当我们使用redis的主从架构时存在一个问题。当master 节点挂掉时,redis服务将不可用。需要人工干预,修改配置。
sentinal就是为了解决redis的高可用问题。主要功能如下:
1.监控所用节点(master,slave)的运行状态。
2.消息通知,当一个节点出现故障时,可能通过提供的API向管理员发送消息提醒。
3.故障转移,当master节点出现故障时,通过对slave的进行选举,升级为新的master
4.配置调整通知:当master节点变更时,会修改节点配置文件信息(master节点变更相关配置)、并通知其他sentinal节点变化。还会通知连接的客户端,告知新master节点信息。
当我们部署sentinal 分布式系统时,最少为三个节点。因为当主节点发生故障时,每一个sentinal 要进行对slave的投票选举。经典的三节点哨兵集群部署如下:
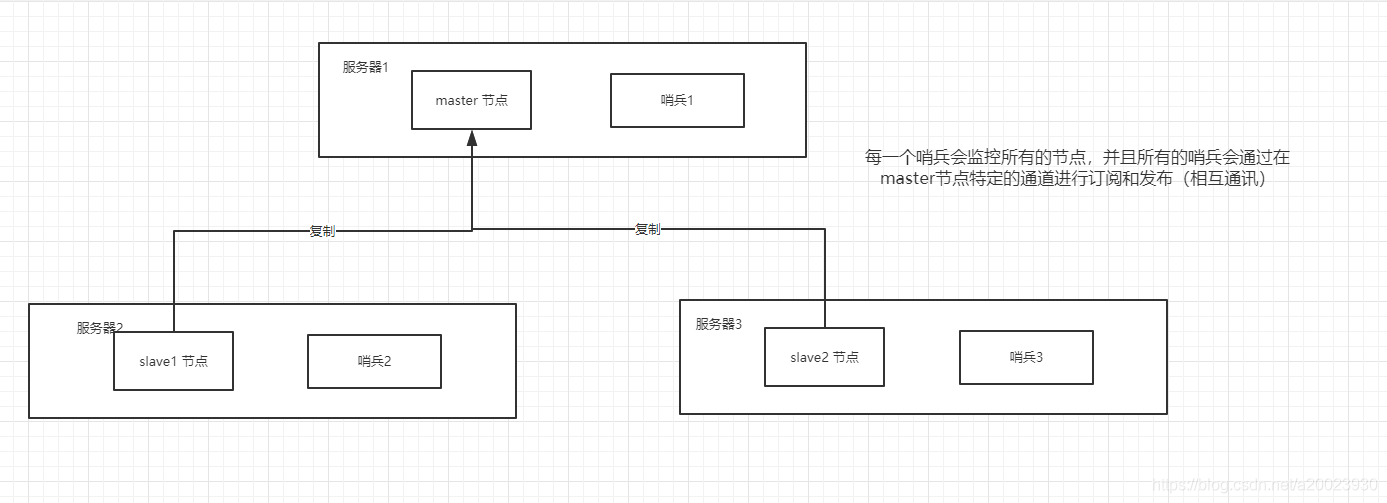
一、哨兵的监控原理:
1.1
每个哨兵10秒会向主节点和从节点发送info命令,获取到最新的 拓扑结构。当配置哨兵时只用配置主节点信息即可,因为可以通过向主节点发送info信息得到从节点的信息,有新从节点加入时也能通过info知道。
1.2
哨兵之间的通讯是通过redis的publish和subscribe来完成。每一个哨兵2秒会向指定的通道发送自己监控情况和自身的节点信息。其他哨兵订阅消息来确定主节点的运行情况。当有新哨兵节点加入或哨兵节点异常时,相互之间也能感知到。
1.3
每个哨兵1秒会向主节点和从节点进行 ping 命令,当超过down-after-milliseconds时间无正确响应是则主观(sdown)认为该节点宕机。当宕机的节点为主节点时,哨兵会通过sentinel is-masterdown-by-addr命令获取到其他哨兵对主节点状态的反馈,如果超过 quorum 台哨兵都认为宕机,则转了客观宕机(odown),然后会进行选举切换操作。
二、选Leader Sentinel原理
当第一个哨兵发现主节点异常时,会向其他的哨兵发is-masterdown-by-addr命令来获取反馈,并建议自己成了leader sentinel来进行故障切换操作。每人上哨兵都有资格成为leader。
其他哨兵收到命令时同意或则拒绝申请升级的哨兵。当有超过一半+1的哨兵同意,那么申请者将升级为leader sentinel。这里使用的是Raft算法主要思想是同一期Term(Epoch)投票中少数服从多数原则达成一致,选出Leader
https://www.jianshu.com/p/8e4bbe7e276c
三、故障转移机制
1.对从节点进行评估,先出一个从节点升级为主节点。
算法:
1.1跟master断开连接的时长,如果一个slave跟master断开连接已经超过了down-after-milliseconds的10倍,外加master宕机的时长,那么slave就被认为不适合选举为master
1.2slave优先级(配置文件中的 slave priority越低,优先级就越高)
1.3 复制offset越靠后(同步数据越多),优先级越高
1.4 run id 如果上面两个条件都相同,那么选择一个run id比较小的那个slave
2.将从节点升级为主节点,并修改配置信息。
3.将所有的从节点的master信息修改为新的主节点信息。
4.将老的主节点设置成为一个从节点。如果恢复则复制主节点信息。
5.将新的主节点信息生成,并发布到通道中,让其他订阅的哨兵知道最新主节点的信息(这里有一个变更配置version的概念,其他哨兵只会更新比自己高版本的配信息到本地,保证所用哨兵的配置信息统一)。
6.告知客户端主节点变更。让客户端重新连接到新的主节点上。
四、实战配置:
https://blog.csdn.net/zbw18297786698/article/details/52891695
https://blog.csdn.net/J080624/article/details/86370718
五:重要参数解释:
sentinel
monitor name hostname port quorum
down-after-milliseconds:
超过多少毫秒跟一个redis实例断了连接,哨兵就可能认为这个redis实例挂了
parallel-syncs:
新的master别切换之后,同时有多少个slave被切换到去连接新master,重新做同步,数字越低,花费的时间越多
假设你的redis是1个master,4个slave,然后master宕机了,4个slave中有1个切换成了master,剩下3个slave就要挂到新的master上面去
这个时候,如果parallel-syncs是1,那么3个slave,一个一个地挂接到新的master上面去,1个挂接完,而且从新的master sync完数据之后,再挂接下一个
如果parallel-syncs是3,那么一次性就会把所有slave挂接到新的master上去
failover-timeout:
执行故障转移的timeout超时时长