使用yolov3-tiny训练VOC数据集
前言
最近由于要做一个课程的课设,想着用yolov3-tiny来玩一玩,然后上网看了看,yolov3版本的训练教程倒是一大堆,但是tiny版本的非常少,虽然大部分情况下两者都是差不多的,不过还是存在一些小差别,然后这里想着写篇博客记录一下。
训练
数据预处理
因为我们是使用的VOC数据集,所以省去了不少麻烦,不用自己标注数据做数据清洗什么的了,不过如果是要使用自己的数据的话,可以用
lableme
或者
labelimg
进行标注。
下载VOC数据集
非官方:https://pjreddie.com/projects/pascal-voc-dataset-mirror/
官方: http://host.robots.ox.ac.uk/pascal/VOC/
下载下来的是一个tar包,解压之后得到一个VOCdevkit文件夹

Annotations : 放的是图片的标注文件
ImageSets : 训练、验证数据的一些信息
JPEGImages : 所有的图片信息
其余两个文件夹是用来做图片分割的,这里可以不用管
生成训练数据集以及验证数据集
因为默认的VOC的训练与验证的比例大概是一个1:1的样子,这里可以自己使用下面代码重新生成一下,为了方便可以先把ImageSets下全部清空,然后创建
Main
和
Layout
两个文件夹

再使用下面这段代码(创建一个convert_to_text.py然后在VOC2012目录下运行)生成训练数据集以及验证数据集,会生成4个文件
trainval.txt(验证集)、train.txt(训练集)、test.txt、val.txt
import os
import random
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行结束后会发现Main文件下多了4个文件。
下载并编译DarkNet
YOLOV3的主页:https://pjreddie.com/darknet/yolo/
git clone https://github.com/pjreddie/darknet // 从github上下载项目
编译源码
如果要使用GPU进行训练(CPU不用修改),需要修改Makefile文件,如下:
GPU=1 # 前面三行设为1
CUDNN=1
OPENCV=1
OPENMP=0
DEBUG=0
ARCH= -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52]
# -gencode arch=compute_20,code=[sm_20,sm_21] \ This one is deprecated?
# This is what I use, uncomment if you know your arch and want to specify
# ARCH= -gencode arch=compute_52,code=compute_52
VPATH=./src/:./examples
SLIB=libdarknet.so
ALIB=libdarknet.a
EXEC=darknet
OBJDIR=./obj/
CC=gcc
CPP=g++
NVCC=/usr/local/cuda-10.0/bin/nvcc # 修改成自己的cuda路径
AR=ar
ARFLAGS=rcs
OPTS=-Ofast
LDFLAGS= -lm -pthread
COMMON= -Iinclude/ -Isrc/
CFLAGS=-Wall -Wno-unused-result -Wno-unknown-pragmas -Wfatal-errors -fPIC
ifeq ($(OPENMP), 1)
CFLAGS+= -fopenmp
endif
ifeq ($(DEBUG), 1)
OPTS=-O0 -g
endif
CFLAGS+=$(OPTS)
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV
LDFLAGS+= `pkg-config --libs opencv` -lstdc++
COMMON+= `pkg-config --cflags opencv`
endif
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda-10.0/include # 这里也是修改为自己的cuda路径
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda-10.0/lib64 -lcuda -lcudart -lcublas -lcurand
endif
ifeq ($(CUDNN), 1)
COMMON+= -DCUDNN
CFLAGS+= -DCUDNN
LDFLAGS+= -lcudnn
endif
OBJ=gemm.o utils.o cuda.o deconvolutional_layer.o convolutional_layer.o list.o image.o activations.o im2col.o col2im.o blas.o crop_layer.o dropout_layer.o maxpool_layer.o softmax_layer.o data.o matrix.o network.o connected_layer.o cost_layer.o parser.o option_list.o detection_layer.o route_layer.o upsample_layer.o box.o normalization_layer.o avgpool_layer.o layer.o local_layer.o shortcut_layer.o logistic_layer.o activation_layer.o rnn_layer.o gru_layer.o crnn_layer.o demo.o batchnorm_layer.o region_layer.o reorg_layer.o tree.o lstm_layer.o l2norm_layer.o yolo_layer.o iseg_layer.o image_opencv.o
EXECOBJA=captcha.o lsd.o super.o art.o tag.o cifar.o go.o rnn.o segmenter.o regressor.o classifier.o coco.o yolo.o detector.o nightmare.o instance-segmenter.o darknet.o
ifeq ($(GPU), 1)
LDFLAGS+= -lstdc++
OBJ+=convolutional_kernels.o deconvolutional_kernels.o activation_kernels.o im2col_kernels.o col2im_kernels.o blas_kernels.o crop_layer_kernels.o dropout_layer_kernels.o maxpool_layer_kernels.o avgpool_layer_kernels.o
endif
EXECOBJ = $(addprefix $(OBJDIR), $(EXECOBJA))
OBJS = $(addprefix $(OBJDIR), $(OBJ))
DEPS = $(wildcard src/*.h) Makefile include/darknet.h
all: obj backup results $(SLIB) $(ALIB) $(EXEC)
#all: obj results $(SLIB) $(ALIB) $(EXEC)
$(EXEC): $(EXECOBJ) $(ALIB)
$(CC) $(COMMON) $(CFLAGS) $^ -o $@ $(LDFLAGS) $(ALIB)
$(ALIB): $(OBJS)
$(AR) $(ARFLAGS) $@ $^
$(SLIB): $(OBJS)
$(CC) $(CFLAGS) -shared $^ -o $@ $(LDFLAGS)
$(OBJDIR)%.o: %.cpp $(DEPS)
$(CPP) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.c $(DEPS)
$(CC) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.cu $(DEPS)
$(NVCC) $(ARCH) $(COMMON) --compiler-options "$(CFLAGS)" -c $< -o $@
obj:
mkdir -p obj
backup:
mkdir -p backup
results:
mkdir -p results
.PHONY: clean
clean:
rm -rf $(OBJS) $(SLIB) $(ALIB) $(EXEC) $(EXECOBJ) $(OBJDIR)/*
然后在darknet目录下执行
make
命令
make
然后把我们之前下载下来的
VOC数据移动到darknet的scripts目录下

修改voc_label.py文件
主要修改以下两处:

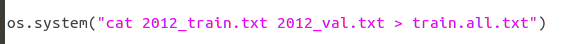
sets
:这里与之前的VOCdevlit目录下的 VOC[Year]对应,例如VOC2012则只保留2012的即可
classes
:数据集的类别,根据你自己的情况修改。
文件最下面也根据你修改的sets进行相应的修改。
运行voc_label.py
python voc_label.py
发现label文件夹下生成了yolo所需要的所有图片的标签信息,内容格式如下

第一列表示编号,后面分别表示 x,y,w,h的值,用来描述bbox
并且VOCdevkit同级目录下也生成了如下几个文件,就是前面所说的
文件内容是每张图片的
绝对路径
。
还需要修改cfg目录下的
voc.data
文件,如下:

classes就是你的类别数量,train和valid分别是你通过voc_label生成的那两个带年份标签的文件
names就是darknet的data目录下voc.names的路径,里面放的是类别名,根据情况自行修改。
修改配置文件
打开cfg目录下的yolov3-tiny.cfg文件进行修改,如下
[net]
# Testing #这里分为test和train两种不同的情况
# batch=1
# subdivisions=1
# Training
batch=64 # 这里如果显存小的话就适当改小一点,但是 batch与subdivision的值不能相同,否则会出现无法收敛的情况
subdivisions=8
width=416 #输入图片的尺寸
height=416
channels=3
momentum=0.9 ### 动量
decay=0.0005 ### 权重衰减
angle=0
saturation = 1.5 ### 饱和度
exposure = 1.5 ### 曝光度
hue=.1 ### 色调
learning_rate=0.001 ### 学习率
burn_in=1000 ### 学习率控制的参数
max_batches = 10000 ### 迭代次数 ##注意## 这里训练次数一般填10000到50000次
policy=steps ### 学习率策略
steps=400000,450000 ### 学习率变动步长
scales=.1,.1 ### 学习率变动因子
# ============第一层============ 208*208*16
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
# ============================
# ============第二层============ 104*104*32
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
# ============第三层============ 52*52*64
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
# ============第四层============ 26*26*128
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
# ============第五层============
# 取这里的结果作为第一个尺度与后续进行拼接,取的是 MaxPool之前的结果 26*26*256
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
# ============第六层============ 13 * 13 * 512
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
# ============第七层============ 11*11*1024
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
###########
# ===========第八层============ 13*13*256
# 取这里的结果作为第二个尺度输出
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
# ===========第九层========== 13*13*512
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
# ==========最后一层========= 13*13*75
[convolutional]
size=1
stride=1
pad=1
filters=75 # 这里的filter修改成 (5+classes)* 3
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=20 # 修改成你自己的class数量
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1 # 这里如果显存小的话改为0,关闭多尺度训练
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 8
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=75 # 这里的filter修改成 (5+classes)* 3
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=20 # 修改成你自己的class数量
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1 # 这里如果显存小的话改为0,关闭多尺度训练
下载yolov3-tiny的权重文件
wget https://pjreddie.com/media/files/yolov3_tiny.weights
对于进行特征提取的网络,官方没有明确使用多少层,一般都是使用前面15层。通过以下命令
提取前15层作为特征提取
。
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
开始训练
./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15
训练过程如下:

参数含义:
- Region xx: cfg文件中yolo-layer的索引;
- Avg IOU:当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
- Class: 标注物体的分类准确率,越大越好,期望数值为1;
- obj: 越大越好,期望数值为1;
- No obj: 越小越好;
- .5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
- 0.75R: 以IOU=0.75为阈值时候的recall;
- count:正样本数目。
多GPU训练:
./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15 -gpus 0,1,2,3
断点训练:
./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg backup/yolov3-tiny.backup -gpus 0,1,2,3
验证训练结果
这里是借鉴自这位大佬https://blog.csdn.net/xiao_lxl/article/details/85047103的文章,然后根据自己的情况在一些地方进行了修改。
计算recall
这里和前面那位博主基本上是一样的,这里再给个传送门https://blog.csdn.net/xiao_lxl/article/details/85047103
- 修改validate_detector_recall()函数的定义
//void validate_detector_recall(char *cfgfile, char *weightfile)
void validate_detector_recall(char *datacfg, char *cfgfile, char *weightfile)
- 修改validate_detector_recall()函数的调用
//else if(0==strcmp(argv[2], "recall")) validate_detector_recall(cfg, weights);
else if(0==strcmp(argv[2], "recall")) validate_detector_recall(datacfg,cfg, weights);
- 替换list *plist = get_paths(“data/coco_val_5k.list”);为list *plist=get_paths(“voc/train.txt”);自己的训练集文本
//list *plist = get_paths("data/coco_val_5k.list");
//char **paths = (char **)list_to_array(plist); #改成自己的路径,就是前面生成的2012_val.txt
- 修改for循环中的nboxes
//for(k = 0; k < l.w*l.h*l.n; ++k){
for(k = 0; k < nboxes; ++k){
修改完成之后还需要重新编译make
注意:需要还原成没有make之前的环境,即需要删除一些编译之后产生的文件,否则会编译失败!
编译之前的文件目录如下:

删除编译之后产生的文件!
计算recall以及IOU
./darknet detector recall cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup
结果如下

计算mAP
对验证集下的图片数据进行验证并输出结果(默认输出至darknet下的results目录)
./darknet detector valid cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup -out ""
out后面接的是说明,为空即可。执行后,得到如下结果:

用类别名作为文件名,后续方便计算mAP。
为了计算mAP,需要使用py-faster-rcnn下的voc_eval.py
官方代码在这里:https://github.com/rbgirshick/py-faster-rcnn/blob/master/lib/datasets/voc_eval.py
py-faster-rcnn中的voc_eval.py解读:
https://blog.csdn.net/qq_34806812/article/details/82018072
我根据情况在一些地方做了修改:
import xml.etree.ElementTree as ET
import os
# import cPickle python2版本的
import _pickle as cPickle # python3使用这个
import numpy as np
def parse_rec(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
# obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['truncated'] = 0 # 这里发现2012之后标注的数据中,有些没有truncated标签,由于这个标签对于我们影响不大,默认全部设为0即可
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
cachefile = os.path.join(cachedir, 'annots.pkl')
# read list of images
lines = []
with open(imagesetfile, 'r') as f:
for line in f:
lines.append(line[70:81])
imagenames = [x.strip() for x in lines]
if not os.path.isfile(cachefile):
# load annots
recs = {}
for i, imagename in enumerate(imagenames):
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
print('Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames)))
# save
print('Saving cached annotations to {:s}'.format(cachefile))
with open(cachefile, 'wb') as f: # 读取二进制文件,这里需要改为 ’wb‘
cPickle.dump(recs, f)
else:
# load
with open(cachefile, 'rb') as f: # 这里也一样修改为 ’rb‘
recs = cPickle.load(f)
# extract gt objects for this class
class_recs = {}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
# sort by confidence
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
# BB = BB[sorted_ind, :]
BB = BB[sorted_ind] # 这里去掉第二个维度索引
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
新建compute_mAP.py
from voc_eval import voc_eval
import os
current_path = os.getcwd()
results_path = current_path+"/results"
f = open("./data/voc.names")
mAP = []
for line in f:
class_name = line.split(".txt")[0]
class_name = class_name.replace('\n', '')
rec, prec, ap = voc_eval('自己的路径/darknet/results/{}.txt', '自己的路径/darknet/scripts/VOCdevkit/VOC2012/Annotations/{}.xml', '自己的路径/darknet/scripts/data/2012_val.txt', class_name, '自己的路径/darknet/scripts/VOCdevkit/VOC2012/mAP')
print("{} :\t {} ".format(class_name, ap))
mAP.append(ap)
mAP = tuple(mAP)
print("***************************")
print("mAP :\t {}".format(float(sum(mAP)/len(mAP))))
现在基本差不多了,运行compute_mAP.py
python compute_mAP.py
结果如下:

总结
基本的训练以及验证流程就是这样,然后后续还需要进行参数调优以及一些模型修改,到时候有时间再写一写。还有很多需要学习借鉴的地方,哪里写错了,希望大神们轻喷。