上;
(三)同个老师不能在同一小节同时上两个课;
(四)上课时间尽可能分散开,不要集中于某一天,减缓学生压力;
7.2 准备工作
(一)划分每天的1-9节课为四大节,白天三大节,每节2课时;晚上一大节,每节3课时,如下表7-2-1。
表7-2-1 课程表划分
| 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | |
|---|---|---|---|---|---|
| 第一大节8:30~10:05 | |||||
| 第二大节10:25~12:00 | |||||
| 第三大节15:00~16:35 | |||||
| 第四大节18:00~20:25 | |||||
| (二)将每周2课时的课程与3课时的课程分开排课,用同一套算法,每周2课时的课程在白天进行排课,每周3课时的课程在晚上进行排课,当白天或晚上排课效率不高时,再调整多余部分课程到另一时间段。 | |||||
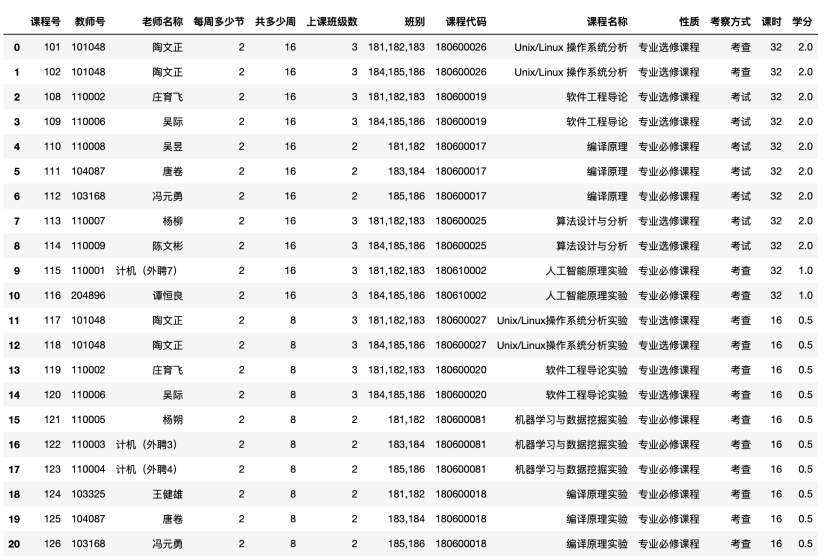
|
图7.2.1 每周2课时的课程

图7.2.2 每周3课时的课程
7.3 遗传算法
(一)我们以每周2课时的课程为例子,进行下面遗传算法选课流程的介绍。我们注意到存在着只上8周的课程,没有覆盖整个16周,所以选择把两个8周且班级相同的课程并到一起,或者有包含关系的两个课程(前面8周集合元素覆盖或等于后面8周的),算一个16周课程进行以下算法分析。
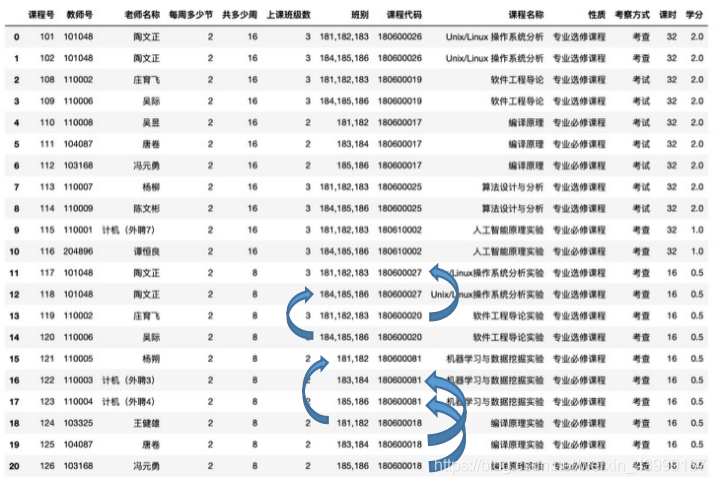
图7.3.1 课程合并
合并后,我们需要排课的课程号如下:
[101,102,108,109,110,111,112,113,114,115,116,117,118,121,122,123]
其中合并关系为:117-》119,118-》120,121-》124,122-》125,123-》126
(二)我们将每天的课程进行编号,以便于下面算法的进行。
表7-3-1 课程表标记
| 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | |
|---|---|---|---|---|---|
| 第一大节8:30~10:05 | 1 | 4 | 7 | 10 | 13 |
| 第二大节10:25~12:00 | 2 | 5 | 8 | 11 | 14 |
| 第三大节15:00~16:35 | 3 | 6 | 9 | 12 | 15 |
(三)如表7-2-1所示,我们每节课安排的时间范围即为1~15,我们需要排课的列表为[101,102,108,109,110,111,112,113,114,115,116,117,118,121,122,123],长度为16,所以我们可以随机生成一个list,长度为16,数字范围为1~15,这样一个列表可以表示,每一门课程所安排的时间;
(四)显然,随机数的排课具有很大不确定性,可能会导致一些课程冲突、课程集中某个时间段等等,所以我们想要去找到一条list,可以让我们的排课让老师同学们都满意;
(五)这里,引入遗传算法,这里简单介绍遗传算法,遗传算法是一种局部寻优算法,可以根据我们定义的遗传算子,通过交叉、变异等操作,生成更多不同算子,帮助我们在高维空间上寻找局部最优解,这里的最优解的条件由我们实现者根据具体实际情况进行定义。下面给出一些基本操作:
① 遗传算子-染色体即为一条与需排课列表长度的时间序列,范围为1~15,生成染色体时必须保证同一个时间段的课程老师、班级不能冲突,否则重新生成;
② 选择种群:优胜劣汰,对低于平均适应度的染色体进行交叉和突变,高于平均适应度的进行保留;
③ 交叉操作:选取两条父母染色体,对母亲随机截取一段S,直接替换父亲的该段,返回拼接后的染色体;
④ 突变操作:对染色体进行随机截取一段,进行翻转操作;突变某个点的时间值,范围为1~15
⑤ 种群进化:种群内每一根染色体都有可能进行交叉和突变,取决于交叉率和突变率。
7.4 适应度函数
定义适应度函数,也类似于机器学习的目标函数,我们需要优化它,达到最优解,从而获得我们的最优排课顺序。这里,我们的得分函数由三部分组成:
① 第一部分:时间段权重
根据网上部分资料,一般学生课程安排有权重调整,即早上的课程权重相应大些,特别是第二大节课,对应的下午的课程权重少些,还有星期二下午不开课(广州大学惯例),星期五的课权重少些,这里给出我定义的权重表7-4-1。第一部分得分算法:染色体list点乘对应得分除以[0.9*len(list)]
100,
注:[0.9
len(list)]指的是全部安排在第二大节,得分为满分100分。
表7-4-1 课程表权重
| 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | |
|---|---|---|---|---|---|
| 第一大节8:30~10:05 | 0.88 | 0.88 | 0.88 | 0.88 | 0.85 |
| 第二大节10:25~12:00 | 0.9 | 0.9 | 0.9 | 0.9 | 0.88 |
| 第三大节15:00~16:35 | 0.85 | 0 | 0.85 | 0.85 | 0.8 |
代码如下:
grade = {1: 0.88, 2:0.9 ,3: 0.85,4:0.88 ,5: 0.9,6: 0,7:0.88, 8:0.9, 9:0.85, 10:0.88,11:0.9,12:0.85,13:0.85,14:0.88,15:0.8}
point1 = 0 #不同时间段不同得分权重,以全部9.0为满分权重
for i in gene:
point1 += grade[i]
point1 = point1/(len(gene) *0.9)*100
② 第二部分:全部课程时间方差
为了保证我们的整个专业排课结果尽可能分散,我们可以通过方差大小来调整,我们计算以刚好15个课程铺满整个课表的方差为基准,基准为ave_var = np.var([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]),我们希望我们所排的课程的方差越接近于这个方差越好,所以我给出的第二部分得分算法为:
point2 = (1 - np.abs(np.var(gene) -ave_var) /ave_var) *100
。
③ 第三部分:每个班级课程时间方差
第二部分优化的所有课程,我希望每个班级内部的课程也可以得到优化,这里设置一个最大方差
max_var = np.var([1,8,15])
,每个班级的课程安排时间的方差也此为标准,第三部分得分算法为:分别计算6个班级的课程时间方差相加,除以6*max_var,然后乘以100。
三部分得分函数总结完毕,我们给予各个部分一个权重,以便于我们更倾向于哪一部分时可以进行适当调整。在这里,我给出本次实验所用的最终得分表示:
point = point1 + 0.8* point2 + 0.6* point3
7.5 排课效果
遗传算法参数选择:交叉率0.4、突变率0.3、种群大小20、进化代数100
最优时间序列为:[15, 14, 7, 1, 9, 4, 4, 12, 2, 2, 11, 11, 12, 10, 10, 13]
图7.5.1为遗传算法寻优局部最优解的迭代过程,三部分得分最高为240,局部寻优效果为216.12。图7.5.2为调课时间整理后的部分展示,可以看到课程分布较均匀,且时间、班级、教师完全无冲突。
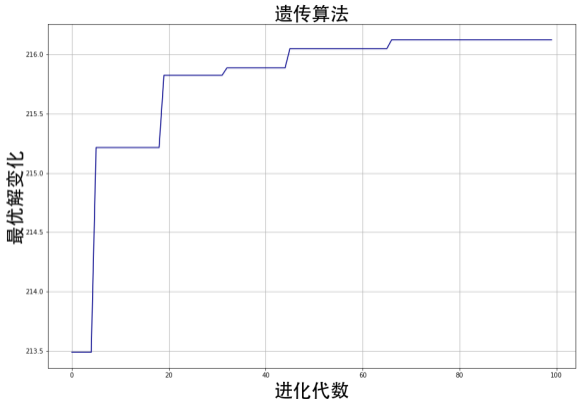
图7.5.1 智能调课遗传迭代图
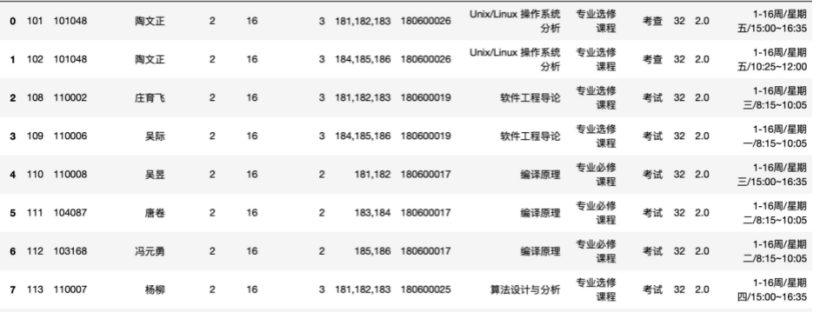
图7.5.2 调课时间展示(部分)
第八章 系统实现
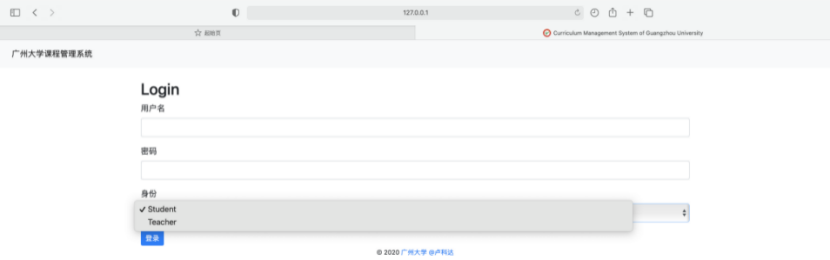
8.1 登陆界面
学生:学号+密码(学号后5位)
教师:教师号+密码(1111)
8.2 学生界面
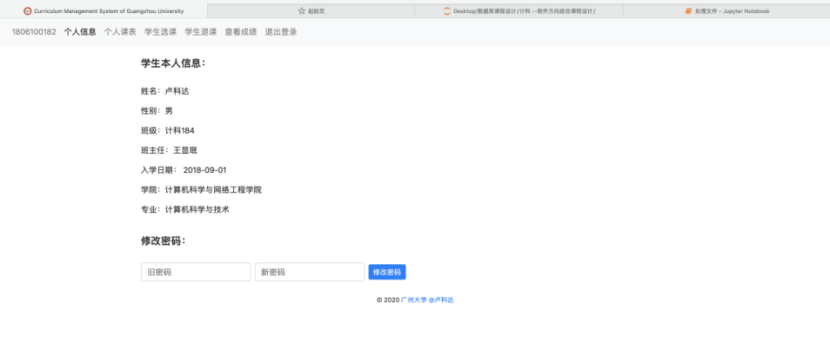
8.2.1 学生个人信息界面
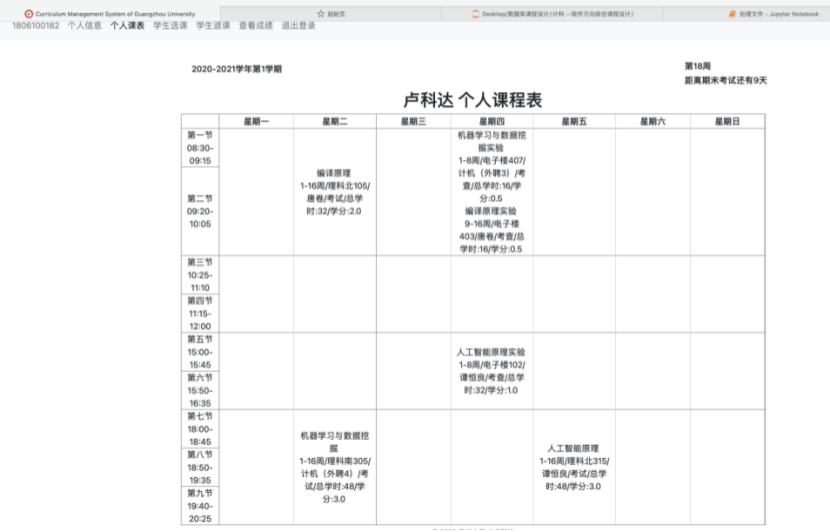
8.2.2 学生个人课表界面
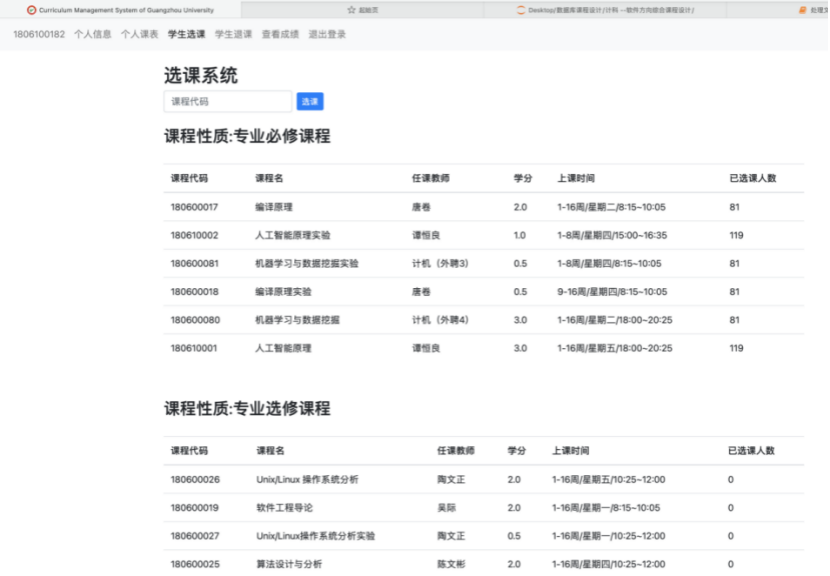
8.2.3 学生选课界面
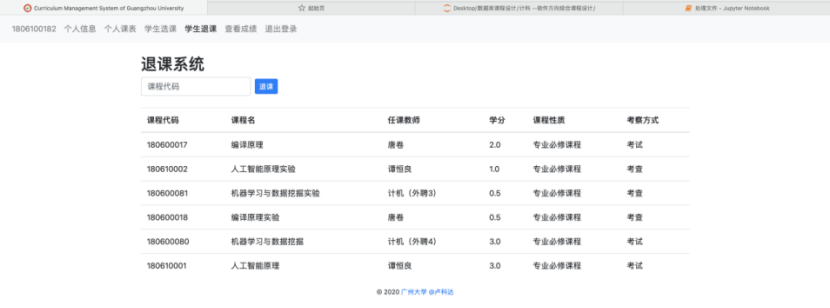
8.2.4 学生退课界面
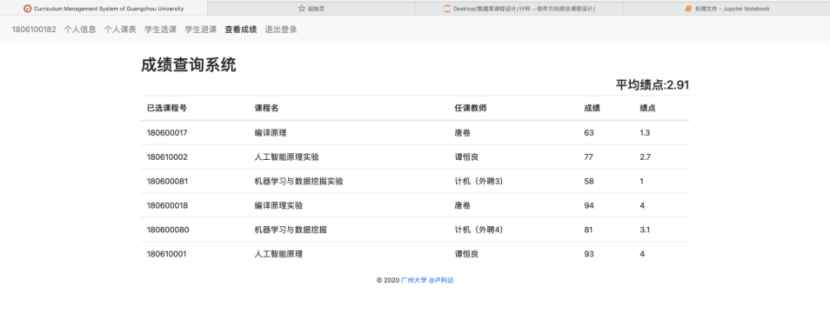
8.2.5 学生查看成绩界面
8.3 教师界面
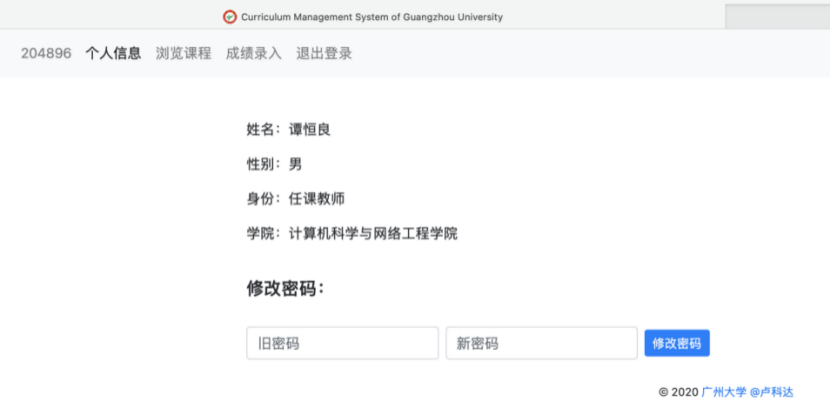
8.3.1 教师信息界面
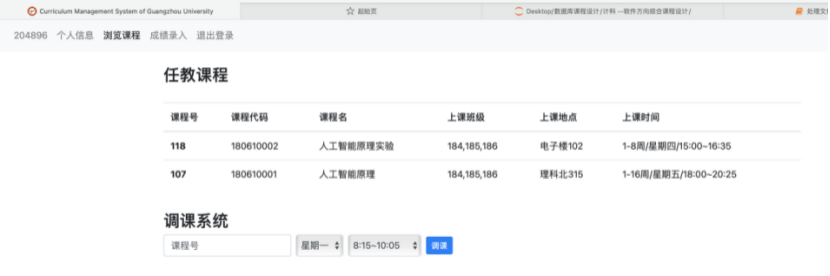
8.3.2 任教课程和调课系统界面
8.3.3 课程学生名单界面

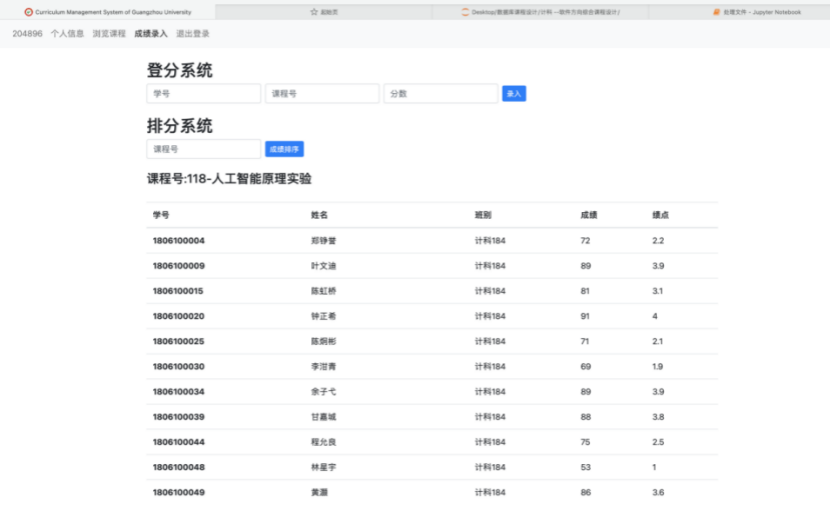
8.3.4 登分、排分系统界面
8.4 系主任界面
8.4.1 查看所有学生界面
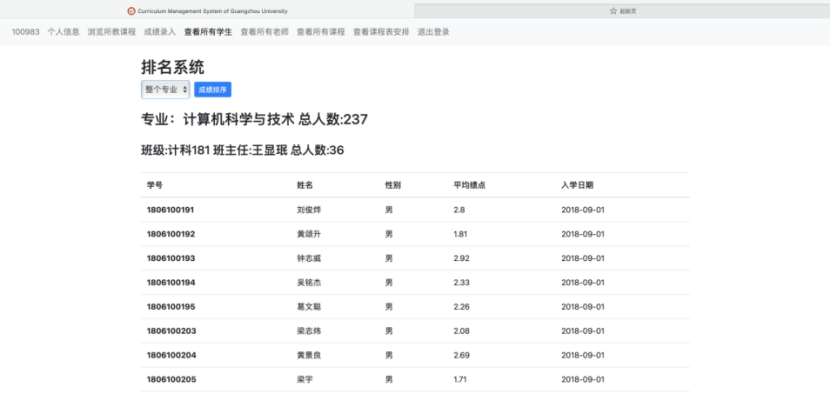
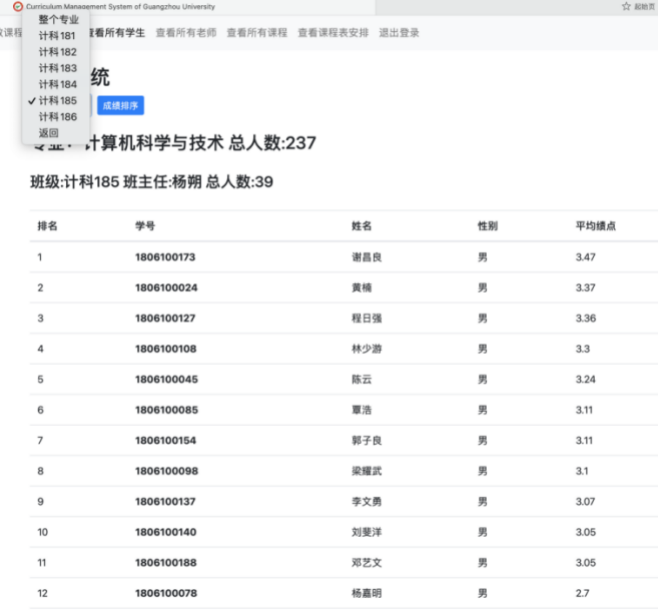
8.4.2 班级成绩、专业成绩排序
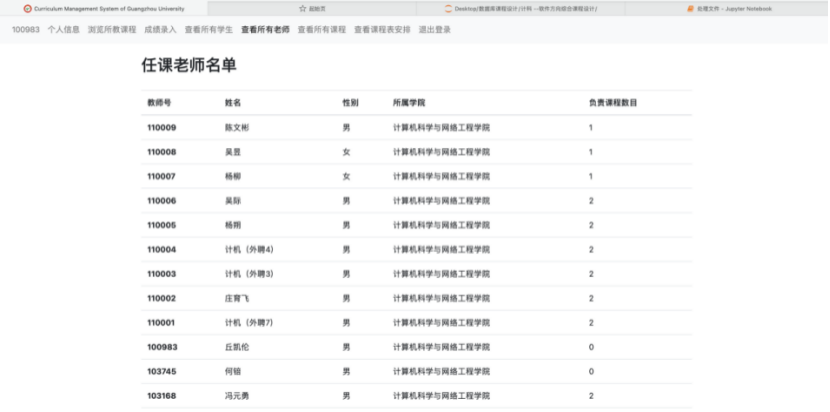
8.4.3 查看所有老师
8.4.4 查看所有课程
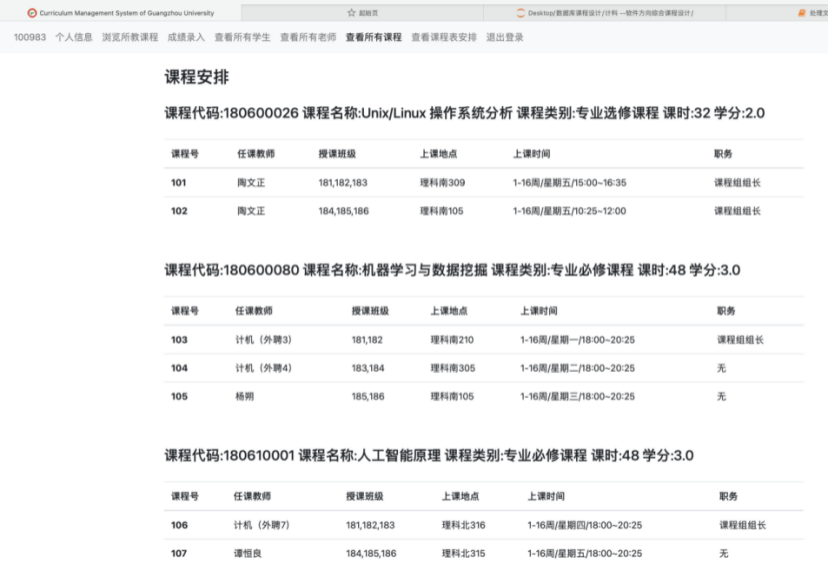
8.4.5 查看所有班级课程表


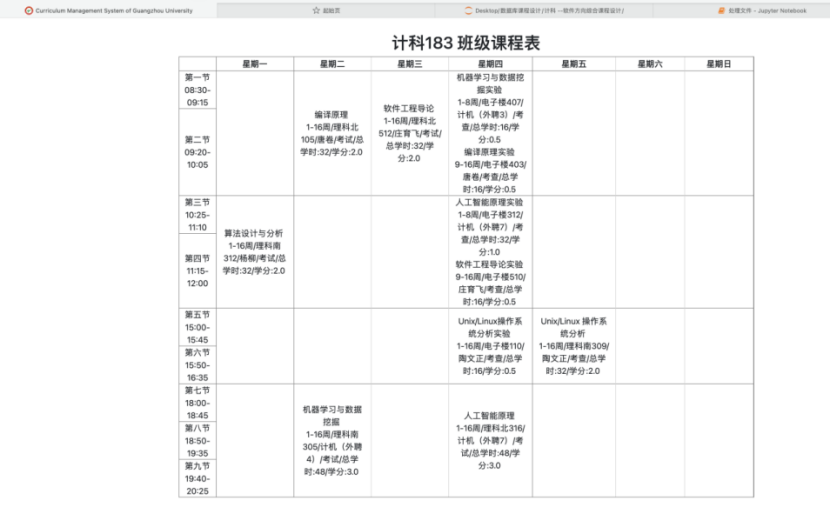
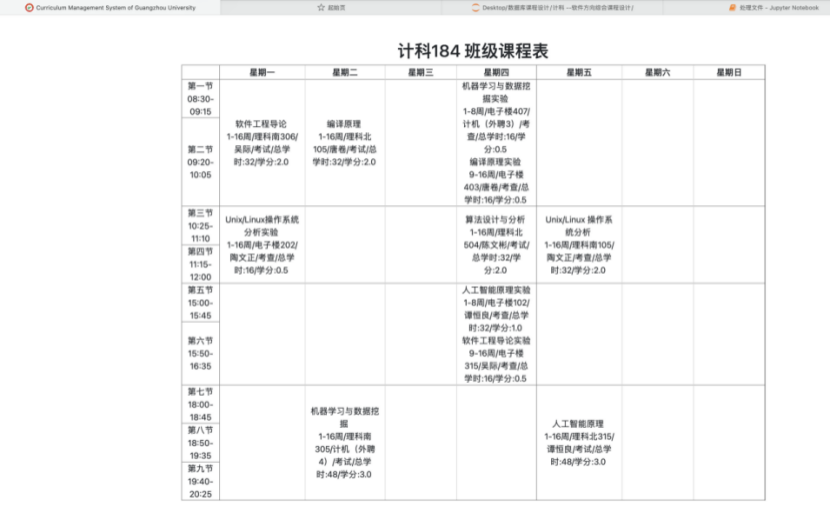
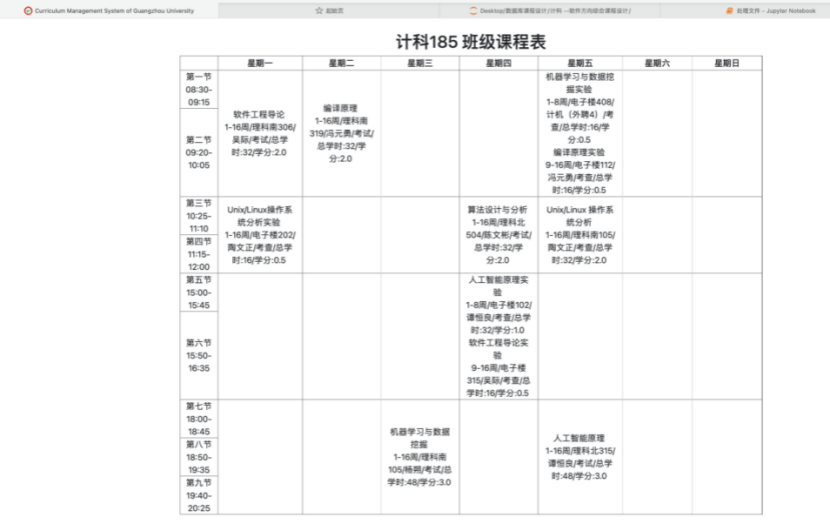
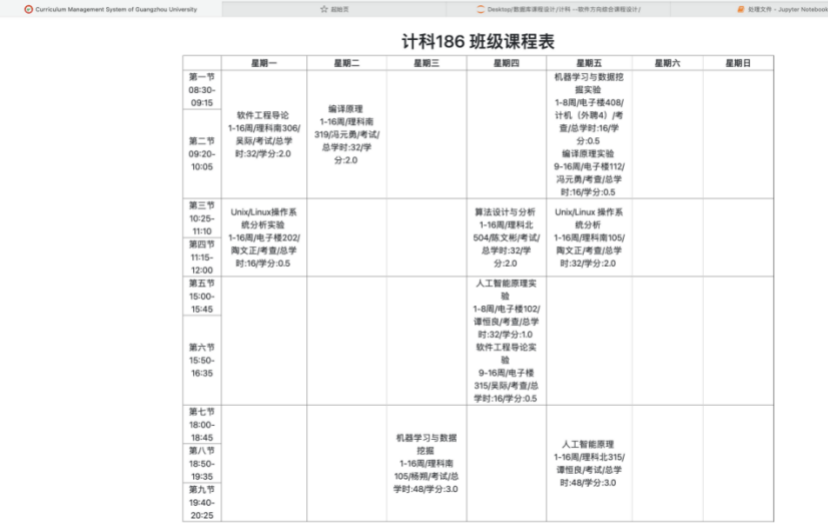
第九章 附录
9.1 遗传算法代码
class YIchuan(object):
time = [1, 2, 3, 4, 5, 7, 8, 9, 10, 11, 12, 13, 14, 15]
course = np.array(cno) # 课程数组
course_name = np.array([])
population_size = 100 # 种群大小,每个种群含有多少条基因
cross_rate = 0.9 # 交叉率
change_rate = 0.1 # 突变率
population = np.array([]) # 种群数组
fitness = np.array([]) # 适应度数组
course_size = len(cno) # 标记城市数目
iter_num = 200 # 最大迭代次数
best_distance = 1 # 记录目前最优方案
best_gene = [] # 记录目前最优旅行方案
all_best_distance = [] # 记录每一代最优距离
def __init__(self, cross_rate, change_rate, population_size, iter_num):
self.fitness = np.zeros(self.population_size)
self.cross_rate = cross_rate
self.change_rate = change_rate
self.population_size = population_size
self.iter_num = iter_num
self.course_size = len(cno) # 标记城市数目
self.all_best_distance = []
def init(self):
TSP = self
# TSP.load_course_data() # 加载城市数据
TSP.population = TSP.creat_population(TSP.population_size) # 创建种群
# print(TSP.population)
TSP.fitness = TSP.get_fitness(TSP.population) # 计算初始种群适应度
# print(TSP.fitness)
def creat_population(self, size):
"""
创建种群
:param size:种群大小
:return: 种群
"""
population = [] # 存储种群生成的基因
for i in range(size):
right = 1
gene = self.time + random.sample(self.time, self.course.shape[0] - len(self.time))
np.random.shuffle(gene) # 打乱数组[0,...,coursecity_size]
j_course = []
s_course = []
while (right):
right = 0
for j in range(len(gene)):
if gene[j] == 6:
right = 1
break
for k in range(len(gene) - j - 1):
s = k + j + 1
if (gene[j] == gene[s]):
if two_school_courses.iloc[j, :]['teacher_name'] == two_school_courses.iloc[s, :][
'teacher_name']:
gene = self.time + random.sample(self.time, self.course.shape[0] - len(self.time))
np.random.shuffle(gene) # 打乱数组[0,...,coursecity_size]
right = 1
if two_school_courses.iloc[j, :]['班别'] == two_school_courses.iloc[s, :]['班别']:
gene = self.time + random.sample(self.time, self.course.shape[0] - len(self.time))
np.random.shuffle(gene) # 打乱数组[0,...,coursecity_size]
right = 1
j_course = two_school_courses.iloc[j, :]['班别'].split(',')
s_course = two_school_courses.iloc[s, :]['班别'].split(',')
okk = [js for js in j_course if js in s_course]
if okk:
gene = self.time + random.sample(self.time, self.course.shape[0] - len(self.time))
np.random.shuffle(gene) # 打乱数组[0,...,coursecity_size]
right = 1
population.append(gene) # 加入种群
return np.array(population)
def get_fitness(self, population):
"""
获得适应度
:param population:种群
:return: 种群每条基因对应的适应度
"""
fitness = np.array([]) # 适应度记录数组
for i in range(population.shape[0]):
gene = population[i] # 取其中一条基因(编码解,个体)
dis = self.compute(gene) # 计算此基因优劣(距离长短)
dis = dis / self.best_distance # 当前population[i](个体)分数除以 当前最优分数;越近适应度越高,最优适应度为1
fitness = np.append(fitness, dis) # 保存适应度population[i]
return fitness
def select_population(self, population):
"""
选择种群,优胜劣汰
策略:低于平均的要替换
:param population: 种群
:return: 更改后的种群
"""
best_index = np.argmax(self.fitness)
ave = np.median(self.fitness, axis=0)
for i in range(self.population_size):
if i != best_index and self.fitness[i] < ave:
gene = self.cross(population[best_index], population[i]) # 交叉
gene = self.change(gene) # 变异
right = 1
while (right):
right = 0
for jjj in range(len(gene)):
if gene[jjj] == 6:
print('cao')
right = 1
break
for kkk in range(len(gene) - jjj - 1):
s = kkk + jjj + 1
if (gene[jjj] == gene[s]):
if two_school_courses.iloc[jjj, :]['teacher_name'] == two_school_courses.iloc[s, :][
'teacher_name']:
gene = self.cross(population[best_index], population[i]) # 交叉
gene = self.change(gene) # 变异
right = 1
if two_school_courses.iloc[jjj, :]['班别'] == two_school_courses.iloc[s, :]['班别']:
gene = self.cross(population[best_index], population[i]) # 交叉
gene = self.change(gene) # 变异
right = 1
j_course = two_school_courses.iloc[jjj, :]['班别'].split(',')
s_course = two_school_courses.iloc[s, :]['班别'].split(',')
okk = [js for js in j_course if js in s_course]
if okk:
gene = self.cross(population[best_index], population[i]) # 交叉
gene = self.change(gene) # 变异
right = 1
population[i, :] = gene[:]
return population
def cross(self, parent1, parent2):
"""
交叉
:param parent1: 父亲
:param parent2: 母亲
:return: 儿子基因
"""
if np.random.rand() > self.cross_rate:
return parent1
index1 = np.random.randint(0, self.course_size - 1)
index2 = np.random.randint(index1, self.course_size - 1)
tempgene = parent2[index1:index2] # 交叉的基因片段
parent1[index1:index2] = tempgene
newGene = np.array(parent1)
return newGene
def reverse_gene(self, gene, i, j):
"""
翻转i到j位置的基因
:param gene: 基因
:param i: 第i个位置
:param j: 第j个位置
:return: 翻转后的基因
"""
if i >= j:
return gene
if j > self.course_size - 1:
return gene
parent1 = np.copy(gene)
tempgene = list(parent1[i:j])
tempgene.reverse()
parent1[i:j] = np.array(tempgene)
return np.array(parent1)
def change(self, gene):
"""
突变,主要使用翻转和突变某个位置的选课时间
:param gene: 基因
:return: 突变后的基因
"""
if np.random.rand() > self.change_rate:
return gene
index1 = np.random.randint(0, self.course_size - 1)
index2 = np.random.randint(index1, self.course_size - 1)
new_gene = self.reverse_gene(gene, index1, index2) # 翻转
if np.random.rand() > self.change_rate:
return new_gene
charu = random.sample(self.time, 1)[0]
station = random.randint(0, self.course_size - 1)
new_gene[station] = charu
new_gene = np.array(new_gene)
return new_gene
def evolution(self):
"""
迭代进化种群
:return: None
"""
for i in range(self.iter_num):
best_index = np.argmax(self.fitness)
worst_f_index = np.argmin(self.fitness)
local_best_genee = self.population[best_index]
local_best_distance = self.compute(local_best_genee)
if i == 0: # 第一代记录最优基因
self.best_gene = local_best_genee
self.best_distance = self.compute(local_best_genee)
if local_best_distance > self.best_distance:
self.best_distance = local_best_distance # 记录最优值
self.best_gene = local_best_genee # 记录最个体基因
else:
self.population[worst_f_index] = self.best_gene # 替换掉最差的基因
print('代数:%d 最优得分:%s' % (i, self.best_distance))
self.all_best_distance.append(self.best_distance)
self.population = self.select_population(self.population) # 选择淘汰种群
self.fitness = self.get_fitness(self.population) # 计算种群适应度
for j in range(self.population_size):
k = np.random.randint(0, self.population_size - 1)
if j != k:
gene = self.cross(self.population[j], self.population[k]) # 交叉种群中第j,k个体的基因
gene = self.change(gene) # 突变种群中第j个体的基因
right = 1
while (right):
right = 0
for jjj in range(len(gene)):
if gene[jjj] == 6:
print('caonima')
right = 1
break
for kkk in range(len(gene) - jjj - 1):
s = kkk + jjj + 1
if (gene[jjj] == gene[s]):
if two_school_courses.iloc[jjj, :]['teacher_name'] == two_school_courses.iloc[s, :][
'teacher_name']:
gene = self.cross(self.population[j], self.population[k]) # 交叉种群中第j,k个体的基因
gene = self.change(gene) # 突变种群中第j个体的基因
right = 1
if two_school_courses.iloc[jjj, :]['班别'] == two_school_courses.iloc[s, :]['班别']:
gene = self.cross(self.population[j], self.population[k]) # 交叉种群中第j,k个体的基因
gene = self.change(gene) # 突变种群中第j个体的基因
right = 1
j_course = two_school_courses.iloc[jjj, :]['班别'].split(',')
s_course = two_school_courses.iloc[s, :]['班别'].split(',')
okk = [js for js in j_course if js in s_course]
if okk:
gene = self.cross(self.population[j], self.population[k]) # 交叉种群中第j,k个体的基因
gene = self.change(gene) # 突变种群中第j个体的基因
right = 1
self.population[j] = gene
def load_city_data(self, file='city.csv', delm=';', head=10):
# 加载实验数据
data = pd.read_csv(file, delimiter=delm, header=None).values
self.course = data[:head, 1:]
self.course = data[:head, 0]
self.city_size = data[:head].shape[0]
def compute(self, gene):
grade = {1: 0.88, 2: 0.9, 3: 0.85, 4: 0.88, 5: 0.9, 6: 0, 7: 0.88, 8: 0.9, 9: 0.85, 10: 0.88, 11: 0.9, 12: 0.85,
13: 0.85, 14: 0.88, 15: 0.8}
point1 = 0 # 不同时间段不同得分权重,以全部9.0为满分权重
for i in gene:
point1 += grade[i]
point1 = point1 / (len(gene) * 0.9) * 100
point2 = 0
# 计算所有课的方差,保证每个课在总课表上分布均匀
ave_var = np.var(time)
point2 = (1 - np.abs(np.var(gene) - ave_var) / ave_var) * 100
point3 = 0
# 同一个班别的课最好均匀分散在每一天,以方差最大为满分权重
max_var = np.var([1, 8, 15])
a181 = [0, 2, 4, 7, 9, 11, 13]
a182 = [0, 2, 4, 7, 9, 11, 13]
a183 = [0, 2, 5, 7, 9, 11, 14]
a184 = [1, 3, 5, 8, 10, 12, 14]
a185 = [1, 3, 6, 8, 10, 12, 15]
a186 = [1, 3, 6, 8, 10, 12, 15]
linshi = []
for i in a181:
linshi.append(gene[i])
point3 += np.var(linshi)
linshi = []
for i in a182:
linshi.append(gene[i])
point3 += np.var(linshi)
linshi = []
for i in a183:
linshi.append(gene[i])
point3 += np.var(linshi)
linshi = []
for i in a184:
linshi.append(gene[i])
point3 += np.var(linshi)
linshi = []
for i in a185:
linshi.append(gene[i])
point3 += np.var(linshi)
linshi = []
for i in a186:
linshi.append(gene[i])
point3 += np.var(linshi)
point3 = point3 / (6 * max_var) * 100
point = point1 + 0.8 * point2 + 0.6 * point3
# print(point1,point2,point3)
return point
def draw_dis(selfs):
# 绘制最优选课曲线
#:return: none
print(selfs.all_best_distance)
print(len(selfs.all_best_distance))
x = [i for i in range(len(selfs.all_best_distance))]
y = selfs.all_best_distance
fig, ax = plt.subplots(figsize=(15, 10))
font = FontProperties(fname=r"/System/Library/Fonts/STHeiti Medium.ttc", size=20)
ax.plot(x, y, color='darkblue', linestyle='-')
plt.xlabel("进化代数", FontProperties=font, size=30) # X轴标签
plt.ylabel("最优解变化", FontProperties=font, size=30) # Y轴标签
plt.title("遗传算法", FontProperties=font, size=30)
plt.grid()
plt.show()
9.2 数据库连接、增删改代码
# -*- coding: utf-8 -*-
import sqlite3
# 建立数据库连接
def OpenDb():
database = "./data.db"
conn = sqlite3.connect(database)
return conn
# 获取数据库连接
def GetSql(conn, sql):
cur = conn.cursor()
cur.execute(sql)
fields = []
for field in cur.description:
fields.append(field[0])
result = cur.fetchall()
# for item in result:
# print(item)
cur.close()
return result, fields
# 关闭数据库连接
def CloseDb(conn):
conn.close()
# 获取数据库连接
def GetSql2(sql):
conn = OpenDb()
result, fields = GetSql(conn, sql)
CloseDb(conn)
return result, fields
# 改
def UpdateData(data, tablename):
conn = OpenDb()
values = []
cursor = conn.cursor()
idName1 = list(data)[0]
idName2 = list(data)[1]
for v in list(data)[2:]:
values.append("%s='%s'" % (v, data[v]))
sql = "update %s set %s where %s='%s' and %s='%s'" % (
tablename, ",".join(values), idName1, data[idName1], idName2, data[idName2])
# print (sql)
cursor.execute(sql)
conn.commit()
CloseDb(conn)
# 增
def InsertData(data, tablename):
conn = OpenDb()
values = []
cusor = conn.cursor()
fieldNames = list(data)
for v in fieldNames:
values.append(data[v])
sql = "insert into %s (%s) values( %s) " % (tablename, ",".join(fieldNames), ",".join(["?"] * len(fieldNames)))
# print(sql)
cusor.execute(sql, values)
conn.commit()
CloseDb(conn)
# 删
def DelDataById(id1, id2, value1, value2, tablename):
conn = OpenDb()
# values = []
cursor = conn.cursor()
sql = "delete from %s where %s=? and %s=?" % (tablename, id1, id2)
# print (sql)
cursor.execute(sql, (value1, value2))
conn.commit()
CloseDb(conn)
9.3 前端设计代码
见附件
处理文件代码:处理文件.ipynb
前端设计:文件夹templates
9.4 执行代码
# 安装Flask
pip install Flask
# 安装Bootstrap-Flask
pip install Bootstrap-Flask
# 安装SQLAlchemy
pip install SQLAlchemy
pycharm执行app.py即可