python爬虫模板
首先我们先把网页内容保存下来,之后我们对网页内容进行分析,找到我们想要的,以小米商城官网为例
import urllib3
#首先我们先把网页内容保存下来,之后我们对网页内容进行分析,找到我们想要的
def download_content(url):
res = urllib3.PoolManager().request(‘GET’, url).data.decode()
return res
def save_to_file(filename, content):
file = open(filename, ‘w’, encoding=‘utf-8’)
file.write(content)
file.close()
url = ‘https://www.mi.com/’
res = download_content(url)
save_to_file(‘tips1.html’, res)
import urllib3
#首先我们先把网页内容保存下来,之后我们对网页内容进行分析,找到我们想要的
def download_content(url):
res = urllib3.PoolManager().request('GET', url).data.decode()
return res
def save_to_file(filename, content):
file = open(filename, 'w', encoding='utf-8')
file.write(content)
file.close()
url = 'https://www.mi.com/'
res = download_content(url)
save_to_file('tips1.html', res)
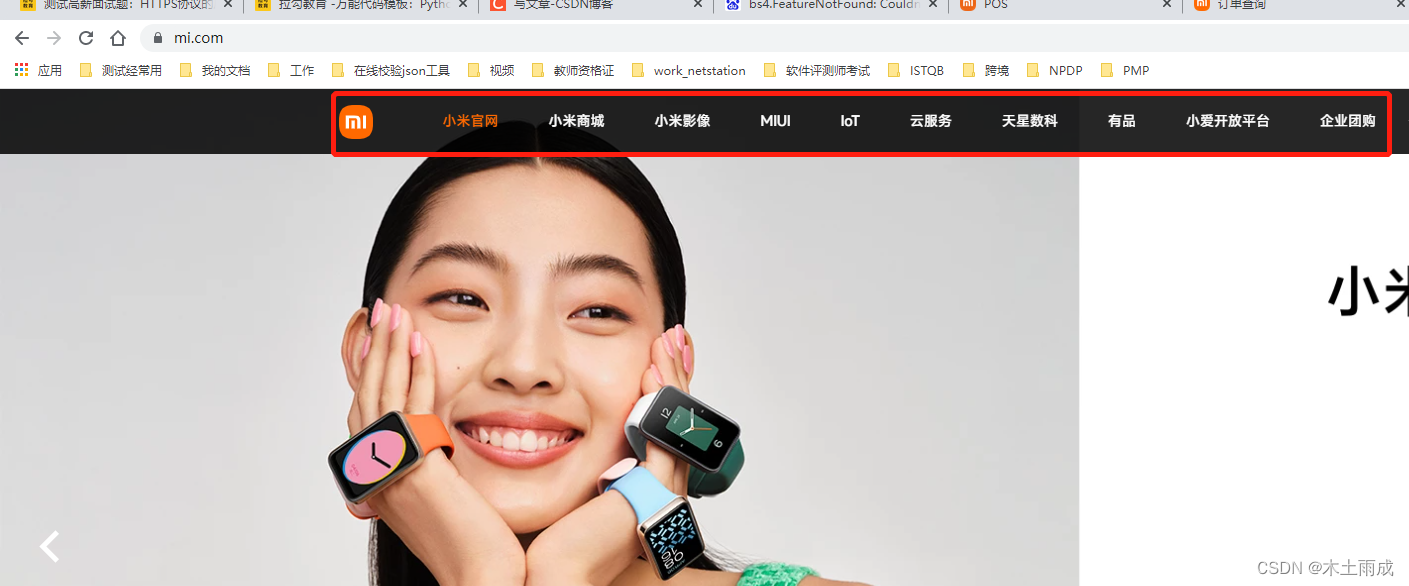
如图我们将对应的文件保存下来,命名为tips1.html,假设我们要爬取的内容为首页红框中的文字和链接,假设我们只要第二个小米影像
代码如下
import bs4
# 输入参数为要分析的 html 文件名,返回值为对应的 BeautifulSoup 对象
def create_doc_from_filename(filename):
fo = open(filename, "r", encoding='utf-8')
html_content = fo.read()
fo.close()
doc = bs4.BeautifulSoup(html_content, "lxml")
return doc
def parse(doc):
post_list = doc.find_all("div", class_="home-page")
for post in post_list:
link = post.find_all("a")[2]
print(link)
print(link.text.strip())
print(link["href"])
def main():
doc = create_doc_from_filename("tips1.html")
#print(doc)
parse(doc)
if __name__ == '__main__':
main()
运行之后发现正是我们想要的

在这里doc.find_all(“div”, class_=“home-page”)的含义就是首先找到所有 class 属性是 home-page的 div 标签,然后将这些标签中的 a 标签的文本部分提取出来
两个代码块是两个文件,第二个文件的html文件是从第一个文件获取的,当然我们也可以写在一起,这也是没有问题的,我个人的目录如下,比较随意
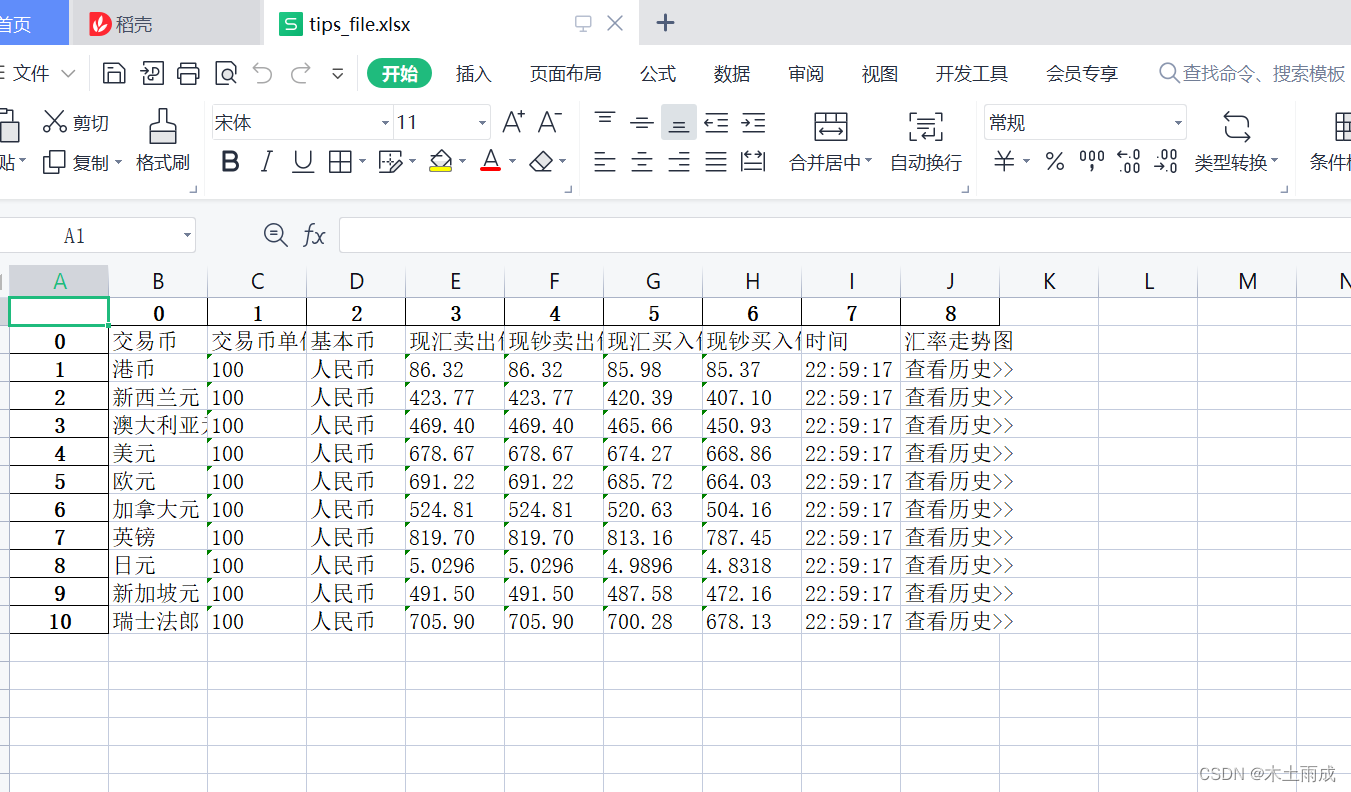
python网页表格生成表格文件
研究了下别人的例子,发现只有是table标签才能够很快转换,而且整个数据都需要table标签里面
比如这个地址:https://fx.cmbchina.com/Hq/
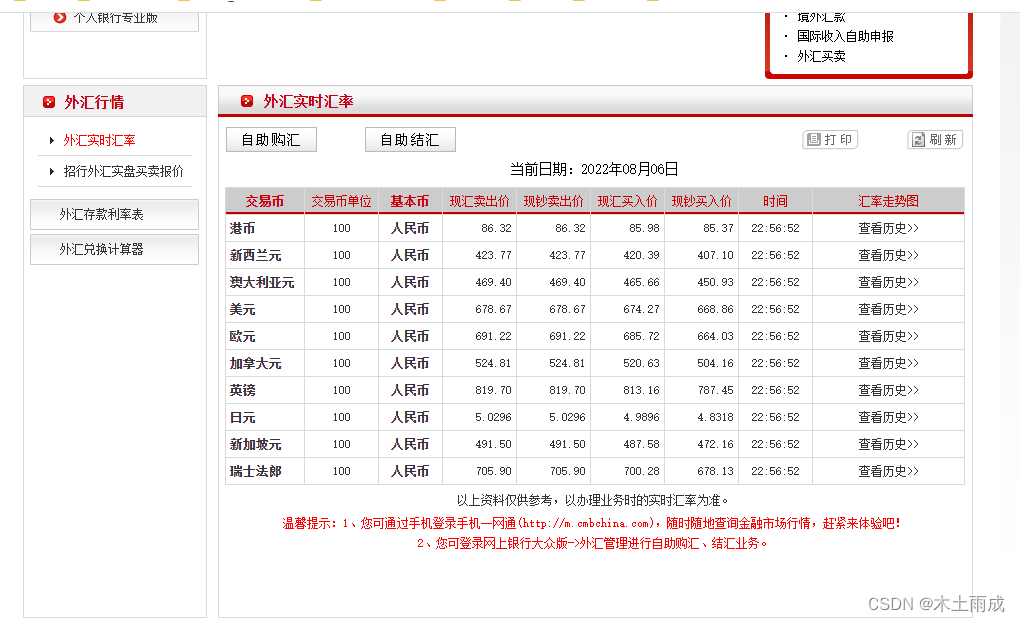
标签形式如下
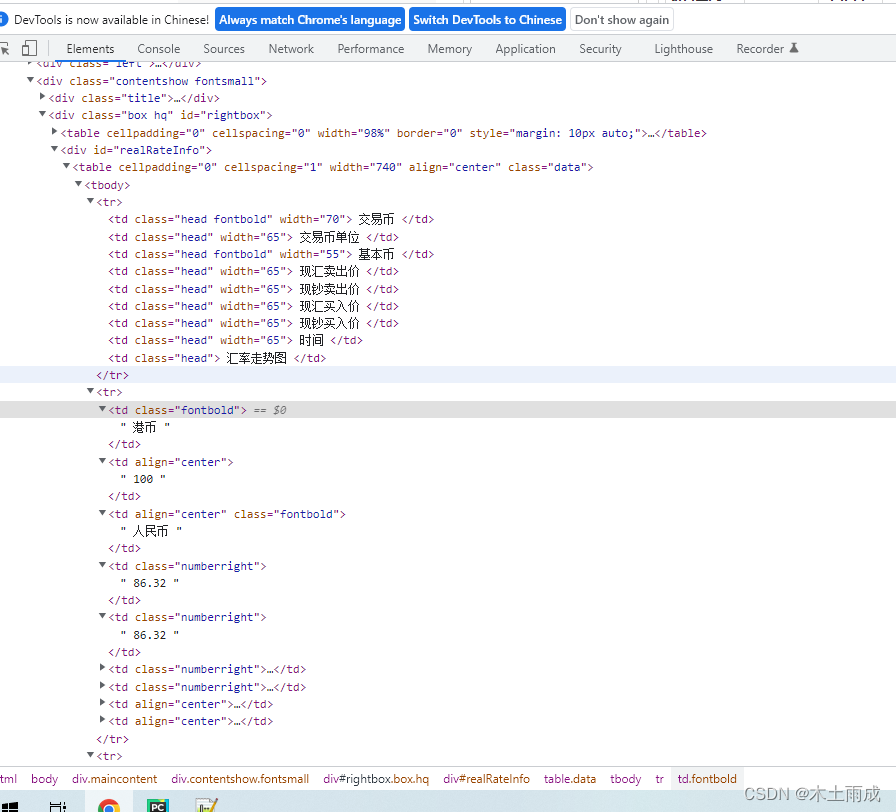
直接上代码吧
import urllib3
import pandas as pd
#首先我们先把网页内容保存下来,之后我们对网页内容进行分析,找到我们想要的
def download_content(url):
res = urllib3.PoolManager().request('GET', url).data.decode()
return res
res = download_content('https://fx.cmbchina.com/Hq/')
print(res)
file = pd.read_html(res)
print('---------')
print(file)
file[1].to_excel('tips_file.xlsx')
不过在这个过程中会报好几个库不存在,直接pip安装就可以了
执行后生成结果如下