气象家园投稿第四篇:编写程序
说起编程,平时我们都是写什么样的程序呢?算个平均、求个趋势,再检验下显著性?或者进行小波分析、EOF 分析?不知道大家的选择如何,反正我平时大多是靠 Matlab 来完成的,感觉二爷教的东西更有用啊喂!当然也有需要用到 Fortran 进行计算的,但谁会跑到 Linux 上写代码啊,在 Windows 下方便多了嘛!
不过呢,气象上用到的很多模式都需要在 Linux 的环境下运行,了解一些基本的 Linux 编程还是很有用的。模式的使用并不需要有很深的计算机知识,通常按照说明敲几行命令,说不定就 run 起来了。不过很多情况下还需要根据你的系统环境进行配置,有时甚至出现莫名其妙的问题而运行不了,这时候若是能对 Linux 编程略知一二,可能就帮了你的大忙了。这一期我会介绍一些有关 Linux 编程的基本知识,也稍微提一下 Makefile,但更多的内容还需要自己深入学习,相信大家不用多久就能成为模式小能手呢!那么第一步就从 hello world 开始吧!
开始编译吧!
在 Linux 下,我们用 vi 照样写代码,但写好的代码如何编译呢?Windwos 下只需要一个按钮就行,Linux 下可以用一行命令来实现。hello world 的代码我就不贴了,但编译命令是这样的:
1[N@Dell hello]$ ifort -o hello hello.f90
这里我的 Linux 装的是 Intel 的 Fortran 编译器,如果你想在你的 Linux 上编译 hello.f90,得看看你那的 Fortran 编译器是啥,然后把这里的 ifort 改成你的编译器的名称就行了。-o hello 会指定可执行文件名为 hello,你也可以改成 -o myhello”,而后面跟的hello.f90则是将要编译的源码文件。若是不指定-o,写成“ifort hello.f90,就会得到名为 a.out 的可执行文件。或许你的编译器是 gfortran?那就输入:
1[N@Dell hello]$ gfortran -o hello hello.f90
除了 -o 选项,还有 -O、-O2、-O3,这些“杠大欧”们会对你的程序进行优化,貌似很多数值模式都考虑把它给加上,以提高运算效率。还有更多的参数,若是需要用到就 man 一下吧。如果你没有 Fortran 编译器(很有可能是这样),那么你可以去 Intel 官网下一个,他们有提供教育版的,安装过程也很方便。对了,我记得气象家园上有分享过来着。
加入函数库
为什么需要加入函数库呢?简而言之,外部函数库的功能就是帮助你完成一些 Fortran 本身无法完成的工作,比如读写 nc 文件、进行并行计算等等。通常下载安装完一个函数库以后,会得到一些库文件和头文件分别存放在 lib 和 include 文件夹下,以 netcdf 库(读写 nc 文件的库)为例:
1
2
3
4
5
6
7
8
9
10[N@Dell ~]$ ls /opt/netcdf/netcdf-latest/lib/
libnetcdf.a libnetcdff.so libnetcdf.la libnetcdf.so.11
libnetcdff.a libnetcdff.so.6 libnetcdf.settings libnetcdf.so.11.0.0
libnetcdff.la libnetcdff.so.6.0.1 libnetcdf.so pkgconfig
[N@Dell ~]$ ls /opt/netcdf/netcdf-latest/include/
netcdf4_f03.mod netcdf.h netcdf_nc_data.mod
netcdf4_nc_interfaces.mod netcdf.inc netcdf_nc_interfaces.mod
netcdf4_nf_interfaces.mod netcdf_mem.h netcdf_nf_data.mod
netcdf_f03.mod netcdf_meta.h netcdf_nf_interfaces.mod
netcdf_fortv2_c_interfaces.mod netcdf.mod typesizes.mod
那么如何使用 netcdf 库呢?首先需要在源代码里面 use netcdf,然后调用 netcdf 库函数进行读取。而在编译的时候则需要把库的名称和路径告诉编译器,即编译时加上几个参数。这里提供一个示例程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29program main
use netcdf
implicit none
character(50) :: ncfile
integer :: fid, varid, stat, year, recnum, start_num
integer :: i
real(kind=8), dimension(200) :: ice
real(kind=8), dimension(180) :: lat
real(kind=8), dimension(360) :: lon
!初始化
ncfile=’HadISST_ice.nc’
year=1979
recnum=12
start_num=(year-1870)*12+1
!打开文件,读取数据
stat=nf90_open(ncfile, NF90_NOWRITE, fid)
stat=nf90_inq_varid(fid, ‘sic’, varid)
stat=nf90_get_var(fid, varid, ice, start=(/180,10,start_num/), count=(/1,1,recnum/))
stat=nf90_inq_varid(fid, ‘latitude’, varid)
stat=nf90_get_var(fid, varid, lat)
stat=nf90_inq_varid(fid, ‘longitude’, varid)
stat=nf90_get_var(fid, varid, lon)
stat=nf90_close(fid)
!输出到屏幕
write(*,*)’ lat= ‘, lat(10), ‘ lon= ‘, lon(180)
do i=1,recnum
write(*,*)ice(i)
enddo
end program main
源码就不作过多说明了,我们来看看编译命令及运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[N@Dell readnc]$ ifort -o readnc readnc.f90 -lnetcdff -I/opt/netcdf/netcdf-latest/include -L/opt/netcdf/netcdf-latest/lib
[N@Dell readnc]$ ./readnc
lat= 80.5000000000000 lon= -0.500000000000000
0.920000016689301
0.959999978542328
0.850000023841858
0.959999978542328
0.870000004768372
0.910000026226044
0.680000007152557
0.589999973773956
0.259999990463257
0.560000002384186
0.720000028610229
0.750000000000000
编译的命令和之前相比多了三项。-lnetcdff 可以看成是 -l 和 netcdff 连在一起,其中的 -l 是 lib 的意思,netcdff 为库名,表示你将用到的库文件名为 libnetcdff.so 或 libnetcdff.a。库文件的位置由 -L 后的路径给出,头文件则从 -I 后的路径里去找。使用其他库时,也是类似地加上 -lxxx -Ixxx -Lxxx,然后就能正确调用外部函数了。当然,你可以加上多个 -l、-I 以及 -L。也许你也想读个 nc 文件试试,却发现没有 netcdf 库?等下载好了却装不成功?那就百度一下吧,或者参考下一期的内容。
.so / .a / .o文件
有人可能会问了,xxx.so 文件和 xxx.a 文件有啥区别啊,其实前者是动态函数库,而后者是静态函数库。两者的区别之一在于,是否需要从库文件中读取函数信息。对于静态函数库,它在编译的时候就直接整合到可执行文件中了,程序可以独立运行的,不需要再读 xxx.a 的内容。若是使用了动态函数库,可执行文件运行时还得去 xxx.so 里面读取函数。形象点描述的话,静态函数库是揣兜里的,随时可以使用,而动态函数是人家的,要用的时候还得找人家拿来看看。
也许你就要问了,前面使用 netcdf 库编译时加的是 -lnetcdff,可我们并不知道它到底用的 libnetcdff.so 还是 libnetcdff.a 啊?要知道,在 /opt/netcdf/netcdf-latest/lib 目录下,这两个文件可都是存在的!实际上我们可以不使用 -l 和 -L 的组合,而是这样写:
1
2[N@Dell readnc]$ ifort -o readnc readnc.f90 /opt/netcdf/netcdf-latest/lib/libnetcdff.so -I/opt/netcdf/netcdf-latest/include
[N@Dell readnc]$ ifort -o readnc readnc.f90 /opt/netcdf/netcdf-latest/lib/libnetcdff.a -I/opt/netcdf/netcdf-latest/include > ifort.log 2>&1
可以看到使用 libnetcdff.so 时,编译没有问题。而使用 libnetcdff.a 时则会出错,这里我将标准输出和标准错误输出都重定向了,不了解重定向没有关系,总之就是我把编译错误的信息放到 ifort.log 文件里了。当然我们不用查看 ifort.log,只需知道使用 libnetcdff.a 时确实出错了,也说明之前采用 -l 与 -L 组合时,实际是用了 libnetcdff.so 文件。至于为什么不能用静态库编译呢?大概是还需要其他函数库,而 libnetcdff.so 里有它们的信息但 libnetcdff.a 里面却没有吧。
那么我们来看另一个有关动态库的问题。还是以 netcdf 库为例,之前我们能够正常编译运行,但现在我把 .bashrc 文件里的某行注释掉(图中 netcdf 部分的 export LD_LIBRARY_PATH=… 那行):
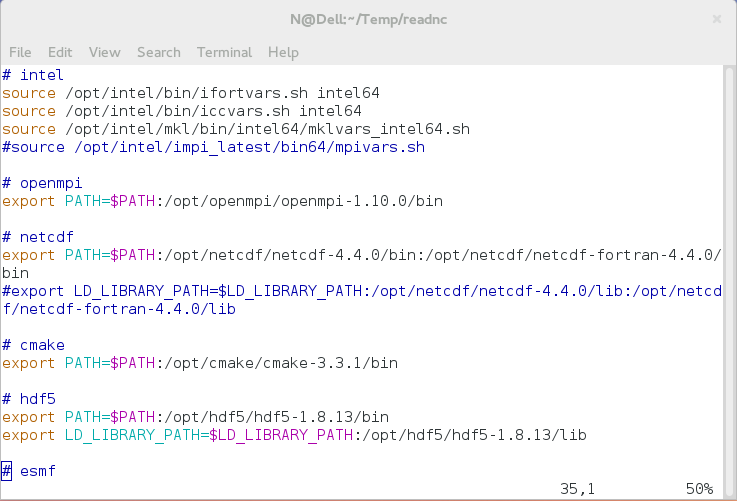
那么当我重新登录的时候,就会显示这样的结果:
1
2
3[N@Dell readnc]$ ifort -o readnc readnc.f90 -lnetcdff -I/opt/netcdf/netcdf-latest/include -L/opt/netcdf/netcdf-latest/lib
[N@Dell readnc]$ ./readnc
./readnc: error while loading shared libraries: libnetcdff.so.6: cannot open shared object file: No such file or directory
为什么呢?编译没错,却不能运行?那是因为我们编译时用的动态库,运行时就得再次访问 libnetcdff.so 文件,而程序需要由 LD_LIBRARY_PATH 这个环境变量提供动态库文件所在的位置。这样就懂了吧?注释掉那行就意味着程序再也找不着 libnetcdff.so 了。
动态库和静态库有各自的优点,动态库用起来方便一点,静态库独立一些。前面说过用 libnetcdff.a 编译时,因为缺少其他函数库的信息失败了,而 libnetcdff.so 则含有那些函数库的信息,ldd libnetcdff.so 就能看到。另一方面,动态库升级后不需要重新编译可执行文件,而静态库升级后需要重新编译才能使用新函数。不过,使用静态库的好处在于,编译得到的程序可以独立执行,不再需要访问库文件了。
这里我再稍微介绍下怎样生成 .a 及 .so 文件。不过先要提一下 .o 文件,即目标文件,相信大家都见过。以 hello world 为例,如果编译命令这样写,就会生成 .o 文件:
1
2
3
4[N@Dell hello]$ ifort -c hello.f90
[N@Dell hello]$ ifort -o hello hello.o
[N@Dell hello]$ ls
hello hello.f90 hello.o
反而多敲了一行,为什么一定要生成 .o 文件呢?其实静态库就是将很多 .o 和在一起形成的,动态库也差不多,有了库文件就能多次使用而不用每次都编译了。那如何形成库文件呢?这里我用另一个程序来演示一下,和 hello world 不同,它有三个源码文件。先不管我这个程序是做什么用的,只看看我是如何编译的吧:
1
2
3
4
5
6
7
8
9
10[N@Dell test]$ ls
main.c main.h solve_x.c solve_x.h solve_y.c solve_y.h
[N@Dell test]$ mpicc -c solve_x.c
[N@Dell test]$ mpicc -c solve_y.c
[N@Dell test]$ ar -r libsolve.a solve_x.o solve_y.o
ar: creating libsolve.a
[N@Dell test]$ mpicc -o solve main.c libsolve.a
[N@Dell test]$ mpirun -n 2 ./solve
Proc 0: x=1.994085,ex=0.000035,step=11
Proc 1: y=1.999241,ey=0.000002,step=11
这个程序是用 c 语言写的,还用到了并行,因此编译器是 mpicc,且运行时需要写成 mpirun -n 2 ./solve,但它跟普通的串行程序看起来区别不大。可以看到我先编译了 solve_x.c 和 solve_y.c,得到目标文件后把它们合成一个 libsolve.a,建立了自己的一个函数库。然后编译 main.c 时直接就用这个静态库了,最后执行 solve。如果考虑制作动态函数库,可以这样:
1
2
3
4
5
6
7
8[N@Dell test]$ ls
main.c main.h solve_x.c solve_x.h solve_y.c solve_y.h
[N@Dell test]$ mpicc -fPIC -shared -o libsolve.so solve_x.c solve_y.c
[N@Dell test]$ mpicc -o solve main.c libsolve.so
[N@Dell test]$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:.
[N@Dell test]$ mpirun -n 2 ./solve
Proc 0: x=1.994085,ex=0.000035,step=11
Proc 1: y=1.999241,ey=0.000002,step=11
其过程和静态库生成差不太多,只是出现了 -fPIC 和 -shared 选项,同时还需要设置 LD_LIBRARY_PATH。相信大家百度一下 man 一下大致就懂,这里不再赘述。
如何调试?
Windows 下程序调试大家都会,编译器自带该功能。而 Linux 下可以用 GDB 来进行调试:
1
2[N@Dell readnc]$ ifort -g -o readnc readnc.f90 -lnetcdff -I/opt/netcdf/netcdf-latest/include -L/opt/netcdf/netcdf-latest/lib
[N@Dell readnc]$ gdb readnc
你会发现编译的时候多加了一个参数 -g,然后你才能用 gdb readnc 进行调试。说实话我平时在 Linux 下几乎不用 GDB,但也许你会需要它,所以这里还是列一下 GDB 的基本操作:
file [filename]:打开可执行文件 filename
info:查看相关信息,如 info breakpoints 查看所有断点
list:列出可执行文件对应的代码
break:设置断点,一般按源文件行号来设置,如 break 5
delete:按断点号删除断点
clear:按行号删除断点
run:运行可执行文件
continue:从断点处继续执行
next:单步执行
print:显示变量或表达式的值
whatis:查看变量类型
kill:终止正在调试的程序
quit:退出 GDB
大致就是这些,我就不演示了,用一用就熟悉啦!
Makefile
Makefile 是啥?为什么要使用它呢?想象一下你有个程序是由100个源文件编译链接而成,那我岂不是要敲很长的命令?若要重新编译,我还得再敲一遍?当然不是,我们可以把编译信息写到一个文件里,即 Makefile,然后敲入命令 make 就行了!而且当你改动了一些源码文件后再次编译时,make 还能够自动识别修改了哪些文件并只编译那些文件,这样可以节省不少时间。还是以 solve 程序为例来演示下 Makefile 的基本规则吧,我写的 Makefile 文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12CC = mpicc
solve: main.o solve_x.o solve_y.o
${CC} -o solve main.o solve_x.o solve_y.o
main.o: main.c
${CC} -c main.c
solve_x.o: solve_x.c
${CC} -c solve_x.c
solve_y.o: solve_y.c
${CC} -c solve_y.c
clean:
rm -f solve main.o solve_x.o solve_y.o
其中第一行为定义变量,这里我把编译器定为 mpicc,如果想换另一个编译器,只需要修改第一行。后面的内容则以这样的形式书写:
1
2target: object files
[tab] command
其中 target 为目标文件或标签,后面的 object files 为完成该 target 所需要用到的文件,两者以冒号隔开。第二行以 tab 键开头,后面紧跟完成该 target 的具体命令。这里共有5个 target,前四个分别生成 solve、main.o、solve_x.o、solve_y.o,最后一个是把这四个文件删除。如果你要执行某一条 target,可以敲入 make target,比如这样的操作:
1
2
3
4
5
6
7
8
9
10
11[N@Dell test]$ ls
libsolve.a main.c Makefile solve_x.h solve_y.h
libsolve.so main.h solve_x.c solve_y.c
[N@Dell test]$ make solve_x.o
mpicc -c solve_x.c
[N@Dell test]$ make solve
mpicc -c main.c
mpicc -c solve_y.c
mpicc -o solve main.o solve_x.o solve_y.o
[N@Dell test]$ make clean
rm -f solve main.o solve_x.o solve_y.o
当我们需要实现 solve_x.o 这个 target 的时候,它将 solve_x.c 编译成了 solve_x.o。实现 solve 这个 target 时,需要用到 main.o、solve_x.o、solve_y.o 三个文件,而 main.o 和 solve_y.o 并不存在,此时 make 就会先编译得到 main.o 与 solve_y.o,然后再得到 solve。如果你直接敲 make,那就会自动完成第一个目标。如果你要 make 的文件不叫 Makefile,而叫 MyMakefile,那就敲 make –f MyMakefile。
其实随便找一个模式看看,就发现它们基本都是采用 make(或者 gmake?)进行编译,因为源文件实在是太多了。不过模式的 Makefile 是很复杂的,我也看不太明白,但我知道它大致在干嘛,然后改一下关键的地方,嗯,编译通过啦!
结语
Linux 下写程序对于习惯了 Windows 的我们来说确实需要一段时间适应,适应了就一切都手到擒来。不过 Linux 编程的知识多了去了,我也有很多不懂的地方,真的是需要不断地学习啊!好了,这期就这样啦,我们下期见!