摘要
以前优化器的学习率总是设置为恒定不变的,现在想让优化器学习率随着epoch进行改变。本文使用Torch框架和Paddle框架对优化器的学习率进行更新。
1. Torch优化器的学习率更新
建立一个简单的模型
import torch
model = torch.nn.Conv2d(3,3,1)
optim = torch.optim.Adam(model.parameters(),lr=1e-2)
optim.param_groups[0]["lr"] # 可以看到当前优化器的学习率
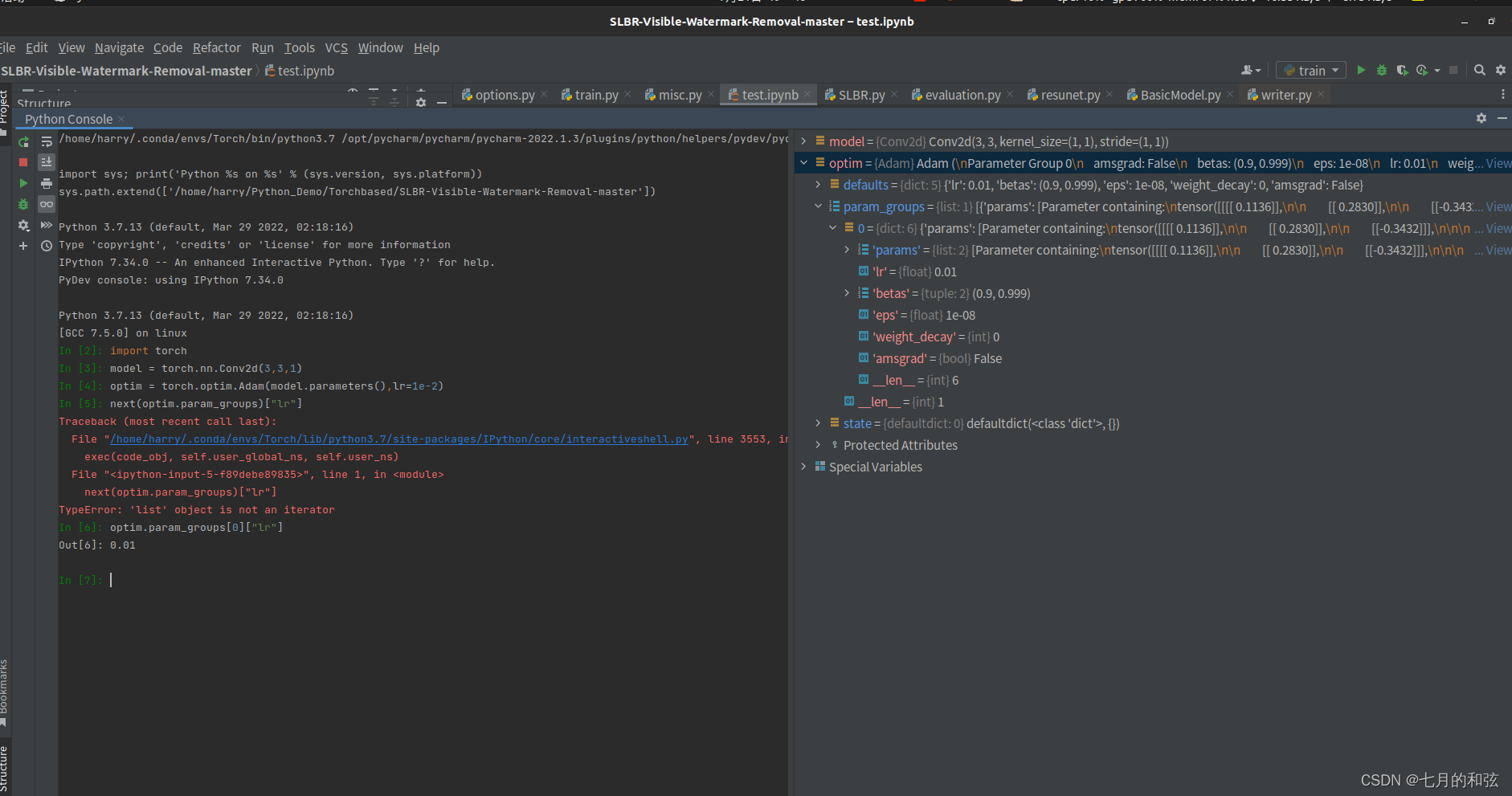
对模型设置Adam优化器,默认学习率为1e-2。现在想让学习率在训练的时候,进行改变。那么可以借助,
torch.optim.lr_scheduler
来实现
# 对上边的优化器创建优化策略,每2个epoch进行更新一次,缩放因子为0.1
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=2, gamma=0.1, last_epoch=-1)
for epoch in range(10):
scheduler.step(epoch)
print("Epoch : {}/{} | lr : {}".format(epoch+1,10,optim.param_groups[0]["lr"]))
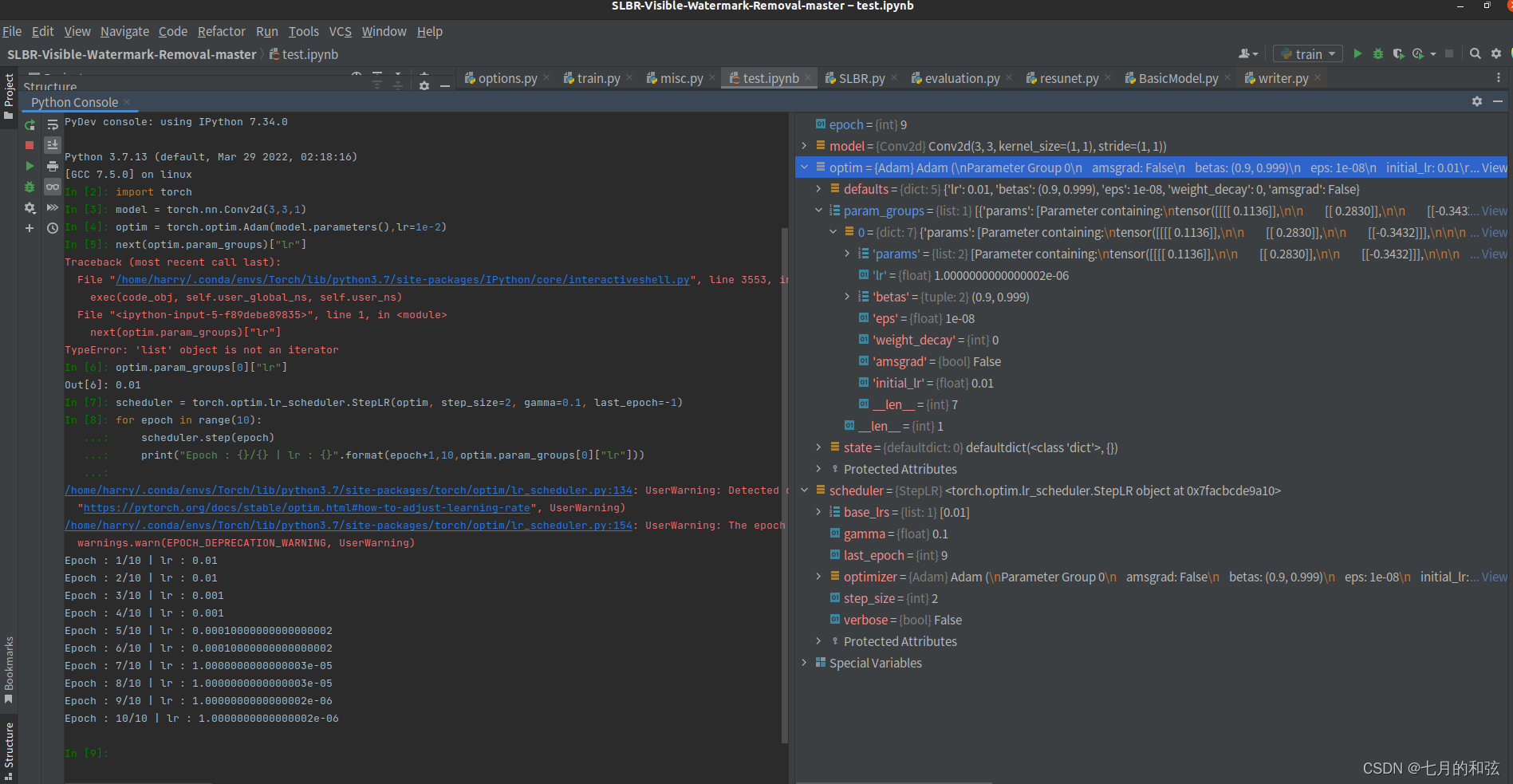
可以观察到,每2个epoch,学习率按缩放因子进行一次改变。
2. Paddle优化器学习率更新
目标是实现与Torch相同的功能
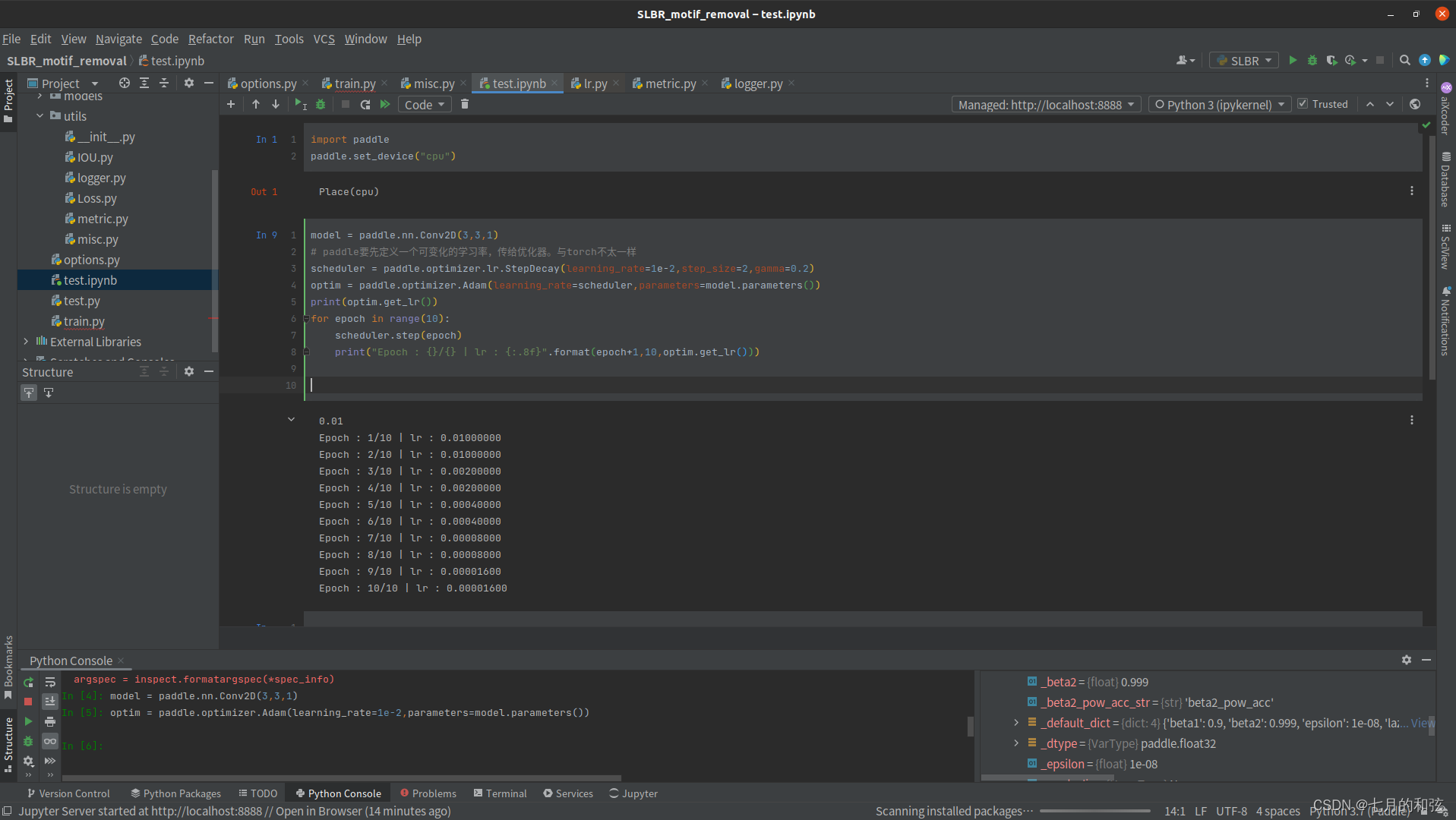
import paddle
paddle.set_device("cpu")
model = paddle.nn.Conv2D(3,3,1)
# paddle要先定义一个可变化的学习率,传给优化器。与torch不太一样
scheduler = paddle.optimizer.lr.StepDecay(learning_rate=1e-2,step_size=2,gamma=0.2)
optim = paddle.optimizer.Adam(learning_rate=scheduler,parameters=model.parameters())
print(optim.get_lr())
for epoch in range(10):
scheduler.step(epoch)
print("Epoch : {}/{} | lr : {:.8f}".format(epoch+1,10,optim.get_lr()))
参考资料
版权声明:本文为qq_44009107原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。