1. 背景
本节介绍 阿里的分布式事务框架 Seate ,和集成示例。
2.知识
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。
Seata 用户提供了多种事务模式:
- AT 模式
- TCC 模式
- SAGA 模式
- XA 模式
2.1 AT 模式
适合场景:
- 基于支持本地 ACID 事务的关系型数据库。
- Java 应用,通过 JDBC 访问数据库。
AT 模式是基于 2PC模式(两阶段提交协议)的演变:
- 一阶段:业务操作时,记录一个操作日志记录,并在同一个本地事务中一起提交,然后释放本地锁和连接资源。
- 二阶段:异步化快速地完成。或者回滚日志进行回滚。
2.2 TCC 模式
TCC 模式,不依赖于底层数据资源的事务支持:
- 一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
- 二阶段 commit 行为:调用 自定义 的 commit 逻辑。
- 二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
本文仅讨论 AT 模式
2.3 概念
TC (Transaction Coordinator) – 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) – 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) – 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
它们之间的关系用图来表示如下:
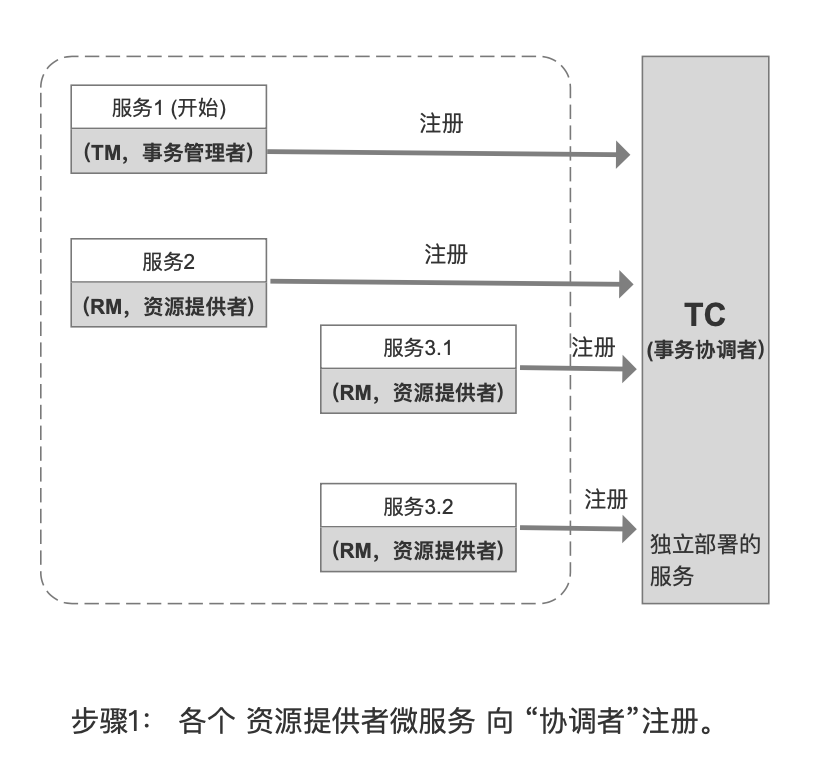
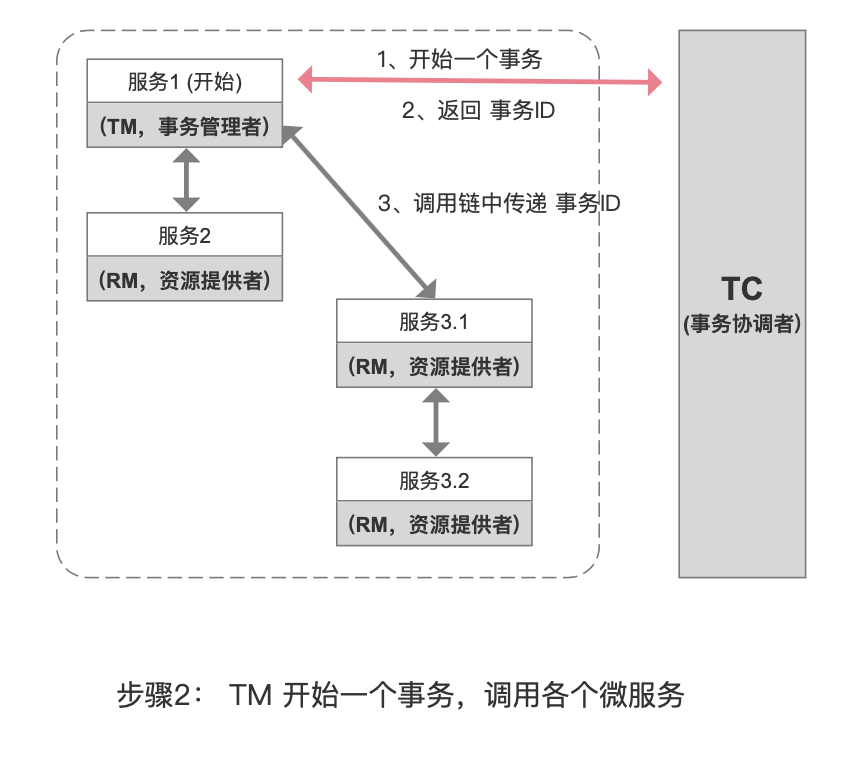
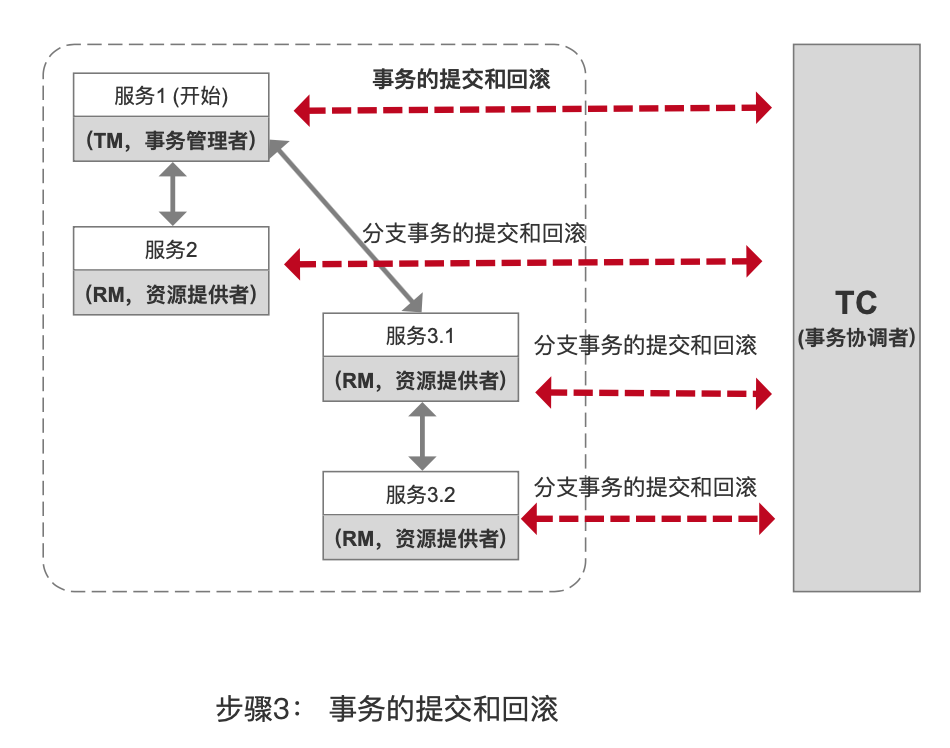
3. Springboot 集成 Seate 的示例
3.1 整体结构组成
由这些组成:
- 1个 seata-server,作为 TC 事务协调者
- 多个 微服务和服务方法,作为 RM 资源提供者
可以认为 事务管理者就是发起 分布式事务调用的 起始方法。
3.2 步骤一:配置server
seata-server 是 seata 官方提供的服务端,作为 协调者 使用。
seata-server的存储的模式
其中 seata-server 的存储事务ID ,各个分支事务等内容,它可以支持多种存储模式(store.mode),现有
- file 文本模式存储
- db 数据库存储
- redis 存储在redis中
file 存储是单服务器的方式,不需要额外配置,直接启动即可。
db 存储需要 建好库表,并配置好参数。
redis 存储比较快,但是存在事务信息丢失的风险。
由此也可以想到 在高可用 需求下还是需要 使用 db 模式,防止单一服务挂掉。
我这里就用 file 模式演示。
-
从
https://github.com/seata/seata/releases
,下载服务器软件包,将其解压缩。
Usage: sh seata-server.sh(for linux and mac) or cmd seata-server.bat(for windows) [options]
Options:
--host, -h
The host to bind.
Default: 0.0.0.0
--port, -p
The port to listen.
Default: 8091
--storeMode, -m
log store mode : file、db
Default: file
--help启动:
sh seata-server.sh -p 8091 -h 127.0.0.1 -m file解释:-h 是绑定的ip,-p 后面是端口,-m 指定了存储模式 file 文本模式。
3.3 步骤二:配置微服务
1、添加依赖
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</dependency>
2、配置访问 seata 服务的地址
修改 application.yml 文件
seata:
enabled: true
application-id: business-service
tx-service-group: my_test_tx_group
service:
vgroup-mapping:
my_test_tx_group: default
grouplist:
default: 127.0.0.1:8091
#enable-degrade: false
#disable-global-transaction: false
3、配置下数据访问的数据源
我使用 ibatis 作为存储层,配置下数据源
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource() {
DruidDataSource druidDataSource = new DruidDataSource();
return druidDataSource;
}
@Bean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(dataSource);
factoryBean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath*:/mapper/*.xml"));
return factoryBean.getObject();
}
4、在一个方法上开启一个事务
使用 @GlobalTransactional 注解 在方式上 标识开启事务
@GlobalTransactional
public void payMoney(int id, int money) {
LOGGER.info("# 分布式事务 开始... xid: " + RootContext.getXID());
Money money1 = moneyMapper.selectById(id);
if (money1.getMoney() + money < 0) {
throw new RuntimeException("没有足够的钱");
}
money1.setMoney(money1.getMoney() + money);
moneyMapper.updateById(money1);
storageClient.changeMoney(id, money * 100);
}至此完成了 微服务的配置,它负责开始一个 分布式事务。而在这个过程中它还调用了 其他的微服务中的服务,这些其他服务是整体服务的一部分。因此我们还需要传递 “事务ID”,我们使用 RestTemplate 作为HTTP 请求的客户端工具,因此我们可以写一个 拦截器,在每次HTTP中携带 “事务ID”
3.4 步骤四:在RestTemplate中携带“事务ID”
由于使用 springboot,我们可以在注入 RestTemplate 时,添加初始化方法:
/* RestTemplate 的注入 */
@Configuration
public class SeataRestTemplateAutoConfiguration {
@Autowired(
required = false
)
private Collection<RestTemplate> restTemplates;
@Autowired
private SeataRestTemplateInterceptor seataRestTemplateInterceptor;
public SeataRestTemplateAutoConfiguration() {
}
@Bean
public SeataRestTemplateInterceptor seataRestTemplateInterceptor() {
return new SeataRestTemplateInterceptor();
}
@PostConstruct
public void init() {
if (this.restTemplates != null) {
Iterator var1 = this.restTemplates.iterator();
while (var1.hasNext()) {
RestTemplate restTemplate = (RestTemplate) var1.next();
List<ClientHttpRequestInterceptor> interceptors = new ArrayList(restTemplate.getInterceptors());
interceptors.add(this.seataRestTemplateInterceptor);
restTemplate.setInterceptors(interceptors);
}
}
}
}
/* 拦截器类的实现 */
public class SeataRestTemplateInterceptor implements ClientHttpRequestInterceptor {
private static final Logger LOGGER = LoggerFactory.getLogger(SeataRestTemplateInterceptor.class);
public SeataRestTemplateInterceptor() {
}
public ClientHttpResponse intercept(HttpRequest httpRequest, byte[] bytes, ClientHttpRequestExecution clientHttpRequestExecution) throws IOException {
LOGGER.info("# 进入 RestTemplate 拦截器");
HttpRequestWrapper requestWrapper = new HttpRequestWrapper(httpRequest);
String xid = RootContext.getXID();
if (StringUtils.isNotEmpty(xid)) {
requestWrapper.getHeaders().add(RootContext.KEY_XID, xid);
LOGGER.info("# 进入 RestTemplate 请求中加入 全局事务 xid=" + xid);
}
return clientHttpRequestExecution.execute(requestWrapper, bytes);
}
}事务ID 要在微服务的调用链中传递,并绑定到 Seata 上下文中,这样 一个完整事务就通过 事务ID 串联起来。
到了这一步后,RestTemplate 发送 HTTP 请求时已携带事务ID,而在 其他的 微服务被调用方在收到 “事务ID”后,还需要做 绑定事务ID 到 Seata 的上下文对象中。
3.5 步骤四:绑定 事务ID 到上下文中。
微服务的被调用方,也就是 事务ID的接收方,需要 绑定 事务ID 到上下文。 Seata 的上下文对象 可以调用 RootContext.bind(xid); 完成 事务ID 的绑定。
我们写一个 过滤器 ,它会从 请求中检索到 事务ID,并完成绑定 事务ID到上下文。
@Component
public class SeataFilter implements Filter {
private static final Logger LOGGER = LoggerFactory.getLogger(SeataFilter.class);
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) servletRequest;
String xid = req.getHeader(RootContext.KEY_XID.toLowerCase());
boolean isBind = false;
if (StringUtils.isNotBlank(xid)) {
LOGGER.info("# 绑定 xid=" + xid);
RootContext.bind(xid);
isBind = true;
}
try {
filterChain.doFilter(servletRequest, servletResponse);
} finally {
if (isBind) {
RootContext.unbind();
}
}
}
@Override
public void destroy() {
}
}
3.6 步骤五:建立 UNDO_LOG 表(回滚日志表)
UNDO_LOG表 是 回滚日志表。它记录了每次 数据前后变化的内容,因此可以做为回滚记录,当需要回滚时,读取这个表的数据写回去。
在你的每个 微服务使用的数据库里 建立这个表,如下:
回滚日志表
UNDO_LOG Table:不同数据库在类型上会略有差别。
以 MySQL 为例:
Field Type
branch_id bigint PK
xid varchar(100)
context varchar(128)
rollback_info longblob
log_status tinyint
log_created datetime
log_modified datetime
-- 注意此处0.7.0+ 增加字段 context
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;上面就是集成 seata 的关键步骤。
3.7 总结
回滚日志表怎么用?
seata 是 “两步提交机制”,即 2PC,在两步提交的模式进行了增强:
第一步:
-
— 1.1 更新前:根据解析得到的条件信息,生成查询语句,获得“修改前数据”。
-
— 1.2 执行业务 SQL:更新这条记录的 name 为 ‘GTS’。
-
— 1.3 更新后:通过 主键 定位数据,获得“修改后的数据”
-
— 1.4 插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中。
第二步:
根据业务操作情况,判断分支事务的结果,并决策是回滚或者提交:
- 如果提交: 删除各个 分支事务中的 UNDO_LOG 表的记录。
- 如果回滚:读取 UNDO_LOG 表的记录内容,重写写过 “原数据”即可。
由此可以看到, seata 通过 UNDO_LOG 表来实现回滚,它并依赖于 数据的的 本地事务的回滚机制,它不锁定 “资源“,由此带来的好处是数据访问的更大吞吐量。
5. 扩展
我的代码示例见:
https://github.com/vir56k/java_demo/tree/master/seata_demo
5.参考:
重点参考:
https://seata.io/zh-cn/docs/overview/what-is-seata.html
https://seata.io/zh-cn/docs/ops/deploy-guide-beginner.html
https://github.com/seata/seata-samples