线程安全问题是多线程中的重点与难点。所谓线程安全就是在
CPU各种随机调度的顺序下,运行结果没有bug,能够符合预期的方式来执行。
如果在多线程调度下,代码出现了bug,此时就认为线程是不安全的。
下面先来演示一下
线程安全问题
:
使用多线程使一个
变量自增100000次
:
class Count{
public int counter=0;
public void increase(){
counter++;
}
}
public class Test {
private static Count count=new Count();
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
for(int i=0;i<50000;i++){
count.increase();
}
});
Thread t2=new Thread(()->{
for(int i=0;i<50000;i++){
count.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.print(count.counter);
}
}
运行三次的结果如下:
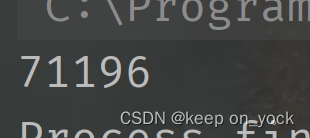
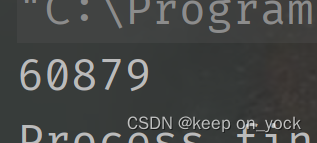
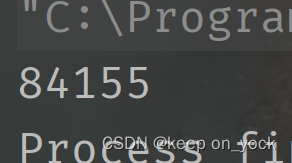
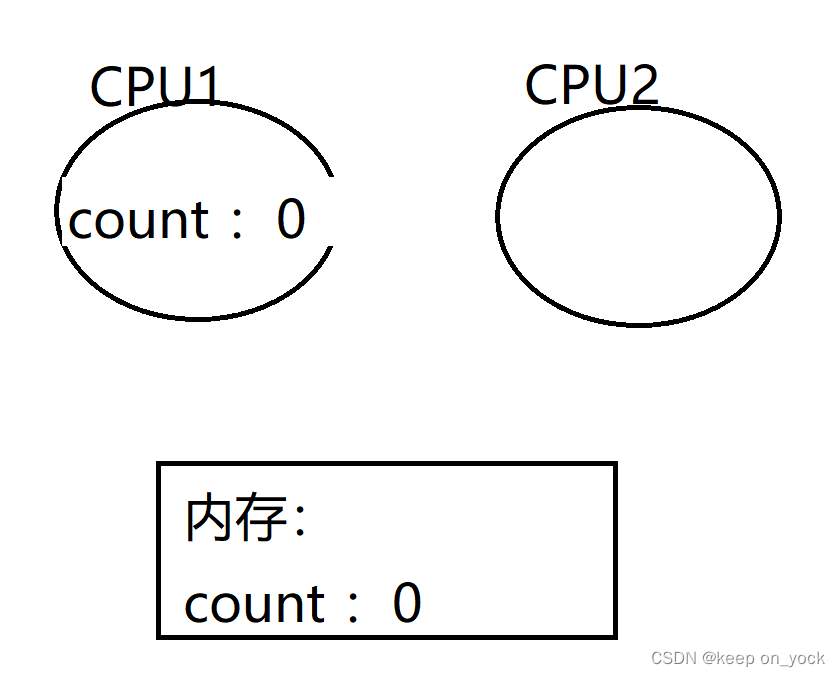
我们可以看到,运行出的结果是随机的,并不是期待的100000。这就是所谓的线程不安全。不安全的原因是什么呢?代码中进行的count++操作,底层是三条指令在CPU上完成的。1.把内存中的count加载到CPU寄存器中(load)。2.把CPU寄存器中的值进行++操作(add)。3.把寄存器中的值,写回到内存中(save)。
由于有两个线程同时执行这一代码逻辑,就会在真正执行的时候产生多种执行的排列顺序。
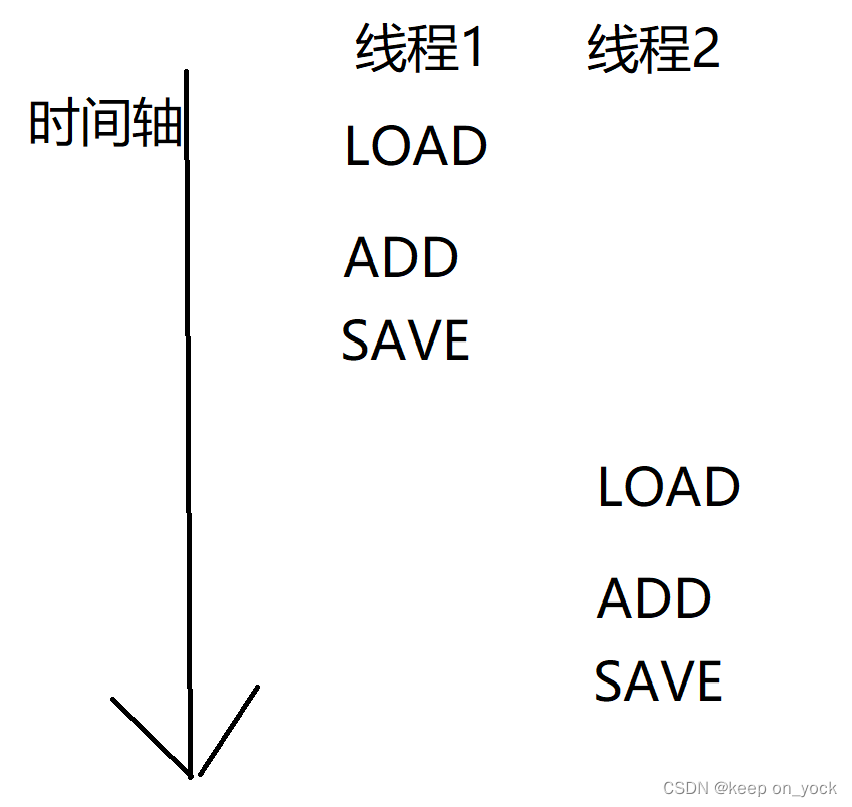
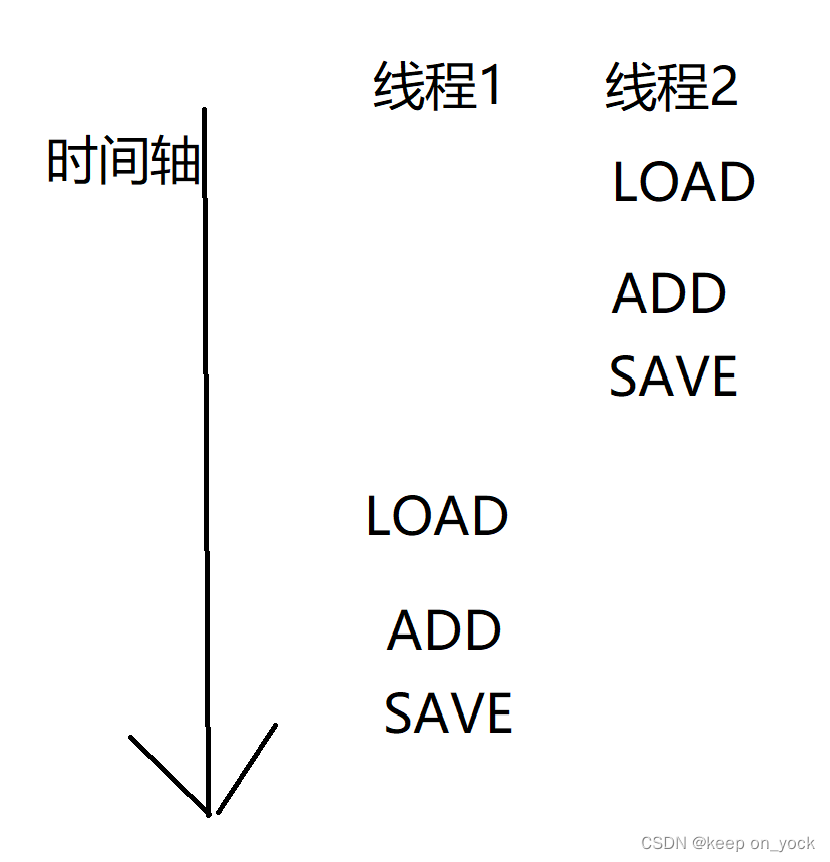
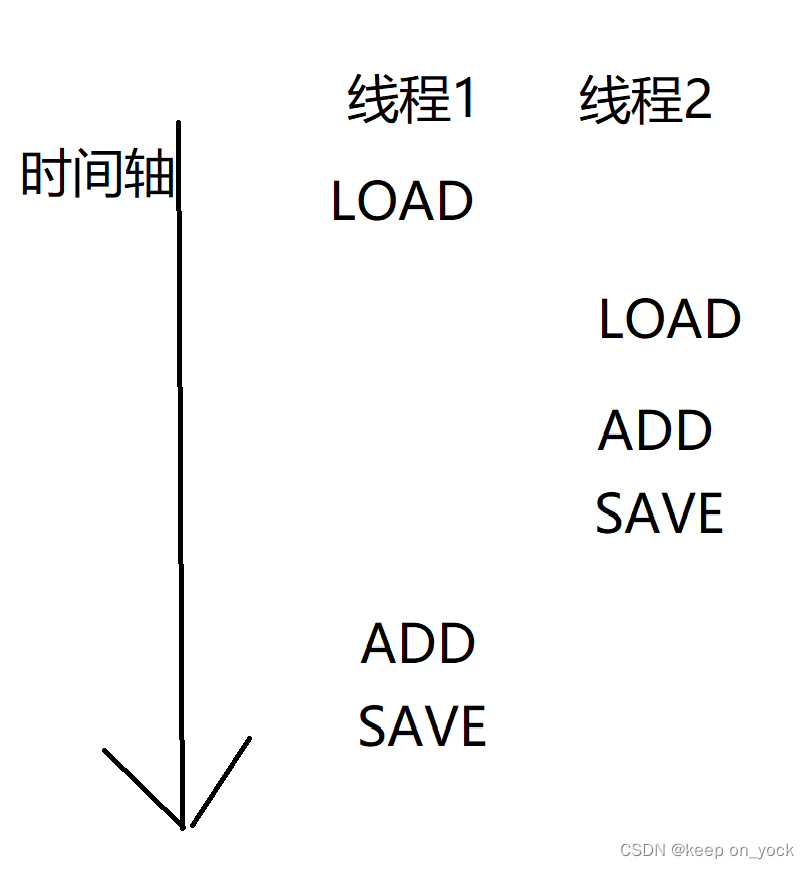
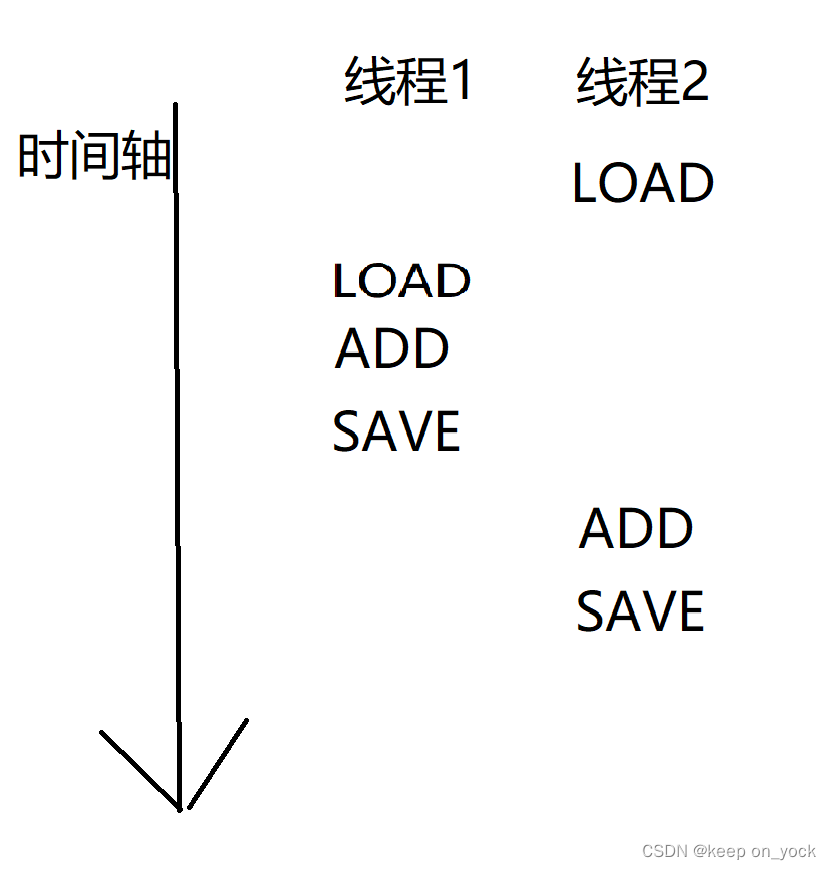
当代码在真正执行的时候,会有多种执行顺序。图1和图2虽是在多线程下执行的,但是和串行执行的代码效果一样,不会产生线程安全的问题。但是以图3为例:
首先是线程一将count加载到CPU的寄存器中:
然后线程2也将count加载到CPU的寄存器中:

然后线程2执行ADD操作并且写回到内存中:
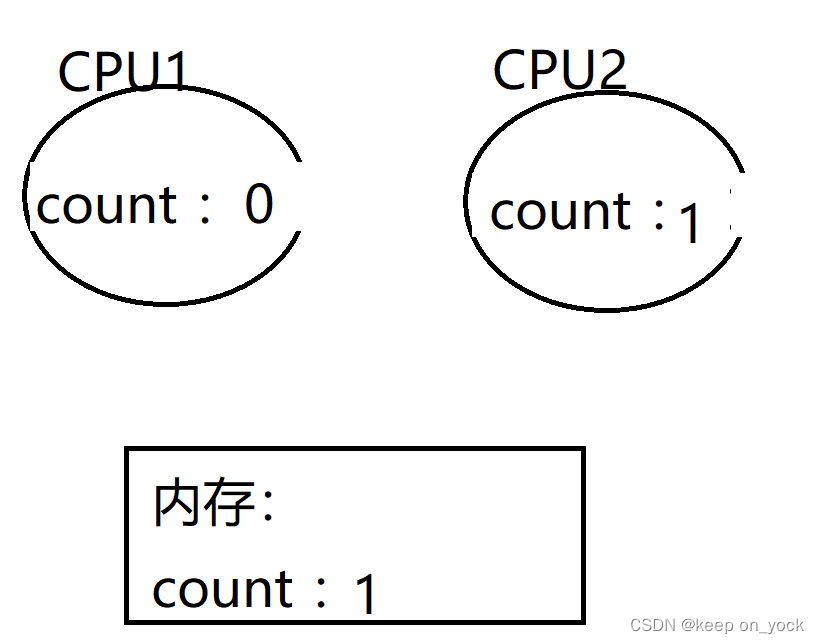
最后线程1执行ADD操作并且写回到内存中:
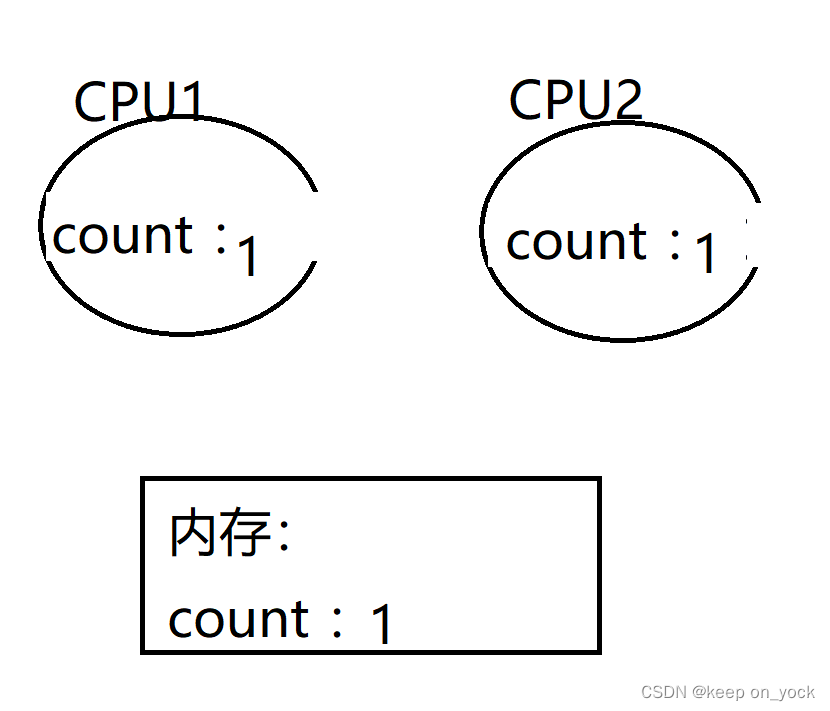
此时虽然进行了两次自增操作,但是在多线程执行代码逻辑时并没有达到预期的效果,自增逻辑执行了两次,但是实际上却只自增一次。这就是线程安全问题。
线程不安全只要有五种原因:
1.抢占式执行(线程不安全的主要原因):多个线程调度执行的过程中,可以认为是全随机的。在写多线程代码是,就要考虑到在任何一种调度情况下都能够运行出正确的结果。
2.多个线程修改同一变量:以上的例子就是多个线程修改同一变量的例子。
3.修改操作不是原子的:原子表示不可分割的最小单位。count++这种操作,本质上是有三个CPU指令(LOAD,ADD,SAVE)。像“count++”这种操作,都是以“一个指令”为单位进行执行的。一个指令就是CPU执行的最小单位了。
4.内存可见性问题:也会引发线程不安全问题。是由于JVM的代码优化引入的bug。
5.指令重排序:也会引发线程不安全问题。
我们在解决线程安全问题,最常见的方法就是通过特殊手段,将“count++”这种操作打包成原子,此时的修改操作就是原子的了。这种操作就是
加锁
操作:在count++之前先加锁,在count++之后再解锁。在加锁和解锁之间进行修改,这时别的线程就修改不了了。别的线程只能阻塞等待,等待正在修改的线程执行完毕之后再进行修改。
在java中,要进行加锁操作,使用synchronized关键字。
public synchronized void increase(){
count++;
}这是synchronized关键字最基本的使用方法:使用synchronized关键字来修饰一个普通方法,当进入该方法的时候就会进行加锁操作,方法执行完之后就会进行解锁操作;
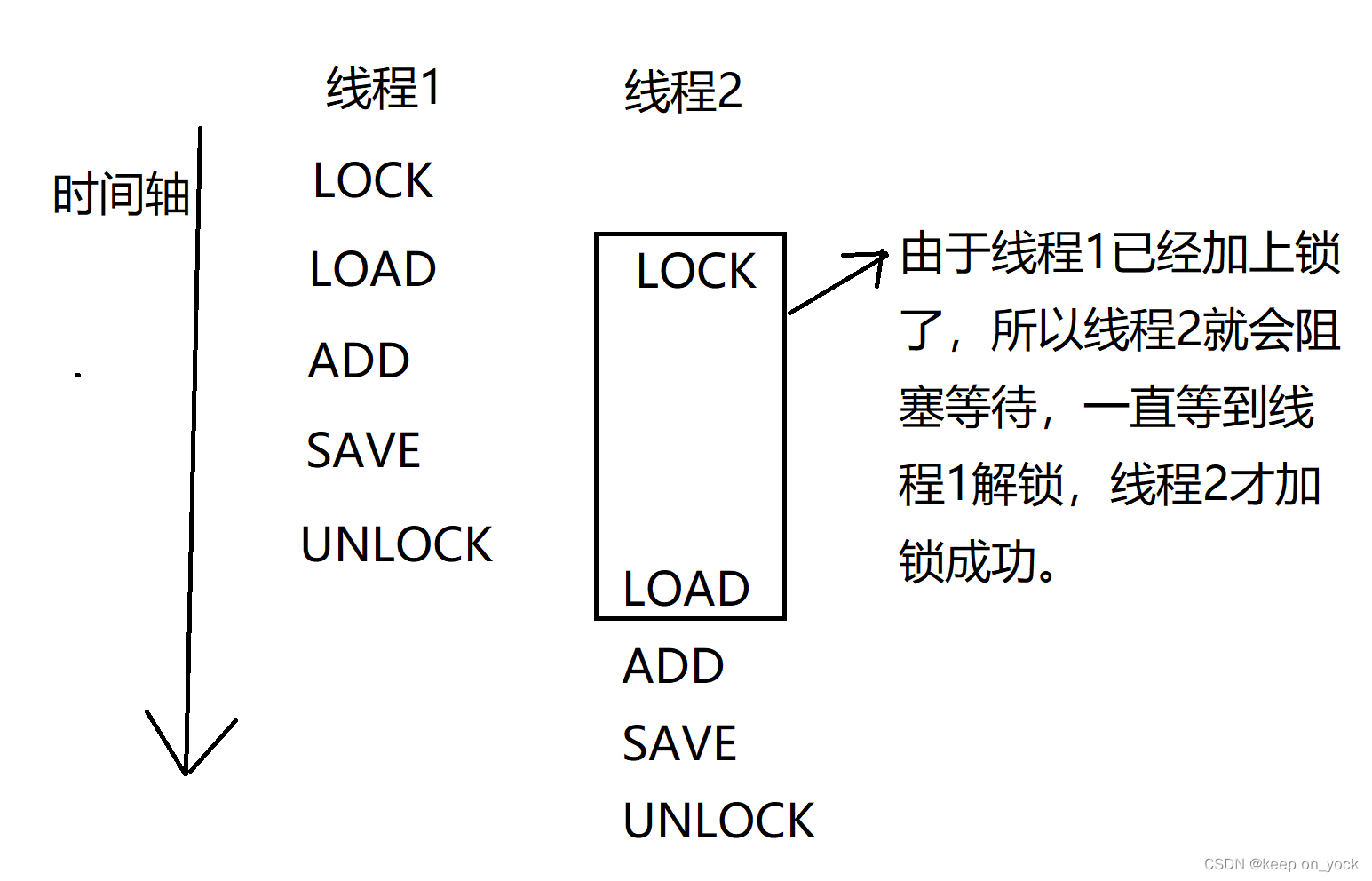
锁是具有独占性的,如果当前没人来加锁,加锁操作就会成功。如果此时锁已经被加上了,加锁操作就会阻塞等待。
解决线程安全问题,不是说加了锁就一定线程安全了,而是说通过加锁操作,让并发修改同一变量变成串行修改同一变量。
public void incease(){
synchronized(){
//synchronized括号里面要填一个对象,表示是要针对哪个对象进行加锁
}
}被用来加锁的对象,称为锁对象。在java中,任意的对象,都可以作为锁对象。synchronized关键字不仅可以用来修饰方法,还可以用来修饰代码块。
public void increase(){
synchronized(this){
//针对当前对象进行加锁,谁调用了increase方法谁就是this
count++;
}
}public Object locker=new Object();
public void increase(){
synchronized(locker){
count++;
}
}class Locker{
}
public void increase(){
public static Locker locker=new Locker();
public void increase(){
synchronized(locker){
count++;
}
}
}在使用synchronized关键字的时候,不必关心这个锁对象究竟是谁,是哪种形态,只是关心两个线程是否锁的是同一个对象,锁同一个对象就会产生锁竞争,锁的不是同一个对象就不会产生锁竞争。
总结一下synchronized 的使用方法:1.修饰普通方法,锁对象相当于this。 2.修饰代码块,要在括号中指定锁对象。3.修饰静态方法,锁对象相当于类对象。
上述讲解由一个线程安全案例引发出synchronized的使用方法,我们接下来要了解一下常见的锁策略,了解了这些锁策略之后才能更好的了解synchronized原理。
常见的锁策略
1.乐观锁VS悲观锁:描述的是两种不同的加锁态度。锁冲突指的是:两个线程竞争同一把锁产生的阻塞等待。 乐观锁:预测锁冲突的概率不高,因此做的工作就可以简单一些。悲观锁:预测锁冲突的概率较高,因此做的工作就要复杂一些。
2.普通互斥锁VS读写锁:普通的互斥锁:就如同synchronized一样,当两个线程竞争同一把锁的时候就会产生锁冲突进而会有阻塞等待。 读写锁是根据代码实际的逻辑进行加锁:有加读锁和加写锁两种锁。读锁和读锁之间,不会产生锁竞争。读锁和写锁之间,会产生锁竞争。写锁和写锁之间,会产生锁竞争。如果代码逻辑中读的场景很多,写的场景很少,此时读写锁就会比普通互斥锁优化了效率并且减少了不必要的锁竞争。
3.重量级锁VS轻量级锁:重量级锁:加锁解锁的开销比较大,典型的就是进入内核态的加锁逻辑,开销是比较大的。轻量级锁:加锁解锁的开销比较小,典型的就是纯用户态的加锁逻辑,开销是比较小的。 重量级锁和轻量级锁最终是站在结果的角度去看待加锁解锁的过程开销是多还是少。 而乐观锁和悲观锁是站在过程的角度去看待加锁解锁过程中干的活是多还是少。 通常情况下,干的工作多也就会消耗资源多,干的工作少也就会消耗资源少,因此,通常情况下,我们会认为乐观锁比较轻量,悲观锁比较重量(但不绝对)。
4.自旋锁VS挂起等待锁:自旋锁是轻量级锁的一种典型实现,自旋锁就类似于“忙等”,反复不停地看当前锁是否就绪是否可以加锁,会消耗大量地CPU。挂起等待锁是重量级锁的一种典型实现,不会像自旋锁一样一直等着当前锁,而是可以选择去先做别的事情,过一会再来看当前锁是否已经就绪。
5.公平锁VS非公平锁:公平是遵循“先来后到”的原则的。t1,t2,t3三个线程竞争同一把锁,谁先来的谁就拿到锁,这叫公平锁。如果是三个线程随机一个拿到锁,后来的线程可能会先拿到锁,这就是非公平锁。操作系统默认的锁的调度是非公平的。
6.可重入锁VS不可重入锁:同一个线程针对同一把锁连续加锁两次,如果会造成死锁就是不可重入锁,如果不会造成死锁就是可重入锁。
而对于snychronized锁来说:1.既是乐观锁,也是悲观锁。2.既是轻量级锁,也是重量级锁。3.乐观锁的部分是基于自旋锁实现的,悲观锁的部分是基于挂起等待锁实现的。4.synchronized是普通互斥锁,不是读写锁。5.synchronized是非公平锁。6.synchronized是可重入锁。
所以,
snychronized是自适的
。在初始使用的时候,是乐观锁/轻量级锁/自旋锁,如果竞争不激烈,就处于上述状态不变,如果竞争激烈,synchronized会自动升级为悲观锁/重量级锁/挂起等待锁。这是JVM在实现synchronized的时候给我们提供的自动优化的策略,synchronized会自动适用多种不同的场景。
由此,又引出了synchronized的内部原理 锁升级、锁消除、锁粗化:
synchronized的效果是加锁,当两个线程针对同一个对象进行加锁的时候,会产生锁竞争,后来尝试加锁的线程就会阻塞等待,直到另一个线程释放锁。
1.锁升级/锁膨胀
:synchronized加锁的具体过程是:偏向锁->轻量级锁->重量级锁。
synchronized更多的是考虑到降低程序员的使用负担,内部就实现了”自适应”的操作。如果当前场景中锁竞争是不激烈的,则是以轻量级锁状态来进行工作。如果当前场景中锁竞争是激烈的,则是以重量级锁状态来进行工作。
偏向锁:必要的时候才加锁,能不加锁的时候就不加。我们给某个代码加了一个synchronized,但是代码在执行过程中真的会触发锁竞争吗?是不一定的。
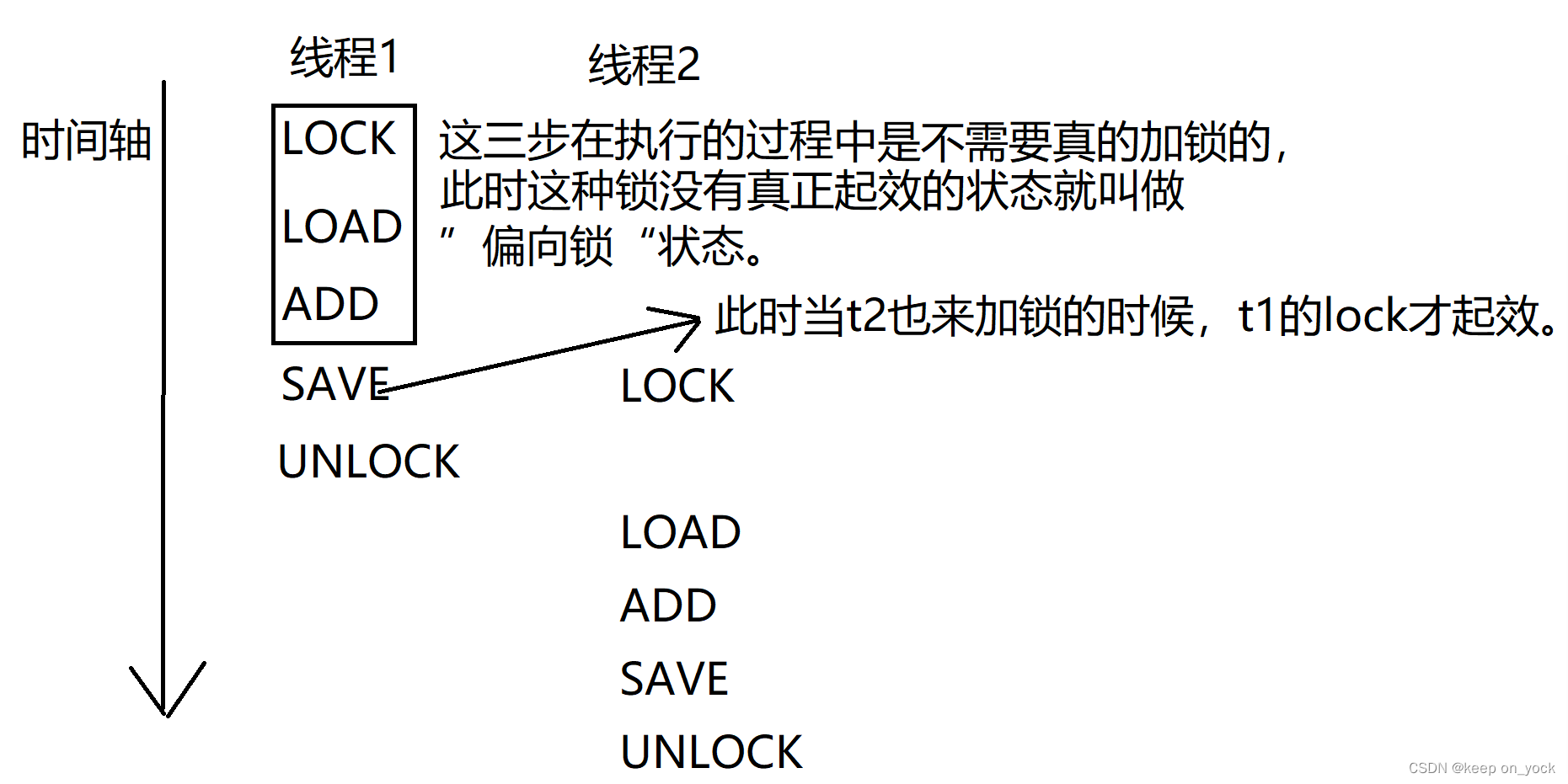
如果线程1线程2两个线程本身调度的时候错开了,此时两个线程没有发生过锁竞争,就没有必要进行加锁操作,此时的锁状态就是 偏向锁状态。
偏向锁不是真加锁,只是设置的一种加锁状态。
轻量级锁(自旋锁):会第一时间拿到锁。
重量级锁(挂起等待锁):不会那么及时拿到锁,但是节省了CPU的开销。
synchronized的执行过程:
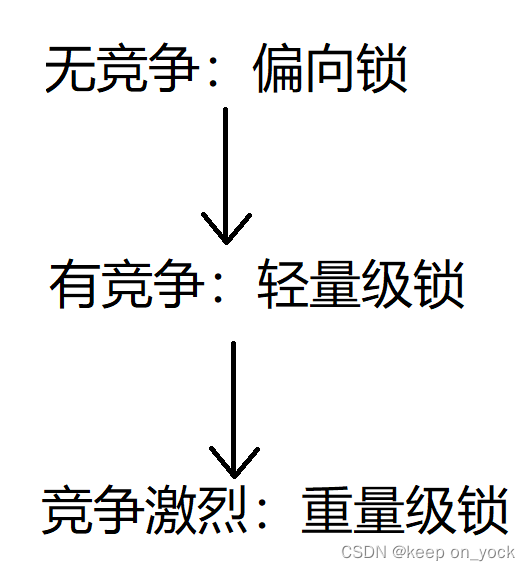
上述这样的过程称为:锁升级/锁膨胀。这是JVM实现synchronized的时候,为了方便我们的使用,引入的一些优化机制。
2. 锁消除
:JVM会自动判定,某个地方不必加锁,如果代码中写了synchronized,JVM就会自动把锁去掉。比如在一个线程中,或者在多个线程中,多个线程不涉及同时修改同一个变量,如果代码中写了synchronized,此时的synchronized加锁操作,就会直接被JVM给干掉。
锁消除也是一种编译器优化的行为。编译器的判定不一定非常准,因此如果编译器觉得代码的锁百分之百能消除,编译器就能给消除。如果不能判定这个锁百分之百消除,就不消除。所以,锁消除是在编译器十分有把握的时候才会实现。
3.锁粗化
:锁的粒度:表示synchronized对应代码块中包含了多少代码。包含的代码少,锁的粒度就细,包含的代码多,锁的粒度就粗。锁粗化:就是将锁的粒度由细变粗。
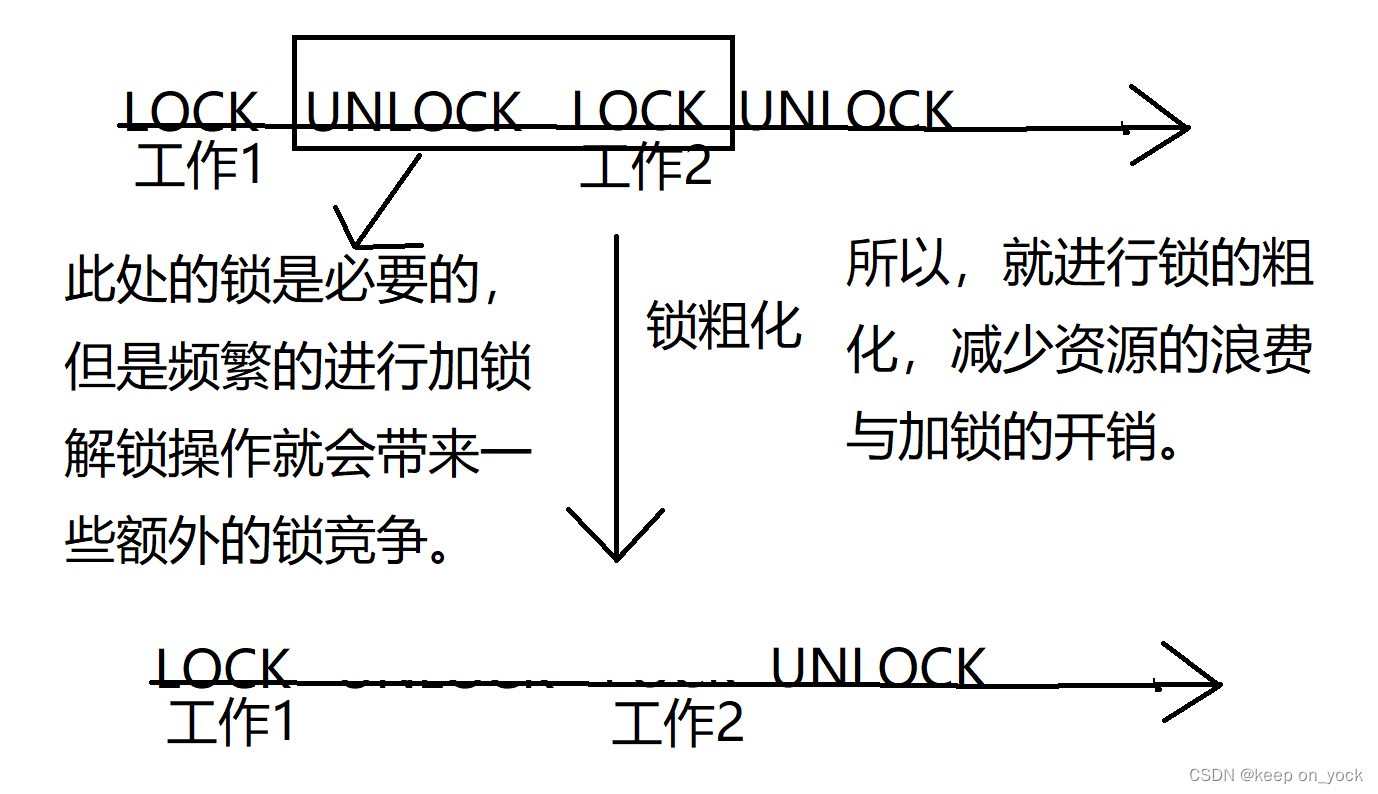
synchronized的原理介绍完了之后,开始理解
死锁
:
死锁
:一个线程加上锁之后,解不开了,僵住了。
场景一:一个线程一把锁:
class Counter{
public synchronized void increase(){
synchronized(this){
count++;
}
}
}形如上述场景,在一个线程中,连续针对同一把锁加锁两次,就可能会造成死锁。造成死锁的原因是:第一把锁能够加锁成功,但是在对第二把锁进行加锁的时候,因为锁已经被占用了,所以会产生阻塞等待,要等待第一把锁解锁之后,第二把锁才能加锁成功。而第一把锁解锁,则需要执行完相应的synchronized代码块,也就是需要第二把锁加锁成功。
针对上述场景,不会产生死锁的这种锁叫做 可重入锁。会产生死锁的这种锁叫做不可重入锁。而synchronized是一把可重入锁,所以针对上述场景,是不会发生死锁的。
可重入锁的底层实现原理:1.让锁持有当前加锁的线程对象。2.维护一个计数器,用于衡量啥时候是真加锁,啥时候是直接放行。

可重入锁的底层会引入一个计数器,每次加锁,计数器++;每次解锁,计数器–;当此时计数器为0的时候,此时的加锁是真加锁。此时的计数器为1的时候, 此时的解锁是真解锁。
场景二:两个线程两把锁:比如生活中一个常见的场景:门钥匙锁在车里了,而车钥匙锁在家里了。
public class Test {
public static void main(String[] args){
Object locker1=new Object();
Object locker2=new Object();
Thread t1=new Thread(()->{
System.out.println("t1线程尝试获取locker1");
synchronized (locker1){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("t1线程尝试获取locker2");
synchronized (locker2){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("t1线程获取两把锁成功");
}
}
});
Thread t2=new Thread(()->{
System.out.println("t2尝试获取locker2");
synchronized (locker2){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("t2尝试获取locker1");
synchronized (locker1){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("t2线程获取两把锁成功");
}
}
});
t1.start();
t2.start();
}
}
场景三:多个线程多把锁,更容易死锁。典型的一个实例就是哲学家吃饭问题:
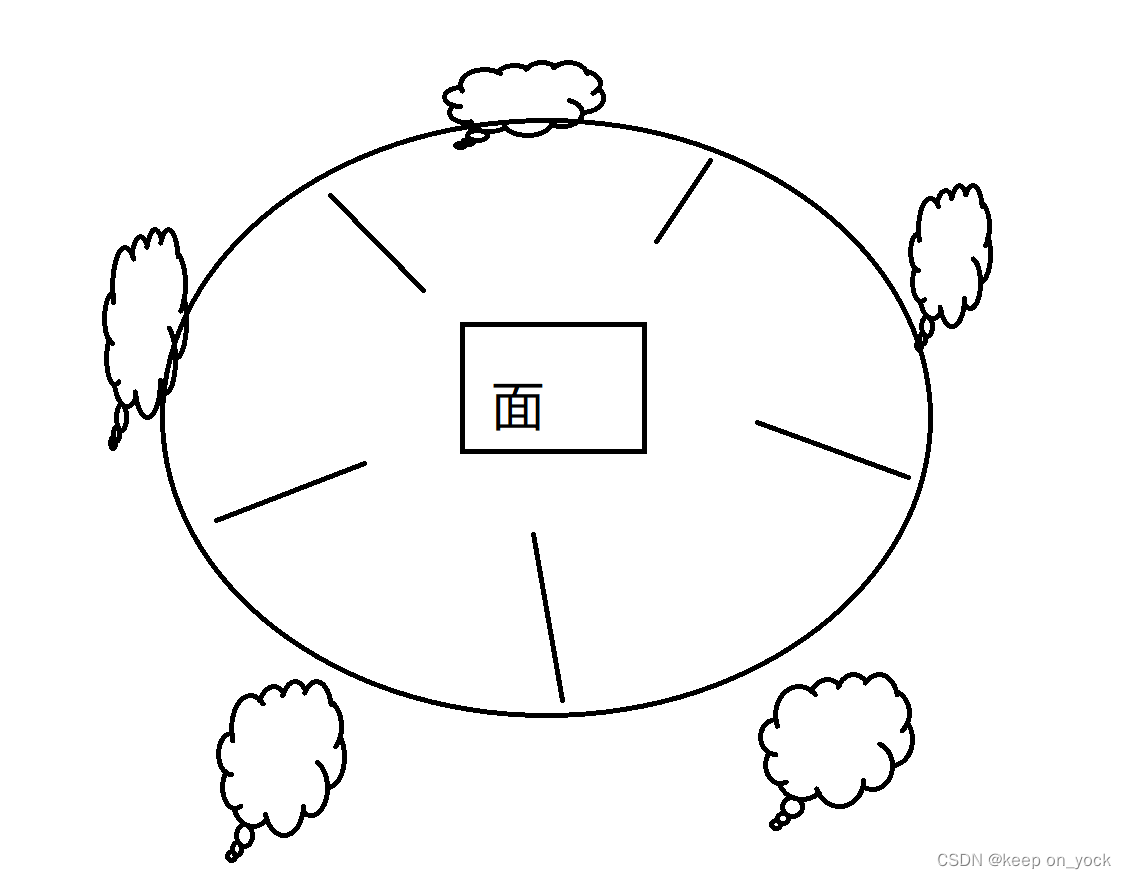
有五个哲学家,每个哲学家中间有一根筷子,只有拿起两个筷子(先拿左边再拿右边)才能去吃面。 大部分情况下,这种模型是不会有问题的,但是极端情况下,就会出现死锁的情况。比如:五个科学家同时拿起左边的筷子。此时五个线程都会陷入阻塞。
先说一下死锁的四个必要条件,再去考虑如何打破这种僵局:
死锁的四个必要条件:1.互斥使用:锁被线程1占用,线程2就用不了了。2.不可抢占:锁A被线程1占用,线程2不能把锁A给抢过来,除非线程1主动释放。3.请求和保持:有多把锁,线程1拿到锁A之后,不想释放,还想拿到一个锁B。4.循环等待:线程1要等待线程2释放锁,线程2等待线程3释放锁,线程3等待线程1释放锁……
其中第四个必要条件是最容易打破的,约定好加锁顺序,就可以打破循环等待。比如:给每把锁编号:两把锁必须先获取编号小的再获取编号大的;